Ссылка на запросы Power Query
Эта статья предназначена для моделирователя данных, работающего с Power BI Desktop. Он предоставляет рекомендации при определении запросов Power Query, ссылающихся на другие запросы.
Давайте ясно о том, что это означает: когда запрос ссылается на второй запрос, это так, как будто шаги во втором запросе объединяются и выполняются до этого, шаги в первом запросе.
Рассмотрим несколько запросов: запрос1 источников данных из веб-службы и его загрузка отключена. Запрос2, Запрос3 и Запрос4 все ссылочные запросы1 и их выходные данные загружаются в модель данных.
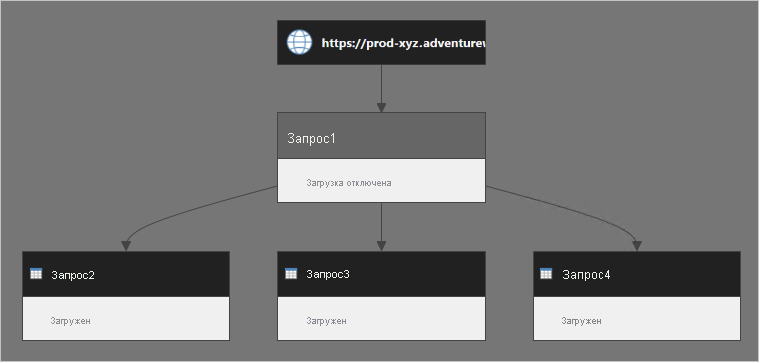
При обновлении модели данных часто предполагается, что Power Query извлекает результат Query1 и используется повторно с помощью ссылочных запросов. Это неправильное мышление. На самом деле Power Query выполняет запрос2, запрос3 и запрос4 отдельно.
Вы можете подумать, что Запрос2 содержит шаги Query1 , внедренные в него. Это также относится к запросу 3 и Query4. На следующей схеме представлено более четкое представление о том, как выполняются запросы.
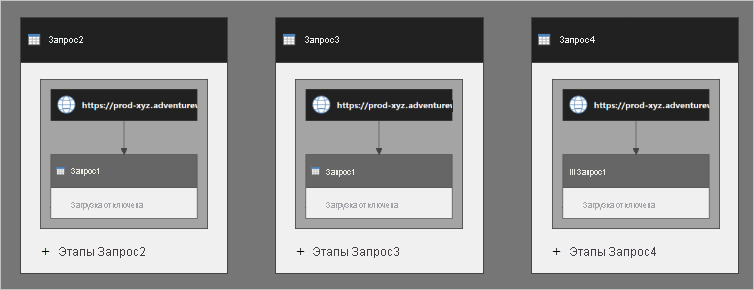
Запрос1 выполняется три раза. Несколько выполнений могут привести к медленному обновлению данных и негативному влиянию на источник данных.
Использование функции Table.Buffer в Query1 не приведет к устранению дополнительных сведений. Эта функция буферизирует таблицу в память, а буферная таблица может использоваться только в рамках одного выполнения запроса. Таким образом, в примере, если запрос1 буферичен при выполнении запроса 2 , буферированные данные не могут использоваться при выполнении запроса3 и query4 . Они сами буферизируют данные в два раза больше. (Это может привести к снижению производительности, так как таблица будет буферирована каждым запросом ссылки.)
Примечание.
Архитектура кэширования Power Query сложна, и это не фокус этой статьи. Power Query может кэшировать данные, полученные из источника данных. Однако при выполнении запроса он может получить данные из источника данных более одного раза.
Рекомендации
Как правило, мы рекомендуем ссылаться на запросы, чтобы избежать дублирования логики в запросах. Однако, как описано в этой статье, этот подход к проектированию может способствовать медленному обновлению данных и переполнению источников данных.
Вместо этого рекомендуется создать поток данных. Использование потока данных может повысить время обновления данных и снизить влияние на источники данных.
Поток данных можно создать для инкапсулировать исходные данные и преобразования. Так как поток данных является сохраненным хранилищем данных в служба Power BI, его извлечение данных выполняется быстро. Таким образом, даже если ссылки на запросы приводят к нескольким запросам для потока данных, время обновления данных можно улучшить.
В примере, если запрос1 перепроектирован как сущность потока данных, Query2, Query3 и Query4 может использовать его в качестве источника данных. С помощью этой структуры сущность, исходная запросом 1 , будет оцениваться только один раз.
Связанный контент
Дополнительные сведения, связанные с этой статьей, проверка следующие ресурсы:
- Подготовка данных самообслуживания в Power BI
- Creating and using dataflows in Power BI (Создание и использование потоков данных в Power BI)
- Вопросы? Задайте их в сообществе Power BI.
- Есть предложения? Участие в разработке идей по улучшению Power BI
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по