Варианты конфигурации HdInsight
В HDInsight имеется широкий спектр технологий OSS, которые можно использовать для потоковой и пакетной передачи данных в лямбда-архитектурах. В этой модели архитектуры есть критический и холодный путь данных. Критический путь данных создается в режиме реального времени устройствами, датчиками или приложениями, а анализ данных выполняется практически в реальном времени. Часто это называется потоковой передачей данных. Холодный путь данных — это перемещение данных пакетами, обычно из других хранилищ данных.
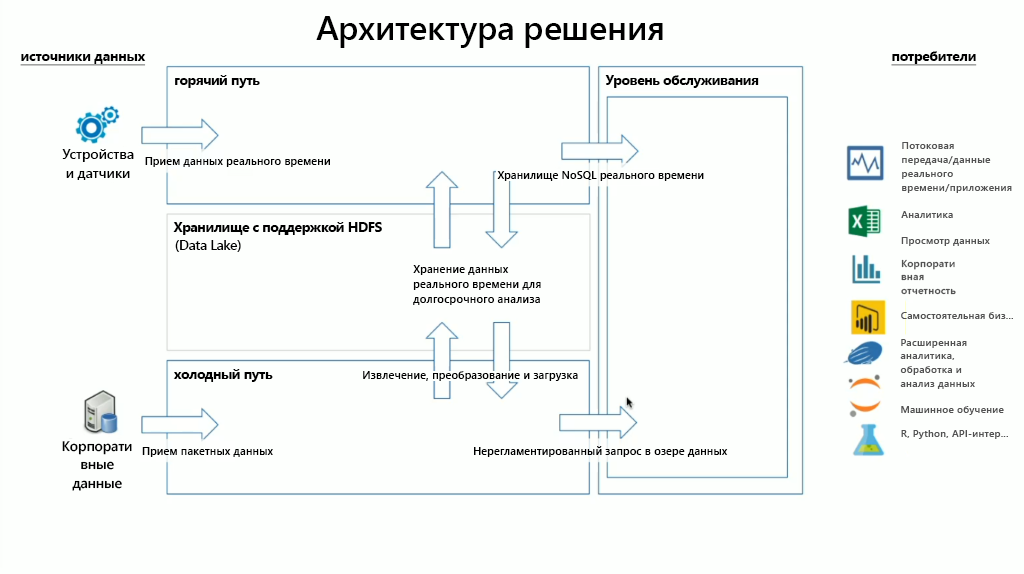
При реализации HDInsight хранилище данных находится в совместимой распределенной файловой системе Hadoop (HDFS). В Azure в качестве хранилища данных обычно используется Data Lake 2-го поколения, так как он совместим с HDFS. Данные из критического и холодного пути после обработки хранятся в централизованном хранилище данных — озере данных. Само по себе озеро данных может быть разделено на секции данных, которые можно определить по состоянию данных (зона размещения, зона преобразования и т. д.), требованиям к доступу (горячий, теплый и холодный) и бизнес-группам. Уровень обслуживания — это последняя секция озера данных, которая содержит данные в формате, готовом для использования различными типами потребителей.
Вычислительный компонент HDInsight работает с обработкой потоковых или пакетных данных и может различаться в зависимости от типа кластера, выбранного при подготовке кластера HDInsight. HDInsight предлагает службы в отдельных кластерах, как показано в следующей таблице.
| Тип кластера | Description |
|---|---|
| Apache Hadoop | Платформа, в которой используется HDFS и простая модель программирования MapReduce для обработки и анализа пакетных данных. |
| Apache Spark | Платформа параллельной обработки с открытым кодом, которая поддерживает обработку в памяти, чтобы повысить производительность приложений для анализа больших данных. |
| HBase | База данных NoSQL, созданная на основе Hadoop и обеспечивающая прямой доступ и строгую согласованность для больших объемов неструктурированных и частично структурированных данных (с потенциальным размером таблиц в миллиарды строк и миллионы столбцов). |
| Apache Interactive Query | Кэширование в памяти для обеспечения интерактивных и ускоренных запросов Hive. |
| Apache Kafka | Платформа с открытым исходным кодом, которая используется для создания конвейеров и приложений потоковой передачи данных. Kafka также предоставляет функциональные возможности очереди сообщений, с помощью которых можно публиковать потоки данных и подписываться на них. |
Поэтому важно выбрать правильный тип кластера для вашего сценария. Независимо от выбранного типа кластера, дополнительные компоненты с открытым исходным кодом также добавляются в кластер для предоставления дополнительных возможностей, включая:
Управление Hadoop
HCatalog — уровень управления таблицами и хранилищами для Hadoop
Apache Ambari — упрощает управление и мониторинг кластера Apache Hadoop
Apache Oozie — система планировщика рабочих процессов для управления заданиями Apache Hadoop.
Apache Hadoop YARN — управление ресурсами и планирование и мониторинг заданий
Apache ZooKeeper — централизованная служба для сведений о конфигурации, именования, предоставления распределенной синхронизации и групповых служб.
Обработка данных
Apache Hadoop MapReduce — платформа для простого написания приложений, которые обрабатывают огромные объемы данных.
Apache Tez — платформа приложений для обработки данных
Apache Hive — упрощает управление большими наборами данных, находящимися в распределенном хранилище, с помощью SQL.
Анализ данных
Apache Pig — предоставляет слой абстракции через MapReduce для анализа больших наборов данных
Apache Phoenix — включает OLTP и операционную аналитику в Hadoop
Apache Mahout — платформа Algebra для создания собственных алгоритмов
Примечание.
На момент написания статьи поддерживаемыми уровнями хранилища данных для HDInsight являются Azure Data Lake 1-го поколения и хранилище BLOB-объектов Azure. Необходимо перенести эти данные в Azure Data Lake 2-го поколения, так как это рекомендуемая платформа хранения для Spark и Hadoop, а также вариант по умолчанию для HBase.