Доступность SAP HANA в пределах одного региона Azure
В этой статье описывается несколько сценариев доступности SAP HANA в одном регионе Azure. В Azure есть множество регионов, распределенных по всему миру. Список доступных регионов см. на странице с регионами Azure. При развертывании SAP HANA на виртуальных машинах в пределах одного региона Azure корпорация Майкрософт предлагает развернуть одну виртуальную машину с экземпляром HANA. Для повышения доступности можно развернуть две виртуальные машины с двумя экземплярами HANA с помощью гибкого масштабируемого набора с FD=1, зонами доступности или набором доступности, использующим систему HANA реплика tion для доступности.
Регионы Azure, предоставляющие Зоны доступности, состоят из нескольких центров обработки данных, каждый из которых имеет собственный источник питания, охлаждения и сетевую инфраструктуру. Цель предложения разных зон в одном регионе Azure — включить развертывание приложений в двух или трех доступных Зоны доступности. Распределяя развертывание приложения между зонами, любые проблемы с питанием или сетью, влияющие на определенную инфраструктуру зоны доступности Azure, не полностью нарушают функциональные возможности приложения в регионе Azure. Хотя в одной зоне может быть сокращена емкость, например потенциальная потеря виртуальных машин в одной зоне, виртуальные машины в оставшихся зонах будут продолжать работать без прерывания. Чтобы настроить два экземпляра HANA в отдельных виртуальных машинах, охватывающих различные зоны, можно развернуть виртуальные машины с помощью гибкого масштабируемого набора с параметром развертывания зон доступности FD=1 или зоны доступности.
Для повышения доступности в регионе рекомендуется развернуть две виртуальные машины с двумя экземплярами HANA с помощью группы доступности. Группа доступности Azure — это логическая возможность группирования, которая гарантирует, что ресурсы виртуальной машины, настроенные в группе доступности, изолированы друг от друга при развертывании в центре обработки данных Azure. Azure гарантирует, что виртуальные машины, размещенные в группе доступности, выполняются на нескольких физических серверах, в вычислительных стойках, в пределах единиц хранения и сетевых коммутаторов. В некоторых документах Azure такая конфигурация упоминается как размещения в различных доменах сбоя и обновления. Эти размещения обычно находятся в центре обработки данных Azure. Предположим, что проблемы с источником питания и сетью повлияют на развернутый центр обработки данных, все ресурсы в одном регионе Azure будут затронуты.
Размещение центров обработки данных, представляющих Зоны доступности Azure, связано с компромиссом: допустимые задержки сети между службами, развернутыми в разных зонах, и определенное расстояние между центрами обработки данных. В идеале природные катастрофы не повлияют на питание, сеть и инфраструктуру во всех Зонах доступности в этом регионе. Однако, как показали крупные стихийные бедствия, Зоны доступности не всегда могут обеспечить доступность в рамках одного региона. Вспомните ураган "Мария", который обрушился на остров Пуэрто-Рико 20 сентября 2017 года. Тогда из-за него на острове шириной в 145 км практически полностью пропало электричество.
Сценарий с одной виртуальной машиной
В этом сценарии создана одна виртуальная машина Azure для экземпляра SAP HANA. Для размещения диска операционной системы и всех дисков с данными используется хранилище Azure класса Premium. Соглашения Azure об уровне обслуживания с временем бесперебойной работы на уровне 99,9 % и соглашения об уровне обслуживания других компонентов Azure достаточно для того, чтобы обеспечить доступность по соглашению для своих клиентов. В этом сценарии не требуется использовать группу доступности Azure для виртуальных машин, работающих на уровне СУБД. В этом сценарии вы полагаетесь на две различные функции:
- Автоматическая перезагрузка виртуальной машины Azure (также называется восстановлением службы Azure)
- Автоматическая перезагрузка SAP HANA
Автоматическая перезагрузка виртуальной машины Azure (или "восстановление службы") — это функция в Azure, которая работает на двух уровнях:
- узел сервера Azure проверяет работоспособность размещенных на нем виртуальных машин;
- контроллер структуры Azure отслеживает работоспособность и доступность узла сервера.
Функция проверки работоспособности отслеживает работоспособность каждой виртуальной машины, размещенной на узле сервера Azure. Если виртуальные машины оказываются в неисправном состоянии, агентом узла Azure, который проверяет работоспособность виртуальных машин, может быть инициирована их перезагрузка. Контроллер структуры Azure проверяет работоспособность узла путем проверки многих других параметров, указывающих на проблемы с оборудованием узла. Он также проверяет доступность узла в сети. Признаки проблем с узлом могут привести к следующим событиям:
- Перезагрузка узла и запущенных на нем виртуальных машин, если узел сигнализирует о плохом состоянии работоспособности.
- Если после успешной перезагрузки узел не находится в работоспособном состоянии, инициируется повторное развертывание виртуальных машин, которые изначально находились на этом узле, на работоспособный узел сервера. В этом случае исходный узел помечается как неработоспособный. Он не будет использоваться в дальнейших развертываниях, пока не будет очищен или заменен.
- Если во время процесса перезагрузки на неработоспособном узле возникают проблемы, запускается немедленный перезапуск виртуальных машин на работоспособном узле.
Благодаря мониторингу узла и виртуальной машины, выполняемому Azure, виртуальные машины Azure, размещенные на неисправном узле, автоматически перезагружаются на работоспособном узле Azure.
Важно!
При восстановлении работоспособности службы Azure виртуальные машины Linux, на которых находится гостевая ОС с ядром в критическом состоянии, не будут перезапущены. Параметры по умолчанию для обычно используемых выпусков Linux автоматически не перезапускают виртуальные машины или сервер, где ядро Linux находится в критическом состоянии. Вместо этого для ОС сохраняется критическое состояние ядра, чтобы подключить отладчик ядра для анализа. Azure учитывает это поведение, не перезапуская виртуальную машину с гостевой ОС в таком состоянии. Предполагается, что такие случаи встречаются крайне редко. Вы можете перезаписать поведение по умолчанию, чтобы инициировался перезапуск виртуальной машины. Чтобы изменить поведение по умолчанию, задайте параметр "kernel.panic" в разделе /etc/sysctl.conf. Для этого параметра устанавливается время в секундах. Рекомендуем подождать 20–30 секунд, прежде чем запускать перезагрузку с помощью этого параметра. Дополнительные сведения: sysctl.conf.
Вторая функция, на которую вы полагаетесь в таких сценариях, заключается в том, что служба HANA, выполняемая в пределах таких перезагруженных виртуальных машин, автоматически запускается после перезагрузки виртуальной машины. Вы можете настроить автоматическую перезагрузку службы HANA с помощью служб наблюдателя различных служб HANA.
Этот сценарий с одной виртуальной машиной можно улучшить, добавив узел холодной отработки отказа в конфигурацию SAP HANA. В документации по SAP HANA эта настройка называется автоматической переключение узла. Эта конфигурация может быть разумной в локальной ситуации развертывания, когда серверное оборудование ограничено, и вы выделяете узел с одним сервером в качестве узла автоматической переключения узла для набора рабочих узлов. Но в Azure, где базовая инфраструктура Azure предоставляет здоровый целевой сервер для успешного перезапуска виртуальной машины, не имеет смысла развертывать автоматическую переключение узла SAP HANA. Из-за восстановления службы Azure нет эталонной архитектуры, которая предвидит резервный узел для автоматического переключения узла HANA.
Особый случай конфигураций горизонтального масштабирования SAP HANA в Azure
Архитектуры высокой доступности на основе резервного узла или репликации системы HANA можно найти в следующих документах. В случаях, когда резервные узлы или система HANA реплика высокий уровень доступности не используются в конфигурациях горизонтального масштабирования SAP HANA, можно зависеть от возможностей восстановления службы виртуальных машин Azure и автоматического перезапуска экземпляра SAP HANA после повторной работы виртуальной машины.
- RedHat Enterprise Linux
- SUSE Linux Enterprise Server
Сценарии доступности с двумя разными виртуальными машинами
Чтобы обеспечить доступность системы HANA в определенном регионе, можно настроить две виртуальные машины в зонах доступности региона или в пределах региона. Для достижения этой цели можно настроить виртуальные машины с помощью гибкого масштабируемого набора, зон доступности или параметра развертывания группы доступности. Базовая установка в Azure будет выглядеть следующим образом:
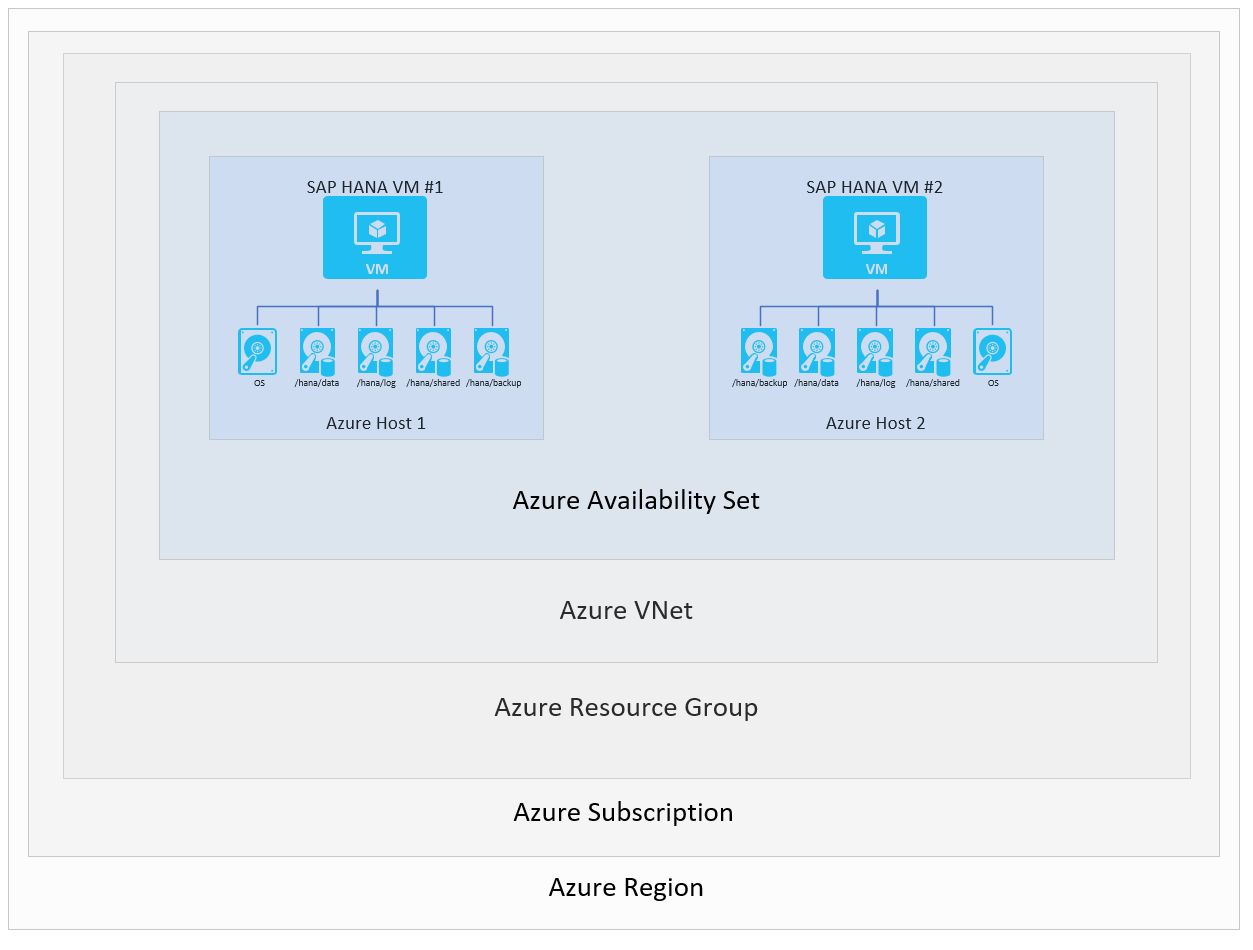
Чтобы проиллюстрировать различные сценарии доступности SAP HANA, несколько слоев на схеме опущены. На схеме показаны уровни виртуальных машин, узлов, групп доступности и регионов Azure. Виртуальные сети Azure, группы ресурсов и подписки не играют роли в сценариях, описанных в этом разделе.
Репликация резервных копий на вторую виртуальную машину
Одной из самых элементарных конфигураций является использование резервных копий. В частности, для передачи резервных копий журналов транзакций с одной виртуальной машины Azure на другую. Можно выбрать хранилище Azure любого типа. В этой настройке вы несете ответственность за скрипты копирования запланированных резервных копий, которые выполняются на первой виртуальной машине на второй виртуальной машине. В случае использования экземпляров второй виртуальной машины понадобится восстановить полные, добавочные, разностные резервные копии и резервные копии журналов транзакций до нужной вам точки.
Архитектура выглядит следующим образом:
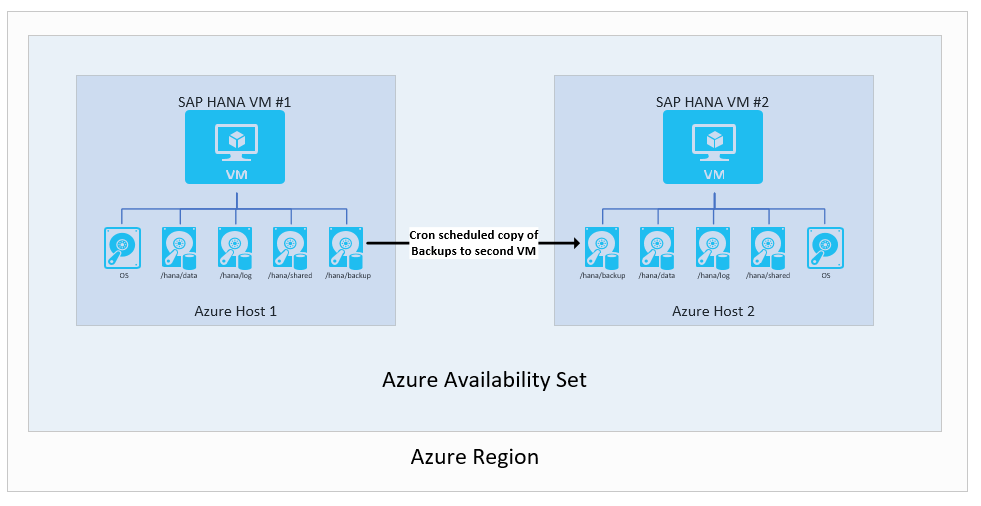
Эта настройка не подходит для достижения большой цели точки восстановления (RPO) и времени восстановления (RTO). Она особенно отражается на целевом времени восстановления (RTO): оно увеличится из-за необходимости полного восстановления всей базы данных с использованием скопированных резервных копий. Тем не менее эту конфигурацию можно использовать для восстановления после непреднамеренного удаления данных в основных экземплярах. С такой конфигурацией можно в любой момент выполнить восстановление до определенного момента во времени, извлечь данные и импортировать удаленные данные в свой основной экземпляр. Следовательно, имеет смысл использовать такой метод резервного копирования в сочетании с другими функциями обеспечения высокого уровня доступности.
Пока резервные копии копируются, можно обойтись виртуальной машиной меньшего размера, чем основная виртуальная машина, в которой выполняется основной экземпляр SAP HANA. Помните, что к виртуальным машинам меньшего размера можно подключить меньше виртуальных жестких дисков. Сведения об ограничениях отдельных типов виртуальных машин см. в статье Размеры виртуальных машин Linux в Azure.
Репликация системы SAP HANA без автоматического перехода на другой ресурс
В следующих сценариях используется репликация системы SAP HANA. См. сведения о репликации системы в документации по SAP. Сценарии без автоматической отработки отказа не являются распространенными для конфигураций в одном регионе Azure. Для конфигурации без автоматического перехода на другой ресурс мониторинг и отработку отказов нужно выполнять вручную (хотя и нет необходимости устанавливать Pacemaker). Так как это трудозатратно, большинство клиентов выбирают восстановление работоспособности службы Azure. С точки зрения сценариев сбоев такая конфигурация может помочь только в некоторых пограничных случаях. Или в случаях, когда клиент хочет повысить эффективность.
Репликация системы SAP HANA без автоматического перехода на другой ресурс и предварительной загрузки данных
В этом сценарии репликация системы SAP HANA используется для синхронного перемещения данных в целях достичь целевой точки восстановления равной 0. С другой стороны, целевая точка восстановления достаточно продолжительная, поэтому вам не нужна ни отработка отказа, ни предварительная загрузка данных в кэш экземпляра HANA. В таком случае у вас есть возможности снизить затраты в своей конфигурации следующим образом:
- Запустите другой экземпляр SAP HANA на второй виртуальной машине. Экземпляр SAP HANA на второй виртуальной машине займет большую часть объема ее памяти. В случае отработки отказа на вторую виртуальную машину необходимо завершить работу запущенного экземпляра SAP HANA, данные которого полностью загружены на вторую виртуальную машину. Таким образом реплицируемые данные можно загрузить в кэш целевого экземпляра HANA на второй виртуальной машине.
- Вторая виртуальная машина может быть меньшего размера. В случае отработки отказа перед переходом на другой ресурс вручную следует выполнить еще один шаг. Необходимо изменить размер виртуальной машины до размера исходной виртуальной машины.
Сценарий выглядит следующим образом:
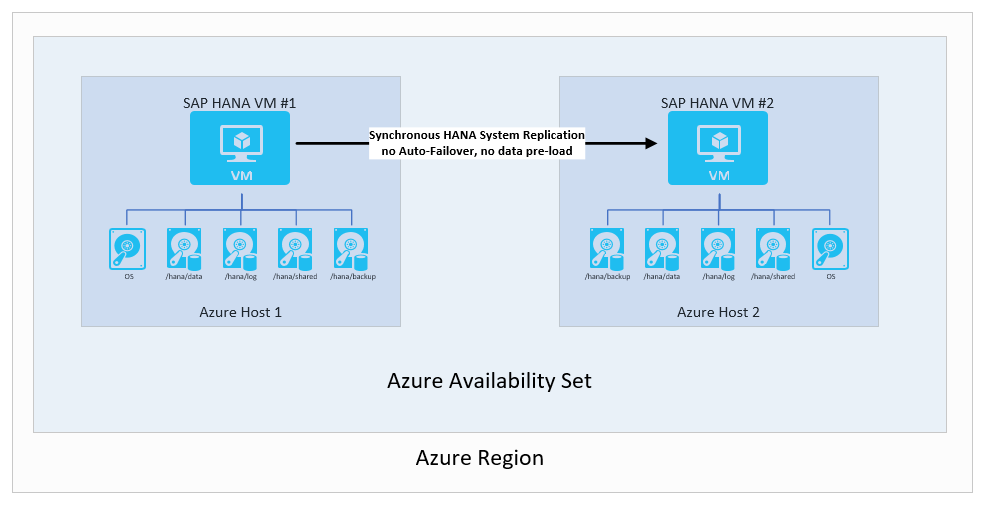
Примечание.
Даже без предварительной загрузки данных в целевом объекте репликации системы HANA потребуется по крайней мере 64 ГБ памяти. В дополнение к этому необходим достаточный объем памяти для хранения данных хранилища строк в памяти целевого экземпляра.
Репликация системы SAP HANA без автоматического перехода на другой ресурс, но с предварительной загрузкой данных
В этом сценарии данные, которые реплицируются на экземпляр HANA во второй виртуальной машине, предварительно загружаются. Таким образом теряются два преимущества отсутствия предварительной загрузки данных. В этом случае нельзя запустить другую систему SAP HANA на второй виртуальной машине, Также нельзя использовать виртуальные машины меньшего размера. Таким образом, пользователи редко реализуют этот сценарий.
Репликация системы SAP HANA с автоматическим переходом на другой ресурс
В стандартной и наиболее распространенной конфигурации доступности в одном регионе Azure две виртуальные машины Azure под управлением Linux с пакетами высокого уровня доступности имеют определенный отказоустойчивый кластер. Кластер HA Linux основан на Pacemaker платформе с помощью SLES или RHEL сfencing device SLES или RHEL в качестве примера.
С точки зрения SAP HANA используется режим синхронизированной репликации и настроен автоматический переход на другой ресурс. На второй виртуальной машине экземпляр SAP HANA действует как узел горячей замены. Этот узел получает синхронный поток записей с изменениями из основного экземпляра SAP HANA. По мере того как транзакции фиксируются приложением на основном узле HANA, основной узел HANA не будет подтверждать фиксацию в приложении, пока дополнительный узел SAP HANA не подтвердит получение записи о фиксации. В SAP HANA есть два различных режима синхронной репликации. Сведения об этих режимах см. в статье Replication Modes for SAP HANA System Replication (Режимы репликации для репликации систем SAP HANA).
Общая конфигурация выглядит следующим образом:
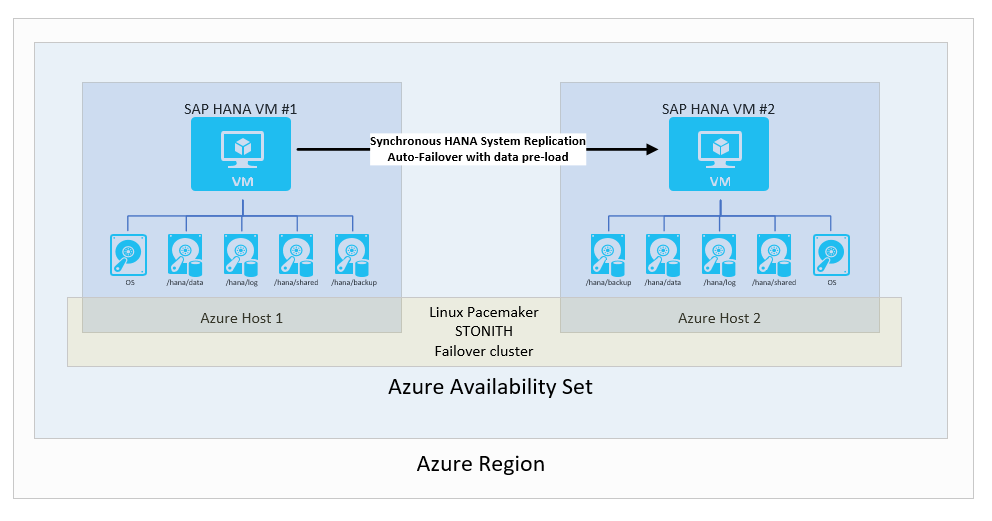
Вы можете выбрать это решение, так как это позволяет достичь RPO=0 и низкого уровня RTO. Настройте клиентское подключение SAP HANA таким образом, чтобы клиенты SAP HANA использовали виртуальный IP-адрес для подключения к конфигурации репликации системы HANA. Такая конфигурация устранит необходимость перенастройки приложения в случае отработки отказа на дополнительный узел. В этом сценарии номера SKU Azure для основной и дополнительной виртуальных машин должны быть одинаковыми.
Следующие шаги
Пошаговое руководство по настройке этих конфигураций в Azure см. в следующих статьях:
- Высокий уровень доступности SAP HANA на виртуальных машинах Azure
- Your SAP on Azure – Part 4 – High Availability for SAP HANA using System Replication (SAP в Azure (часть 4). Настройка высокого уровня доступности SAP HANA путем использования репликации системы)
Дополнительные сведения о доступности SAP HANA в регионах Azure: