Использование текста для API распознавания речи
Аналогично api преобразования речи в текст, служба распознавания речи Azure предлагает другие ИНТЕРФЕЙСы REST API для синтеза речи:
- API преобразования текста в речь, который является основным способом синтеза речи.
- API синтеза пакетной службы, предназначенный для поддержки пакетных операций, которые преобразуют большие объемы текста в звук, например для создания аудиокниги из исходного текста.
Дополнительные сведения о REST API см. в документации по REST API преобразования речи в текст. На практике большинство интерактивных приложений с поддержкой речи используют службу распознавания речи Azure с помощью пакета SDK для конкретного языка (программирования).
Использование пакета SDK службы "Распознавание речи Azure"
Как и при распознавании речи, на практике большинство интерактивных приложений с поддержкой речи создаются с помощью пакета SDK службы "Речь ИИ Azure".
Схема реализации синтеза речи аналогична модели распознавания речи.
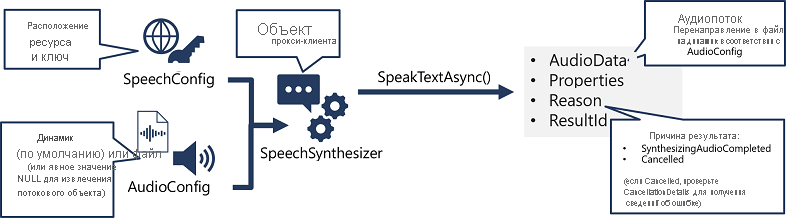
- Используйте объект SpeechConfig, чтобы инкапсулировать сведения, необходимые для подключения к ресурсу службы "Речь ИИ Azure". таких как расположение и ключ.
- При необходимости используйте AudioConfig для определения устройства вывода для синтезирования речи. По умолчанию это системный динамик, но можно также указать звуковой файл. Если явно задать значение NULL, вы сможете напрямую обработать возвращаемый объект звукового потока.
- Используйте SpeechConfig и AudioConfig для создания объекта SpeechSynthesizer. Этот объект является прокси-клиентом API преобразования текста в речь .
- Для вызова базовых функций API используйте методы объекта SpeechSynthesizer. Например, метод SpeakTextAsync() использует службу "Речь ИИ Azure" для преобразования текста в речевой звук.
- Обработайте ответ от службы "Речь" Azure AI. В случае метода SpeakTextAsync результатом является объект SpeechSynthesisResult , содержащий следующие свойства:
- AudioData
- Свойства
- Причина
- ResultId
После успешного синтеза речи свойству Reason присваивается перечисляемое значение SynthesizingAudioCompleted, а свойство AudioData содержит звуковой поток (который в зависимости от AudioConfig может быть автоматически отправлен в динамик или файл).