Сверточные нейронные сети
Хотя модели глубокого обучения можно использовать для любого вида машинного обучения, они особенно полезны для работы с данными, которые состоят из больших массивов числовых значений, таких как изображения. Модели машинного обучения, работающие с изображениями, являются основой для области искусственного интеллекта, называемой компьютерным зрением, и в течение последних лет методы глубокого обучения привели к потрясающим результатам в этой сфере.
Центральное место в достижении успеха в этом направлении глубокого обучения занимает модель, называемая сверточной нейронной сетью (CNN). Как правило, сеть CNN работает путем извлечения признаков из изображений и их последующей передачи в полносвязную нейронную сеть для создания прогноза. Слои извлечения признаков в сети уменьшают число признаков, в результате чего потенциально огромный массив отдельных значений пикселей становится небольшим набором признаков, поддерживающим прогнозирование меток.
Слои в CNN
Сети CNN состоят из нескольких слоев, каждый из которых выполняет определенную задачу в процессе извлечения функций или прогнозирования меток.
Сверточные слои
Одним из основных типов слоев является сверточный, который извлекает важные функции из изображений. Сверточный слой работает путем применения фильтра к изображениям. Фильтр определяется ядром, состоящим из матрицы значений веса.
Например, фильтр 3 x 3 может быть определен следующим образом.
1 -1 1
-1 0 -1
1 -1 1
Изображение также представляет собой матрицу значений пикселей. Чтобы применить фильтр, необходимо "наложить" его на изображение и вычислить взвешенную сумму соответствующих значений пикселей изображения в ядре фильтра. Затем результат присваивается центральной ячейке эквивалентного участка 3 x 3 в новой матрице значений, имеющей тот же размер, что и изображение. Предположим, что изображение 6 x 6 имеет следующие значения пикселей:
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
Применение фильтра к верхнему левому участку 3 x 3 изображения будет работать следующим образом.
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
Результат присваивается соответствующему значению пикселя в новой матрице следующим образом.
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Теперь фильтр перемещается по матрице (свертывается) обычно с использованием размера шага, равного 1 (перемещаясь на один пиксель вправо), и вычисляется значение для следующего пикселя.
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
Теперь можно заполнить следующее значение новой матрицы.
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Этот процесс повторяется до тех пор, пока фильтр не будет применен ко всем участкам 3 x 3 изображения для создания новой матрицы значений.
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
Из-за размера ядра фильтра вычислить значения для пикселей на стороне невозможно, поэтому обычно просто применяется значение заполнения (часто 0).
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
Выходные данные свертка обычно передаются функции активации, часто являющейся функцией усеченного линейного преобразования (ReLU), которая гарантирует, что для отрицательных значений задан 0.
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
Полученная матрица является картой признаков для значений признаков, которые можно использовать для обучения модели машинного обучения.
Примечание. Значения в карте признаков могут быть больше максимального значения для пикселя (255), поэтому если необходимо визуализировать карту признаков в виде изображения, необходимо нормализовать значения признаков от 0 до 255.
Процесс свертки показан в анимации ниже.

- Изображение передается в сверточный слой. В этом случае изображение является простой геометрической фигурой.
- Изображение состоит из массива пикселей со значениями от 0 до 255 (для цветных изображений обычно это трехмерный массив со значениями красного, зеленого и синего каналов).
- Как правило, ядро фильтра инициализируется случайными значениями веса (в этом примере выбраны значения для выделения влияния фильтра на значения пикселей, но в реальной сети CNN исходные значения веса обычно создаются на основе случайного распределения по Гауссу). Этот фильтр будет использоваться для извлечения карты признаков из данных изображения.
- Фильтр свертывается по изображению, вычисляя значения признаков путем применения суммы значений веса, умноженной на соответствующие значения пикселей в каждой позиции. Для установки отрицательных значений в 0 применяется функция усеченного линейного преобразования (ReLU).
- После свертки карта признаков содержит извлеченные значения признаков, которые часто обозначают ключевые визуальные атрибуты изображения. В нашем случае карта признаков выделяет стороны и углы треугольника на изображении.
Как правило, сверточный слой применяет несколько ядер фильтров. Каждый фильтр создает разную карту признаков функций, и все карты признаков передаются на следующий слой сети.
Слои объединения
После извлечения значений признаков из изображений начинают действовать слои объединения (или понижающей выборки), которые уменьшают число значений признаков, сохраняя при этом извлеченные ключевые отличительные признаки.
Одним из наиболее распространенных видов объединения является максимальное объединение, при котором к изображению применяется фильтр и сохраняется только максимальное значение пикселя в области фильтра. Например, применение ядра объединения 2 x 2 к следующему участку изображения приведет к результату, равному 155.
0 0
0 155
Обратите внимание, что действие пула объединения 2 x 2 заключается в сокращении количества значений с 4 до 1.
Как и в случае со сверточными слоями, слои объединения работают путем применения фильтра по всей карте признаков. На приведенной ниже анимации показан пример максимального объединения для карты изображения.

- Карта признаков, извлеченная фильтром в сверточном слое, содержит массив значений признаков.
- Ядро объединения используется для сокращения количества значений признаков. В этом случае размер ядра составляет 2 x 2, поэтому будет создан массив с количеством значений, составляющих четвертую часть от числа значений признаков.
- Ядро объединения свертывается по карте признаков, сохраняя в каждой позиции только самое высокое значение пикселя.
Слои исключения
Одной из самых сложных проблем в сети CNN является предотвращение переобучения, когда обученная модель хорошо работает с обучающими данными, но теряет способность к обобщению новых данных, не участвовавших в обучении. Один из способов решения проблемы переобучения заключается во включении слоев, в которых процесс обучения случайным образом исключает (или "отбрасывает") карты признаков. Это может показаться нелогичным, но это эффективный способ гарантирующий, что модель не станет излишне зависимой от обучающих изображений.
К другим методам, которые можно использовать для устранения переобучения, относятся случайное отражение, зеркальное отображение или наклон обучающих изображений для создания данных, которые зависят от обучающих эпох.
Слои сглаживания
После использования сверточных слоев и слоев объединения для извлечения основных признаков в изображениях итоговые карты признаков становятся многомерными массивами значений пикселей. Слой сглаживания используется для сведения карт признаков в вектор значений, которые можно использовать в качестве входных данных для полносвязного слоя.
Полносвязные слои
Как правило, сеть CNN заканчивается полносвязной сетью, в которой значения признаков передаются во входной слой через один или несколько скрытых слоев и генерируют прогнозируемые значения в выходном слое.
Базовая архитектура сети CNN может выглядеть примерно следующим образом.
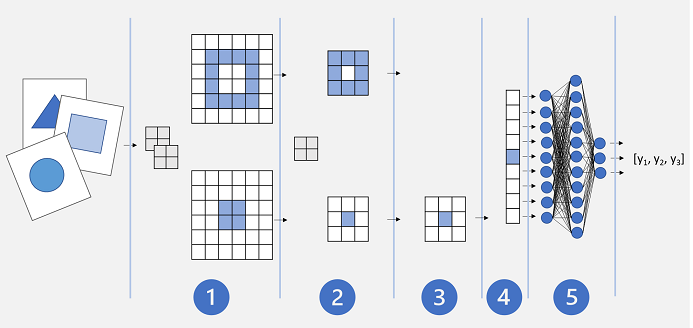
- Изображения передаются в сверточный слой. В нашем случае есть два фильтра, поэтому каждое изображение формирует две карты признаков.
- Карты признаков передаются в слой объединения, где ядро объединения 2 x 2 уменьшает размер карт признаков.
- Слой исключения случайным образом отбрасывает некоторые карты признаков, чтобы предотвратить переобучение.
- Слой сглаживания принимает оставшиеся массивы карт признаков и сводит их в вектор.
- Элементы вектора передаются в полносвязную сеть, где создаются прогнозы. В нашем случае сеть является моделью классификации, которая прогнозирует вероятности для трех возможных классов изображений (треугольник, квадрат и круг).
Обучение модели CNN
Как и любая глубокая нейронная сеть, сеть CNN обучается путем передачи по ней пакетов обучающих данных через несколько эпох. При этом значения весов и смещений корректируются на основе потерь, вычисляемых для каждой эпохи. При использовании сети CNN обратное распространение скорректированных весов включает в себя веса ядра фильтра, используемые в сверточных слоях, а также веса, используемые в полносвязных сетях.