Планируйте, масштабируйте и обслуживайте критически важное для бизнеса решение шлюза
Эта статья предназначена для всех, кто планирует развернуть локальный шлюз данных в критически важном для бизнеса сценарии. Локальный шлюз данных критически важен для бизнеса, если он необходим для нормальной работы вашего бизнеса и обрабатывает критически важные для бизнеса данные.
Если критически важные для бизнеса шлюзы не управляются должным образом, вы можете столкнуться с неудачными запросами или низкой производительностью. При правильном планировании, масштабировании и поддержании решения шлюза, важного для бизнеса, вероятность проблемы, влияющей на бизнес, может быть сведена к минимуму.
Терминология
В этой статье используются следующие важные термины:
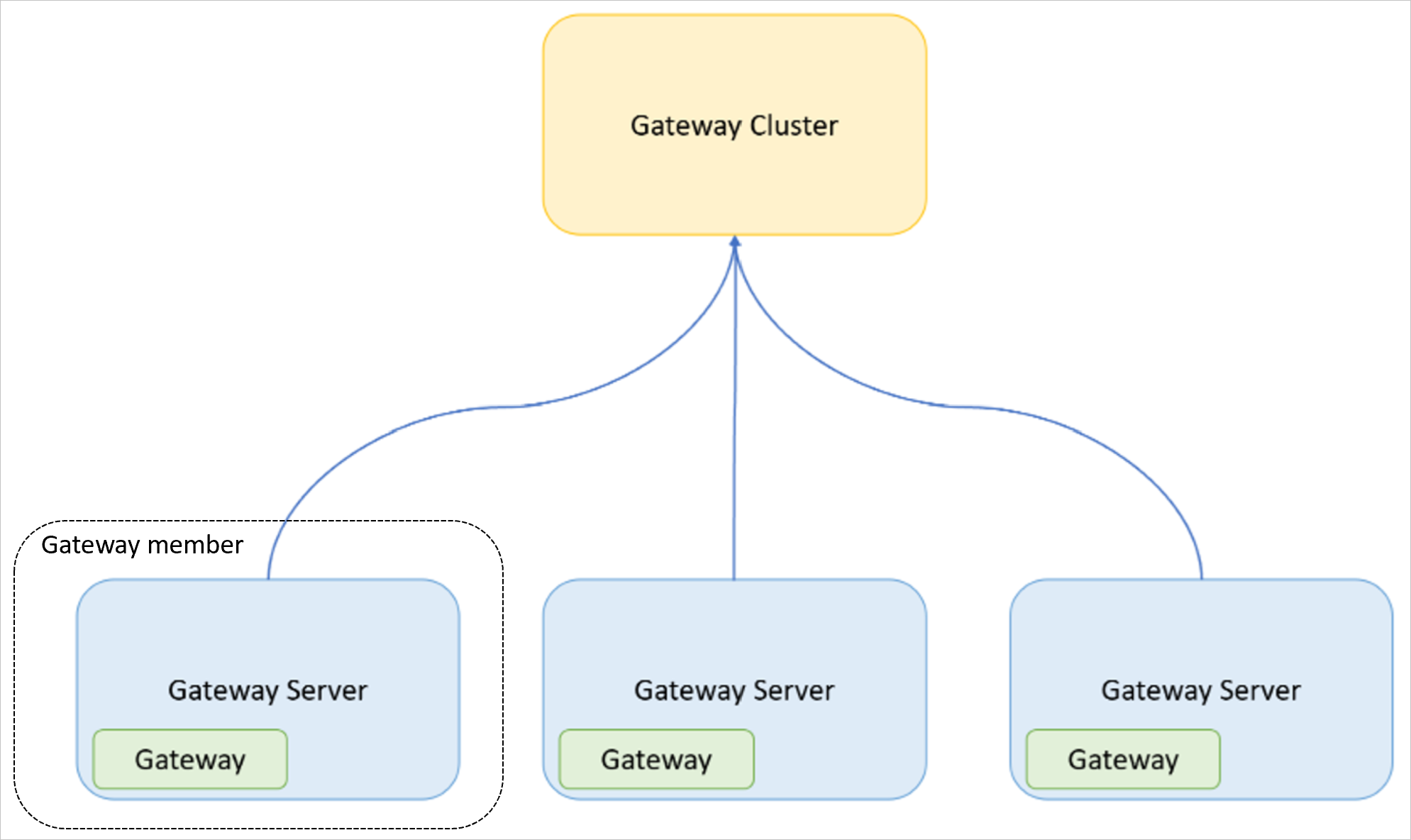
- Шлюз — приложение локального шлюза данных, установленное на компьютере.
- Сервер шлюза — компьютер Windows (виртуальная машина или физический компьютер или сервер), на котором установлено приложение локального шлюза данных.
- Кластер шлюзов — набор шлюзов, которые работают вместе (и могут быть сбалансированы по нагрузке).
- Участник шлюза — шлюз, являющийся частью кластера шлюзов.
На следующем изображении показана взаимосвязь между понятиями, определенными выше.
Рекомендации по критически важным для бизнеса шлюзам
Шлюзы, критически важные для бизнеса, должны быть правильно развернуты и правильно управляться, чтобы обеспечить высокий уровень доступности, хорошую производительность и поддерживаемую масштабируемость. Неправильное развертывание шлюзов может привести к снижению производительности, неудачным запросам и трудностям в диагностике потенциальных проблем. Это также может помешать вам масштабировать шлюзы по мере роста необходимости их использования.
Чтобы обеспечить оптимальную масштабируемость, производительность и пропускную способность, следуйте рекомендациям в следующих разделах.
Знание всех ключей восстановления шлюза
Убедитесь, что все ключи восстановления шлюза известны и хранятся в безопасном месте. Без ключа восстановления невозможно восстановить шлюзы или перейти на более раннюю версию. Это ограничение по проектированию. Если вы потеряете ключи восстановления, единственный вариант — создать новые шлюзы и воссоздать источники данных. Кроме того, невозможно добавлять новые шлюзы в кластер без ключа восстановления, что ограничит масштабируемость в будущем.
Храните ключи восстановления в безопасном месте так же, как вы хранили бы административные учетные данные, например в сейфе для паролей, доступ к которому имеют только авторизованные администраторы.
Если вы в настоящее время не знаете все ключи восстановления вашего шлюза, это представляет собой существенный коммерческий риск. Немедленно создайте новые кластеры шлюзов и начните перенос рабочих нагрузок на кластеры шлюзов.
Рабочие нагрузки разработки и критически важные для бизнеса рабочие нагрузки
Отделите рабочие нагрузки разработки от критически важных для бизнеса, настроив один или несколько кластеров шлюзов разработки и один или несколько кластеров рабочих шлюзов, как описано ниже.
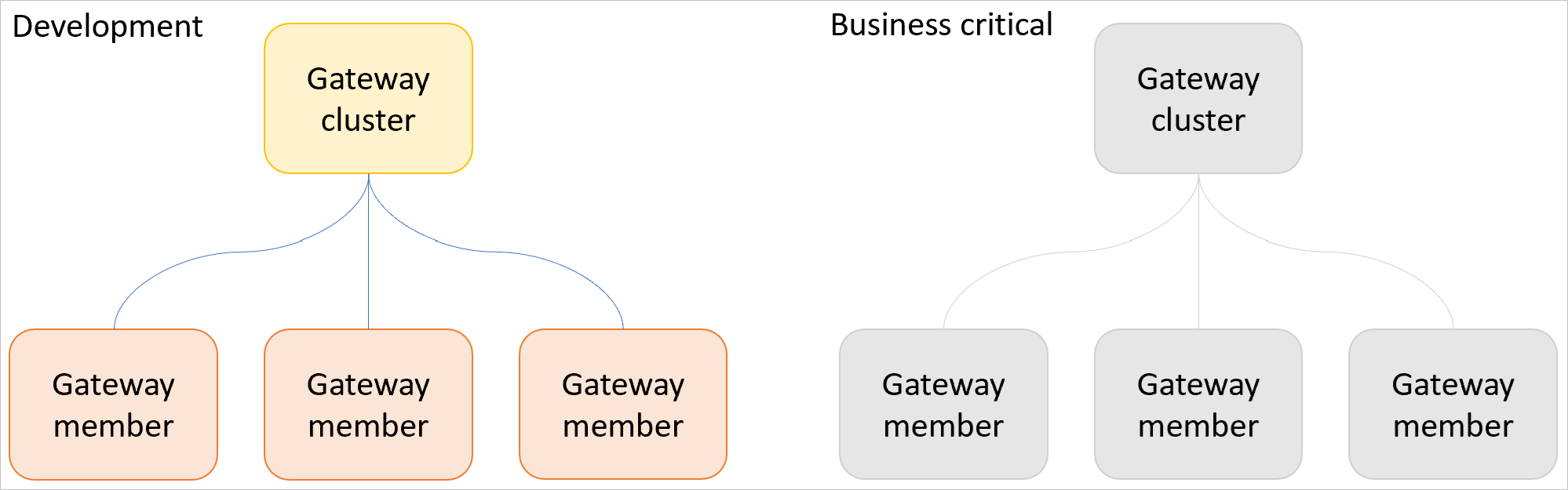
Используйте кластер шлюза разработки для тестирования новых семантических моделей, отчетов, запросов и т. д. После проверки новой рабочей нагрузки перенесите ее в критически важный для бизнеса кластер шлюзов. Этот процесс предотвращает влияние новых, непроверенных или экспериментальных рабочих нагрузок на производительность рабочих нагрузок.
Также используйте кластеры шлюзов разработки для тестирования новых обновлений шлюзов перед применением обновлений к критически важным для бизнеса кластерам шлюзов. Новые обновления шлюза должны быть развернуты в течение как минимум 24 часов в кластерах шлюзов разработки, прежде чем они будут использованы в критически важных для бизнеса кластерах шлюзов.
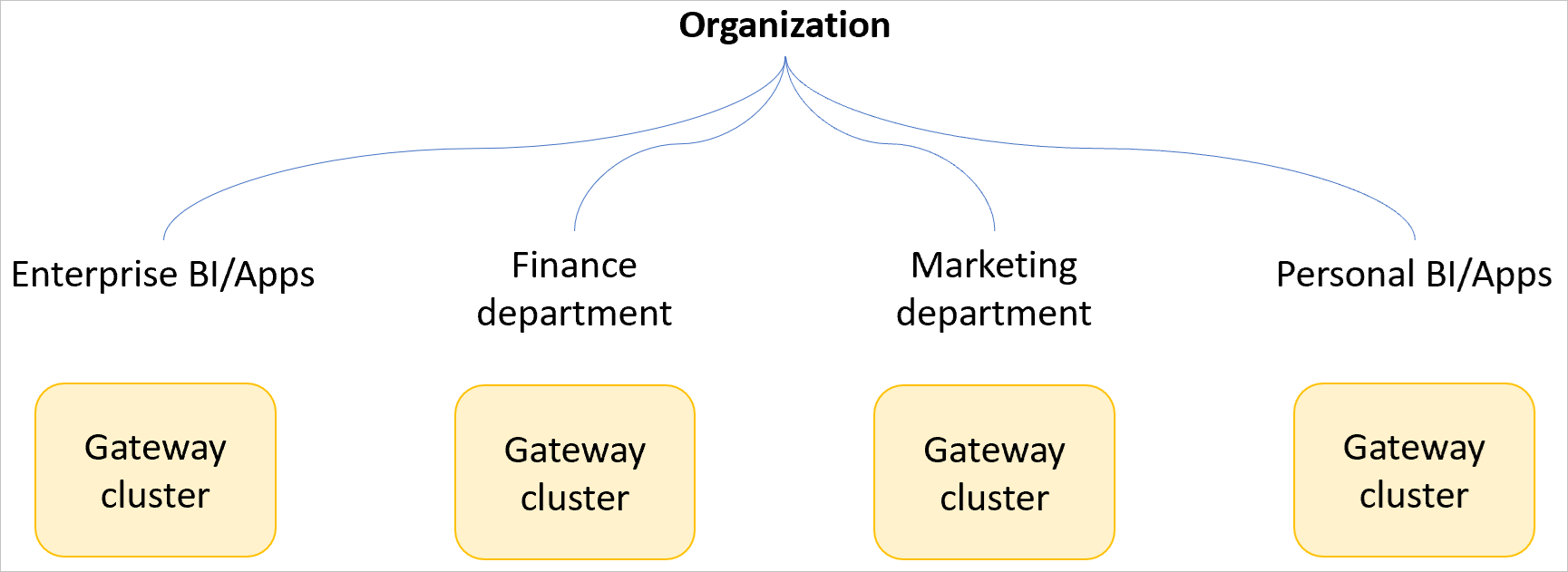
Используйте несколько кластеров шлюзов
Если вы создаете кластер шлюзов для большого количества пользователей в вашей организации, вам необходимо создать несколько кластеров шлюзов на основе бизнес-подразделений или подразделений меньшего размера, чтобы ограничить любое потенциальное влияние на производительность небольшим подмножеством пользователей.
Не рекомендуется использовать один критически важный для бизнеса кластер шлюзов для всей компании (если только это не малое предприятие). В сценарии кластера с одним шлюзом один пользователь мог бы, гипотетически, отправить запрос, который оказывает значительное влияние на производительность всего трафика через шлюз. Если шлюз используется во всей компании, влияние на производительность может затронуть всю компанию. Кроме того, когда кластер шлюза используется во всей компании, вам было бы сложнее определить, какой запрос может вызывать проблемы с производительностью при использовании кластера с помощью функции мониторинга производительности шлюза.
Использование функций высокого уровня доступности шлюза и балансировки нагрузки
Всегда используйте функции высокого уровня доступности шлюза и балансировки нагрузки для любого критически важного для бизнеса кластера шлюзов.
- Высокая доступность. Устраняет единую точку отказа.
- Балансировка нагрузки. Автоматически распределяет рабочую нагрузку между всеми серверами шлюза в кластере.
Настройте как минимум два шлюза на кластер шлюзов на случай, если в шлюзе по какой-либо причине происходит сбой. Эта настройка гарантирует, что сбой одного шлюза не повлечет сбой всего кластера шлюзов. Кроме того, на шлюзах можно включить ограничения ЦП, памяти, параллелизма, чтобы лучше распределить нагрузку по кластеру шлюзов.
Планирование и поддержание масштабируемости кластера шлюзов
Настройка кластера шлюза с использованием предложенных нами рекомендаций по оборудованию и программному обеспечению гарантирует, что кластер будет работать с хорошей производительностью. Шлюзы, которые не масштабируются должным образом, могут привести к снижению производительности. Есть много факторов, которые вы должны учитывать, чтобы иметь хорошую производительность в кластере шлюза.
Определение технических характеристик оборудования сервера шлюза
Спецификации сервера шлюза (ЦП, память, диск и т. д.) являются важным фактором, поскольку в большинстве случаев преобразования Power Query применяются к данным на сервере шлюза. Таким образом, сервер шлюза должен иметь достаточно ресурсов, памяти и вычислительной мощности для обработки всех преобразований данных.
Когда вам нужно выбрать размер сервера, есть две наиболее важные метрики: память и ЦП. Вам потребуется достаточно памяти и мощности ЦП для обработки этапов преобразования данных Power Query в шлюзе. Важно, чтобы ваш сервер шлюза был достаточно мощным, чтобы обрабатывать самые высокие рабочие нагрузки, которые у вас имеются. Если сервер шлюза не может справиться с рабочей нагрузкой, ваш прямой запрос или обновление данных не удастся. Также важно понимать, сколько запросов выполняется одновременно.
Эти различные параметры запроса влияют на сервер шлюза.
| Тип запроса | Коэффициент ограничения |
|---|---|
| Import | Память |
| DirectQuery | ЦП |
| Live Подключение | ЦП |
Во время импорта необходимо запросить и обработать весь набор данных, для чего потребуется большой объем памяти. Этот импорт часто занимает больше времени. DirectQueries и LiveConnections обычно загружают ЦП. В большинстве случаев прямые запросы выполняются много раз для обработки лишь небольшой части данных. Так как обрабатывается только небольшая часть данных, эти прямые запросы обычно не являются тяжелой задачей памяти. Однако, поскольку запросы выполняются много раз по требованию, это может создавать сильную нагрузку на ЦП.
В зависимости от рабочей нагрузки рассмотрите возможность оптимизации сервера шлюза для использования памяти или ЦП.
Когда нужно масштабировать кластер шлюза
Масштабирование — важный аспект критически важного для бизнеса кластера шлюзов. По мере роста использования кластера шлюза, его необходимо масштабировать, то увеличивая, то уменьшая, чтобы обеспечить хорошую производительность. Мы рекомендуем начать масштабирование кластера шлюзов, если вы ранее масштабировали шлюзы в кластере.
Масштабирование и распределение нагрузки трафика между отдельными узлами в кластере — это сложный процесс, который зависит от каждого отдельного сценария. Хотя не существует окончательной модели, чтобы убедиться, что весь трафик шлюза будет прогнозируемо обслуживаться, ограничения, перечисленные ниже, указывают на необходимость масштабирования. Как правило, рекомендуется масштабировать (добавлять узлы в кластер) предпочтительно для увеличения масштаба (увеличение объема ЦП, ОЗУ или дискового пространства на отдельных узлах). Масштабирование, как правило, более эффективно в целом в способности системы обрабатывать дополнительный трафик. Масштабирование также оказывает положительное влияние на общую пропускную способность кластера, в то время как масштабирование, как правило, не влияет. Если один или несколько узлов шлюза указывают на достижение пороговых значений, описанных ниже, следует настоятельно учитывать масштабирование кластера.
ЦП: ЦП выше 80 % в течение длительного периода времени, однако случайные короткие (менее 5 минут) пики, которые максимальное количество ЦП не являются ненормальными.
ОЗУ: объем доступной памяти меньше 20 % регулярно.
Диск. Свободное место на диске часто опускает до 5 ГБ. Этот спад также может указывать на необходимость настройки каталогов кэширования или spooling более стратегически.
Параллелизм: выполнение более 40 запросов одновременно на одном узле.
Так как обновления и запросы, распределенные между узлами шлюза, могут иметь значительно разные профили, мы также рекомендуем дополнительное внимание размещать на длительных или интенсивных заданиях с большим объемом памяти. Оптимизация запросов в таких случаях может оказать огромное влияние на производительность и масштабируемость, а не только для отдельных отчетов и обновлений, но и на систему в целом. Рекомендуется изолировать обновления, которые задаются в одном выделенном кластере шлюза, чтобы оценить характеристики производительности и выполнить оптимизацию с помощью плана запросов диагностика, свертывания индикаторов и всех других опубликованных рекомендаций по производительности. Эта изоляция сводит к минимуму объем полученных данных и объем необходимых после обработки данных. Эта изоляция также может использоваться в качестве долгосрочной стратегии для последовательности длительных заданий ETL в кластер выделенного шлюза, чтобы сократить количество разных обновлений в организации.
Масштабирование кластера шлюзов
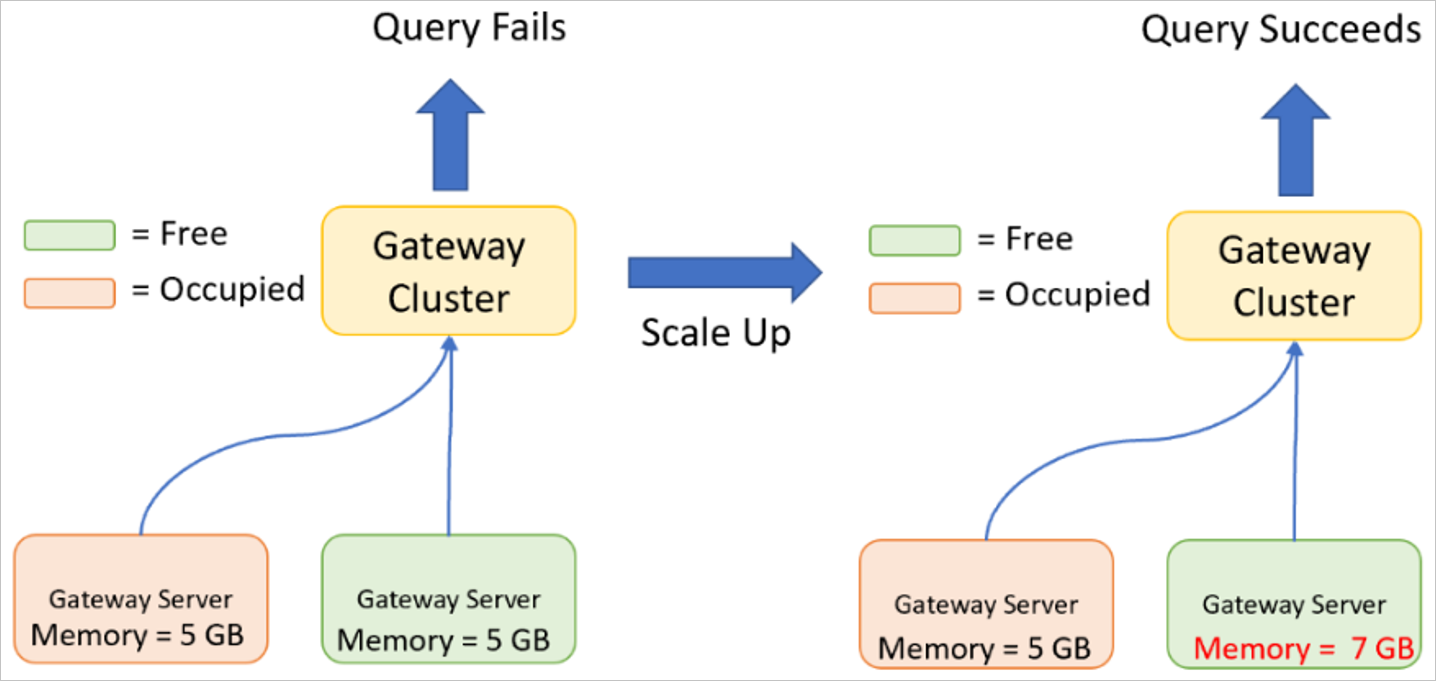
Масштабирование — это когда вы увеличиваете характеристики (ЦП, память, диск и т. д.) серверов шлюза.
Масштабирование может понадобиться, если достигается максимально возможные показатели ЦП или памяти, когда шлюз выполняет один или несколько запросов. Запрос может выполняться только на одном сервере шлюза, поэтому сервер шлюза должен иметь достаточно ресурсов для обработки всего запроса вместе с результирующей данными.
Масштабирование кластера шлюзов
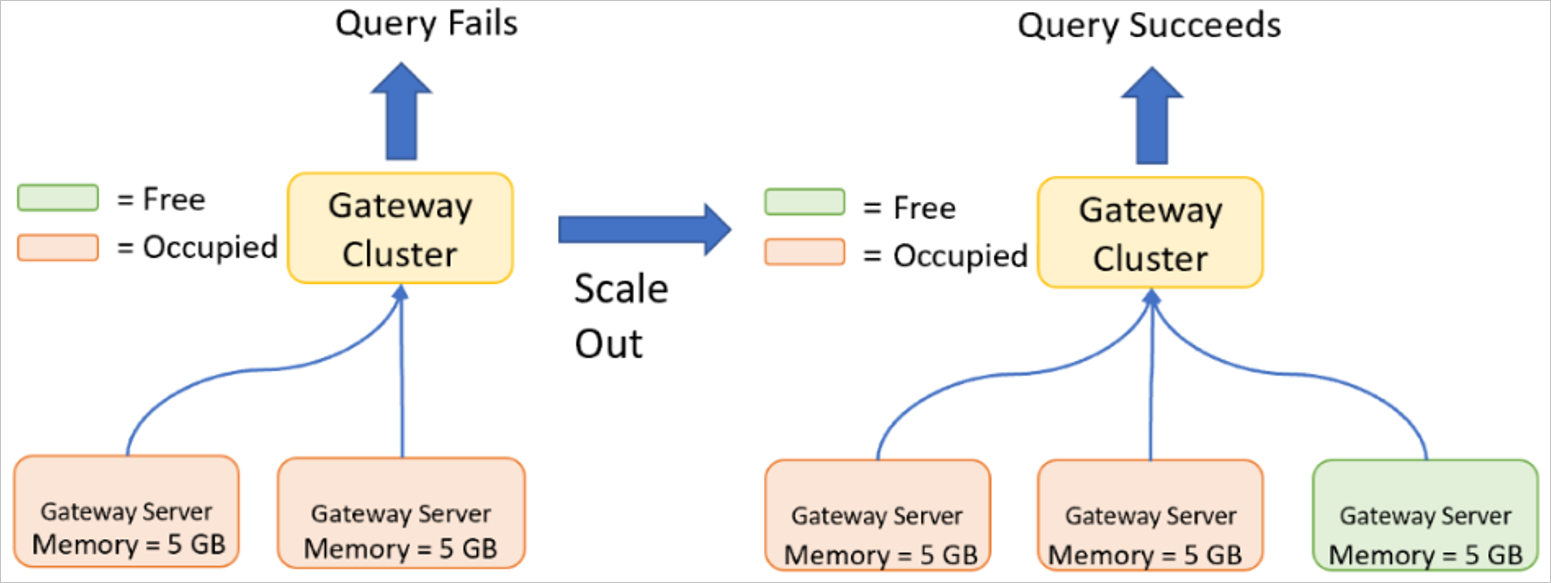
Увеличение масштаба требуется в том случае, если у сервера шлюза уже имеются высокие характеристики (другими словами, для сервера шлюза уже выполнено увеличение масштабирования), или достигнут предел возможностей управления одним сервером шлюза ввиду количества одновременно выполняемых запросов. Широкое увеличение нагрузки на основе всего набора элементов шлюза является хорошим показателем того, что масштабирование кластера путем добавления узлов является правильным курсом действий. При масштабировании кластера шлюза предоставляются определенные пороговые значения, указывающие время масштабирования. Для дополнительных сведений об уменьшении масштабировании см. раздел Использование функций высокого уровня доступности шлюза и балансировки нагрузки.
Масштабирование за счет создания новых кластеров шлюзов
Если использование ресурсов вашего кластера шлюзов велико или исключительно большое количество пользователей полагаются на кластер шлюзов, можно создать новый кластер шлюзов. Затем подмножество рабочей нагрузки можно перенести в новый кластер шлюза. Когда большое количество пользователей полагаются на один кластер шлюзов, вероятность того, что пользователь может отправить запрос, значительно влияющий на производительность всего кластера шлюзов, значительно возрастает.
Исключительно большое количество пользователей, использующих один кластер шлюзов, указывает на необходимость создания нового кластера шлюзов.
Мониторинг и устранение неполадок производительности шлюза
Важно отслеживать общую производительность критически важных для бизнеса шлюзов с помощью функции мониторинга производительности шлюза. Вы также можете использовать эту функцию для устранения проблем с производительностью, выявления узких мест и запросов, влияющих на общую производительность шлюза. Эта функция также является важным инструментом, помогающим определить, когда следует масштабировать кластер шлюза.
Если вы определили, что запрос сильно влияет на шлюз, что приводит к снижению общей производительности, вы можете переписать запрос, чтобы сделать его более эффективным и свести к минимуму влияние на снижение производительности.
Если корпорацией Майкрософт обнаружена низкая производительность, вызванная шлюзом или компонентом, связанным со шлюзом, например перегруженной емкостью Power BI Premium, то перегруженный компонент необходимо устранить путем масштабирования или снижения нагрузки. Корпорация Майкрософт не исследует снижение производительности при перегрузке шлюза или компонента, связанного со шлюзом.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по