Шаблоны данных, ориентированные на облако
Совет

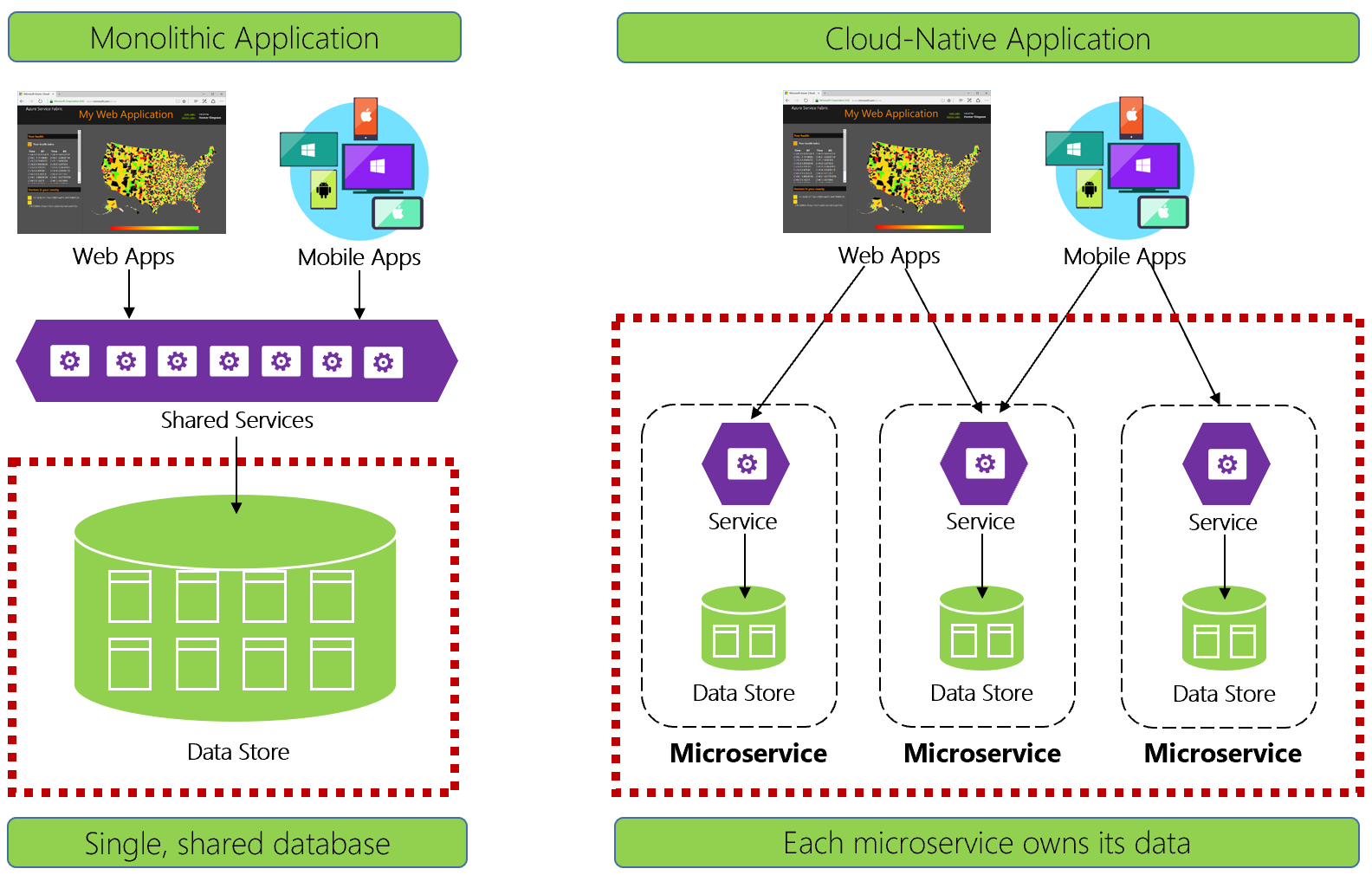
Рис. 5-1.
Одна база данных для каждой микрослужбы
В рамках этой модели:
Такая архитектура позволяет каждой микрослужбе реализовывать хранилище данных, которое оптимально подходит для рабочей нагрузки, потребностей в хранении данных и особенностей чтения и записи. Возможные типы хранилищ данных включают в себя реляционное хранилище, хранилище документов, хранилище пар "ключ — значение" и хранилище на основе графов.
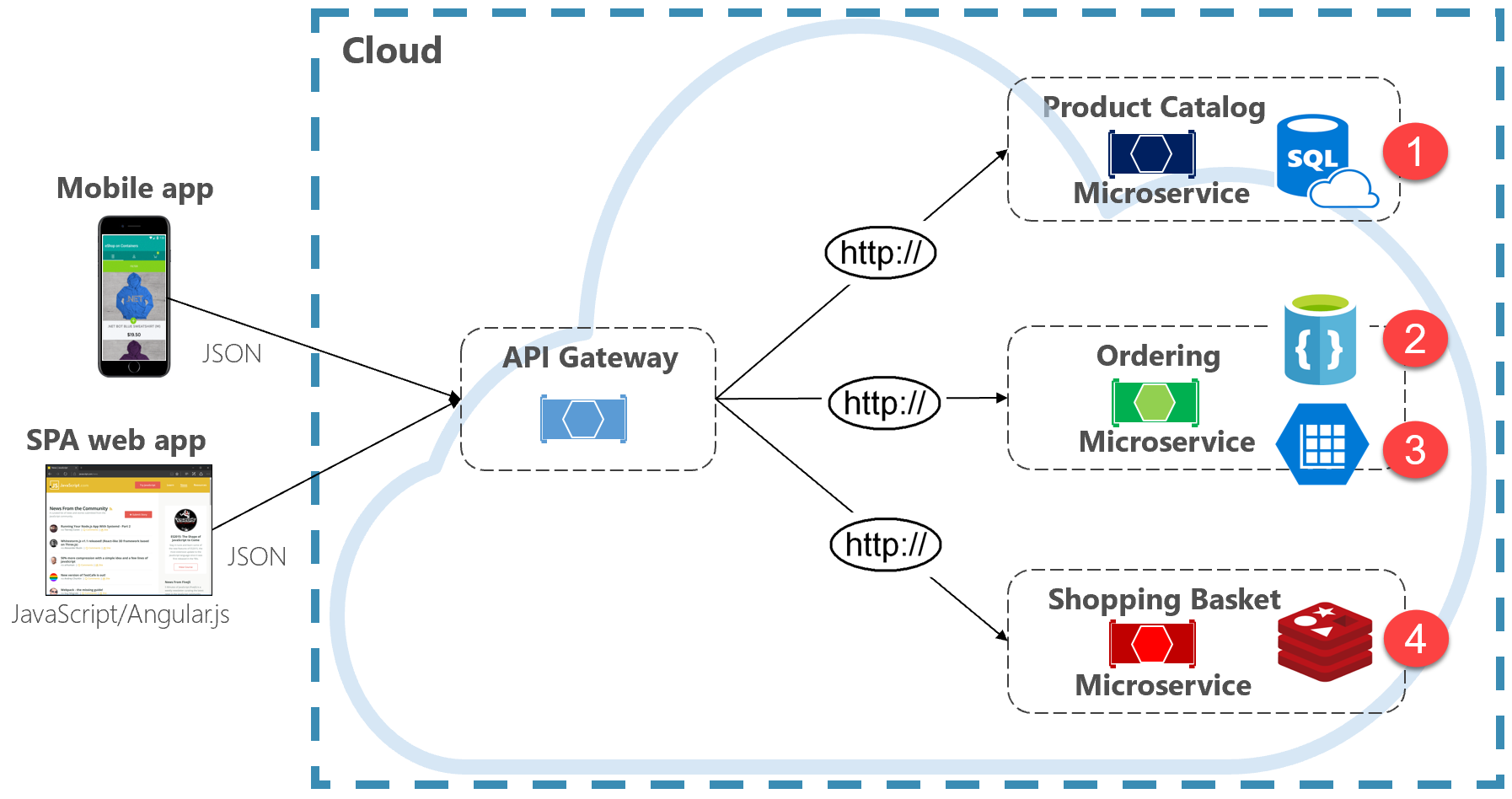
Рис. 5-2. Polyglot persistence
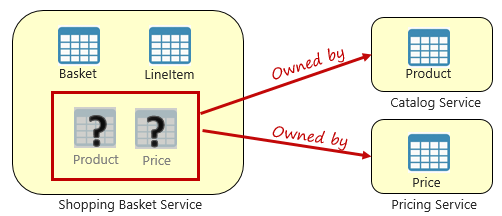
Рис. 5-3.
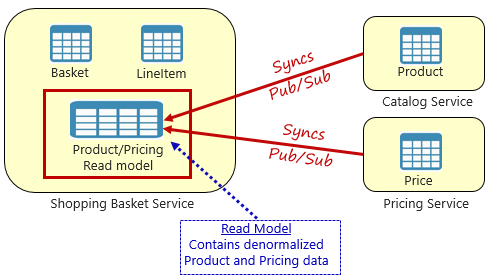
Рис. 5-4. Materialized View Pattern
Распределенные транзакции
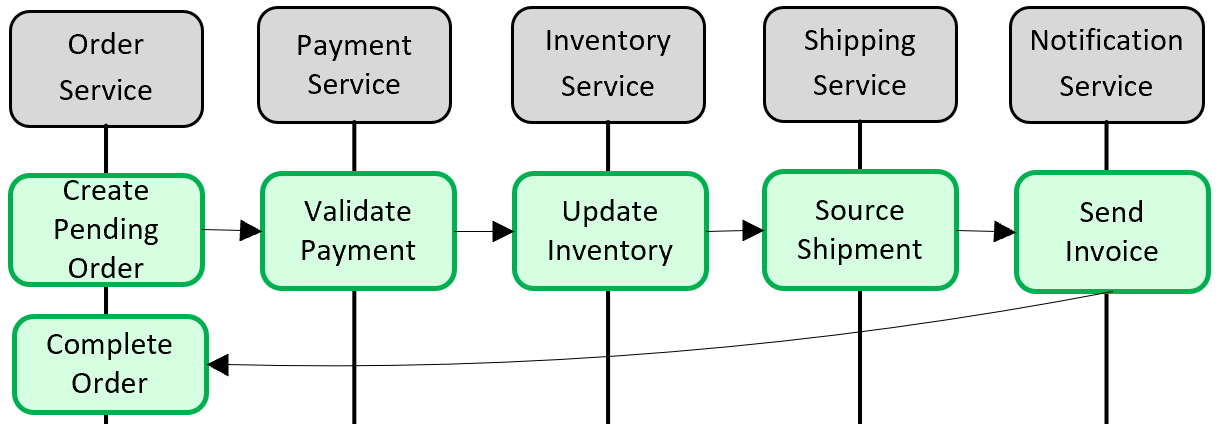
Рис. 5-5.

Рис. 5-6. Откат транзакции
Использование томов данных
CQRS

Рис. 5-7. Реализация IDPS
Для процессов чтения можно применить схему, оптимизированную для запросов, а для процессов записи — другую схему, оптимизированную для обновлений.
Источник событий
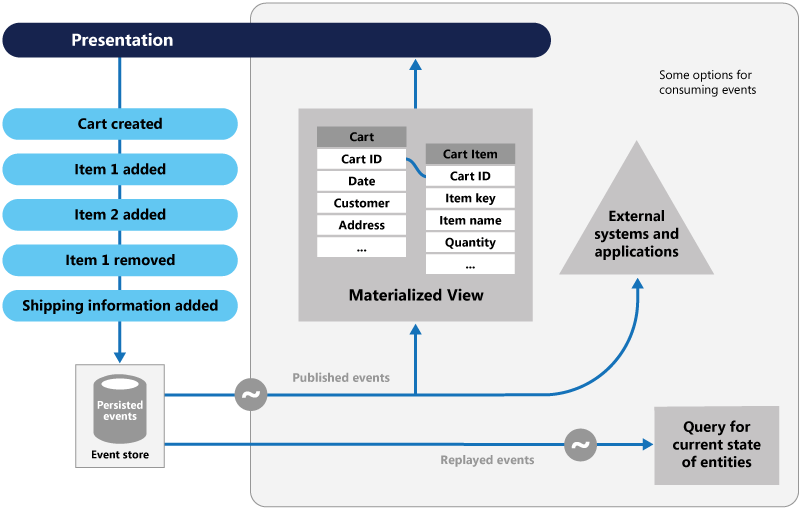
Рис. 5-8. Источник событий
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по