Краткое руководство. Создание первого потока данных для получения и преобразования данных
Потоки данных — это самостоятельная облачная технология подготовки данных. В этой статье вы создадите первый поток данных, получите данные для потока данных, а затем преобразуете данные и опубликуете поток данных.
Необходимые компоненты
Перед началом работы требуются следующие предварительные требования:
- Учетная запись клиента Microsoft Fabric с активной подпиской. Создайте бесплатную учетную запись.
- Убедитесь, что у вас есть рабочая область с поддержкой Microsoft Fabric: создайте рабочую область.
Создание потока данных
В этом разделе вы создаете первый поток данных.
Перейдите к интерфейсу фабрики данных.
Перейдите в рабочую область Microsoft Fabric.

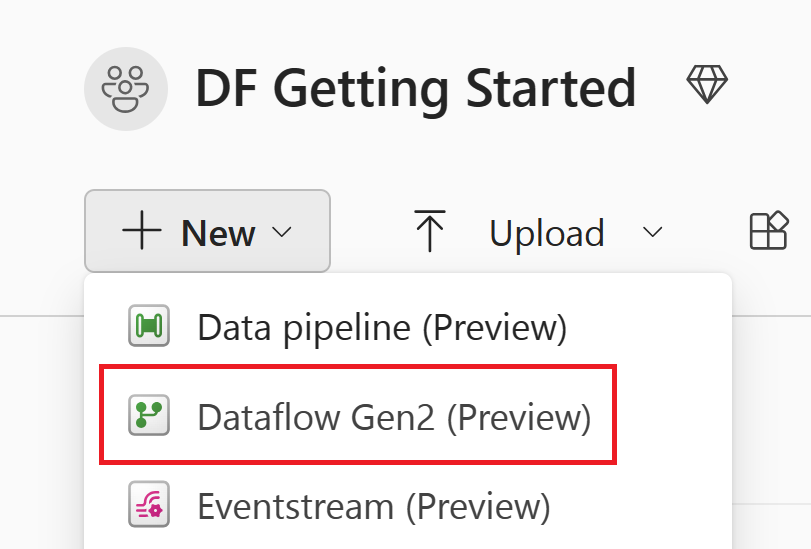
Выберите "Создать" и выберите "Поток данных 2-го поколения".

Получить данные
Давайте получим некоторые данные! В этом примере вы получаете данные из службы OData. Чтобы получить данные в потоке данных, выполните следующие действия.
В редакторе потока данных выберите " Получить данные " и нажмите кнопку "Дополнительно".
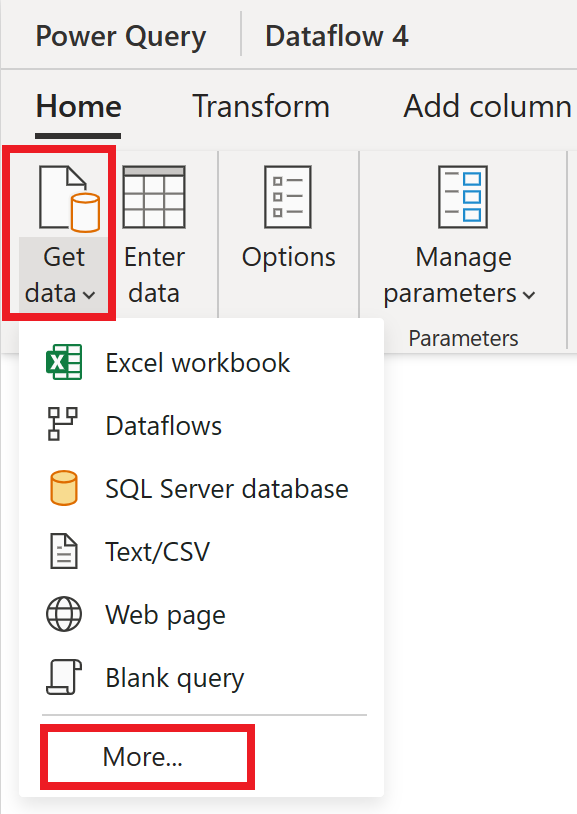
В разделе "Выбор источника данных" выберите "Просмотреть больше".

В новом источнике выберите "Другие>OData" в качестве источника данных.

Введите URL-адрес
https://services.odata.org/v4/northwind/northwind.svc/и нажмите кнопку "Далее".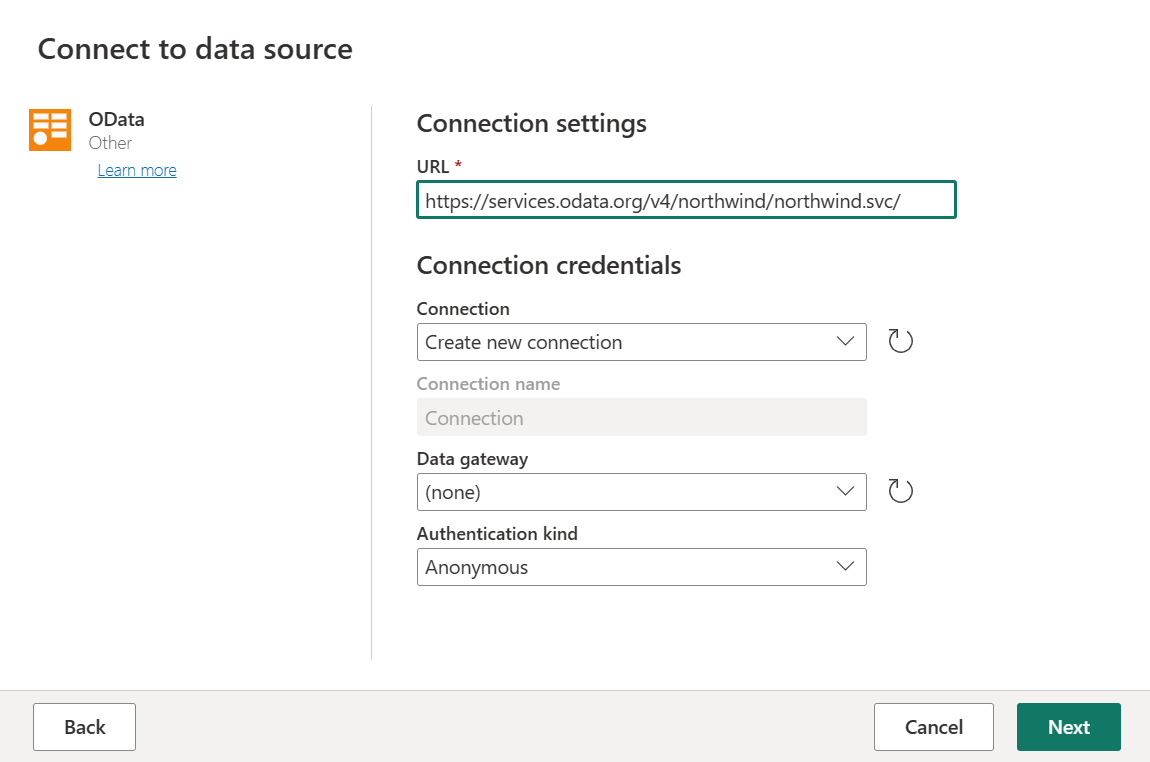
Выберите таблицы "Заказы и клиенты", а затем нажмите кнопку "Создать".




Дополнительные сведения о работе с данными и функциональных возможностях см. в статье "Получение данных".
Применение преобразований и публикация
Теперь вы загрузили данные в первый поток данных, поздравляем! Теперь пришло время применить несколько преобразований, чтобы перенести эти данные в нужную форму.
Вы собираетесь выполнить эту задачу из редактора Power Query. Подробный обзор редактора Power Query можно найти в пользовательском интерфейсе Power Query.
Выполните следующие действия, чтобы применить преобразования и опубликовать:
Убедитесь, что средства профилирования данных включены, перейдя к глобальным параметрам> для дома.>
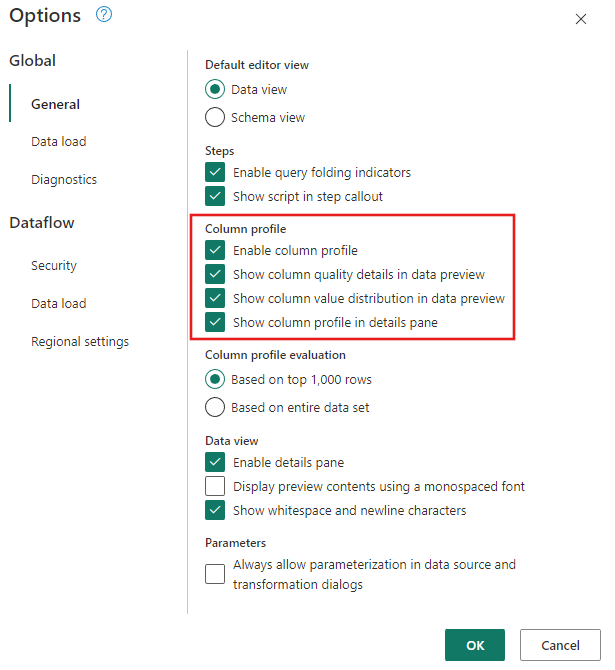
Кроме того, убедитесь, что вы включили представление схемы с помощью параметров на вкладке "Вид " на ленте редактора Power Query или щелкните значок представления схемы в правой нижней части окна Power Query.

В таблице "Заказы" вычислите общее количество заказов на каждого клиента. Чтобы достичь этой цели, выберите столбец CustomerID в предварительном просмотре данных и выберите группировать повкладке "Преобразование " на ленте.

Количество строк выполняется в виде агрегирования в группе By. Дополнительные сведения о возможностях Group By см. в разделе "Группирование" или "Суммирование строк".
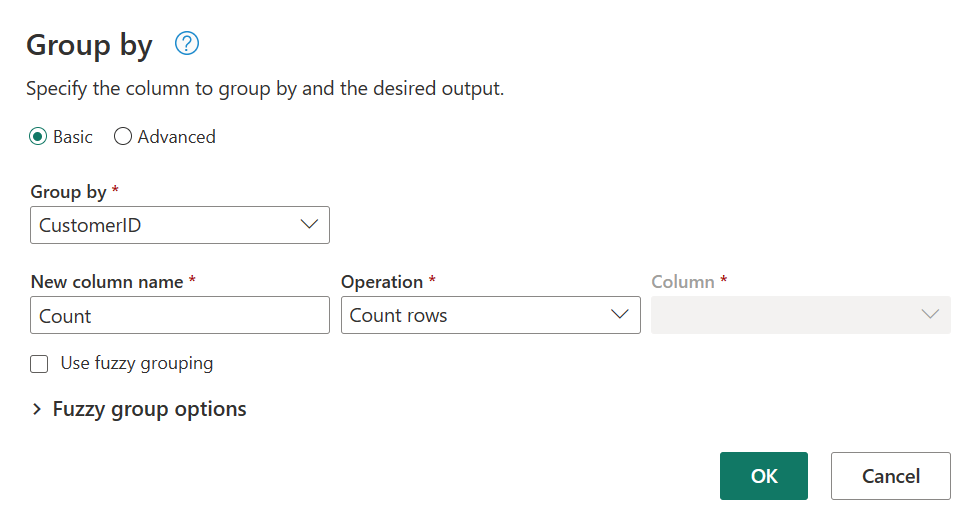
После группировки данных в таблице Orders мы получим таблицу с двумя столбцами с CustomerID и Count в качестве столбцов.

Затем необходимо объединить данные из таблицы "Клиенты" с числом заказов на клиента. Чтобы объединить данные, выберите запрос "Клиенты" в представлении диаграммы и используйте меню "⋮" для доступа к запросам слияния в качестве нового преобразования.

Настройте операцию слияния, как показано на следующем снимке экрана, выбрав CustomerID в качестве соответствующего столбца в обеих таблицах. Затем выберите ОК.
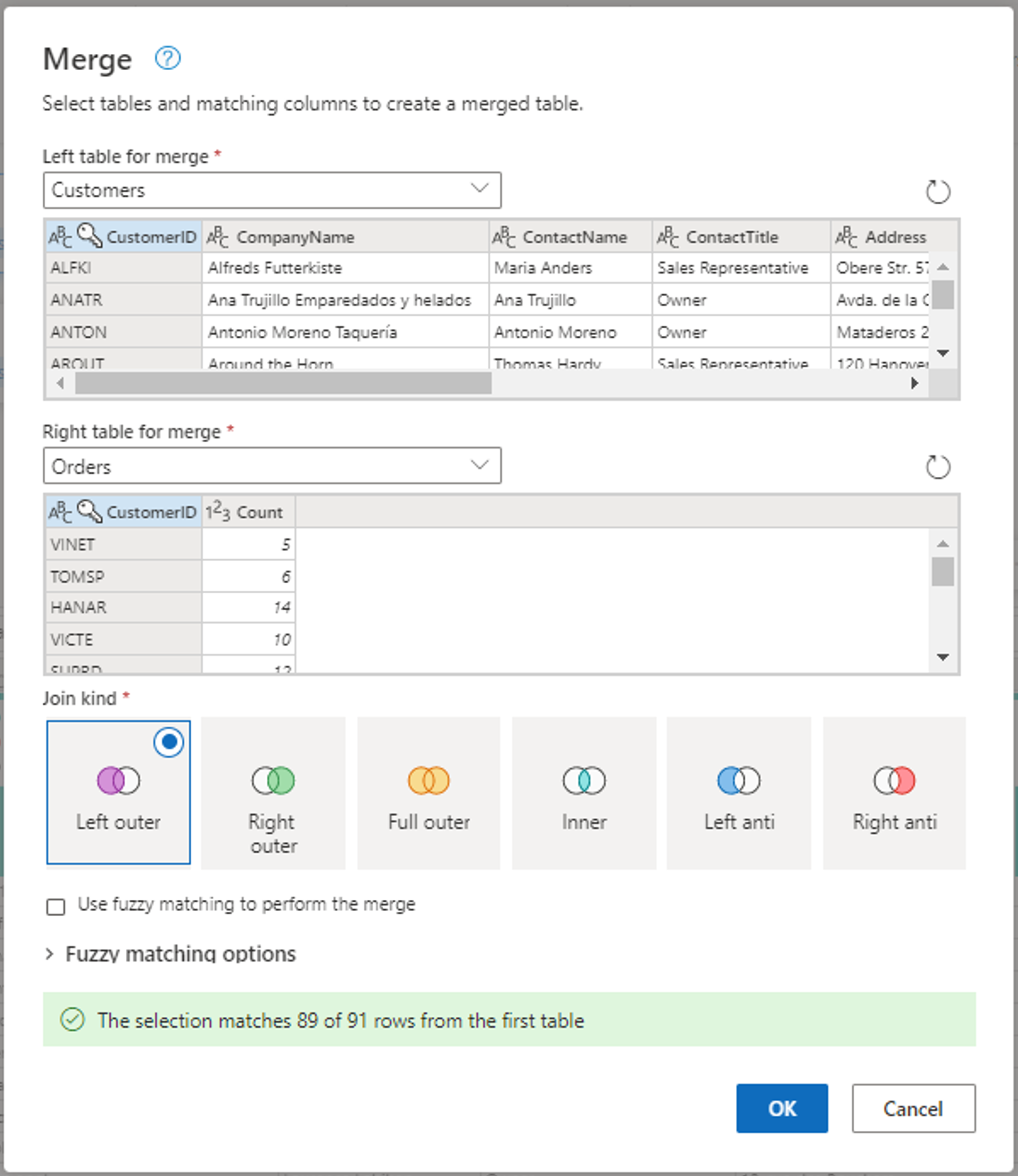
Снимок экрана: окно слияния с левой таблицей для слияния, заданной в таблице Customers, и правой таблицей для слияния, заданной в таблице Orders. Столбец CustomerID выбран для таблиц "Клиенты" и "Заказы". Кроме того, тип соединения имеет значение "Левый внешний". Все остальные выборы задаются по умолчанию.
После выполнения запросов слияния в качестве новой операции вы получите новый запрос со всеми столбцами из таблицы Customers и одного столбца с вложенными данными из таблицы Orders.
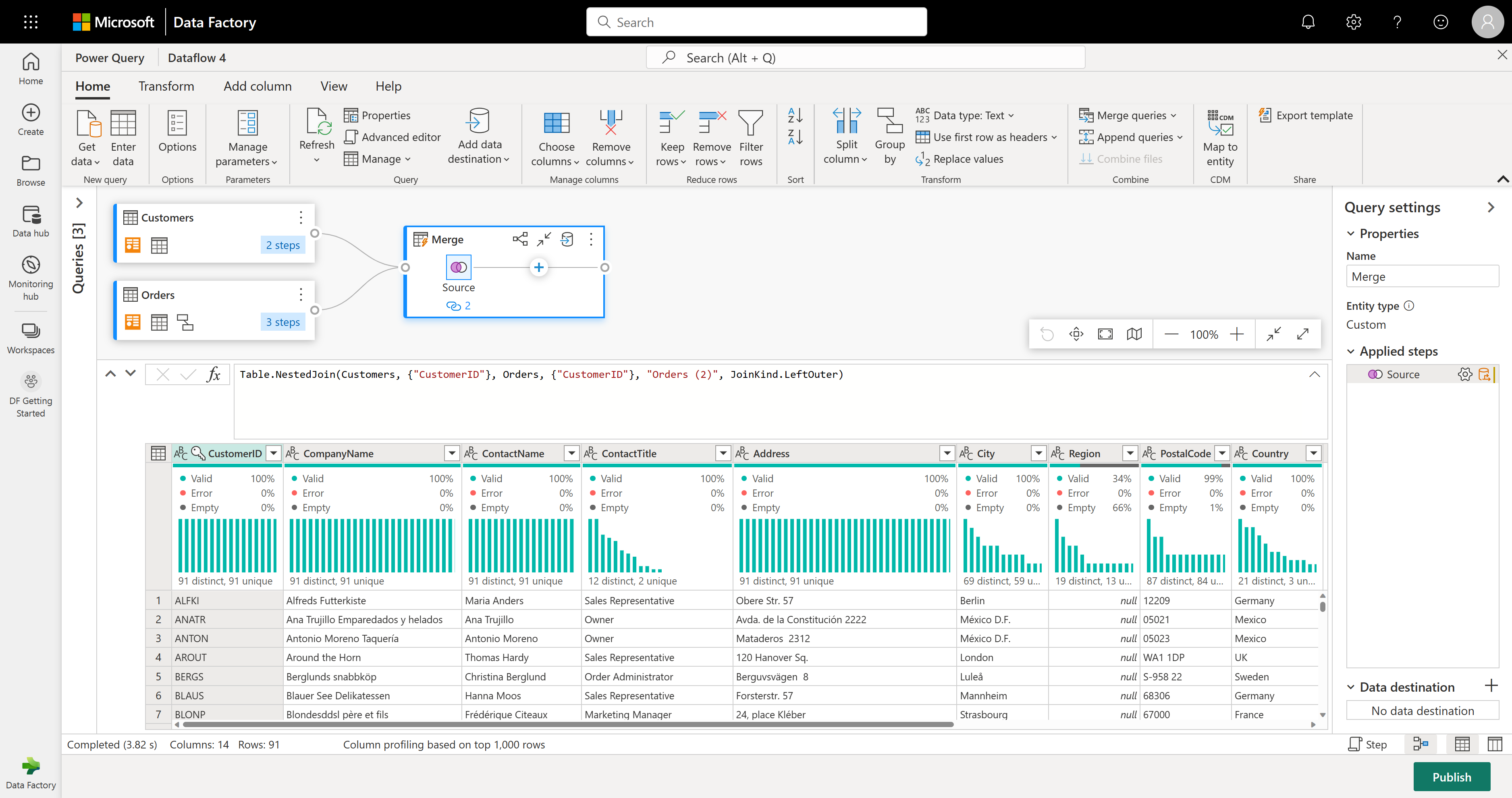
В этом примере вы заинтересованы только в подмножестве столбцов в таблице Customers. Вы выбираете эти столбцы с помощью представления схемы. Включите представление схемы в кнопке переключателя в правом нижнем углу редактора потоков данных.

Представление схемы предоставляет ориентированное представление в сведениях о схеме таблицы, включая имена столбцов и типы данных. Представление схемы содержит набор средств схемы, доступных на вкладке контекстной ленты. В этом сценарии вы выбираете столбцы CustomerID, CompanyName и Orders (2), а затем нажмите кнопку "Удалить столбцы" и выберите "Удалить другие столбцы" на вкладке "Средства схемы".


Столбец Orders (2) содержит вложенные сведения, полученные из операции слияния, которую вы выполнили несколько шагов назад. Теперь переключитесь в представление данных, нажав кнопку "Показать представление данных" рядом с кнопкой "Показать представление схемы" в правом нижнем углу пользовательского интерфейса. Затем используйте преобразование "Развернуть столбец " в заголовке столбца Orders (2) для выбора столбца Count .
В качестве последней операции вы хотите ранжировать клиентов на основе их количества заказов. Выберите столбец Count и нажмите кнопку "Ранжирование столбца" на вкладке "Добавить столбец" на ленте.
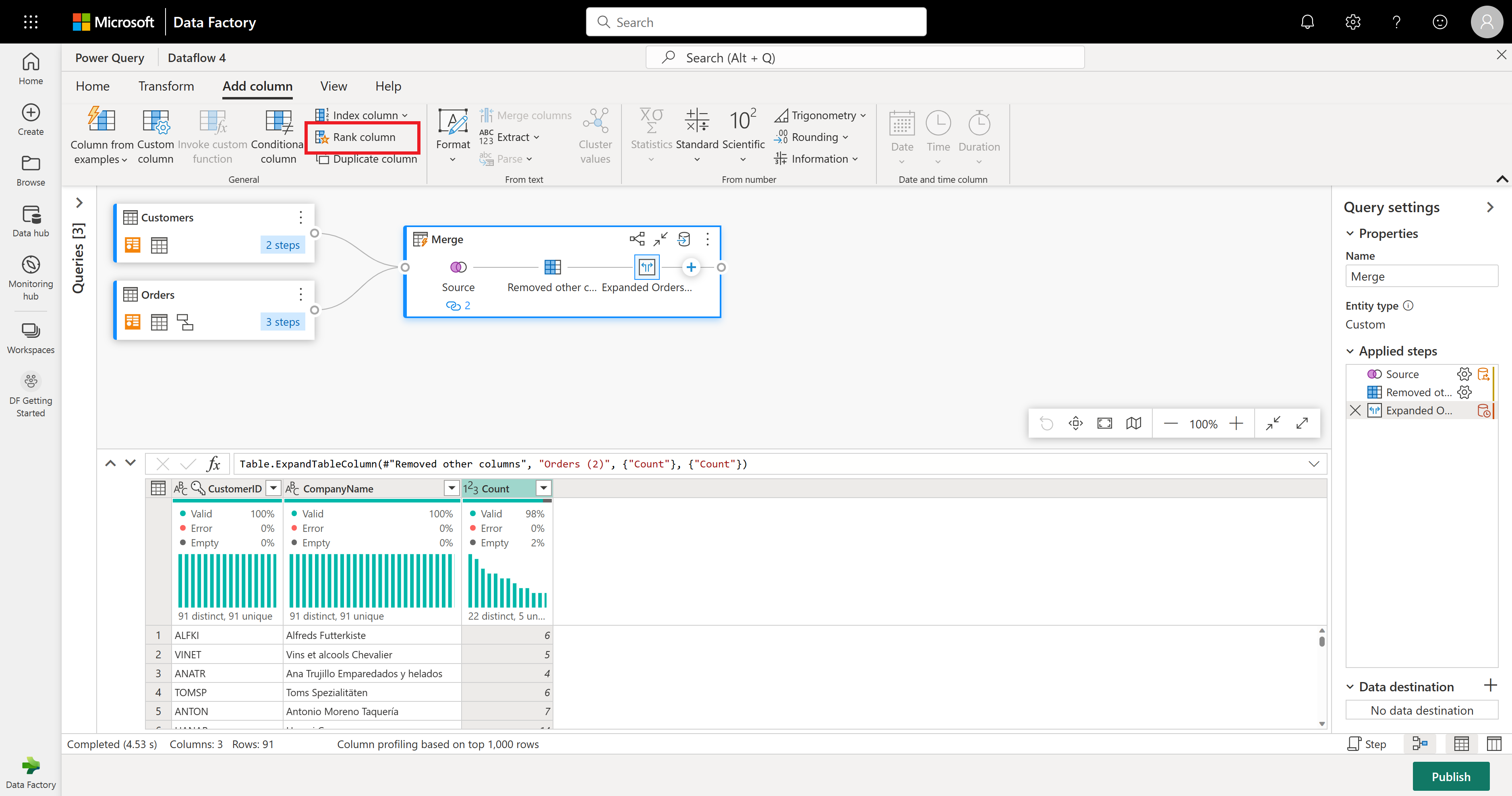
Сохраните параметры по умолчанию в столбце ранжирования. Затем нажмите кнопку "ОК ", чтобы применить это преобразование.
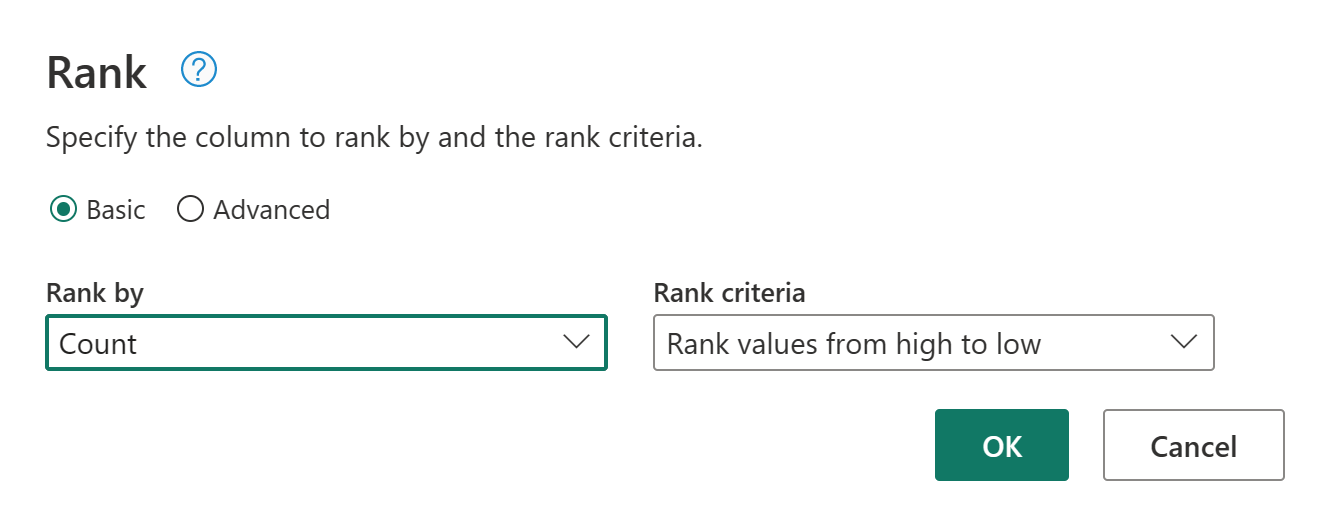
Теперь переименуйте полученный запрос в качестве ранжированных клиентов с помощью области параметров запроса справа от экрана.

Вы завершили преобразование и объединение данных. Таким образом, теперь вы настраиваете параметры назначения выходных данных. Выберите назначение данных в нижней части области параметров запроса.

На этом шаге можно настроить выходные данные в lakehouse, если у вас есть один доступный, или пропустить этот шаг, если вы этого не сделали. В рамках этого интерфейса вы можете настроить целевой lakehouse и таблицу для результатов запроса в дополнение к методу обновления (добавление или замена).


Поток данных теперь готов к публикации. Просмотрите запросы в представлении диаграммы и выберите " Опубликовать".
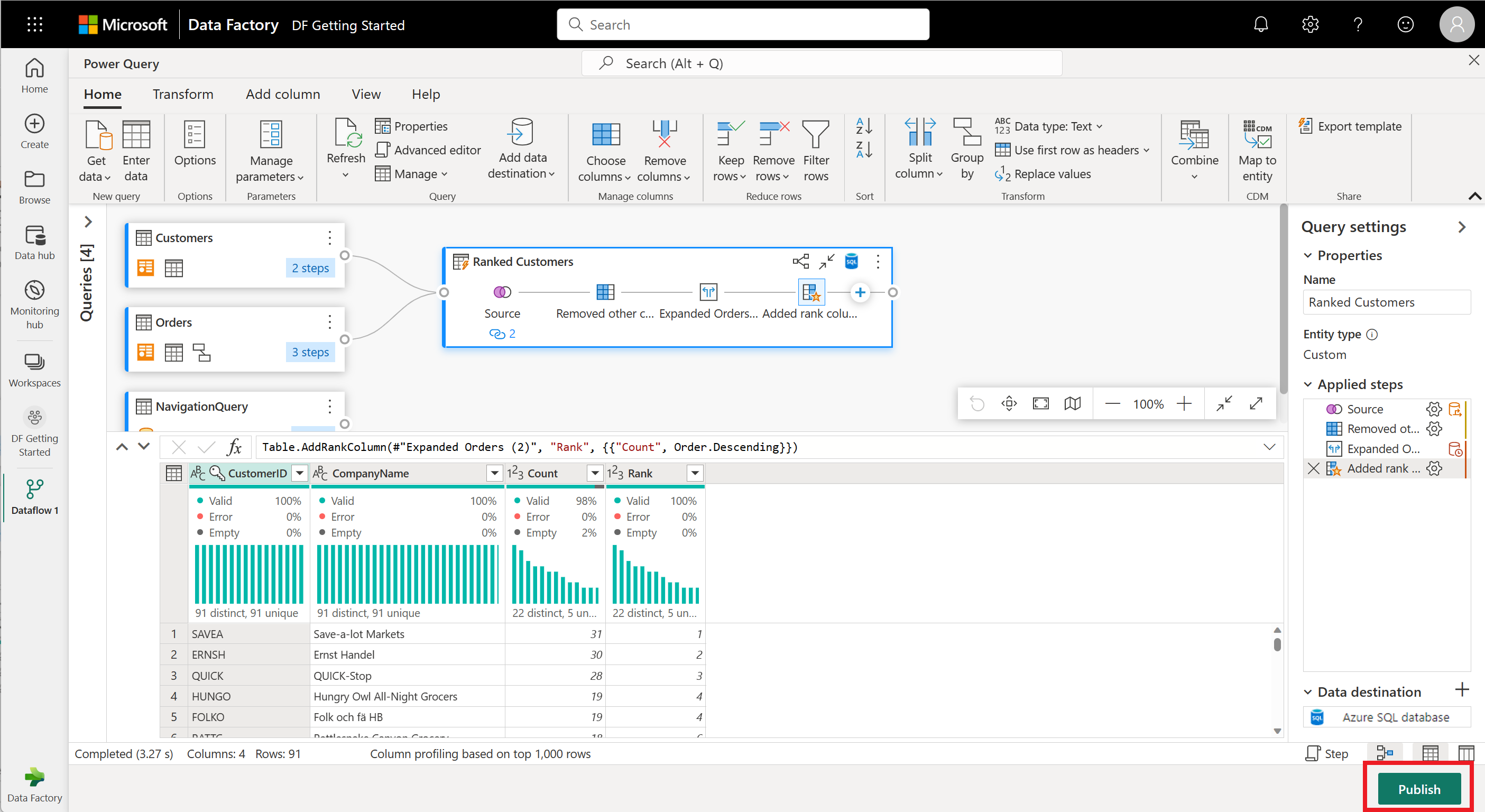
Теперь вы вернелись в рабочую область. Значок спиннера рядом с именем потока данных указывает, что публикация выполняется. После завершения публикации поток данных будет готов к обновлению!
Важно!
При создании первого поколения Dataflow 2-го поколения в рабочей области элементы Lakehouse и Warehouse подготавливаются вместе с соответствующими конечными точками аналитики SQL и семантической моделями. Эти элементы разделяются всеми потоками данных в рабочей области и требуются для работы потока данных 2-го поколения, не следует удалять и не предназначены для непосредственного использования пользователями. Элементы — это сведения о реализации потока данных 2-го поколения. Элементы не отображаются в рабочей области, но могут быть доступны в других интерфейсах, таких как записная книжка, конечная точка аналитики SQL, Lakehouse и хранилище. Элементы можно распознать по их префиксу в имени. Префикс элементов — DataflowsStaging.
В рабочей области выберите значок "Запланировать обновление ".

Включите запланированное обновление, нажмите кнопку "Добавить еще раз" и настройте обновление, как показано на следующем снимке экрана.
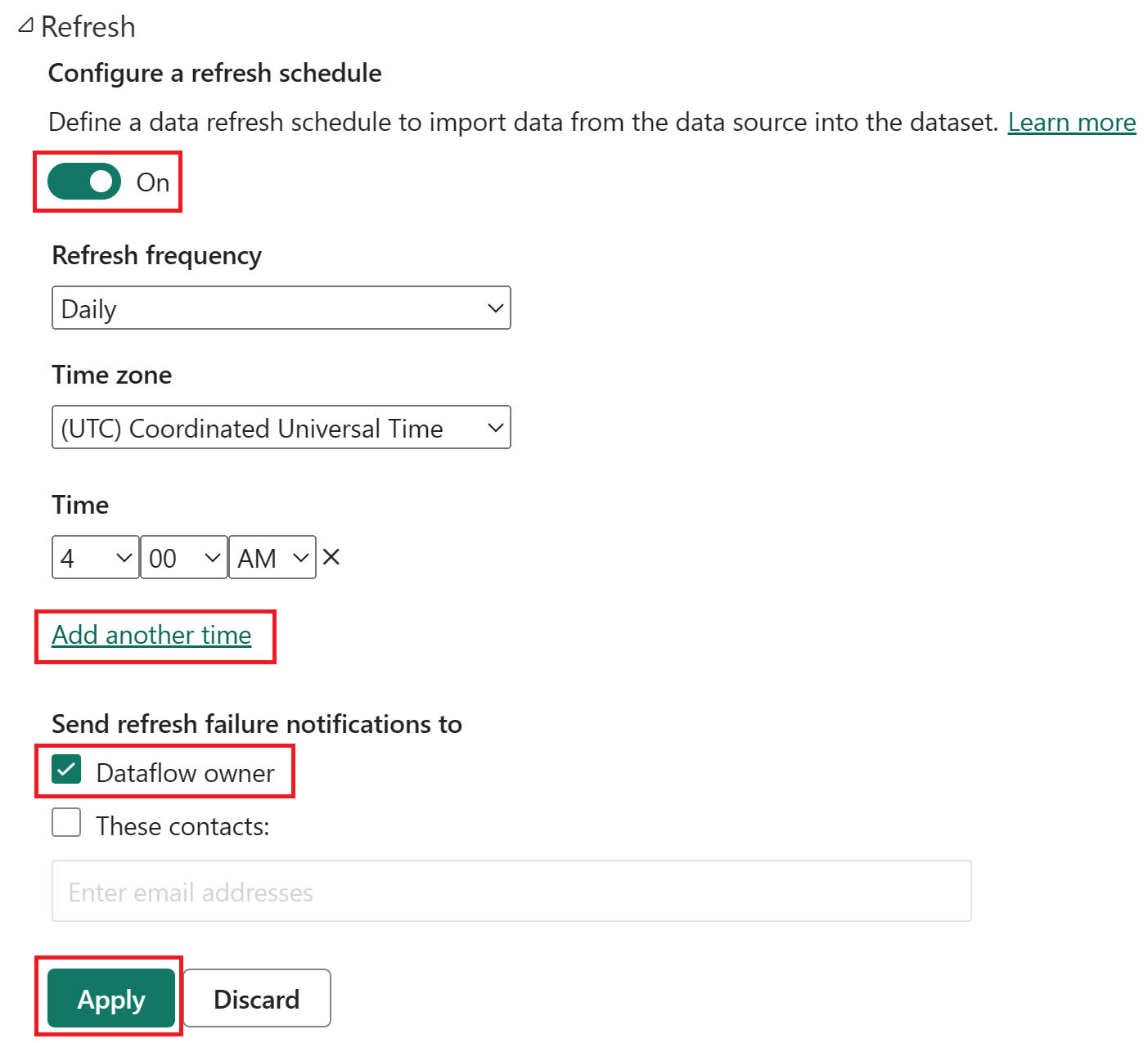
Снимок экрана: параметры запланированного обновления с включенным запланированным обновлением, частота обновления— Daily, часовой пояс, заданный для координированного универсального времени, и время 4:00. Кнопка "Добавить другое время", владелец потока данных и кнопка "Применить" все выделены.













Очистка ресурсов
Если вы не собираетесь продолжать использовать этот поток данных, удалите поток данных, выполнив следующие действия.
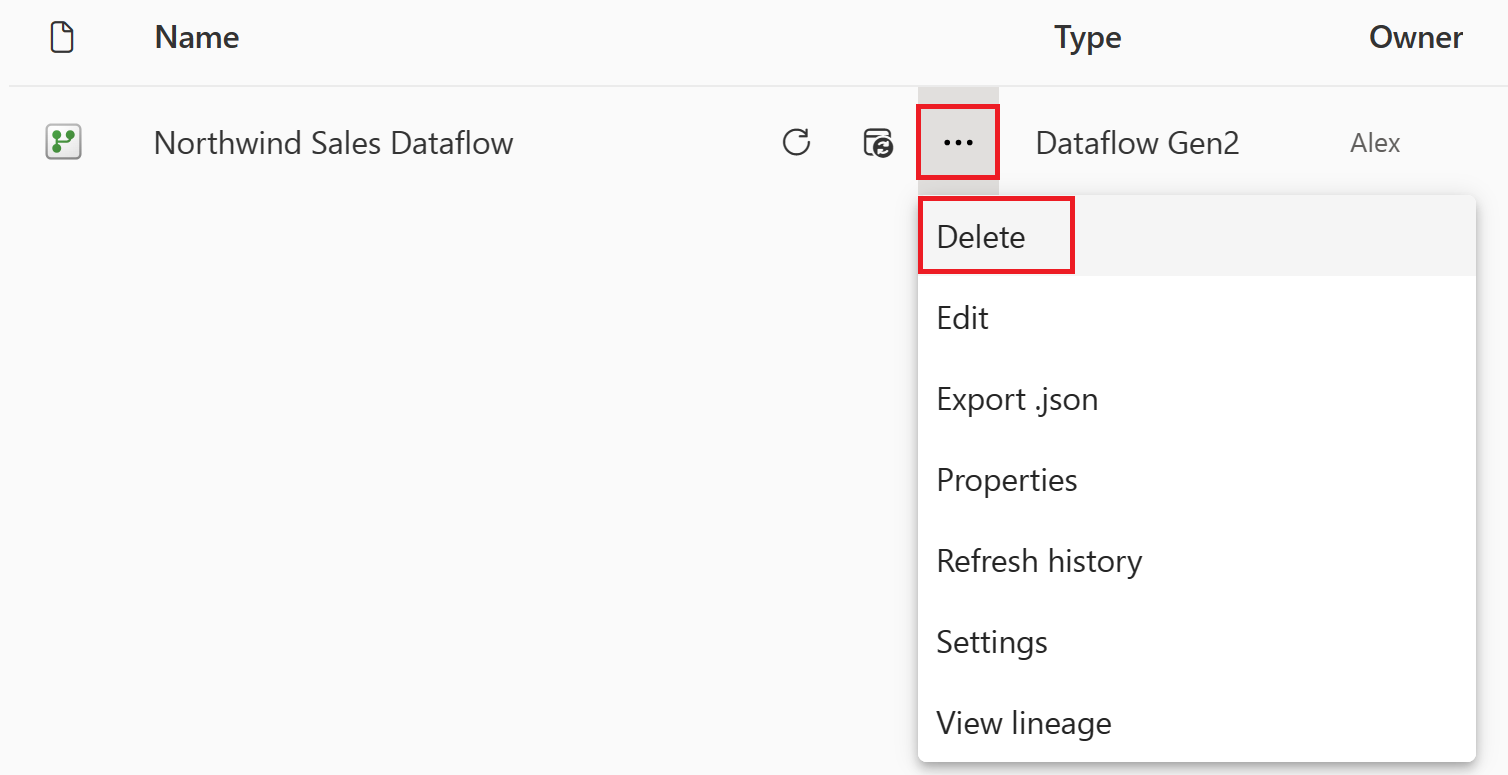
Перейдите в рабочую область Microsoft Fabric.
Выберите вертикальное многоточие рядом с именем потока данных и нажмите кнопку "Удалить".
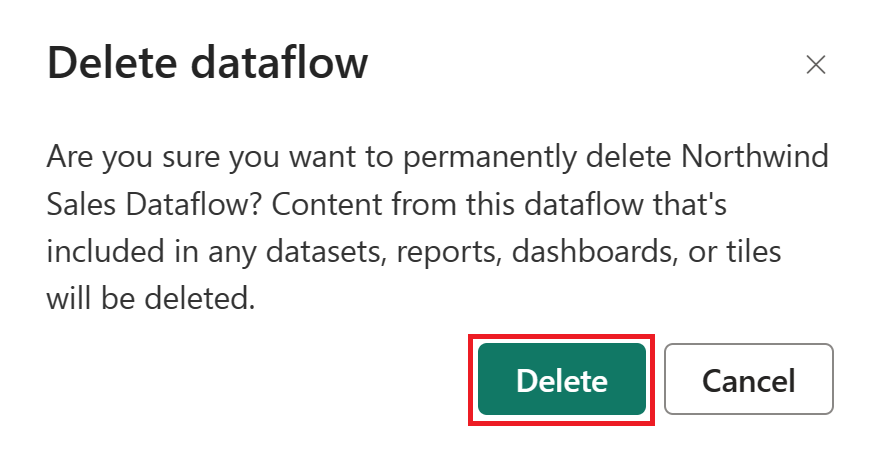
Выберите "Удалить" , чтобы подтвердить удаление потока данных.
Связанный контент
Поток данных в этом примере показывает, как загружать и преобразовывать данные в поток данных 2-го поколения. Вы научились выполнять следующие задачи:
- Создание потока данных 2-го поколения.
- Преобразовать данные.
- Настройте параметры назначения для преобразованных данных.
- Запустите и запланируйте конвейер данных.
Перейдите к следующей статье, чтобы узнать, как создать первый конвейер данных.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по