Рекомендации по производительности ДЛЯ EF 4, 5 и 6
Дэвид Obando, Эрик Деттингер и другие
Опубликовано: апрель 2012 г.
Последнее обновление: май 2014 г.
1. Введение
Платформы сопоставления объектов — это удобный способ предоставления абстракции для доступа к данным в объектно-ориентированном приложении. Для приложений .NET рекомендуется использовать O/RM корпорации Майкрософт в Entity Framework. Однако с любой абстракцией производительность может стать проблемой.
Этот технический документ был написан, чтобы показать рекомендации по производительности при разработке приложений с помощью Entity Framework, чтобы дать разработчикам представление о внутренних алгоритмах Entity Framework, которые могут повлиять на производительность, и предоставить советы по изучению и улучшению производительности в своих приложениях, использующих Entity Framework. Есть ряд хороших тем о производительности, уже доступных в Интернете, и мы также пытались указать на эти ресурсы, где это возможно.
Производительность является сложной темой. Этот технический документ предназначен как ресурс для принятия решений, связанных с производительностью для приложений, использующих Entity Framework. Мы включили некоторые тестовые метрики для демонстрации производительности, но эти метрики не предназначены в качестве абсолютных показателей производительности, которые вы увидите в приложении.
В практических целях в этом документе предполагается, что Entity Framework 4 выполняется в .NET 4.0 и Entity Framework 5 и 6 выполняются в .NET 4.5. Многие улучшения производительности, сделанные для Entity Framework 5, находятся в основных компонентах, которые поставляются с .NET 4.5.
Entity Framework 6 является выпуском вне полосы и не зависит от компонентов Entity Framework, которые поставляются с .NET. Entity Framework 6 работает как над .NET 4.0, так и .NET 4.5 и может предложить большую производительность для тех, кто не обновился с .NET 4.0, но хотите, чтобы последние биты Entity Framework в своем приложении. Когда этот документ упоминание Entity Framework 6, он ссылается на последнюю версию, доступную на момент написания этой статьи: версия 6.1.0.
2. Холодное и теплое выполнение запросов
Самый первый раз, когда любой запрос выполняется в отношении данной модели, Entity Framework выполняет большую работу за кулисами для загрузки и проверки модели. Мы часто называем этот первый запрос "холодным" запросом. Дальнейшие запросы к уже загруженной модели называются "теплыми" запросами и гораздо быстрее.
Давайте рассмотрим высокоуровневое представление о том, где время тратится при выполнении запроса с помощью Entity Framework, и посмотрим, где улучшаются возможности Entity Framework 6.
Выполнение первого запроса — холодный запрос
| Запись пользователя кода | Действие | Влияние на производительность EF4 | Влияние на производительность EF5 | Влияние на производительность EF6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Создание контекста | Средняя | Средний | Низкий |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Создание выражения запроса | Низкая | Низкая | Низкая |
var c1 = q1.First(); |
Выполнение запроса LINQ | — загрузка метаданных: высокая, но кэшированная — Представление поколения: потенциально очень высокий, но кэшированный — оценка параметров: средний — перевод запросов: средний — поколение материализатора: средний, но кэшированный — Выполнение запроса базы данных: потенциально высокий + Подключение ion. Открыть + Command.ExecuteReader + DataReader.Read Материализация объектов: средний — поиск удостоверений: средний |
— загрузка метаданных: высокая, но кэшированная — Представление поколения: потенциально очень высокий, но кэшированный — оценка параметров: низкая — перевод запросов: средний, но кэшированный — поколение материализатора: средний, но кэшированный — Выполнение запроса базы данных: потенциально высокий (более лучшие запросы в некоторых ситуациях) + Подключение ion. Открыть + Command.ExecuteReader + DataReader.Read Материализация объектов: средний — поиск удостоверений: средний |
— загрузка метаданных: высокая, но кэшированная — Просмотр поколения: средний, но кэшированный — оценка параметров: низкая — перевод запросов: средний, но кэшированный — поколение материализатора: средний, но кэшированный — Выполнение запроса базы данных: потенциально высокий (более лучшие запросы в некоторых ситуациях) + Подключение ion. Открыть + Command.ExecuteReader + DataReader.Read Материализация объектов: средний (быстрее, чем EF5) — поиск удостоверений: средний |
} |
Подключение. Закрыть | Низкая | Низкая | Низкая |
Выполнение второго запроса — теплый запрос
| Запись пользователя кода | Действие | Влияние на производительность EF4 | Влияние на производительность EF5 | Влияние на производительность EF6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Создание контекста | Средняя | Средний | Низкий |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Создание выражения запроса | Низкая | Низкая | Низкая |
var c1 = q1.First(); |
Выполнение запроса LINQ | — подстановка загрузки - Просмотр — оценка параметров: средний — поиск перевода - Поиск создания — Выполнение запроса базы данных: потенциально высокий + Подключение ion. Открыть + Command.ExecuteReader + DataReader.Read Материализация объектов: средний — поиск удостоверений: средний |
— подстановка загрузки - Просмотр — оценка параметров: низкая — поиск перевода - Поиск создания — Выполнение запроса базы данных: потенциально высокий (более лучшие запросы в некоторых ситуациях) + Подключение ion. Открыть + Command.ExecuteReader + DataReader.Read Материализация объектов: средний — поиск удостоверений: средний |
— подстановка загрузки — Просмотр — оценка параметров: низкая — поиск перевода - Поиск создания — Выполнение запроса базы данных: потенциально высокий (более лучшие запросы в некоторых ситуациях) + Подключение ion. Открыть + Command.ExecuteReader + DataReader.Read Материализация объектов: средний (быстрее, чем EF5) — поиск удостоверений: средний |
} |
Подключение. Закрыть | Низкая | Низкая | Низкая |
Существует несколько способов снижения производительности холодных и теплых запросов, и мы рассмотрим их в следующем разделе. В частности, мы рассмотрим снижение затрат на загрузку модели в холодных запросах с помощью предварительно созданных представлений, которые должны помочь облегчить проблемы производительности, возникающие во время создания представлений. Для теплых запросов мы рассмотрим кэширование плана запросов, без отслеживания запросов и различные параметры выполнения запросов.
2.1 Что такое поколение представлений?
Чтобы понять, что такое поколение представлений, необходимо сначала понять, что такое "Представления сопоставления". Представления сопоставления — это исполняемые представления преобразований, указанных в сопоставлении для каждого набора сущностей и связи. Внутри этих представлений сопоставления формируется CQTs (канонические деревья запросов). Существует два типа представлений сопоставления:
- Представления запросов: это преобразование, необходимое для перехода от схемы базы данных к концептуальной модели.
- Представления обновления: это преобразование, необходимое для перехода от концептуальной модели к схеме базы данных.
Имейте в виду, что концептуальная модель может отличаться от схемы базы данных различными способами. Например, для хранения данных для двух разных типов сущностей может использоваться одна таблица. Наследование и нетривиальные сопоставления играют роль в сложности представлений сопоставления.
Процесс вычисления этих представлений на основе спецификации сопоставления — это то, что мы называем поколением представлений. Создание представлений может происходить динамически при загрузке модели или во время сборки с помощью предварительно созданных представлений; последний сериализуется в виде инструкций Entity SQL в файл C# или VB.
При создании представлений они также проверяются. С точки зрения производительности подавляющее большинство затрат на создание представления фактически является проверкой представлений, что гарантирует, что соединения между сущностями имеют смысл и имеют правильную карта inality для всех поддерживаемых операций.
При выполнении запроса по набору сущностей запрос объединяется с соответствующим представлением запроса, а результат этой композиции выполняется с помощью компилятора плана, чтобы создать представление запроса, который может понять резервное хранилище. Для SQL Server окончательный результат этой компиляции будет инструкцией T-SQL SELECT. При первом выполнении обновления набора сущностей представление обновления выполняется через аналогичный процесс, чтобы преобразовать его в инструкции DML для целевой базы данных.
2.2 Факторы, влияющие на производительность создания представлений
Производительность шага создания представления зависит не только от размера модели, но и от того, как связана модель. Если две сущности подключены через цепочку наследования или ассоциацию, они, как сообщается, подключены. Аналогично, если две таблицы подключены через внешний ключ, они подключены. По мере увеличения количества подключенных сущностей и таблиц в схемах стоимость создания представления увеличивается.
Алгоритм, используемый для создания и проверки представлений, является экспоненциальным в худшем случае, хотя мы используем некоторые оптимизации для улучшения этого. Самые большие факторы, которые, как представляется, негативно влияют на производительность:
- Размер модели, ссылающийся на количество сущностей и количество связей между этими сущностями.
- Сложность модели, в частности наследование с большим количеством типов.
- Использование независимых ассоциаций вместо ассоциаций внешних ключей.
Для небольших простых моделей стоимость может быть достаточно небольшой, чтобы не беспокоиться с помощью предварительно созданных представлений. При увеличении размера и сложности модели существует несколько вариантов, которые позволяют сократить затраты на создание и проверку представления.
2.3. Использование предварительно созданных представлений для уменьшения времени загрузки модели
Подробные сведения об использовании предварительно созданных представлений в Entity Framework 6 см . в предварительно созданных представлениях сопоставления
2.3.1 Предварительно созданные представления с помощью Entity Framework Power Tools Community Edition
Вы можете использовать Entity Framework 6 Power Tools Community Edition для создания представлений моделей EDMX и Code First, щелкнув правой кнопкой мыши файл класса модели и выбрав пункт "Создать представления". Entity Framework Power Tools Community Edition работает только в контекстах, производных от DbContext.
2.3.2 Использование предварительно созданных представлений с моделью, созданной EDMGen
EDMGen — это программа, которая поставляется с .NET и работает с Entity Framework 4 и 5, но не с Entity Framework 6. EDMGen позволяет создавать файл модели, слой объектов и представления из командной строки. Одним из выходных данных будет файл Views на выбранном языке, VB или C#. Это файл кода, содержащий фрагменты кода Entity SQL для каждого набора сущностей. Чтобы включить предварительно созданные представления, просто включите файл в проект.
Если вы вручную вносите изменения в файлы схемы для модели, вам потребуется повторно создать файл представлений. Это можно сделать, запустив EDMGen с флагом /mode:ViewGeneration .
2.3.3. Использование предварительно созданных представлений с файлом EDMX
Вы также можете использовать EDMGen для создания представлений для EDMX-файла. Ранее упоминаемый раздел MSDN описывает, как добавить событие предварительной сборки для этого- но это сложно, и есть некоторые случаи, когда это невозможно. Как правило, проще использовать шаблон T4 для создания представлений, когда модель находится в edmx-файле.
В блоге команды ADO.NET содержится запись, описывающая использование шаблона T4 для создания представлений ( <https://learn.microsoft.com/archive/blogs/adonet/how-to-use-a-t4-template-for-view-generation>). Эта запись содержит шаблон, который можно скачать и добавить в проект. Шаблон был написан для первой версии Entity Framework, поэтому они не гарантированы для работы с последними версиями Entity Framework. Однако вы можете скачать более актуальный набор шаблонов создания представлений для Entity Framework 4 и 5from в коллекции Visual Studio:
- VB.NET: <http://visualstudiogallery.msdn.microsoft.com/118b44f2-1b91-4de2-a584-7a680418941d>
- В C#: <http://visualstudiogallery.msdn.microsoft.com/ae7730ce-ddab-470f-8456-1b313cd2c44d>
Если вы используете Entity Framework 6, вы можете получить шаблоны создания представлений T4 из коллекции Visual Studio по адресу <http://visualstudiogallery.msdn.microsoft.com/18a7db90-6705-4d19-9dd1-0a6c23d0751f>.
2.4 Снижение затрат на создание представления
Использование предварительно созданных представлений перемещает стоимость создания представления с загрузки модели (время выполнения) до времени разработки. Хотя это повышает производительность запуска во время выполнения, вы по-прежнему испытываете боль в создании представлений во время разработки. Существует несколько дополнительных способов, которые могут помочь сократить затраты на создание представления, как во время компиляции, так и во время выполнения.
2.4.1 Использование ассоциаций внешних ключей для снижения затрат на создание представлений
Мы видели ряд случаев, когда переключение ассоциаций в модели с независимых ассоциаций на внешние ключевые ассоциации значительно улучшило время, затраченное на создание представлений.
Чтобы продемонстрировать это улучшение, мы создали две версии модели Navision с помощью EDMGen. Примечание. См. приложение C для описания модели Navision. Модель Navision интересна для этого упражнения из-за его очень большого количества сущностей и связей между ними.
Одна из версий этой очень большой модели была создана с помощью ассоциаций внешних ключей, а другая была создана с независимыми ассоциациями. Затем мы засучили, сколько времени потребовалось для создания представлений для каждой модели. Тест Entity Framework 5 использовал метод GenerateViews() из класса EntityViewGenerator для создания представлений, а тест Entity Framework 6 использовал метод GenerateViews() из класса служба хранилища MappingItemCollection. Это связано с реструктуризацией кода, которая произошла в базе кода Entity Framework 6.
С помощью Entity Framework 5 представление модели с внешними ключами заняло 65 минут на компьютере лаборатории. Неизвестно, сколько времени потребовалось бы для создания представлений для модели, которая использовала независимые ассоциации. Мы оставили тест, запущенный более месяца, прежде чем компьютер был перезагружен в нашей лаборатории, чтобы установить ежемесячные обновления.
С помощью Entity Framework 6 представление модели с внешними ключами заняло 28 секунд на том же компьютере лаборатории. Создание представления для модели, использующая независимые ассоциации, заняло 58 секунд. Улучшения, выполненные в Entity Framework 6 в коде создания представления, означают, что многие проекты не требуют предварительно созданных представлений для быстрого запуска.
Важно отметить, что предварительно созданные представления в Entity Framework 4 и 5 можно сделать с помощью EDMGen или Entity Framework Power Tools. Для создания представлений Entity Framework 6 можно создавать с помощью Entity Framework Power Tools или программно, как описано в предварительно созданных представлениях сопоставления.
2.4.1.1 Как использовать внешние ключи вместо независимых ассоциаций
При использовании EDMGen или конструктора сущностей в Visual Studio вы получаете FKs по умолчанию, и для переключения между FK и IAs используется только один флажок проверка или командной строки.
Если у вас есть большая модель Code First, использование независимых ассоциаций будет иметь тот же эффект на создание представления. Это влияние можно избежать, включив свойства внешнего ключа в классы для зависимых объектов, хотя некоторые разработчики считают, что это загрязняет свою объектную модель. Дополнительные сведения об этой теме см. в <http://blog.oneunicorn.com/2011/12/11/whats-the-deal-with-mapping-foreign-keys-using-the-entity-framework/>разделе .
| В языке | Действие |
|---|---|
| Entity Designer | После добавления связи между двумя сущностями убедитесь, что у вас есть ограничение ссылки. Ограничения ссылок указывают Entity Framework использовать внешние ключи вместо независимых ассоциаций. Дополнительные сведения см. в статье <https://learn.microsoft.com/archive/blogs/efdesign/foreign-keys-in-the-entity-framework>. |
| EDMGen | При использовании EDMGen для создания файлов из базы данных внешние ключи будут уважаться и добавляться в модель таким образом. Дополнительные сведения о различных вариантах, предоставляемых сайтом EDMGen http://msdn.microsoft.com/library/bb387165.aspx. |
| Code First | Дополнительные сведения о том, как включить свойства внешнего ключа для зависимых объектов при использовании Code First, см. в разделе "Соглашение о связи". |
2.4.2 Перемещение модели в отдельную сборку
Если модель включена непосредственно в проект приложения и вы создаете представления с помощью предварительного события сборки или шаблона T4, создание представлений и проверка будут выполняться всякий раз, когда проект перестроен, даже если модель не была изменена. Если вы перемещаете модель в отдельную сборку и ссылаетесь на нее из проекта приложения, вы можете внести другие изменения в приложение без необходимости перестроить проект, содержащий модель.
Примечание. При перемещении модели в отдельные сборки не забудьте скопировать строка подключения для модели в файл конфигурации приложения клиентского проекта.
2.4.3 Отключение проверки модели на основе edmx
Модели EDMX проверяются во время компиляции, даже если модель не изменяется. Если модель уже проверена, можно отключить проверку во время компиляции, установив для свойства Validate on Build значение false в окне свойств. При изменении сопоставления или модели можно временно повторно включить проверку для проверки изменений.
Обратите внимание, что улучшения производительности были сделаны в конструкторе Entity Framework для Entity Framework 6, а стоимость проверки на сборку значительно ниже, чем в предыдущих версиях конструктора.
Кэширование 3 в Entity Framework
Entity Framework имеет следующие формы кэширования:
- Кэширование объектов — ОбъектStateManager, встроенный в экземпляр ObjectContext, отслеживает объекты, полученные с помощью этого экземпляра. Это также называется кэшем первого уровня.
- Кэширование плана запросов — повторное использованием созданной команды хранилища при выполнении запроса более одного раза.
- Кэширование метаданных — совместное использование метаданных для модели в разных соединениях с одной и той же моделью.
Помимо кэшей, предоставляемых EF вне поля, специальный ADO.NET поставщик данных, известный как поставщик упаковки, также можно использовать для расширения Entity Framework с кэшем для результатов, полученных из базы данных, также известных как кэширование второго уровня.
Кэширование объектов 3.1
По умолчанию, когда сущность возвращается в результатах запроса, незадолго до того, как EF материализует его, ОбъектContext будет проверка если сущность с тем же ключом уже загружена в объект ObjectStateManager. Если сущность с теми же ключами уже присутствует EF, она будет включаться в результаты запроса. Хотя EF по-прежнему выдает запрос к базе данных, это поведение может обойти большую часть затрат на материализацию сущности несколько раз.
3.1.1 Получение сущностей из кэша объектов с помощью DbContext Find
В отличие от обычного запроса, метод Find в DbSet (API, включенные впервые в EF 4.1), будет выполнять поиск в памяти, прежде чем даже выдавать запрос к базе данных. Важно отметить, что два разных экземпляра ObjectContext будут иметь два разных экземпляра ObjectStateManager, что означает, что они имеют отдельные кэши объектов.
Поиск использует значение первичного ключа для попытки найти сущность, отслеживаемую контекстом. Если сущность не находится в контексте, запрос будет выполнен и вычисляется в базе данных, а значение NULL возвращается, если сущность не найдена в контексте или в базе данных. Обратите внимание, что Find также возвращает сущности, добавленные в контекст, но еще не сохранены в базе данных.
При использовании find необходимо учитывать производительность. Вызовы к этому методу по умолчанию активируют проверку кэша объектов, чтобы обнаружить изменения, которые по-прежнему ожидают фиксации в базе данных. Этот процесс может быть очень дорогим, если в кэше объектов есть очень большое количество объектов или в большом графе объектов, добавляемом в кэш объектов, но его также можно отключить. В некоторых случаях при отключении автоматического обнаружения изменений при вызове метода Find может возникнуть разница в порядке разницы. Тем не менее, второй порядок величины воспринимается, когда объект фактически находится в кэше и когда объект должен быть извлечен из базы данных. Ниже приведен пример графа с измерениями, сделанными с помощью некоторых микробнчмарков, выраженных в миллисекундах, с нагрузкой в 5000 сущностей:

Пример поиска с отключенными автоматическим обнаружением изменений:
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
context.Configuration.AutoDetectChangesEnabled = true;
...
Что необходимо учитывать при использовании метода Find:
- Если объект не находится в кэше, преимущества Find отрицаются, но синтаксис по-прежнему проще, чем запрос по ключу.
- Если автоматическое обнаружение изменений включено, стоимость метода Find может увеличиться на один порядок величины или даже больше в зависимости от сложности модели и объема сущностей в кэше объектов.
Кроме того, помните, что Find возвращает только требуемую сущность, и она не загружает связанные сущности автоматически, если они еще не находятся в кэше объектов. Если необходимо получить связанные сущности, можно использовать запрос по ключу с активной загрузкой. Дополнительные сведения см. в разделе 8.1 Отложенная загрузка и страстная загрузка.
3.1.2 Проблемы с производительностью, когда кэш объектов имеет множество сущностей
Кэш объектов помогает повысить общую скорость реагирования Entity Framework. Однако если кэш объектов имеет очень большое количество загруженных сущностей, он может повлиять на определенные операции, такие как Добавление, Удаление, Поиск, Запись, SaveChanges и многое другое. В частности, операции, запускающие вызов DetectChanges, будут отрицательно влиять на очень большие кэши объектов. DetectChanges синхронизирует граф объектов с диспетчером состояний объекта, а его производительность определяется непосредственно размером графа объектов. Дополнительные сведения об DetectChanges см. в разделе "Отслеживание изменений" в сущностях POCO.
При использовании Entity Framework 6 разработчики могут вызывать AddRange и RemoveRange непосредственно в DbSet, а не выполнять итерацию в коллекции и вызывать добавление один раз на экземпляр. Преимущество использования методов диапазона заключается в том, что стоимость DetectChanges оплачивается только один раз для всего набора сущностей, а не один раз для каждой добавленной сущности.
Кэширование плана запросов 3.2
При первом выполнении запроса он проходит через внутренний компилятор плана для перевода концептуального запроса в команду хранилища (например, T-SQL, который выполняется при выполнении с SQL Server). Если кэширование плана запросов включено, при следующем выполнении запроса команда хранилища извлекается непосредственно из кэша плана запроса для выполнения, обход компилятора плана.
Кэш плана запросов используется для экземпляров ObjectContext в одном домене приложения. Не нужно держаться на экземпляре ObjectContext, чтобы воспользоваться кэшированием плана запросов.
3.2.1 Некоторые заметки о кэшировании плана запросов
- Кэш плана запросов используется для всех типов запросов: entity SQL, LINQ to Entity и CompiledQuery.
- По умолчанию кэширование плана запросов включено для запросов Entity SQL, выполняемых через EntityCommand или ObjectQuery. Он также включен по умолчанию для запросов LINQ to Entity Framework в .NET 4.5 и Entity Framework 6
- Кэширование плана запросов можно отключить, установив для свойства EnablePlanCaching (в EntityCommand или ObjectQuery) значение false. Например:
var query = from customer in context.Customer
where customer.CustomerId == id
select new
{
customer.CustomerId,
customer.Name
};
ObjectQuery oQuery = query as ObjectQuery;
oQuery.EnablePlanCaching = false;
- Для параметризованных запросов изменение значения параметра по-прежнему попадет в кэшированный запрос. Но изменение аспектов параметра (например, размер, точность или масштабирование) приведет к другой записи в кэше.
- При использовании Entity SQL строка запроса является частью ключа. Изменение запроса на всех приведет к различным записям кэша, даже если запросы функционально эквивалентны. Сюда входят изменения в регистр или пробелы.
- При использовании LINQ запрос обрабатывается для создания части ключа. Поэтому изменение выражения LINQ приведет к созданию другого ключа.
- Другие технические ограничения могут применяться; Дополнительные сведения см. в разделе "Автокомпилированные запросы".
Алгоритм вытеснения кэша 3.2.2
Понимание того, как работает внутренний алгоритм, поможет определить, когда следует включить или отключить кэширование плана запросов. Алгоритм очистки выглядит следующим образом:
- После того как кэш содержит заданное количество записей (800), мы начинаем таймер, который периодически (один раз в минуту) выполняет очистку кэша.
- Во время очистки кэша записи удаляются из кэша на основе LFRU (наименее часто используемых). Этот алгоритм учитывает количество попаданий и возраст при принятии решения о том, какие записи удаляются.
- В конце каждого развертки кэша кэш снова содержит 800 записей.
Все записи кэша обрабатываются одинаково при определении элементов, которые необходимо вытеснить. Это означает, что команда хранилища для КомпилятораQuery имеет тот же шанс вытеснения, что и команда хранилища для запроса Entity SQL.
Обратите внимание, что таймер вытеснения кэша запускается при наличии 800 сущностей в кэше, но после запуска таймера кэш выполняется всего 60 секунд. Это означает, что до 60 секунд кэш может увеличиться до довольно большого размера.
3.2.3 Тестовые метрики, демонстрирующие производительность кэширования плана запросов
Чтобы продемонстрировать влияние кэширования плана запросов на производительность приложения, мы выполнили тест, в котором мы выполнили ряд запросов Entity SQL в модели Navision. Ознакомьтесь с приложением для описания модели Navision и типов выполненных запросов. В этом тесте сначала выполните итерацию по списку запросов и выполните каждый раз, чтобы добавить их в кэш (если кэширование включено). Этот шаг не выполняется. Далее мы спим основной поток в течение более 60 секунд, чтобы разрешить масштабирование кэша; Наконец, мы итерируем по списку 2-е время для выполнения кэшированных запросов. Кроме того, кэш планов SQL Server очищается перед выполнением каждого набора запросов, чтобы время, которое мы получили точно, отражает преимущество, предоставленное кэшом плана запросов.
Результаты теста 3.2.3.1
| Тест | EF5 нет кэша | КЭШ EF5 | EF6 без кэша | КЭШ EF6 |
|---|---|---|---|---|
| Перечисление всех запросов 18723 | 124 | 125,4 | 124,3 | 125.3 |
| Избегайте очистки (только первые 800 запросов, независимо от сложности) | 41.7 | 5.5 | 40,5 | 5,4 |
| Только запросы AggregatingSubtotals (всего 178 , что позволяет избежать очистки) | 39,5 | 4,5 | 38,1 | 4,6 |
Все время в секундах.
Моральный — при выполнении большого количества отдельных запросов (например, динамически созданных запросов), кэширование не помогает, а результирующее очистка кэша может поддерживать запросы, которые помогут больше всего использовать кэширование планов.
Запросы AggregatingSubtotals являются наиболее сложными из проверенных запросов. Как ожидается, чем более сложный запрос, тем больше преимуществ вы увидите из кэширования плана запросов.
Так как СкомпилированныйQuery действительно является запросом LINQ с кэшируемым планом, сравнение скомпилированногоQuery и эквивалентного запроса Entity SQL должно иметь аналогичные результаты. На самом деле, если у приложения много динамических запросов Entity SQL, заполнение кэша запросами также приведет к декомпиляции компилятора, когда они удаляются из кэша. В этом сценарии производительность может быть улучшена, отключив кэширование динамических запросов, чтобы определить приоритет компилятораQueries. Лучше, конечно, будет переписать приложение для использования параметризованных запросов вместо динамических запросов.
3.3 Использование компилятораQuery для повышения производительности с помощью запросов LINQ
Наши тесты показывают, что использование компилятораQuery может принести преимущество 7 % по сравнению с автоматически компилируемыми запросами LINQ; это означает, что вы будете тратить 7 % меньше времени на выполнение кода из стека Entity Framework; Это не означает, что ваше приложение будет быстрее 7 %. Как правило, стоимость написания и обслуживания объектов CompiledQuery в EF 5.0 может не стоить проблем при сравнении с преимуществами. Ваш пробег может отличаться, поэтому выполните этот параметр, если для вашего проекта требуется дополнительная отправка. Обратите внимание, что Компиляторы совместимы только с моделями, производными от ObjectContext, и несовместимы с моделями, производными от DbContext.
Дополнительные сведения о создании и вызове компилятораQuery см. в разделе "Скомпилированные запросы" (LINQ to Entity).
При использовании КомпилятораQuery необходимо учитывать два соображения, а именно требование использовать статические экземпляры и проблемы, с которыми они связаны. Ниже приведено подробное описание этих двух соображений.
3.3.1 Использование статических экземпляров CompiledQuery
Так как компиляция запроса LINQ является трудоемким процессом, мы не хотим делать это каждый раз, когда нам нужно получить данные из базы данных. Скомпилированные экземплярыQuery позволяют скомпилировать один раз и выполнять несколько раз, но необходимо быть осторожным и приобретать для повторного использования одного и того же экземпляра CompiledQuery каждый раз вместо компиляции его снова и снова. Требуется использование статических элементов для хранения экземпляров CompiledQuery; в противном случае вы не увидите никакого преимущества.
Например, предположим, что на странице имеется следующий текст метода для обработки отображения продуктов для выбранной категории:
// Warning: this is the wrong way of using CompiledQuery
using (NorthwindEntities context = new NorthwindEntities())
{
string selectedCategory = this.categoriesList.SelectedValue;
var productsForCategory = CompiledQuery.Compile<NorthwindEntities, string, IQueryable<Product>>(
(NorthwindEntities nwnd, string category) =>
nwnd.Products.Where(p => p.Category.CategoryName == category)
);
this.productsGrid.DataSource = productsForCategory.Invoke(context, selectedCategory).ToList();
this.productsGrid.DataBind();
}
this.productsGrid.Visible = true;
В этом случае вы создадите новый экземпляр CompiledQuery при каждом вызове метода. Вместо того, чтобы увидеть преимущества производительности, извлекая команду хранилища из кэша плана запроса, КомпиляторQuery будет проходить через компилятор плана каждый раз при создании нового экземпляра. На самом деле вы будете загрязнять кэш плана запросов с новой записью CompiledQuery каждый раз при вызове метода.
Вместо этого необходимо создать статический экземпляр скомпилированного запроса, поэтому при каждом вызове метода вызывается один и тот же скомпилированный запрос. Одним из способов этого является добавление экземпляра CompiledQuery в качестве члена контекста объекта. Затем можно сделать вещи более чистыми, доступ к КомпиляторуQuery с помощью вспомогательного метода:
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IEnumerable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IEnumerable<Product> GetProductsForCategory(string categoryName)
{
return productsForCategoryCQ.Invoke(this, categoryName).ToList();
}
Этот вспомогательный метод будет вызван следующим образом:
this.productsGrid.DataSource = context.GetProductsForCategory(selectedCategory);
3.3.2 Создание по компилятору
Возможность создания любого запроса LINQ очень полезна; Для этого необходимо просто вызвать метод после IQueryable, например Skip() или Count().. Однако при этом по существу возвращается новый объект IQueryable. Хотя нет ничего, чтобы помешать вам технически создавать компиляцию по компилятору CompiledQuery, это приведет к возникновению нового объекта IQueryable, требующего повторного прохождения компилятора плана.
Некоторые компоненты используют составные объекты IQueryable для включения расширенных функциональных возможностей. Например, элемент GridView ASP.NET может быть привязан к объекту IQueryable через свойство SelectMethod. Затем GridView будет создавать над этим объектом IQueryable, чтобы разрешить сортировку и разбиение по страницам в модели данных. Как видно, использование компилятораQuery для GridView не попадает в скомпилированный запрос, но создаст новый автоматически компилированный запрос.
Одно место, в котором может возникнуть проблема, заключается в добавлении прогрессивных фильтров в запрос. Например, предположим, что у вас была страница "Клиенты" с несколькими раскрывающимся списками для необязательных фильтров (например, Country и OrdersCount). Эти фильтры можно создать по результатам IQueryable компилятора Компилятора, но это приведет к тому, что новый запрос будет проходить через компилятор плана при каждом выполнении.
using (NorthwindEntities context = new NorthwindEntities())
{
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployee();
if (this.orderCountFilterList.SelectedItem.Value != defaultFilterText)
{
int orderCount = int.Parse(orderCountFilterList.SelectedValue);
myCustomers = myCustomers.Where(c => c.Orders.Count > orderCount);
}
if (this.countryFilterList.SelectedItem.Value != defaultFilterText)
{
myCustomers = myCustomers.Where(c => c.Address.Country == countryFilterList.SelectedValue);
}
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Чтобы избежать повторной компиляции, можно перезаписать скомпилированныйQuery, чтобы принять во внимание возможные фильтры:
private static readonly Func<NorthwindEntities, int, int?, string, IQueryable<Customer>> customersForEmployeeWithFiltersCQ = CompiledQuery.Compile(
(NorthwindEntities context, int empId, int? countFilter, string countryFilter) =>
context.Customers.Where(c => c.Orders.Any(o => o.EmployeeID == empId))
.Where(c => countFilter.HasValue == false || c.Orders.Count > countFilter)
.Where(c => countryFilter == null || c.Address.Country == countryFilter)
);
Что будет вызываться в пользовательском интерфейсе, например:
using (NorthwindEntities context = new NorthwindEntities())
{
int? countFilter = (this.orderCountFilterList.SelectedIndex == 0) ?
(int?)null :
int.Parse(this.orderCountFilterList.SelectedValue);
string countryFilter = (this.countryFilterList.SelectedIndex == 0) ?
null :
this.countryFilterList.SelectedValue;
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployeeWithFilters(
countFilter, countryFilter);
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Здесь создается команда хранилища всегда будет иметь фильтры с пустыми проверка, но они должны быть довольно простыми для сервера базы данных для оптимизации:
...
WHERE ((0 = (CASE WHEN (@p__linq__1 IS NOT NULL) THEN cast(1 as bit) WHEN (@p__linq__1 IS NULL) THEN cast(0 as bit) END)) OR ([Project3].[C2] > @p__linq__2)) AND (@p__linq__3 IS NULL OR [Project3].[Country] = @p__linq__4)
Кэширование метаданных 3.4
Entity Framework также поддерживает кэширование метаданных. Это, по сути, кэширование сведений о типе и сопоставлении типов в базе данных между различными подключениями к одной модели. Кэш метаданных является уникальным для каждого домена приложения.
Алгоритм кэширования метаданных 3.4.1
Сведения о метаданных для модели хранятся в элементе ItemCollection для каждой сущности Подключение ion.
- В качестве боковой заметки существуют различные объекты ItemCollection для разных частей модели. Например, StoreItemCollections содержит сведения о модели базы данных; ObjectItemCollection содержит сведения о модели данных; EdmItemCollection содержит сведения о концептуальной модели.
Если два подключения используют один и тот же строка подключения, они будут совместно использовать один и тот же экземпляр ItemCollection.
Функционально эквивалентно, но текстовые строка подключения могут привести к разным кэшам метаданных. Мы маркеризируем строка подключения, поэтому просто изменение порядка маркеров должно привести к общим метаданным. Но два строка подключения, которые, кажется, функционально одинаковы, не могут быть оценены как идентичные после токенизации.
ЭлементCollection периодически проверка для использования. Если определено, что рабочая область недавно не была доступна, она будет помечена для очистки при следующем очистке кэша.
Простое создание сущности Подключение ion приведет к созданию кэша метаданных (хотя коллекции элементов в нем не будут инициализированы до открытия подключения). Эта рабочая область останется в памяти, пока алгоритм кэширования не определяет, что он не используется.
Группа консультантов по клиентам написала запись блога, описывающую ссылку на ItemCollection, чтобы избежать "нерекомендуемого" при использовании больших моделей: <https://learn.microsoft.com/archive/blogs/appfabriccat/holding-a-reference-to-the-ef-metadataworkspace-for-wcf-services>
3.4.2 Связь между кэшированием метаданных и кэшированием плана запросов
Экземпляр кэша плана запросов находится в элементе ItemCollection пространства метаданных типов хранилища. Это означает, что кэшированные команды хранилища будут использоваться для запросов к любому контексту, созданному с помощью заданного пространства MetadataWorkspace. Это также означает, что если у вас есть две строки подключений, которые немного отличаются и не совпадают после маркеризации, у вас будут разные экземпляры кэша плана запросов.
Кэширование результатов 3.5
При кэшировании результатов (также называемом "кэшированием второго уровня"), результаты запросов сохраняются в локальном кэше. При выполнении запроса сначала вы увидите, доступны ли результаты локально перед запросом к хранилищу. Хотя кэширование результатов не поддерживается непосредственно Entity Framework, можно добавить кэш второго уровня с помощью поставщика упаковки. Примером поставщика упаковки с кэшем второго уровня является кэш Entity Framework Alachisoft на основе NCache.
Эта реализация кэширования второго уровня — это внедренная функциональность, которая выполняется после вычисления выражения LINQ (и funcletized), а план выполнения запроса вычисляется или извлекается из кэша первого уровня. Кэш второго уровня будет хранить только необработанные результаты базы данных, поэтому конвейер материализации по-прежнему выполняется после этого.
3.5.1 Дополнительные ссылки на кэширование результатов с поставщиком упаковки
- Джули Лерман написал статью MSDN "Кэширование второго уровня в Entity Framework и Windows Azure", включающую обновление примера поставщика упаковки для использования кэширования Windows Server AppFabric: https://msdn.microsoft.com/magazine/hh394143.aspx
- Если вы работаете с Entity Framework 5, в блоге команды есть запись, описывающая, как работать с поставщиком кэширования для Entity Framework 5: <https://learn.microsoft.com/archive/blogs/adonet/ef-caching-with-jarek-kowalskis-provider> Он также включает шаблон T4, помогающий автоматизировать добавление кэширования на уровне 2-го уровня в проект.
4 автоматически компилированных запросов
При выполнении запроса к базе данных с помощью Entity Framework необходимо выполнить ряд шагов, прежде чем фактически материализовать результаты; одним из таких шагов является компиляция запросов. Запросы Entity SQL, как известно, имеют хорошую производительность, так как они автоматически кэшируются, поэтому второй или третий раз, когда выполняется тот же запрос, он может пропустить компилятор плана и использовать кэшированный план.
Entity Framework 5 также представила автоматическое кэширование для запросов LINQ to Entity. В прошлых выпусках Entity Framework создание компилятораQuery для ускорения производительности было распространенной практикой, так как это позволит кэшировать запрос LINQ to Entity. Так как кэширование выполняется автоматически без использования компилятораQuery, мы называем эту функцию "автоматически компилируемыми запросами". Дополнительные сведения о кэше плана запросов и его механике см. в разделе "Кэширование плана запросов".
Entity Framework обнаруживает, когда запрос требует повторной компиляции, и делает это при вызове запроса даже в том случае, если он был скомпилирован раньше. Распространенные условия, которые приводят к повторной компиляции запроса:
- Изменение MergeOption, связанного с запросом. Кэшированный запрос не будет использоваться, вместо этого компилятор плана будет выполняться снова, и только что созданный план кэшируется.
- Изменение значения ContextOptions.UseCSharpNullComparisonBehavior. Вы получаете тот же эффект, что и изменение MergeOption.
Другие условия могут запретить запросу использовать кэш. Ниже приведены распространенные примеры.
- Использование IEnumerable<T>. <>Содержит (T-значение).
- Использование функций, которые создают запросы с константами.
- Использование свойств не сопоставленного объекта.
- Связывание запроса с другим запросом, который требуется перекомпилировать.
4.1 С помощью IEnumerable<T>. Содержит<значение T>(T)
Entity Framework не кэширует запросы, вызывающие IEnumerable<T>. Содержит<значение T>(T) для коллекции в памяти, так как значения коллекции считаются переменными. Следующий пример запроса не будет кэширован, поэтому он всегда будет обрабатываться компилятором плана:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var query = context.MyEntities
.Where(entity => ids.Contains(entity.Id));
var results = query.ToList();
...
}
Обратите внимание, что размер IEnumerable, для которого выполняется contains, определяет, насколько быстро или как медленно скомпилирован запрос. Производительность может значительно снизиться при использовании больших коллекций, таких как показанная в приведенном выше примере.
Entity Framework 6 содержит оптимизации по способу IEnumerable<T>. <Содержит значение T>(T) при выполнении запросов. Созданный код SQL гораздо быстрее создает и более читаемый, и в большинстве случаев он также выполняется быстрее на сервере.
4.2 Использование функций, которые создают запросы с константами
Операторы LINQ skip(), Take(), Contains() и DefautIfEmpty() не создают запросы SQL с параметрами, а помещают значения, передаваемые им в виде констант. Из-за этого запросы, которые могут быть идентичными, в конечном итоге загрязняют кэш плана запросов, как на стеке EF, так и на сервере базы данных, и не используются повторно, если только те же константы не используются в последующем выполнении запроса. Например:
var id = 10;
...
using (var context = new MyContext())
{
var query = context.MyEntities.Select(entity => entity.Id).Contains(id);
var results = query.ToList();
...
}
В этом примере каждый раз, когда этот запрос выполняется с другим значением для идентификатора, запрос будет скомпилирован в новый план.
В частности, обратите внимание на использование skip and Take при выполнении разбиения по страницам. В EF6 эти методы имеют лямбда-перегрузку, которая эффективно делает кэшированный план запросов повторно используемым, так как EF может записывать переменные, передаваемые этим методам, и переводить их в SQLparameters. Это также помогает обеспечить очистку кэша, так как в противном случае каждый запрос с другой константой для Skip и Take получит собственную запись кэша плана запросов.
Рассмотрим следующий код, который является неоптимальным, но предназначен только для примера этого класса запросов:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Более быстрая версия этого же кода будет включать вызов Skip с лямбда-кодом:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(() => i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Второй фрагмент кода может выполняться до 11 % быстрее, так как один и тот же план запроса используется каждый раз при выполнении запроса, что позволяет сэкономить время ЦП и избежать загрязнения кэша запросов. Кроме того, так как параметр skip находится в закрытии кода, может выглядеть следующим образом:
var i = 0;
var skippyCustomers = context.Customers.OrderBy(c => c.LastName).Skip(() => i);
for (; i < count; ++i)
{
var currentCustomer = skippyCustomers.FirstOrDefault();
ProcessCustomer(currentCustomer);
}
4.3 Использование свойств не сопоставленного объекта
Если запрос использует свойства не сопоставленного типа объекта в качестве параметра, запрос не будет кэширован. Например:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myObject.MyProperty)
select entity;
var results = query.ToList();
...
}
В этом примере предположим, что класс NonMappedType не является частью модели сущности. Этот запрос можно легко изменить, чтобы не использовать не сопоставленный тип и вместо этого использовать локальную переменную в качестве параметра для запроса:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var myValue = myObject.MyProperty;
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myValue)
select entity;
var results = query.ToList();
...
}
В этом случае запрос сможет кэшироваться и воспользоваться кэшем плана запросов.
4.4 Связывание с запросами, требующими повторной компиляции
После приведенного выше примера, если у вас есть второй запрос, основанный на запросе, который должен быть перекомпилирован, весь второй запрос также будет перекомпилирован. Ниже приведен пример для иллюстрации этого сценария:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var firstQuery = from entity in context.MyEntities
where ids.Contains(entity.Id)
select entity;
var secondQuery = from entity in context.MyEntities
where firstQuery.Any(otherEntity => otherEntity.Id == entity.Id)
select entity;
var results = secondQuery.ToList();
...
}
Пример является универсальным, но он иллюстрирует, как связывание с firstQuery приводит к невозможности кэширования secondQuery. Если бы firstQuery не был запросом, требующим повторной компиляции, то второйQuery был кэширован.
5 Запросов NoTracking
5.1 Отключение отслеживания изменений для уменьшения затрат на управление состоянием
Если вы находитесь в сценарии только для чтения и хотите избежать затрат на загрузку объектов в ObjectStateManager, вы можете выдавать запросы "Без отслеживания". Отслеживание изменений можно отключить на уровне запроса.
Обратите внимание, что при отключении отслеживания изменений вы фактически отключаете кэш объектов. При запросе сущности невозможно пропустить материализацию, извлекая ранее материализованные результаты запроса из ObjectStateManager. Если вы неоднократно запрашиваете одни и те же сущности в одном контексте, возможно, вы на самом деле увидите преимущество производительности при включении отслеживания изменений.
При запросе с помощью ObjectContext экземпляры ObjectQuery и ObjectSet будут запоминать MergeOption после установки, а запросы, состоящие на них, наследуют эффективный MergeOption родительского запроса. При использовании DbContext отслеживание можно отключить, вызвав модификатор AsNoTracking() в DbSet.
5.1.1 Отключение отслеживания изменений для запроса при использовании DbContext
Вы можете переключить режим запроса на NoTracking, применив вызов метода AsNoTracking() в запросе. В отличие от ObjectQuery, классы DbSet и DbQuery в API DbContext не имеют изменяемого свойства для MergeOption.
var productsForCategory = from p in context.Products.AsNoTracking()
where p.Category.CategoryName == selectedCategory
select p;
5.1.2 Отключение отслеживания изменений на уровне запроса с помощью ObjectContext
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
((ObjectQuery)productsForCategory).MergeOption = MergeOption.NoTracking;
5.1.3 Отключение отслеживания изменений для всего набора сущностей с помощью ObjectContext
context.Products.MergeOption = MergeOption.NoTracking;
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
5.2 Тестовые метрики, демонстрирующие преимущество производительности запросов NoTracking
В этом тесте мы рассмотрим стоимость заполнения ObjectStateManager, сравнивая отслеживание с запросами NoTracking для модели Navision. Ознакомьтесь с приложением для описания модели Navision и типов выполненных запросов. В этом тесте мы выполните итерацию по списку запросов и выполните каждый раз. Мы выполнили два варианта теста, один раз с запросами NoTracking и один раз с параметром слияния по умолчанию "AppendOnly". Мы выполняли каждый вариант 3 раза и принимают среднее значение выполнения. Между тестами мы очищаем кэш запросов в SQL Server и сжимаем tempdb, выполнив следующие команды:
- DBCC DROPCLEANBUFFERS
- DBCC FREEPROCCACHE
- DBCC SHRINKDATABASE (tempdb, 0)
Результаты теста, медиана более 3 выполняется:
| НЕТ ОТСЛЕЖИВАНИЯ — РАБОЧИЙ НАБОР | НЕТ ОТСЛЕЖИВАНИЯ — ВРЕМЯ | ТОЛЬКО ДОБАВЛЕНИЕ — РАБОЧИЙ НАБОР | ТОЛЬКО ДОБАВЛЕНИЕ — ВРЕМЯ | |
|---|---|---|---|---|
| Entity Framework 5 | 460361728 | 1163536 мс | 596545536 | 1273042 мс |
| Entity Framework 6 | 647127040 | 190228 мс | 832798720 | 195521 мс |
Entity Framework 5 будет иметь меньше памяти в конце выполнения, чем Entity Framework 6. Дополнительная память, потребляемая Entity Framework 6, является результатом дополнительных структур памяти и кода, которые обеспечивают новые функции и более высокую производительность.
При использовании ObjectStateManager также существует четкое различие в памяти. Entity Framework 5 увеличил свой объем на 30 % при отслеживании всех сущностей, которые мы материализованы из базы данных. Entity Framework 6 увеличил свой объем на 28 % при этом.
С точки зрения времени Entity Framework 6 опережает Entity Framework 5 в этом тесте большим полем. Entity Framework 6 завершил тест примерно в 16% времени, затраченного Entity Framework 5. Кроме того, Entity Framework 5 занимает 9 % больше времени, когда используется ObjectStateManager. В сравнении Entity Framework 6 использует 3 % больше времени при использовании ObjectStateManager.
6 Варианты выполнения запросов
Entity Framework предлагает несколько различных способов запроса. Мы рассмотрим следующие варианты, сравните плюсы и минусы каждого из них и рассмотрим их характеристики производительности:
- LINQ to Entities.
- Нет отслеживания сущностей LINQ to Entities.
- Entity SQL по объекту ObjectQuery.
- Entity SQL через EntityCommand.
- ExecuteStoreQuery.
- SqlQuery.
- СкомпилированныйQuery.
6.1 запросы LINQ to Entity
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Преимущества
- Подходит для операций CUD.
- Полностью материализованные объекты.
- Самый простой для записи с помощью синтаксиса, встроенного в язык программирования.
- Хорошая производительность.
Недостатки
- Некоторые технические ограничения, такие как:
- Шаблоны, использующие DefaultIfEmpty для запросов OUTER JOIN, приводят к более сложным запросам, чем простые инструкции OUTER JOIN в Entity SQL.
- Вы по-прежнему не можете использовать LIKE с общим сопоставлением шаблонов.
6.2 Без запросов отслеживания LINQ to Entity
Если контекст наследует ObjectContext:
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Если контекст наследует DbContext:
var q = context.Products.AsNoTracking()
.Where(p => p.Category.CategoryName == "Beverages");
Преимущества
- Улучшена производительность по сравнению с обычными запросами LINQ.
- Полностью материализованные объекты.
- Самый простой для записи с помощью синтаксиса, встроенного в язык программирования.
Недостатки
- Не подходит для операций CUD.
- Некоторые технические ограничения, такие как:
- Шаблоны, использующие DefaultIfEmpty для запросов OUTER JOIN, приводят к более сложным запросам, чем простые инструкции OUTER JOIN в Entity SQL.
- Вы по-прежнему не можете использовать LIKE с общим сопоставлением шаблонов.
Обратите внимание, что запросы, которые скалярные свойства проекта не отслеживаются, даже если NoTracking не указан. Например:
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages").Select(p => new { p.ProductName });
Этот конкретный запрос не явно указывает noTracking, но так как он не материализует тип, известный диспетчеру состояний объекта, то материализованный результат не отслеживается.
6.3 Entity SQL по объекту ObjectQuery
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
Преимущества
- Подходит для операций CUD.
- Полностью материализованные объекты.
- Поддерживает кэширование плана запросов.
Недостатки
- Включает текстовые строки запроса, которые более подвержены ошибке пользователя, чем конструкции запросов, встроенные в язык.
6.4 Entity SQL по команде entity
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
while (reader.Read())
{
// manually 'materialize' the product
}
}
Преимущества
- Поддерживает кэширование плана запросов в .NET 4.0 (кэширование планов поддерживается всеми другими типами запросов в .NET 4.5).
Недостатки
- Включает текстовые строки запроса, которые более подвержены ошибке пользователя, чем конструкции запросов, встроенные в язык.
- Не подходит для операций CUD.
- Результаты не материализуются автоматически и должны быть прочитаны из средства чтения данных.
6.5 SqlQuery и ExecuteStoreQuery
SqlQuery в базе данных:
// use this to obtain entities and not track them
var q1 = context.Database.SqlQuery<Product>("select * from products");
SqlQuery в DbSet:
// use this to obtain entities and have them tracked
var q2 = context.Products.SqlQuery("select * from products");
ExecuteStoreQuery:
var beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued, P.DiscontinuedDate
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
Преимущества
- Как правило, самая быстрая производительность, так как компилятор плана обходить.
- Полностью материализованные объекты.
- Подходит для операций CUD при использовании из DbSet.
Недостатки
- Запрос является текстовым и подверженным ошибкам.
- Запрос привязан к определенной серверной части с помощью семантики хранилища вместо концептуальной семантики.
- Когда наследование присутствует, ручной запрос должен учитывать условия сопоставления для запрошенного типа.
6.6 СкомпилированныйQuery
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
…
var q = context.InvokeProductsForCategoryCQ("Beverages");
Преимущества
- Обеспечивает повышение производительности до 7 % по сравнению с обычными запросами LINQ.
- Полностью материализованные объекты.
- Подходит для операций CUD.
Недостатки
- Повышенная сложность и затраты на программирование.
- Улучшение производительности теряется при создании поверх скомпилированного запроса.
- Некоторые запросы LINQ не могут быть записаны как скомпилированныйQuery, например проекции анонимных типов.
6.7 Сравнение производительности различных параметров запроса
Простые микробнчмарки, в которых не было времени создания контекста, были помещены в тест. Мы измеряли запросы 5000 раз для набора не кэшированных сущностей в управляемой среде. Эти числа следует принимать с предупреждением: они не отражают фактические числа, созданные приложением, но вместо этого они являются очень точным измерением разницы производительности при сравнении различных вариантов запроса с яблоками и яблоками, исключая затраты на создание нового контекста.
| EF | Тест | Время (мс) | Память |
|---|---|---|---|
| EF5 | ObjectContext ESQL | 2414 | 38801408 |
| EF5 | Запрос ObjectContext Linq | 2692 | 38277120 |
| EF5 | DbContext Linq Query No Tracking | 2818 | 41840640 |
| EF5 | Запрос DbContext Linq | 2930 | 41771008 |
| EF5 | ОбъектContext Linq Query No Tracking | 3013 | 38412288 |
| EF6 | ObjectContext ESQL | 2059 | 46039040 |
| EF6 | Запрос ObjectContext Linq | 3074 | 45248512 |
| EF6 | DbContext Linq Query No Tracking | 3125 | 47575040 |
| EF6 | Запрос DbContext Linq | 3420 | 47652864 |
| EF6 | ОбъектContext Linq Query No Tracking | 3593 | 45260800 |

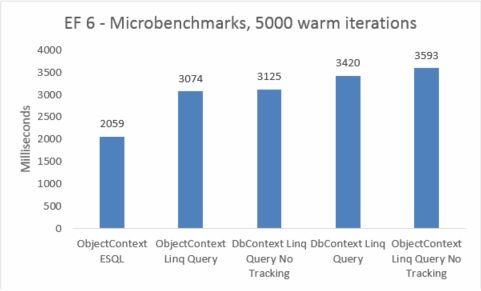
Микробнчмарки очень чувствительны к небольшим изменениям в коде. В этом случае разница между затратами Entity Framework 5 и Entity Framework 6 обусловлена добавлением улучшений перехвата и транзакций. Эти микробнчмарки цифры, однако, являются расширением зрения в очень небольшой фрагмент того, что делает Entity Framework. Реальные сценарии теплых запросов не должны видеть регрессию производительности при обновлении с Entity Framework 5 до Entity Framework 6.
Чтобы сравнить реальную производительность различных вариантов запроса, мы создали 5 отдельных вариантов теста, где мы используем другой вариант запроса для выбора всех продуктов, название категории которых — "Напитки". Каждая итерация включает затраты на создание контекста и стоимость материализации всех возвращаемых сущностей. 10 итерации выполняются незадолго до выполнения суммы 1000 итераций. Показанные результаты — это запуск медианы, взятые из 5 запусков каждого теста. Дополнительные сведения см. в приложении B, в котором содержится код для теста.
| EF | Тест | Время (мс) | Память |
|---|---|---|---|
| EF5 | Команда объекта ObjectContext | 621 | 39350272 |
| EF5 | Sql Query DbContext в базе данных | 825 | 37519360 |
| EF5 | Запрос хранилища ObjectContext | 878 | 39460864 |
| EF5 | ОбъектContext Linq Query No Tracking | 969 | 38293504 |
| EF5 | ObjectContext Entity Sql с помощью запроса объекта | 1089 | 38981632 |
| EF5 | Скомпилированный запрос ObjectContext | 1099 | 38682624 |
| EF5 | Запрос ObjectContext Linq | 1152 | 38178816 |
| EF5 | DbContext Linq Query No Tracking | 120 Б | 41803776 |
| EF5 | Sql Query DbContext в DbSet | 1414 | 37982208 |
| EF5 | Запрос DbContext Linq | 1574 | 41738240 |
| EF6 | Команда объекта ObjectContext | 480 | 47247360 |
| EF6 | Запрос хранилища ObjectContext | 493 | 46739456 |
| EF6 | Sql Query DbContext в базе данных | 614 | 41607168 |
| EF6 | ОбъектContext Linq Query No Tracking | 684 | 46333952 |
| EF6 | ObjectContext Entity Sql с помощью запроса объекта | 767 | 48865280 |
| EF6 | Скомпилированный запрос ObjectContext | 788 | 48467968 |
| EF6 | DbContext Linq Query No Tracking | 878 | 47554560 |
| EF6 | Запрос ObjectContext Linq | 953 | 47632384 |
| EF6 | Sql Query DbContext в DbSet | 1023 | 41992192 |
| EF6 | Запрос DbContext Linq | 1290 | 47529984 |
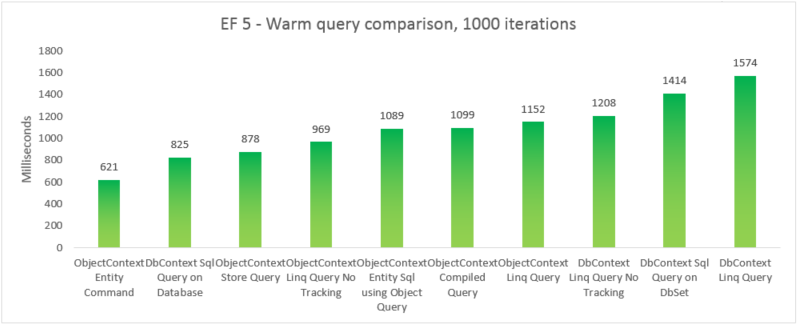
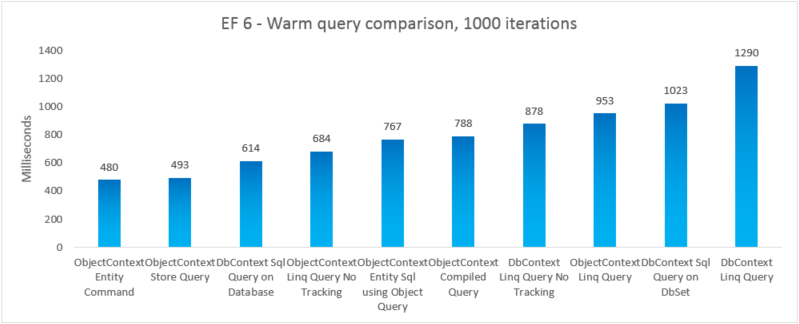
Примечание.
Для полноты мы включили вариант, в котором выполняется запрос Entity SQL в EntityCommand. Однако, поскольку результаты не материализуются для таких запросов, сравнение не обязательно apples-to-apples. Тест включает близкое приближение к материализации, чтобы попытаться сделать сравнение более справедливым.
В этом комплексном случае Entity Framework 6 опережает Entity Framework 5 из-за улучшений производительности, внесенных в несколько частей стека, включая гораздо более светлую инициализацию DbContext и более быструю подстановку МетаданныхCollection<T> .
7 Рекомендации по производительности времени разработки
Стратегии наследования 7.1
Еще одно соображение производительности при использовании Entity Framework — это используемая стратегия наследования. Entity Framework поддерживает 3 основных типа наследования и их сочетания:
- Таблица на иерархию (TPH) — где каждый набор наследования сопоставляется с таблицей с дискриминационным столбцом, чтобы указать, какой тип в иерархии представлен в строке.
- Таблица на тип (TPT) — где каждый тип имеет собственную таблицу в базе данных; Дочерние таблицы определяют только столбцы, которые не содержит родительская таблица.
- Таблица на класс (TPC) — где каждый тип имеет собственную полную таблицу в базе данных; Дочерние таблицы определяют все их поля, включая те, которые определены в родительских типах.
Если в модели используется наследование TPT, создаваемые запросы будут более сложными, чем созданные с помощью других стратегий наследования, что может привести к более длительному времени выполнения в хранилище. Как правило, для создания запросов по модели TPT и материализации результирующих объектов потребуется больше времени.
См. статью "Рекомендации по производительности при использовании наследования TPT (таблица на тип) в entity Framework" блог MSDN: <https://learn.microsoft.com/archive/blogs/adonet/performance-considerations-when-using-tpt-table-per-type-inheritance-in-the-entity-framework>
7.1.1 Избегайте TPT в приложениях Model First или Code First
При создании модели по существующей базе данных, имеющей схему TPT, у вас нет много вариантов. Но при создании приложения с помощью модели First или Code First следует избегать наследования TPT для проблем с производительностью.
При использовании модели в мастере конструктора сущностей вы получите TPT для любого наследования в модели. Если вы хотите переключиться на стратегию наследования TPH с помощью модели First, можно использовать пакет Power Pack создания базы данных Конструктора сущностей, доступный из коллекции Visual Studio ( <http://visualstudiogallery.msdn.microsoft.com/df3541c3-d833-4b65-b942-989e7ec74c87/>).
При использовании code First для настройки сопоставления модели с наследованием EF будет использовать TPH по умолчанию, поэтому все сущности в иерархии наследования будут сопоставлены с одной таблицей. Дополнительные сведения см. в разделе "Сопоставление с API Fluent" статьи "Code First in Entity Framework4.1" в msdn Magazine ( http://msdn.microsoft.com/magazine/hh126815.aspx) .
7.2 Обновление с EF4 для улучшения времени создания модели
В Entity Framework 5 и 6 доступно улучшение алгоритма, создающего хранилище (SSDL) модели, и в качестве обновления до Entity Framework 4 при установке Visual Studio 2010 с пакетом обновления 1 (SP1). Следующие результаты теста демонстрируют улучшение при создании очень большой модели, в этом случае модель Navision. Дополнительные сведения см. в приложении C.
Модель содержит 1005 наборов сущностей и 4227 наборов ассоциаций.
| Настройка | Разбивка времени, потребляемого |
|---|---|
| Visual Studio 2010, Entity Framework 4 | Поколение SSDL: 2 часа 27 минут Создание сопоставления: 1 секунда Поколение CSDL: 1 секунда ObjectLayer Generation: 1 секунда Поколение представлений: 2 ч 14 мин |
| Visual Studio 2010 с пакетом обновления 1 (SP1), Entity Framework 4 | Поколение SSDL: 1 секунда Создание сопоставления: 1 секунда Поколение CSDL: 1 секунда ObjectLayer Generation: 1 секунда Поколение представлений: 1 час 53 мин |
| Visual Studio 2013, Entity Framework 5 | Поколение SSDL: 1 секунда Создание сопоставления: 1 секунда Поколение CSDL: 1 секунда ObjectLayer Generation: 1 секунда Создание представления: 65 минут |
| Visual Studio 2013, Entity Framework 6 | Поколение SSDL: 1 секунда Создание сопоставления: 1 секунда Поколение CSDL: 1 секунда ObjectLayer Generation: 1 секунда Просмотр поколения: 28 секунд. |
Стоит отметить, что при создании SSDL загрузка почти полностью тратится на SQL Server, в то время как компьютер разработки клиента ожидает простоя, чтобы результаты вернулись с сервера. Базы данных должны особенно ценить это улучшение. Кроме того, стоит отметить, что в настоящее время в поколении представлений происходит все затраты на создание моделей.
7.3 Разделение больших моделей с помощью базы данных first и model First
По мере увеличения размера модели поверхность конструктора становится загромождительной и сложной. Обычно мы считаем модель с более чем 300 сущностями слишком большими, чтобы эффективно использовать конструктор. В следующей записи блога описывается несколько вариантов разделения больших моделей: <https://learn.microsoft.com/archive/blogs/adonet/working-with-large-models-in-entity-framework-part-2>
Запись была написана для первой версии Entity Framework, но шаги по-прежнему применяются.
7.4 Рекомендации по повышению производительности с помощью элемента управления источниками данных сущности
Мы видели случаи в многопоточных тестах производительности и стресс-тестах, где производительность веб-приложения с помощью Элемента управления EntityDataSource значительно ухудшается. Основная причина заключается в том, что EntityDataSource неоднократно вызывает MetadataWorkspace.LoadFromAssembly на сборки, на которые ссылается веб-приложение, чтобы обнаружить типы, используемые в качестве сущностей.
Решение заключается в том, чтобы задать ContextTypeName объекта EntityDataSource имя типа производного класса ObjectContext. Это отключает механизм проверки всех ссылочных сборок для типов сущностей.
Задание поля ContextTypeName также предотвращает функциональную проблему, когда EntityDataSource в .NET 4.0 создает Рефлексия ionTypeLoadException, если он не может загрузить тип из сборки с помощью отражения. Эта проблема устранена в .NET 4.5.
7.5 сущностей POCO и прокси-серверов отслеживания изменений
Entity Framework позволяет использовать пользовательские классы данных вместе с моделью данных без внесения изменений в сами классы данных. Это означает, что с моделью данных могут быть использованы традиционные объекты среды CLR (POCO), например существующие объекты домена. Эти классы данных POCO (также известные как невнимаемые объекты сохраняемости), которые сопоставляются с сущностями, определенными в модели данных, поддерживают большую часть того же запроса, вставки, обновления и удаления поведения как типы сущностей, созданные средствами модели данных сущностей.
Entity Framework также может создавать прокси-классы, производные от типов POCO, которые используются при включении таких функций, как отложенная загрузка и автоматическое отслеживание изменений в сущностях POCO. Классы POCO должны соответствовать определенным требованиям, чтобы разрешить Entity Framework использовать прокси-серверы, как описано ниже http://msdn.microsoft.com/library/dd468057.aspx.
Вероятность того, что прокси-серверы отслеживания будут уведомлять диспетчер состояний объекта каждый раз, когда любой из свойств сущностей изменил свое значение, поэтому Entity Framework знает фактическое состояние сущностей все время. Это делается путем добавления событий уведомлений в текст методов задания свойств и обработки таких событий диспетчера состояний объекта. Обратите внимание, что создание сущности прокси-сервера обычно будет дороже, чем создание сущности POCO, отличной от прокси-сервера, из-за добавленного набора событий, созданных Entity Framework.
Если у сущности POCO нет прокси-сервера отслеживания изменений, изменения обнаруживаются путем сравнения содержимого сущностей с копией предыдущего сохраненного состояния. Это глубокое сравнение станет длительным процессом, если у вас есть много сущностей в контексте, или когда сущности имеют очень большое количество свойств, даже если ни один из них не изменился с момента последнего сравнения.
В сводке: вы платите за производительность при создании прокси-сервера отслеживания изменений, но отслеживание изменений поможет ускорить процесс обнаружения изменений, когда сущности имеют множество свойств или при наличии множества сущностей в модели. Для сущностей с небольшим количеством свойств, где количество сущностей не увеличивается слишком много, наличие прокси-серверов отслеживания изменений может оказаться не очень полезным.
8 Загрузка связанных сущностей
8.1 Отложенная загрузка и страстная загрузка
Entity Framework предлагает несколько различных способов загрузки сущностей, связанных с целевой сущностью. Например, при запросе на продукты существуют различные способы загрузки связанных заказов в диспетчер состояний объектов. С точки зрения производительности, самый большой вопрос, который следует учитывать при загрузке связанных сущностей, будет ли использовать отложенную загрузку или стремленную загрузку.
При использовании стремленной загрузки связанные сущности загружаются вместе с целевым набором сущностей. Вы используете инструкцию Include в запросе, чтобы указать, какие связанные сущности необходимо добавить.
При использовании отложенной загрузки исходный запрос выполняется только в целевом наборе сущностей. Но всякий раз, когда вы обращаетесь к свойству навигации, другой запрос выдается в хранилище для загрузки связанной сущности.
После загрузки сущности все дальнейшие запросы для сущности будут загружаться непосредственно из диспетчера состояний объектов, независимо от того, используете ли вы отложенную загрузку или неустранимую загрузку.
8.2 Как выбрать между отложенной загрузкой и охотной загрузкой
Важно понимать разницу между отложенной загрузкой и активной загрузкой, чтобы сделать правильный выбор для вашего приложения. Это поможет оценить компромисс между несколькими запросами к базе данных и одним запросом, который может содержать большие полезные данные. Может потребоваться использовать стремленную загрузку в некоторых частях приложения и отложенную загрузку в других частях.
Как пример того, что происходит под капотом, предположим, вы хотите запросить клиентов, которые живут в Великобритании и их подсчет заказов.
Использование активной загрузки
using (NorthwindEntities context = new NorthwindEntities())
{
var ukCustomers = context.Customers.Include(c => c.Orders).Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Использование отложенной загрузки
using (NorthwindEntities context = new NorthwindEntities())
{
context.ContextOptions.LazyLoadingEnabled = true;
//Notice that the Include method call is missing in the query
var ukCustomers = context.Customers.Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
При использовании активной загрузки вы получите один запрос, который возвращает всех клиентов и все заказы. Команда хранилища выглядит следующим образом:
SELECT
[Project1].[C1] AS [C1],
[Project1].[CustomerID] AS [CustomerID],
[Project1].[CompanyName] AS [CompanyName],
[Project1].[ContactName] AS [ContactName],
[Project1].[ContactTitle] AS [ContactTitle],
[Project1].[Address] AS [Address],
[Project1].[City] AS [City],
[Project1].[Region] AS [Region],
[Project1].[PostalCode] AS [PostalCode],
[Project1].[Country] AS [Country],
[Project1].[Phone] AS [Phone],
[Project1].[Fax] AS [Fax],
[Project1].[C2] AS [C2],
[Project1].[OrderID] AS [OrderID],
[Project1].[CustomerID1] AS [CustomerID1],
[Project1].[EmployeeID] AS [EmployeeID],
[Project1].[OrderDate] AS [OrderDate],
[Project1].[RequiredDate] AS [RequiredDate],
[Project1].[ShippedDate] AS [ShippedDate],
[Project1].[ShipVia] AS [ShipVia],
[Project1].[Freight] AS [Freight],
[Project1].[ShipName] AS [ShipName],
[Project1].[ShipAddress] AS [ShipAddress],
[Project1].[ShipCity] AS [ShipCity],
[Project1].[ShipRegion] AS [ShipRegion],
[Project1].[ShipPostalCode] AS [ShipPostalCode],
[Project1].[ShipCountry] AS [ShipCountry]
FROM ( SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax],
1 AS [C1],
[Extent2].[OrderID] AS [OrderID],
[Extent2].[CustomerID] AS [CustomerID1],
[Extent2].[EmployeeID] AS [EmployeeID],
[Extent2].[OrderDate] AS [OrderDate],
[Extent2].[RequiredDate] AS [RequiredDate],
[Extent2].[ShippedDate] AS [ShippedDate],
[Extent2].[ShipVia] AS [ShipVia],
[Extent2].[Freight] AS [Freight],
[Extent2].[ShipName] AS [ShipName],
[Extent2].[ShipAddress] AS [ShipAddress],
[Extent2].[ShipCity] AS [ShipCity],
[Extent2].[ShipRegion] AS [ShipRegion],
[Extent2].[ShipPostalCode] AS [ShipPostalCode],
[Extent2].[ShipCountry] AS [ShipCountry],
CASE WHEN ([Extent2].[OrderID] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C2]
FROM [dbo].[Customers] AS [Extent1]
LEFT OUTER JOIN [dbo].[Orders] AS [Extent2] ON [Extent1].[CustomerID] = [Extent2].[CustomerID]
WHERE N'UK' = [Extent1].[Country]
) AS [Project1]
ORDER BY [Project1].[CustomerID] ASC, [Project1].[C2] ASC
При использовании отложенной загрузки сначала вы получите следующий запрос:
SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax]
FROM [dbo].[Customers] AS [Extent1]
WHERE N'UK' = [Extent1].[Country]
И каждый раз, когда вы обращаетесь к свойству навигации Orders клиента другой запрос, как показано ниже, выдается в магазине:
exec sp_executesql N'SELECT
[Extent1].[OrderID] AS [OrderID],
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[EmployeeID] AS [EmployeeID],
[Extent1].[OrderDate] AS [OrderDate],
[Extent1].[RequiredDate] AS [RequiredDate],
[Extent1].[ShippedDate] AS [ShippedDate],
[Extent1].[ShipVia] AS [ShipVia],
[Extent1].[Freight] AS [Freight],
[Extent1].[ShipName] AS [ShipName],
[Extent1].[ShipAddress] AS [ShipAddress],
[Extent1].[ShipCity] AS [ShipCity],
[Extent1].[ShipRegion] AS [ShipRegion],
[Extent1].[ShipPostalCode] AS [ShipPostalCode],
[Extent1].[ShipCountry] AS [ShipCountry]
FROM [dbo].[Orders] AS [Extent1]
WHERE [Extent1].[CustomerID] = @EntityKeyValue1',N'@EntityKeyValue1 nchar(5)',@EntityKeyValue1=N'AROUT'
Дополнительные сведения см. в разделе "Загрузка связанных объектов".
8.2.1 Отложенная загрузка и страстная загрузка памятка
Нет такой вещи, как one-size-fits-all, чтобы выбрать страстную загрузку и отложенную загрузку. Сначала попробуйте понять различия между обеими стратегиями, чтобы вы могли сделать хорошо информированное решение; кроме того, рассмотрите, соответствует ли код любому из следующих сценариев:
| Сценарий | Наше предложение |
|---|---|
| Требуется ли получить доступ ко многим свойствам навигации из полученных сущностей? | Нет - Оба варианта, вероятно, будут делать. Тем не менее, если полезные данные, которые ваш запрос приносит, не слишком большой, вы можете воспользоваться преимуществами производительности, используя стремленную загрузку, так как для материализации объектов потребуется меньше сетевых обходов. Да . Если вам нужно получить доступ ко многим свойствам навигации из сущностей, это можно сделать с помощью нескольких инструкций включения в запрос с помощью охотной загрузки. Чем больше сущностей вы включаете, тем больше полезные данные запроса возвращаются. После включения трех или более сущностей в запрос рассмотрите возможность переключения на отложенную загрузку. |
| Знаете ли вы точно, какие данные потребуются во время выполнения? | Нет - Отложенная загрузка будет лучше для вас. В противном случае вы можете запросить данные, которые вам не понадобятся. Да- Страстная загрузка, вероятно, является вашей лучшей ставкой; это поможет ускорить загрузку целых наборов. Если запросу требуется получить очень большой объем данных, и это становится слишком медленным, а затем попробуйте отложенную загрузку. |
| Выполняется ли ваш код далеко от базы данных? (увеличение задержки сети) | Нет . Если задержка в сети не является проблемой, использование отложенной загрузки может упростить код. Помните, что топология приложения может измениться, поэтому не имейте в виду, что база данных не будет предоставлена. Да . Если сеть является проблемой, только вы можете решить, что лучше подходит для вашего сценария. Как правило, страстная загрузка будет лучше, так как она требует меньше круговых путей. |
8.2.2. Проблемы с производительностью с несколькими включает
Когда мы слышим вопросы о производительности, связанные с проблемами времени отклика сервера, источник проблемы часто запрашивается с несколькими операторами Include. Несмотря на то, что связанные сущности в запросе мощны, важно понять, что происходит под обложкой.
Для запроса с несколькими операторами Include в запросе требуется относительно длительное время, чтобы пройти через наш внутренний компилятор плана для создания команды хранилища. Большая часть этого времени тратится на оптимизацию результирующего запроса. Созданная команда хранилища будет содержать внешнее соединение или объединение для каждого включения в зависимости от сопоставления. Такие запросы будут содержать большие подключенные графы из базы данных в одной полезной нагрузке, что приведет к возникновению проблем с пропускной способностью, особенно при наличии большого количества избыточности полезных данных (например, при использовании нескольких уровней include для обхода связей в направлении "один ко многим").
Вы можете проверка в случаях, когда запросы возвращают чрезмерно большие полезные данные, доступ к базовому TSQL для запроса с помощью ToTraceString и выполнения команды хранилища в SQL Server Management Studio для просмотра размера полезных данных. В таких случаях можно попытаться уменьшить количество инструкций Include в запросе, чтобы просто привести необходимые данные. Или вы можете разбить запрос на меньшую последовательность вложенных запросов, например:
Перед нарушением запроса:
using (NorthwindEntities context = new NorthwindEntities())
{
var customers = from c in context.Customers.Include(c => c.Orders)
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
После нарушения запроса:
using (NorthwindEntities context = new NorthwindEntities())
{
var orders = from o in context.Orders
where o.Customer.LastName.StartsWith(lastNameParameter)
select o;
orders.Load();
var customers = from c in context.Customers
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Это будет работать только в отслеживаемых запросах, так как мы используем возможность, что контекст должен выполнять разрешение удостоверений и исправление связи автоматически.
Как и при отложенной загрузке, компромисс будет больше запросов для небольших полезных данных. Вы также можете использовать проекции отдельных свойств для явного выбора только данных, необходимых для каждой сущности, но в этом случае вы не будете загружать сущности, а обновления не будут поддерживаться.
8.2.3 Обходной путь для отложенной загрузки свойств
Entity Framework в настоящее время не поддерживает отложенную загрузку скалярных или сложных свойств. Однако в случаях, когда у вас есть таблица, содержащая большой объект, например БОЛЬШОЙ ДВОИЧНЫй объект, можно использовать разделение таблицы для разделения больших свойств на отдельную сущность. Например, предположим, что у вас есть таблица Product, содержащая столбец фотографии varbinary. Если вам не нужно часто обращаться к этому свойству в запросах, можно использовать разделение таблицы, чтобы перенести только части сущности, которую обычно требуется. Сущность, представляющая фотографию продукта, будет загружена только при явной необходимости.
Хороший ресурс, показывающий, как включить разделение таблиц, — это запись блога Гил Финка "Разделение таблиц в Entity Framework". <http://blogs.microsoft.co.il/blogs/gilf/archive/2009/10/13/table-splitting-in-entity-framework.aspx>
9 Другие вопросы
Сборка мусора сервера 9.1
Некоторые пользователи могут столкнуться с спором ресурсов, ограничивающим параллелизм, который ожидается, когда сборщик мусора неправильно настроен. Если EF используется в многопоточных сценариях или в любом приложении, которое напоминает серверную систему, обязательно включите сборку мусора сервера. Это делается с помощью простого параметра в файле конфигурации приложения:
<?xmlversion="1.0" encoding="utf-8" ?>
<configuration>
<runtime>
<gcServer enabled="true" />
</runtime>
</configuration>
Это должно уменьшить количество разных потоков и увеличить пропускную способность до 30 % в сценариях с насыщенными ЦП. Как правило, всегда следует проверить поведение приложения с помощью классической сборки мусора (которая лучше настроена для сценариев пользовательского интерфейса и клиентской стороны), а также сборку мусора сервера.
9.2 AutoDetectChanges
Как упоминание ранее, Entity Framework может отображать проблемы с производительностью, когда кэш объектов имеет множество сущностей. Некоторые операции, такие как Add, Remove, Find, Entry и SaveChanges, активируют вызовы к DetectChanges, которые могут потреблять большое количество ЦП на основе того, насколько большой кэш объектов стал. Причиной этого является то, что кэш объектов и диспетчер состояний объектов пытаются оставаться синхронизированными по мере возможности для каждой операции, выполняемой в контексте, чтобы созданные данные гарантированно были исправлены в широком массиве сценариев.
Как правило, рекомендуется оставить автоматическое обнаружение изменений Entity Framework включено для всей жизни приложения. Если ваш сценарий негативно влияет на использование ЦП и профили указывают на то, что виновник является вызовом DetectChanges, попробуйте временно отключить AutoDetectChanges в конфиденциальной части кода:
try
{
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
...
}
finally
{
context.Configuration.AutoDetectChangesEnabled = true;
}
Прежде чем отключить AutoDetectChanges, рекомендуется понять, что это может привести к тому, что Entity Framework потеряет возможность отслеживать определенные сведения об изменениях, происходящих на сущностях. При неправильной обработке это может привести к несоответствию данных в приложении. Дополнительные сведения об отключении autoDetectChanges см. в статье <http://blog.oneunicorn.com/2012/03/12/secrets-of-detectchanges-part-3-switching-off-automatic-detectchanges/>.
9.3 Контекст для каждого запроса
Контексты Entity Framework предназначены для использования в качестве кратковременных экземпляров, чтобы обеспечить наиболее оптимальную производительность. Контексты, как ожидается, будут короткими и не карта, и такие возможности были реализованы для очень упрощенного и повторного использования метаданных по возможности. В веб-сценариях важно помнить об этом и не иметь контекста в течение большей продолжительности одного запроса. Аналогичным образом, в сценариях, отличных от веб-сайтов, контекст должен быть отключен карта на основе понимания различных уровней кэширования в Entity Framework. Как правило, следует избегать экземпляра контекста в течение всей жизни приложения, а также контекстов для каждого потока и статических контекстов.
9.4 Семантика базы данных NULL
Entity Framework по умолчанию создает код SQL, имеющий семантику сравнения значений NULL C#. Рассмотрим следующий пример запроса:
int? categoryId = 7;
int? supplierId = 8;
decimal? unitPrice = 0;
short? unitsInStock = 100;
short? unitsOnOrder = 20;
short? reorderLevel = null;
var q = from p incontext.Products
where p.Category.CategoryName == "Beverages"
|| (p.CategoryID == categoryId
|| p.SupplierID == supplierId
|| p.UnitPrice == unitPrice
|| p.UnitsInStock == unitsInStock
|| p.UnitsOnOrder == unitsOnOrder
|| p.ReorderLevel == reorderLevel)
select p;
var r = q.ToList();
В этом примере мы сравниваем ряд переменных, допускающих значение NULL, с свойствами, допускающими значение NULL, в сущности, например SupplierID и UnitPrice. Созданный SQL для этого запроса запрашивает, совпадает ли значение параметра со значением столбца, или если значения столбца и параметр имеют значение NULL. Это позволит скрыть способ обработки значений NULL сервера базы данных и обеспечит согласованный интерфейс C# null для разных поставщиков баз данных. С другой стороны, созданный код немного сверток и может не выполняться хорошо, когда количество сравнений в инструкции запроса растет до большого числа.
Одним из способов решения этой ситуации является использование семантики null базы данных. Обратите внимание, что это может работать по-разному семантикой C# null, так как теперь Entity Framework создаст более простой SQL, который предоставляет способ обработки значений NULL ядром СУБД. Семантику null базы данных можно активировать для каждого контекста с одной строкой конфигурации для конфигурации контекста:
context.Configuration.UseDatabaseNullSemantics = true;
При использовании семантики null базы данных небольшие к среднему размеру запросы не будут отображаться заметное улучшение производительности при использовании семантики null базы данных, но разница станет более заметной в запросах с большим количеством потенциальных сравнений значений NULL.
В приведенном выше примере запроса разница производительности составила менее 2 % в микробнчмарке, работающей в управляемой среде.
9.5 Асинхронная синхронизация
Entity Framework 6 представила поддержку асинхронных операций при запуске в .NET 4.5 или более поздней версии. В большинстве случаев приложения с связанными операциями ввода-вывода помогут использовать асинхронные запросы и операции сохранения. Если приложение не страдает от состязания операций ввода-вывода, использование асинхронного выполнения в лучших случаях выполняется синхронно и возвращает результат в том же количестве времени, что и синхронный вызов, или в худшем случае просто отложит выполнение асинхронной задачи и добавит дополнительное время к завершению сценария.
Сведения о том, как работает асинхронное программирование, которое поможет вам решить, улучшит ли асинхронное программирование приложения, см. в статье "Асинхронное программирование" и "Ожидание". Дополнительные сведения об использовании асинхронных операций в Entity Framework см. в статье "Асинхронный запрос" и "Сохранить".
9.6 NGEN
Entity Framework 6 не выполняет установку платформы .NET по умолчанию. Таким образом, сборки Entity Framework по умолчанию не являются NGEN'd, что означает, что весь код Entity Framework зависит от одной и той же стоимости JIT,что и любая другая сборка MSIL. Это может снизить производительность F5 при разработке и холодном запуске приложения в рабочих средах. Чтобы сократить затраты на ЦП и память JIT'ing, рекомендуется использовать NGEN образов Entity Framework соответствующим образом. Дополнительные сведения о том, как повысить производительность запуска Entity Framework 6 с NGEN, см. в статье "Повышение производительности запуска с помощью NGen".
9.7 Code First и EDMX
Причины несоответствия сущности Entity Framework о несоответствии между объектно-ориентированными и реляционными базами данных путем представления концептуальной модели (объектов), схемы хранилища (базы данных) и сопоставления между этими двумя. Эти метаданные называются моделью данных сущности или EDM. Из этого EDM Entity Framework наследует представления для округления данных из объектов в памяти в базу данных и обратно.
Если Entity Framework используется с файлом EDMX, который официально указывает концептуальную модель, схему хранения и сопоставление, то этап загрузки модели должен проверить правильность EDM (например, убедитесь, что сопоставления отсутствуют), а затем создайте представления, а затем проверьте представления и убедитесь, что эти метаданные готовы для использования. Только после этого запрос можно выполнить или сохранить новые данные в хранилище данных.
Первый подход к коду — это в его основе сложный генератор модели данных сущностей. Entity Framework должен создать EDM из предоставленного кода; Это делается путем анализа классов, участвующих в модели, применения соглашений и настройки модели с помощью API Fluent. После создания EDM платформа Entity Framework по сути ведет себя так же, как и EDMX-файл в проекте. Таким образом, создание модели из Code First добавляет дополнительную сложность, которая преобразуется в более медленное время запуска для Entity Framework по сравнению с EDMX. Стоимость полностью зависит от размера и сложности создаваемой модели.
При выборе использования EDMX и Code First важно знать, что гибкость, представленная code First, увеличивает стоимость создания модели в первый раз. Если приложение может выдержать затраты на эту первую загрузку, обычно code First будет предпочтительным способом перехода.
10 Исследование производительности
10.1 С помощью Профилировщика Visual Studio
Если у вас возникли проблемы с производительностью в Entity Framework, можно использовать профилировщик, например встроенный в Visual Studio, чтобы узнать, где ваше приложение тратит свое время. Это средство, которое мы использовали для создания круговых диаграмм в статье "Изучение производительности ADO.NET Entity Framework — часть 1" записи блога ( <https://learn.microsoft.com/archive/blogs/adonet/exploring-the-performance-of-the-ado-net-entity-framework-part-1>), которая показывает, где Entity Framework тратит свое время во время холодных и теплых запросов.
Запись блога "Профилирование Entity Framework с помощью профилировщика Visual Studio 2010", написанная группой консультантов по анализу данных и моделирования клиентов, показывает реальный пример использования профилировщика для исследования проблемы производительности. <https://learn.microsoft.com/archive/blogs/dmcat/profiling-entity-framework-using-the-visual-studio-2010-profiler>. Эта запись была написана для приложения Windows. Если вам нужно профилировать веб-приложение, средства записи производительности Windows (WPR) и Windows Анализатор производительности (WPA) могут работать лучше, чем работать из Visual Studio. WPR и WPA являются частью набор средств производительности Windows, которая входит в комплект средств оценки и развертывания Windows.
10.2 Профилирование приложений и баз данных
Такие инструменты, как профилировщик, встроенный в Visual Studio, сообщают вам, где ваше приложение тратит время. Другой тип профилировщика доступен, который выполняет динамический анализ запущенного приложения в рабочей или предварительной среде в зависимости от потребностей и ищет распространенные ошибки и антишаблоны доступа к базам данных.
Два коммерчески доступных профилировщика — Entity Framework Profiler ( <http://efprof.com>) и ORMProfiler ( <http://ormprofiler.com>).
Если приложение является приложением MVC с помощью кода First, можно использовать MiniProfiler StackExchange. Скотт Ханселман описывает это средство в своем блоге: <http://www.hanselman.com/blog/NuGetPackageOfTheWeek9ASPNETMiniProfilerFromStackExchangeRocksYourWorld.aspx>
Дополнительные сведения о профилировании активности базы данных приложения см. в статье Msdn Magazine Julie Lerman в разделе " Активность базы данных профилирования" в Entity Framework.
10.3 Средство ведения журнала базы данных
Если вы используете Entity Framework 6, также рассмотрите возможность использования встроенных функций ведения журнала. Свойство Базы данных контекста может быть показано, чтобы регистрировать его действия с помощью простой однострочный конфигурации:
using (var context = newQueryComparison.DbC.NorthwindEntities())
{
context.Database.Log = Console.WriteLine;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
В этом примере действие базы данных будет зарегистрировано в консоли, но свойство журнала можно настроить для вызова любого делегата строки> действия<.
Если вы хотите включить ведение журнала баз данных без повторной компиляции, и вы используете Entity Framework 6.1 или более поздней версии, это можно сделать, добавив перехватчик в файл web.config или app.config приложения.
<interceptors>
<interceptor type="System.Data.Entity.Infrastructure.Interception.DatabaseLogger, EntityFramework">
<parameters>
<parameter value="C:\Path\To\My\LogOutput.txt"/>
</parameters>
</interceptor>
</interceptors>
Дополнительные сведения о добавлении ведения журнала без повторной компиляции см. в <http://blog.oneunicorn.com/2014/02/09/ef-6-1-turning-on-logging-without-recompiling/>раздел .
Приложение 11
11.1 А. Тестовая среда
Эта среда использует 2-компьютерную настройку с базой данных на отдельном компьютере от клиентского приложения. Компьютеры находятся в одной стойке, поэтому задержка сети относительно низкая, но более реалистичная, чем среда с одним компьютером.
Сервер приложений 11.1.1
11.1.1.1 Программное обеспечение
- Среда программного обеспечения Entity Framework 4
- Имя ОС: Windows Server 2008 R2 Корпоративная с пакетом обновления 1 (SP1).
- Visual Studio 2010 — Ultimate.
- Visual Studio 2010 с пакетом обновления 1 (SP1) (только для некоторых сравнений).
- Среда программного обеспечения Entity Framework 5 и 6
- Имя ОС: Windows 8.1 Корпоративная
- Visual Studio 2013 — Ultimate.
11.1.1.2 Аппаратная среда
- Двойной процессор: Процессор Intel(R) Xeon(R) ЦП L5520 W3530 @ 2,27GГц, 2261 ГГц8 ГГц, 4 ядра, 84 логических процессора.
- 2412 ГБ RamRAM.
- 136 ГБ SCSI250GB SATA 7200 rpm 3GB/s диск разделен на 4 секции.
Сервер базы данных 11.1.2
11.1.2.1 Программное обеспечение
- Имя ОС: Windows Server 2008 R28.1 Корпоративная с пакетом обновления 1 (SP1).
- SQL Server 2008 R22012.
Среда оборудования 11.1.2.2
- Один процессор: Intel(R) Xeon(R) ЦП L5520 @ 2,27 ГГц, 2261 MhzES-1620 0 @ 3,60GГц, 4 ядра, 8 логических процессоров.
- 824 ГБ RamRAM.
- 465 ГБ ATA500GB ДИСК SATA 7200 rpm 6GB/s разделен на 4 секции.
11.2 B. Тесты сравнения производительности запросов
Модель Northwind использовалась для выполнения этих тестов. Он был создан из базы данных с помощью конструктора Entity Framework. Затем для сравнения производительности параметров выполнения запроса использовался следующий код:
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.Common;
using System.Data.Entity.Infrastructure;
using System.Data.EntityClient;
using System.Data.Objects;
using System.Linq;
namespace QueryComparison
{
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IQueryable<Product> InvokeProductsForCategoryCQ(string categoryName)
{
return productsForCategoryCQ(this, categoryName);
}
}
public class QueryTypePerfComparison
{
private static string entityConnectionStr = @"metadata=res://*/Northwind.csdl|res://*/Northwind.ssdl|res://*/Northwind.msl;provider=System.Data.SqlClient;provider connection string='data source=.;initial catalog=Northwind;integrated security=True;multipleactiveresultsets=True;App=EntityFramework'";
public void LINQIncludingContextCreation()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTracking()
{
using (NorthwindEntities context = new NorthwindEntities())
{
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void CompiledQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.InvokeProductsForCategoryCQ("Beverages");
q.ToList();
}
}
public void ObjectQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
products.ToList();
}
}
public void EntityCommand()
{
using (EntityConnection eConn = new EntityConnection(entityConnectionStr))
{
eConn.Open();
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
List<Product> productsList = new List<Product>();
while (reader.Read())
{
DbDataRecord record = (DbDataRecord)reader.GetValue(0);
// 'materialize' the product by accessing each field and value. Because we are materializing products, we won't have any nested data readers or records.
int fieldCount = record.FieldCount;
// Treat all products as Product, even if they are the subtype DiscontinuedProduct.
Product product = new Product();
product.ProductID = record.GetInt32(0);
product.ProductName = record.GetString(1);
product.SupplierID = record.GetInt32(2);
product.CategoryID = record.GetInt32(3);
product.QuantityPerUnit = record.GetString(4);
product.UnitPrice = record.GetDecimal(5);
product.UnitsInStock = record.GetInt16(6);
product.UnitsOnOrder = record.GetInt16(7);
product.ReorderLevel = record.GetInt16(8);
product.Discontinued = record.GetBoolean(9);
productsList.Add(product);
}
}
}
}
public void ExecuteStoreQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectResult<Product> beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Database.SqlQuery\<QueryComparison.DbC.Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbSet()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Products.SqlQuery(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void LINQIncludingContextCreationDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTrackingDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.AsNoTracking().Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
}
}
11.3. Модель Navision
База данных Navision — это большая база данных, используемая для демонстрации Microsoft Dynamics — NAV. Созданная концептуальная модель содержит наборы сущностей 1005 и 4227 наборов ассоциаций. Модель, используемая в тесте, является "плоской" — к ней не добавлено наследование.
11.3.1 Запросы, используемые для тестов Navision
Список запросов, используемый с моделью Navision, содержит 3 категории запросов Entity SQL:
Поиск 11.3.1.1
Простой запрос подстановки без агрегатов
- Число: 16232
- Пример:
<Query complexity="Lookup">
<CommandText>Select value distinct top(4) e.Idle_Time From NavisionFKContext.Session as e</CommandText>
</Query>
11.3.1.2 SingleAggregating
Обычный запрос бизнес-аналитики с несколькими агрегатами, но не промежуточные итоги (один запрос)
- Количество: 2313
- Пример:
<Query complexity="SingleAggregating">
<CommandText>NavisionFK.MDF_SessionLogin_Time_Max()</CommandText>
</Query>
Где MDF_SessionLogin_Time_Max() определяется в модели следующим образом:
<Function Name="MDF_SessionLogin_Time_Max" ReturnType="Collection(DateTime)">
<DefiningExpression>SELECT VALUE Edm.Min(E.Login_Time) FROM NavisionFKContext.Session as E</DefiningExpression>
</Function>
11.3.1.3 АгрегированиеSubtotals
Запрос бизнес-аналитики с агрегатами и промежуточными итогими (через объединение всех)
- Число: 178
- Пример:
<Query complexity="AggregatingSubtotals">
<CommandText>
using NavisionFK;
function AmountConsumed(entities Collection([CRONUS_International_Ltd__Zone])) as
(
Edm.Sum(select value N.Block_Movement FROM entities as E, E.CRONUS_International_Ltd__Bin as N)
)
function AmountConsumed(P1 Edm.Int32) as
(
AmountConsumed(select value e from NavisionFKContext.CRONUS_International_Ltd__Zone as e where e.Zone_Ranking = P1)
)
----------------------------------------------------------------------------------------------------------------------
(
select top(10) Zone_Ranking, Cross_Dock_Bin_Zone, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking, E.Cross_Dock_Bin_Zone
)
union all
(
select top(10) Zone_Ranking, Cast(null as Edm.Byte) as P2, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking
)
union all
{
Row(Cast(null as Edm.Int32) as P1, Cast(null as Edm.Byte) as P2, AmountConsumed(select value E
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed))
}</CommandText>
<Parameters>
<Parameter Name="MinAmountConsumed" DbType="Int32" Value="10000" />
</Parameters>
</Query>
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по