Несколько GPU и компьютеров
1. Введение
В настоящее время CNTK поддерживает четыре параллельных алгоритма ШИФРОВАНИЯ:
Предварительные требования
Чтобы запустить параллельное обучение, убедитесь, что установлена реализация интерфейса передачи сообщений (MPI):
В Windows установите версию 7 (7.0.12437.6) Microsoft MPI (MS-MPI), реализацию microsoft стандарта интерфейса передачи сообщений с этой страницы, помеченную как "Версия 7" в заголовке страницы. Нажмите кнопку "Скачать", а затем выберите время выполнения (
MSMpiSetup.exe).В Linux установите OpenMPI версии 1.10.x. Следуйте инструкциям здесь , чтобы создать его самостоятельно.
2. Настройка параллельного обучения в CNTK в Python
Чтобы использовать параллельную обработку данных в Python, пользователю необходимо создать и передать распределенного учащегося в тренер:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Для определяемого пользователем цикла обучения (вместо training_session) пользователям необходимо передать num_data_partitions и partition_indexMinibatchSource.next_minibatch() метод, чтобы различные узлы MPI считывали данные из разных секций данных (после distributed_after чтения примеров).
Обратите внимание, что следует вызывать только в том случае, Communicator.finalize() если распределенное обучение успешно завершено. В случае сбоя распределенной рабочей роли этот метод не следует вызывать.
Полный функциональный пример см. в примере ConvNet.
3. Настройка параллельного обучения в CNTK в BrainScript
Чтобы включить параллельное обучение в CNTK BrainScript, сначала необходимо включить следующий параметр в файле конфигурации или в командной строке:
parallelTrain = true
Во-вторых, SGD блок в файле конфигурации должен содержать вложенный блок ParallelTrain с указанными ниже аргументами:
parallelizationMethod: (обязательные) допустимые значения:DataParallelSGD,BlockMomentumSGDиModelAveragingSGD.Это указывает, какой параллельный алгоритм будет использоваться.
distributedMBReading: (необязательно) принимает логическое значение:trueилиfalse; по умолчаниюfalseРекомендуется включить распределенное чтение мини-батов, чтобы свести к минимуму затраты на операции ввода-вывода в каждой рабочей роли. Если вы используете средство чтения текстового формата CNTK, средство чтения изображений или составное средство чтения данных, значение distributedMBReading должно иметь значение true.
parallelizationStartEpoch: (необязательно) принимает целочисленное значение; значение по умолчанию — 1.Это указывает, начиная с какой эпохи используются алгоритмы параллельного обучения; до этого все работники, выполняющие одно и то же обучение, но только один работник может сохранить модель. Этот параметр может быть полезен, если для параллельного обучения требуется некоторый этап "теплого запуска".
syncPerfStats: (необязательно) принимает целочисленное значение; значение по умолчанию — 0.Это указывает, насколько часто будет выводиться статистика производительности. Эти статистические данные включают время, затраченное на обмен данными и (или) вычисления в период синхронизации, что может быть полезно для понимания узких мест параллельных алгоритмов обучения.
0 означает, что статистика не будет напечатана. Другие значения определяют частоту вывода статистики. Например, это означает, что
syncPerfStats=5статистика будет выводиться после каждых 5 синхронизаций.Вложенный блок, указывающий сведения о каждом алгоритме параллельного обучения. Имя вложенного блока должно быть равно
parallelizationMethod. (обязательно)
Python обеспечивает большую гибкость и использование приведены ниже для различных методов параллелизации.
4. Выполнение параллельного обучения с помощью CNTK
Параллелизация в CNTK реализуется с помощью MPI.
4.1. Выполнение параллельного обучения с помощью BrainScript
Учитывая любую из приведенных выше конфигураций BrainScript параллельного обучения, можно использовать следующие команды для запуска параллельного задания MPI:
Параллельное обучение на том же компьютере с Linux:
mpiexec --npernode $num_workers $cntk configFile=$configПараллельное обучение на том же компьютере с Windows:
mpiexec -n %num_workers% %cntk% configFile=%config%Параллельное обучение на нескольких вычислительных узлах с помощью Linux:
Шаг 1. Создание файла узла $hostfile с помощью избранного редактора
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Где name_of_node(n) — это просто DNS-имя или IP-адрес рабочего узла.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Параллельное обучение между несколькими вычислительными узлами с Помощью Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
где $cntk следует ссылаться на путь исполняемого файла CNTK ($x это способ замены переменных среды Оболочкой Linux, эквивалентной %x% в оболочке Windows).
4.2. Выполнение параллельного обучения с помощью Python
Примеры распределенного обучения для CNTK версии 2 с Python можно найти здесь:
Учитывая скрипт training.py Python CNTK версии 2, можно использовать следующие команды для запуска параллельного задания MPI:
Параллельное обучение на том же компьютере с Linux:
mpiexec --npernode $num_workers python training.pyПараллельное обучение на том же компьютере с Windows:
mpiexec -n %num_workers% python training.pyПараллельное обучение на нескольких вычислительных узлах с помощью Linux:
Шаг 1. Создание файла узла $hostfile с помощью избранного редактора
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Где name_of_node(n) — это просто DNS-имя или IP-адрес рабочего узла.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Параллельное обучение между несколькими вычислительными узлами с Помощью Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
5 Data-Parallel Обучение с 1-разрядной версией ХУК
CNTK реализует 1-разрядный метод JSON [1]. Этот метод позволяет распределить каждый мини-батт над рабочими K ролей. Полученные частичные градиенты затем обмениваются и агрегируются после каждого мини-бата. "1 бит" относится к методике, разработанной корпорацией Майкрософт для уменьшения объема данных, которые обмениваются на каждое значение градиента до одного бита.
5.1 Алгоритм 1-разрядного АЛГОРИТМа EUR
Для прямого обмена частичными градиентами после каждого мини-приложения требуется запретительная пропускная способность связи. Чтобы устранить эту проблему, 1-разрядная функция ГРАДиента агрессивно квантует каждое значение градиента... до одного бита (!) на значение. Практически это означает, что большие градиентные значения обрезаются, а небольшие значения искусственно раздуваются. Удивительно, что это не вредит конвергенции, если, и только если, трюк используется.
Трюк заключается в том, что для каждого минибата алгоритм сравнивает квантизованные градиенты (которые обмениваются между рабочими градиентами) с исходными значениями градиента (которые должны были быть заменены). Разница между двумя ( ошибка квантизации) вычисляется и запоминается как остатк. Затем этот остаточный элемент добавляется в следующий мини-батт.
Как следствие, несмотря на агрессивную квантизацию, каждое значение градиента в конечном итоге обменивается полной точностью; просто в задержке. Эксперименты показывают, что, если эта модель сочетается с теплым началом (начальная модель, обученная на небольшом подмножестве обучающих данных без параллелизации), этот метод показал, что приводит к отсутствии или очень небольшой потере точности, позволяя ускорить не слишком далеко от линейного (ограничивающий фактор, который gpu становится неэффективным при вычислении на слишком небольших подпаковках).
Для максимальной эффективности метод должен сочетаться с автоматическим масштабированием минибатч, где каждый раз, а затем тренер пытается увеличить размер минибатча. При оценке небольшого подмножества предстоящих эпох данных тренер выберет самый большой размер мини-пакета, который не вредит конвергенции. Здесь удобно, что CNTK указывает скорость обучения и гиперпараметры импульса в мини-батч-размере не зависят от скорости обучения.
5.2. Использование 1-разрядного МЕТОДА DNS в BrainScript
У самого 1-разрядного JSON нет параметра, отличного от включения и после которого должна начинаться эпоха. Кроме того, необходимо включить автоматическое масштабирование мини-батов. Эти параметры настраиваются путем добавления следующих параметров в блок EUR:
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Обратите внимание, что Data-Parallel JSON также можно использовать без 1-разрядной квантизации. Однако в типичных сценариях, особенно в сценариях, в которых каждый параметр модели применяется только один раз, как для DNN для канала, это не будет эффективным из-за высоких потребностей в пропускной способности связи.
В разделе 2.2.3 ниже показаны результаты 1-разрядного НАБОРА ДАННЫХ в задаче распознавания речи по сравнению с методом Block-Momentum, описанным далее. Оба метода не имеют или почти не теряют точность при почти линейном ускорении.
5.3 С помощью 1-разрядного КОДА PYTHON
Чтобы использовать параллельный НАБОР ДАННЫХ в Python(необязательно) с 1-разрядным КОДОМ, пользователю необходимо создать и передать распределенное обучение в тренер:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Изменение num_quantization_bits на 32 во время создания distributed_learner позволяет использовать неквантизированные Data-Parallel JSON. В этом случае нет необходимости в теплом старте.
6 Block-Momentum
Block-Momentum JSON — это реализация "блочного обновления и фильтрации модели", или BMUF, алгоритм, короткий блок-импульс [2].
6.1 Алгоритм Block-Momentum СГД
На следующем рисунке показана процедура в алгоритме Block-Momentum.

6.2. Настройка Block-Momentum DNS в BrainScript
Чтобы использовать Block-Momentum НАБОРе ДАННЫХ, необходимо иметь вложенный блок с именем BlockMomentumSGD в блоке SGD со следующими параметрами:
syncPeriod. Это аналогично томуsyncPeriodModelAveragingSGD, как часто выполняется синхронизация моделей. Значение по умолчанию —BlockMomentumSGD120 000.resetSGDMomentum. Это означает, что после каждой точки синхронизации градиент сглаживания, используемый в локальном КОДЕ, будет иметь значение 0. Значение по умолчанию для этой переменной имеет значение true.useNesterovMomentum. Это означает, что обновление импульса в стиле Nesterov применяется на уровне блока. Дополнительные сведения см. в разделе [2]. Значение по умолчанию для этой переменной имеет значение true.
Блок импульса и скорость блочного обучения обычно устанавливаются автоматически в соответствии с количеством используемых рабочих ролей, т. е.
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
Наш опыт показывает, что эти параметры часто дают аналогичную конвергенцию, как стандартный алгоритм ШИФРОВАНИя до 64 GPU, что является крупнейшим экспериментом, который мы выполнили. Можно также вручную указать эти параметры с помощью следующих параметров:
blockMomentumAsTimeConstantуказывает константу времени фильтра низкого прохода в обновлении модели на уровне блока. Он вычисляется следующим образом:blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRateуказывает скорость блочного обучения.
Ниже приведен пример раздела конфигурации Block-Momentum УПРАВЛЕНИЯ КОНФИГУРАЦИей.
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3. Использование Block-Momentum JSON в BrainScript
1. Повторная настройка параметров обучения
Для достижения аналогичной пропускной способности на рабочую роль необходимо увеличить количество выборок в мини-бэтче пропорционально количеству рабочих ролей. Это можно достичь путем настройки
minibatchSizeилиnbruttsineachrecurrentiterв зависимости от того, используется ли случайная выборка в режиме кадров.Нет необходимости настраивать частоту обучения (в отличие от Model-Averaging ХД, см. ниже).
Рекомендуется использовать Block-Momentum JSON с моделью с теплой запущенной моделью. В наших задачах распознавания речи разумное конвергенция достигается при запуске с начальных моделей, обученных в 24 часах (8,6 миллиона выборок) до 120 часов (43,2 миллиона выборок) с помощью стандартного СТАНДАРТА JSON.
2. Эксперименты ASR
Мы использовали алгоритмы Block-Momentum JSON и Data-Parallel (1-разрядные) АЛГОРИТМы JSON для обучения DNN и LSTM в задаче распознавания речи в 2600 часов, а также сравнивали точность распознавания слов и коэффициенты ускорения. В следующих таблицах и рисунках показаны результаты (*).
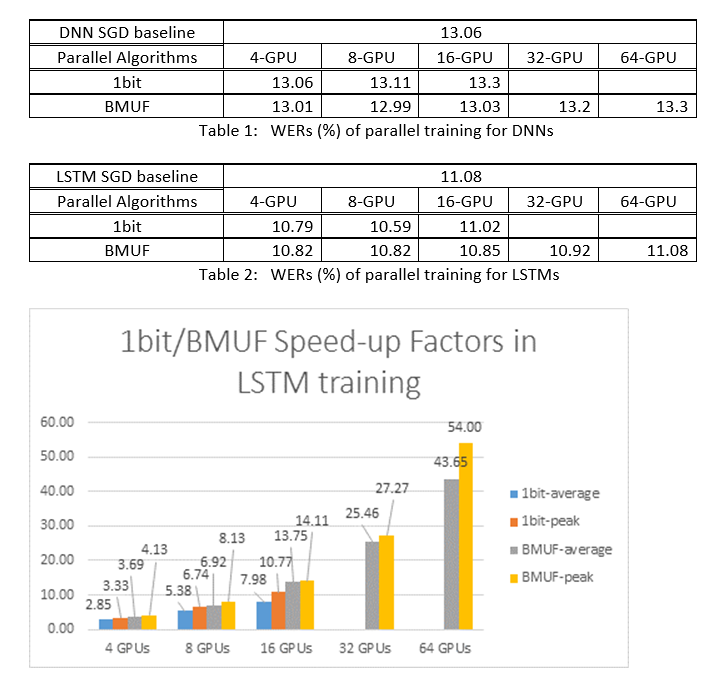
(*): Пиковый коэффициент ускорения: для 1-разрядной СИСТЕМЫ БЕЗОПАСНОСТИ, измеряемой максимальным коэффициентом ускорения (по сравнению с базовым показателем СООТВЕТСТВИЯ), достигнутым в одном мини-пакете; для блок-импульса, измеряемого максимальной скоростью, достигнутой в одном блоке; Средний коэффициент ускорения: затраченное время в базовых показателях JSON, разделенное на наблюдаемое затраченное время. Эти две метрики вводятся из-за задержки операций ввода-вывода в значительной степени влияют на среднее измерение коэффициента ускорения, особенно если синхронизация выполняется на уровне мини-пакета. В то же время максимальный коэффициент ускорения является относительно надежным.
3. Предостережения
Рекомендуется задать
resetSGDMomentumзначение true; в противном случае часто приводит к расхождению критерия обучения. Сброс импульса НАПО до 0 после каждой синхронизации модели фактически отрезает вклад из последних мини-пакетов. Поэтому рекомендуется не использовать большой импульс ФОРМАТОВ. Например, дляsyncPeriod120 000 мы наблюдаем значительную потерю точности, если импульс, используемый для ИСПОЛЬЗОВАНИЯ в ФОРМАТЕ 0,99. Уменьшение импульса в ФОРМАТЕ 0,9, 0,5 или даже его отключение в целом дает аналогичные точности, как это можно сделать с помощью стандартного алгоритма ШИФРОВАНИя.Block-Momentum задержки и распределения обновлений модели из одного блока между последующими блоками. Поэтому необходимо убедиться, что синхронизация моделей выполняется достаточно часто при обучении. Быстрая проверка заключается в использовании
blockMomentumAsTimeConstant. Рекомендуется, чтобы количество уникальных примеровNобучения соответствовало следующему уравнению:N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
Приближение связано со следующими фактами: (1) Блок импульс часто задается как (1-1/num_of_workers); (2) log(1-1/num_of_workers)~=-num_of_workers.
6.4. Использование Block-Momentum в Python
Чтобы включить Block-Momentum в Python, аналогично 1-разрядной системе БЕЗОПАСНОСТИ, пользователю необходимо создать и передать блочный импульс распределенного учащегося в обучение:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Полный функциональный пример см. в примере ConvNet.
7 Model-Averaging МД
Model-Averaging JSON — это реализация алгоритма усреднения модели, подробно описанного в [3,4], без использования естественного градиента. Идея заключается в том, чтобы каждый рабочий процесс обрабатывал подмножество данных, но усреднение параметров модели из каждого рабочего процесса после указанного периода.
Model-Averaging JSON обычно сходится медленнее и к худшему оптимальному, по сравнению с 1-разрядными ЗНАЧЕНИЯМИ и Block-Momentum JSON, поэтому больше не рекомендуется.
Чтобы использовать Model-Averaging ЗАПРОС НА ИСПОЛЬЗОВАНИЕ, необходимо иметь вложенный блок с именем ModelAveragingSGD в SGD блоке со следующими параметрами:
syncPeriodуказывает количество выборок, которые необходимо обработать каждому работнику перед тем, как будет выполнена усреднение модели. Значение по умолчанию — 40 000.
7.1. Использование Model-Averaging JSON в BrainScript
Чтобы обеспечить максимальную эффективность и эффективность Model-Averaging ПАРАМЕТРОВ, пользователям необходимо настроить некоторые гиперпараметров:
minibatchSizeилиnbruttsineachrecurrentiter. Предположимn, что рабочие роли участвуют в конфигурации Model-Averaging JSON, текущая реализация распределенного чтения загружает1/n-th мини-пакета в каждую рабочую роль. Таким образом, чтобы убедиться, что каждая рабочая роль создает ту же пропускную способность, что и стандартный СТАНДАРТ, необходимо увеличить размерnмини-бэтч -свертывания. Для моделей, обученных с помощью случайной выборки в режиме кадров, это можно достичь путем увеличенияminibatchSizeпоnвремени; для моделей обучаются с помощью случайной выборки в режиме последовательности, например RNN, некоторые читатели должны вместо этого увеличиватьсяnbruttsineachrecurrentiterна .nlearningRatesPerSample. Наш опыт свидетельствует о том, что для получения подобной конвергенции, чем стандартный СТАНДАРТ, необходимо увеличитьlearningRatesPerSamplenпо времени. Объяснение можно найти в [2]. Так как скорость обучения увеличивается, требуется дополнительная помощь, чтобы убедиться, что обучение не расходится- и это на самом деле является основным предостережением Model-Averaging JSON. Параметры можно использоватьAutoAdjustдля перезагрузки предыдущей лучшей модели, если наблюдается увеличение критерия обучения.теплое начало. Обнаруживается, что Model-Averaging СТАНДАРТНАЯ ФУНКЦИЯ ЗАПОЛНЕНИЯ обычно сходится лучше, если она запускается из начальной модели, которая обучена стандартным алгоритмом ШИФРОВАНИЯ (без параллелизации). В наших задачах распознавания речи разумное конвергенция достигается при запуске с начальных моделей, обученных в 24 часах (8,6 миллиона выборок) до 120 часов (43,2 миллиона выборок) с помощью стандартного СТАНДАРТА JSON.
Ниже приведен пример раздела конфигурации ModelAveragingSGD .
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2. Использование Model-Averaging JSON в Python
Эта работа выполняется.
8 Data-Parallel обучение с помощью сервера параметров
Сервер параметров — это широко используемая платформа в распределенном машинном обучении [5][6][7]. Наиболее важным преимуществом является асинхронное параллельное обучение со многими рабочими ролями. Он представляет сервер параметров в качестве распределенного хранилища моделей. Вместо прямого использования примитивов AllReduce для синхронизации обновлений параметров между рабочими ролями платформа сервера параметров предоставляет пользователям такие интерфейсы, как Add и Get, чтобы позволить локальным рабочим роям обновлять и извлекать глобальные параметры с сервера параметров. Таким образом, местные работники не должны ждать друг друга во время процесса обучения, что экономит много времени, особенно если рабочий номер большой.
Кроме того, так как серверы параметров — это распределенная платформа, в которых хранятся параметры модели, рабочие роли могут получать только те параметры, которые им нужны во время процесса обучения мини-пакетной службы, это обеспечивает очень хорошую гибкость в проектировании распределенного метода обучения, а также повышает эффективность при проведении обучения с разреженными обновлениями модели. В этом выпуске мы сначала сосредоточимся на асинхронном параллельном обучении. Далее мы предоставим дополнительные сведения о том, как использовать платформу сервера параметров для эффективного обучения модели с разреженными обновлениями.
8.1 Использование Data-Parallel ASGD
- Чтобы использовать серверы параметров для асинхронного ПАКЕТА УПРАВЛЕНИЯ (abbr. as ASGD), необходимо создать CNTK с поддержкой Multiverso, Multiverso — это общая платформа сервера параметров для задачи распределенного машинного обучения, разработанной группой Microsoft Research Asia.
Clone Code: клонируйте код в корневую папку CNTK с помощью:
git submodule update --init Source/Multiverso
Linux: выполните сборку с--asgd=yesпомощью процесса настройки.Windows: добавьтеCNTK_ENABLE_ASGDв системную среду и задайте значениеtrue
- теплое начало. В некоторых случаях лучше начать обучение асинхронной модели из начальной модели (которая обучена стандартным алгоритмом ШИФРОВАНИЯ). В некотором смысле асинхронный МЕТОД БЕЗОПАСНОСТИ обеспечивает больший шум для обучения из-за задержки обновлений от асинхронизма среди работников. Некоторые модели очень чувствительны к такому шуму в начале, что может привести к расколу обучения моделей. В таких обстоятельствах требуется теплый старт .
8.2. Настройка Data-Parallel ASGD в BrainScript
Чтобы использовать Data-Parallel ASGD в CNTK, необходимо иметь вложенный блок DataParallelASGD в блоке СООТВЕТСТВИЯ со следующими параметрами.
-
syncPeriodPerWorkers. Он указывает количество выборок, которые каждый рабочий процесс необходимо обработать перед взаимодействием с серверами параметров. Значение по умолчанию — 256. Рекомендуется использовать мини-пакет. Очевидно, что частое синхронизация приведет к значительной высокой стоимости общения. В нашем тесте не обязательно устанавливать значение 1 в большинстве случаев.
-
usePipeline. Он указывает, включен ли конвейер извлечения модели и локальных вычислений. Включение конвейера значительно увеличит общую пропускную способность обучения, так как она будет скрывать некоторые или все затраты на обмен данными. Однако иногда это может замедлить конвергентную скорость, так как дополнительная задержка будет введена путем добавления конвейера. В целом время часов будет сохранено в большинстве случаев с конвейером.
-
AdjustLearningRateAtBeginning. Согласно недавно опубликованному документу [5], обучение ASGD является менее стабильным, и он требует использования гораздо меньшей скорости обучения, чтобы избежать случайных взрывов потери обучения, поэтому процесс обучения становится менее эффективным. Однако мы обнаружили, что использование более низкой скорости обучения не требуется для всех задач. И для этих задач, чувствительных к началу, мы начинаем обучение с небольшой скоростью обучения и постепенно увеличиваем его на начальном этапе процесса обучения, пока не достигнет начальной скорости обучения, используемой в обычном ФОРМАТЕ. Таким образом, окончательная точность будет соответствовать ФОРМАТу JSON, а скорость ASGD . Поэтому мы предоставляем этот вариант для пользователей ASGD, чтобы использовать этот трюк. Это вложенный блок в DataParallelASGD с двумя параметрами: adjustCoefficient и adjustNBMiniBatch. Логика заключается в том, что скорость обучения начинается с adjustCoefficient начальной скорости обучения JSON и увеличивается за счет корректировкиcoefficient начальной скорости обучения JSON каждый мини-пакеты adjustNBMiniBatch .
Ниже приведен пример раздела конфигурации DataParallelASGD .
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3. Настройка Data-Parallel ASGD в Python
Эта работа выполняется.
8.4 Эксперименты
На следующем рисунке показаны эксперименты по тестированию ASGD с набором данных CIFAR-10. Модель, используемая в этом эксперименте, представляет собой 20-слойную resNet. Асинхронный алгоритм снижает затраты на ожидание всех рабочих узлов. В этом случае ASGD явно быстрее, чем синхронные алгоритмы, такие как MA и SSGD. *В экспериментах все параллельные режимы синхронизируют параметры каждой итерации (мини-пакетное обновление). А для SSGD мы использовали 32-разрядные обновления параметров. Асинхронный алгоритм получает значительное преимущество с точки зрения пропускной способности обучения, измеряемой скоростью обработки выборки, особенно если число рабочего узла достигает 16.
 Рис. 2.4. Ускорение различных методов обучения
Рис. 2.4. Ускорение различных методов обучения
Ссылки (на английском языке)
[1] F. Seide, Hao Fu, Jasha Droppo, Gang Li и Dong Yu, "1-разрядный стохастический градиентный спуск и его применение к параллельному распределенного обучения речи DNN", в proceedings of Interspeech, 2014.
[2] K. Chen и Q. Huo, "Масштабируемое обучение машин глубокого обучения путем добавочного обучения блок-обучения с помощью внутриблоковой параллельной оптимизации и фильтрации по блочному обновлению модели", в proceedings of ICASSP, 2016.
[3] М. Зинхиме, М. Веймер, Л. Ли и А. Дж. Смола, "Параллелизованный стохастический градиентный спуск", в ходе разбирательства достижений в NIPS, 2010, pp. 2595–2603.
[4] Д. Пови, X. Чжан и С. Худанпур, "Параллельное обучение DNN с естественным градиентом и усреднением параметров", в разделе "Материалы Международной конференции по представлению обучения, 2014 год.
[5] Chen J, Monga R, Bengio S, et al. Revisiting Distributed Synchronous JSON. ICLR, 2016.
[6] Дин Джеффри, Грег Коррадо, Раджат Монга, Кай Чэнь, Маттие Девин, Марк Мао, Эндрю Старший и др. Крупномасштабные распределенные глубокие сети. В прогрессе в нейронных системах обработки информации, pp. 1223-1231. 2012.
[7] Ли Му, Ли Чжоу, Зичао Ян, Аарон Ли, Фей Ся, Дэвид Г. Андерсен и Александр Смола. "Сервер параметров для распределенного машинного обучения". В Мастерской NIPS в Big Learning, vol. 6, p. 2. за 2013 год.