Управление затратами для бессерверного пула SQL в Azure Synapse Analytics
В этой статье объясняется, как выполнять оценку и управление затратами для бессерверного пула SQL в Azure Synapse Analytics.
- Оценка объема данных, обрабатываемых перед выдачей запроса
- Использование функции управления затратами для установки бюджета
Следует учитывать, что затраты на бессерверный пул SQL в Azure Synapse Analytics включаются в счет ежемесячной оплаты Azure. Если вы используете другие службы Azure, то вам будет выставлен счет за все службы и ресурсы Azure, используемые в вашей подписке Azure, в том числе сторонние службы. В этой статье объясняется, как выполнять оценку и управление затратами для бессерверного пула SQL в Azure Synapse Analytics.
Обработанные данные
Обработанные данные — это объем данных, которые система временно сохраняет во время выполнения запроса. Обработанные данные делятся на следующие составляющие.
- Объем данных, считанных из хранилища. Этот объем включает:
- Чтение данных при считывании данных.
- Чтение данных при считывании метаданных (для форматов файлов, содержащих метаданные, например Parquet).
- Объем данных в промежуточных результатах. Эти данные передаются между узлами во время выполнения запроса. Они включают в себя передачу данных в конечную точку в несжатом формате.
- Объем данных, записываемых в хранилище. Если для экспорта результирующего набора данных в хранилище используется CETAS, то объем записанных данных добавляется к объему данных, обрабатываемых для части SELECT, выполняемых CETAS.
Чтение файлов из хранилища обеспечивает высокую степень оптимизации. Эта процедура использует следующие возможности.
- Упреждающая выборка, которая может добавить некоторую нагрузку в объем считанных данных. Если запрос считывает файл целиком, то дополнительной нагрузки нет. Если файл считывается частично, как в запросах TOP N, то за счет предварительного получения данных объем данных будет немного больше.
- Оптимизированное средство синтаксического анализа значений с разделителями-запятыми (CSV). Если для чтения CSV-файлов используется PARSER_VERSION=’2.0’, то объем данных, считанных из хранилища, немного увеличится. Оптимизированное средство синтаксического анализа CSV считывает файлы параллельно, фрагментами одинакового размера. Фрагменты не обязательно будут содержать целые строки. Чтобы обеспечить синтаксический анализ всех строк, оптимизированное средство синтаксического анализа CSV также считывает небольшие части смежных фрагментов. При этом добавляется небольшой лишний объем.
Статистика
Оптимизатор запросов бессерверного пула SQL использует статистику для создания оптимальных планов выполнения запросов. Статистику можно создать вручную. В противном случае бессерверный пул SQL создаст их автоматически. В любом случае статистика создается путем выполнения отдельного запроса, возвращающего конкретный столбец с указанной частотой выборки. Этот запрос имеет связанный объем обработанных данных.
Если вы запускаете тот же или любой другой запрос, который может выиграть от создания статистики, то по возможности статистика используется повторно. Дополнительная обработка данных при создании статистики не производится.
При создании статистики для столбца Parquet из файлов считывается только соответствующий столбец. При создании статистики для столбца CSV все файлы считываются и анализируются.
Округление
Объем обработанных данных округляется до ближайшего мегабайта на запрос. Каждый запрос содержит не менее 10 МБ обработанных данных.
Какие обработанные данные не включаются в расчет
- Метаданные уровня сервера (например, имена входа, роли и учетные данные уровня сервера).
- Базы данных, создаваемые в конечной точке. Эти базы данных содержат только метаданные (в том числе пользователи, роли, схемы, представления, встроенные возвращающие табличное значение функции, хранимые процедуры, учетные данные уровня базы данных, внешние источники данных, внешние форматы файлов и внешние таблицы).
- Если используется вывод схемы, то фрагменты файлов считываются для определения имен столбцов и типов данных, а объем считанных данных добавляется к объему обработанных данных.
- Инструкции языка описания данных DDL, за исключением инструкции CREATE STATISTICS, поскольку она обрабатывает данные из хранилища на основе указанного процента выборки.
- Запросы, возвращающие только метаданные.
Уменьшение объема обработанных данных
Можно оптимизировать объем обработанных данных по каждому запросу, а также повысить производительность путем секционирования и преобразования данных в сжатый формат на основе столбцов, например Parquet.
Примеры
Представим три таблицы.
- Таблица population_csv состоит из 5 ТБ CSV-файлов. Файлы упорядочены по пяти столбцам одинакового размера.
- Таблица population_parquet содержит те же данные, что и таблица population_csv. Он содержит 1 ТБ файлов Parquet. Эта таблица меньше предыдущей, так как данные в ней сжаты в формате Parquet.
- Таблица very_small_csv состоит из файлов CSV размером 100 КБ.
Запрос 1: SELECT SUM(population) FROM population_csv
Этот запрос считывает и анализирует файлы целиком, чтобы получить значения для столбца population. Узлы обрабатывают фрагменты этой таблицы, а сумма совокупности для каждого фрагмента передается между узлами. Окончательная сумма передается в конечную точку.
Этот запрос обрабатывает 5 ТБ данных и небольшой объем ресурсов для передачи сумм фрагментов.
Запрос 2: SELECT SUM(population) FROM population_parquet
При запросе сжатых и основанных на столбцах форматов, таких как Parquet, считывается меньше данных, чем в запросе 1. Вы видите такой результат потому, что бессерверный пул SQL считывает один сжатый столбец, а не весь файл. В этом случае считывается 0,2 ТБ. (Пять столбцов одинакового размера, 0,2 ТБ каждый.) Узлы обрабатывают фрагменты этой таблицы, а сумма совокупности для каждого фрагмента передается между узлами. Окончательная сумма передается в конечную точку.
Этот запрос обрабатывает 0,2 ТБ данных и небольшой объем ресурсов для передачи сумм фрагментов.
Запрос 3: SELECT * FROM population_parquet
Этот запрос считывает все столбцы и передает все данные в несжатом формате. Если формат сжатия составляет 5:1, то запрос обработает 6 ТБ, так как будет считано 1 ТБ и передано 5 ТБ несжатых данных.
Запрос 4: SELECT COUNT(*) FROM very_small_csv
Этот запрос считывает файлы целиком. Общий размер файлов в хранилище для этой таблицы — 100 КБ. Узлы обрабатывают фрагменты этой таблицы, а сумма совокупности для каждого фрагмента передается между узлами. Окончательная сумма передается в конечную точку.
Этот запрос обрабатывает немногим более 100 КБ данных. Объем данных, обработанных для этого запроса, округляется до 10 МБ, как указано в разделе Округления данной статьи.
Управление затратами
Функция управления затратами в бессерверном пуле SQL позволяет установить бюджет для объема обработанных данных. Можно задать бюджет в терабайтах данных, обработанных в течение дня, недели и месяца. Одновременно могут быть заданы один или несколько бюджетов. Настроить управление затратами для бессерверного пула SQL можно в Synapse Studio или через T-SQL.
Настройка управления затратами для бессерверного пула SQL в Synapse Studio
Чтобы настроить управление затратами для бессерверного пула SQL в Synapse Studio, откройте пункт "Управление" в меню слева, а затем выберите пункт "Пул SQL" в разделе "Пулы аналитики". При наведении на бессерверный пул SQL вы увидите значок "Управление затратами". Щелкните этот значок.
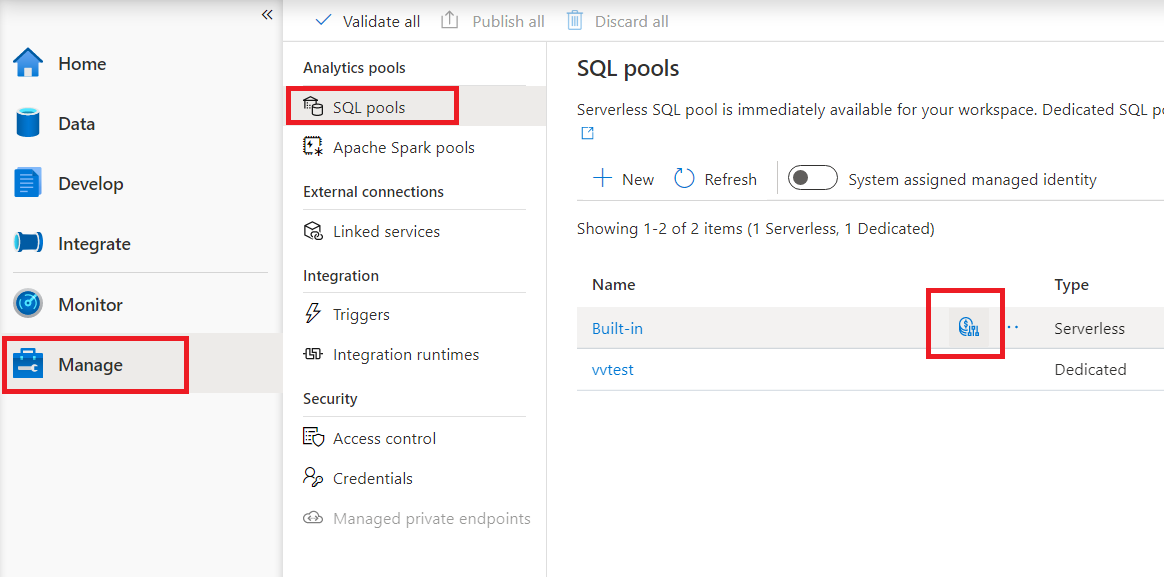
Когда вы щелкните значок управления затратами, появится боковая панель:
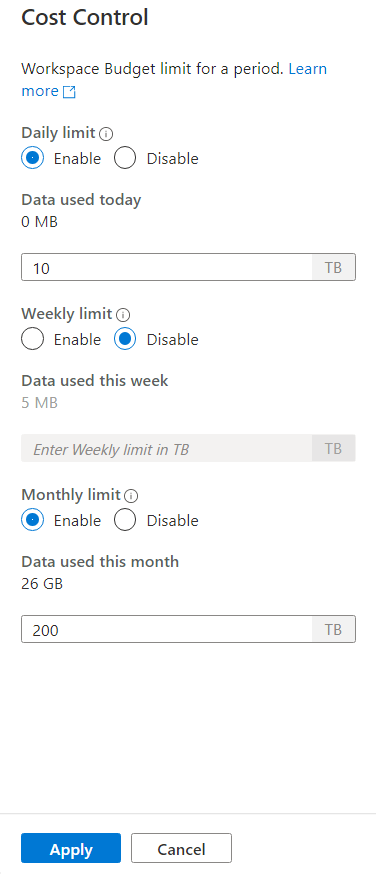
Чтобы задать один или несколько бюджетов, сначала выберите переключатель "Включить" для нужного бюджета, а затем введите целочисленное значение в текстовом поле. Единица измерения для этого значения — ТБ. После настройки бюджетов нажмите кнопку "Применить" в нижней части боковой панели. Все, бюджет установлен.
Настроить управление затратами для бессерверного пула SQL можно через T-SQL.
Чтобы настроить управление затратами для бессерверного пула SQL в T-SQL, необходимо выполнить одну или несколько следующих хранимых процедур.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Чтобы увидеть текущую конфигурацию, выполните следующую инструкцию T-SQL:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Чтобы узнать, сколько данных было обработано в течение текущего дня, недели или месяца, выполните следующую инструкцию T-SQL:
SELECT * FROM sys.dm_external_data_processed
Превышение ограничений, заданных с помощью параметров контроля затрат
Если во время выполнения запроса превышено какое-либо ограничение, запрос не будет завершен.
При превышении ограничения новый запрос отклоняется с сообщением об ошибке, которое содержит подробные сведения о периоде, определенном ограничении для этого периода и данных, обработанных за этот период. Например, если выполняется новый запрос, для которого задано еженедельное ограничение в 1 ТБ, которое было превышено, отобразится следующее сообщение об ошибке:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Дальнейшие действия
О том, как оптимизировать запросы на производительность, см. в статье Рекомендации по использованию бессерверного пула SQL.