Определение отчетов об ошибках безопасности на основе заголовков отчетов и шумных данных
| Майана Перейра | Скотт Кристиансен (Scott Christiansen) |
|---|---|
| Обработка и анализ данных CELA | Безопасность и доверие клиентов |
| Microsoft | Microsoft |
Аннотация. Определение отчетов об ошибках безопасности (ООБ) — это очень важный шаг в жизненном цикле разработки программного обеспечения. В контролируемых подходах, основанных на машинном обучении, обычно предполагается, что все отчеты об ошибках доступны для обучения и что их метки не содержат помех. Насколько нам известно, это первое исследование, которое показывает, что точное прогнозирование меток для ООБ возможно, даже если доступен только заголовок и имеются помехи меток.
Ключевые термины: машинное обучение, неправильные метки, помехи, отчет об ошибках безопасности, репозитории ошибок
I. ВВЕДЕНИЕ
Выявление связанных с безопасностью проблем, которые возникают в отчетах об ошибках, является актуальной необходимостью для каждой команды разработчиков программного обеспечения, поскольку такие проблемы требуют более срочного устранения для выполнения требований соответствия и обеспечения целостности программного обеспечения и данных клиентов.
Средства машинного обучения и средства искусственного интеллекта обещают сделать разработку программного обеспечения более быстрой, гибкой и правильной. Несколько исследователей применяли машинное обучение к проблеме определения ошибок безопасности [2], [7], [8], [18]. В предыдущих опубликованных исследованиях предполагалось, что весь отчет об ошибках доступен для обучения и оценивания модели машинного обучения. Это не всегда так. Существуют ситуации, когда невозможно предоставить доступ ко всему отчету об ошибках. Например, отчет об ошибках может содержать пароли, персональные идентификационные данные или другие конфиденциальные сведения — именно с такой ситуацией сейчас столкнулась корпорация Майкрософт. Поэтому важно установить, насколько хорошо можно определять ошибки безопасности, используя меньше информации, например, если доступен только заголовок отчета об ошибках.
Кроме того, репозитории ошибок часто содержат записи с неправильными метками [7]: отчеты об ошибках, не относящихся к безопасности, классифицированные как связанные с безопасностью, и наоборот. Существует несколько причин возникновения неправильных меток: от нехватки опыта в области безопасности у команды разработки до нечеткости определенных проблем. Например, ошибка, не связанная с безопасностью, может косвенным образом влиять на безопасность. Это серьезная проблема, поскольку из-за неправильных меток в ООБ специалисты по безопасности вынуждены вручную проверять базу данных ошибок, а это занимает много времени и стоит дорого. Необходимо понять, как помехи влияют на различные классификаторы и насколько устойчивыми (или хрупкими) оказываются различные методы машинного обучения при наличии наборов данных, засоренных различными видами помех, чтобы ввести автоматическую классификацию в практику программной инженерии.
По результатам предварительной работы утверждается, что репозитории ошибок обладают внутренними ошибками и что помехи могут неблагоприятно влиять на классификаторы производительности машинного обучения [7]. Однако не проводится систематическое и количественное исследование того, как различные уровни и типы помех влияют на производительность различных управляемых алгоритмов машинного обучения для проблемы выявления отчетов об ошибках безопасности (ООБ).
В этом исследовании мы показываем, что классификация отчетов об ошибках может быть выполнена, даже если для обучения и оценивания доступен лишь заголовок. Насколько нам известно, это было сделано впервые. Кроме того, мы предоставляем первое систематическое исследование влияния помех на классификацию отчетов об ошибках. Мы выполняем сравнительный анализ устойчивости трех методов машинного обучения (логистическая регрессия, упрощенный алгоритм Байеса и AdaBoost) к помехам, независящим от класса.
Хотя существуют некоторые аналитические модели, которые определяют общее влияние помех на несколько простых классификаторов [5], [6], эти результаты не демонстрируют строгих границ влияния помех на точность и являются допустимыми только для определенного метода машинного обучения. Точный анализ влияния помех в моделях машинного обучения обычно выполняется с помощью вычислительных экспериментов. Такие анализы выполнялись в нескольких сценариях: от данных программного измерения [4] до классификации спутниковых снимков [13] и медицинских данных [12]. Однако эти результаты не могут быть использованы для решения нашей конкретной проблемы ввиду ее сильной зависимости от природы наборов данных и базовой проблемы классификации. Насколько нам известно, не существует опубликованных результатов конкретно по проблеме влияния наборов данных, содержащих помехи, на классификацию отчетов об ошибках безопасности.
НАШ ВКЛАД В ИССЛЕДОВАНИЕ:
Мы обучаем классификаторы определять отчеты об ошибках безопасности (ООБ) исключительно на основании заголовков отчетов. Насколько нам известно, раньше никто этого не делал. В предыдущих работах либо использовался полный отчет об ошибках, либо отчет об ошибках улучшался с использованием дополнительных характеристик. Классификация ошибок исключительно на основании заголовка особенно важна, когда полные отчеты об ошибках не могут быть доступны из-за конфиденциальности. Распространенным примером этого являются отчеты об ошибках, содержащие пароли и другие конфиденциальные данные.
Мы также представляем первое систематическое исследование толерантности меток к помехам в различных моделях и методах машинного обучения, которые используются для автоматической классификации ООБ. Мы выполняем сравнительный анализ устойчивости трех разных методов машинного обучения (логистическая регрессия, упрощенный алгоритм Байеса и AdaBoost) к помехам, зависящим и независящим от класса.
Оставшаяся часть документа представлена следующим образом: в разделе II мы представляем некоторые из предыдущих работ в литературе. В разделе III мы описываем набор данных и процедуру предварительной обработки данных. Методология описана в разделе IV, а результаты наших экспериментов анализируются в разделе V. Наконец, наши выводы и будущие работы представлены в разделе VI.
II. ПРЕДЫДУЩИЕ РАБОТЫ
ПРИМЕНЕНИЕ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РЕПОЗИТОРИЕВ ОШИБОК.
Существует обширная литература по применению интеллектуального анализа текста, обработки естественного языка и машинного обучения к репозиториям ошибок в попытке автоматизации трудоемких задач, среди которых: определение ошибок безопасности [2], [7], [8], [18], определение дублирования ошибок [3], рассмотрение ошибок [1], [11]. В идеале, объединение машинного обучения и обработки естественного языка позволяет сократить объем ручной работы, необходимый для курирования баз данных, и необходимое время на выполнение этих задач, а также позволяет повысить надежность результатов.
В [7] авторы предлагают модель естественного языка для автоматизации классификации ООБ на основе описания ошибки. Авторы извлекают словарь из всех описаний ошибок в наборе данных для обучения и вручную разделяют его на три списка слов: релевантные слова, стоп-слова (общие слова, которые кажутся нерелевантными для классификации) и синонимы. Они сравнивают производительность классификатора ошибок безопасности, обученного на основе данных, полностью прошедших оценку инженерами по безопасности, с производительностью классификатора, обученного на основе данных, помеченных отчетами об ошибках в целом. Хотя их модель явно более эффективна при обучении на основе данных, проверенных инженерами по безопасности, предлагаемая модель основана на составленном вручную словаре, что делает ее зависимой от контроля человеком. Более того, отсутствует анализ того, как на их модель влияют разные уровни помех, как на помехи реагируют разные классификаторы и отличается ли влияние помех на производительность в каждом из классов.
Зу и т. д. al [18] использует несколько типов сведений, содержащихся в отчете об ошибках, которые включают нетекстовые поля отчета об ошибке (мета-функции, например, время, серьезность и приоритет) и текстовое содержимое отчета об ошибке (текстовые функции, т. е. текст в полях сводки). На основе этих характеристик они создают модель для автоматического обнаружения ООБ с помощью методов обработки естественного языка и машинного обучения. В [8] авторы проводят аналогичный анализ, но также сравнивают производительность контролируемых и неконтролируемых методов машинного обучения и изучают, какой объем данных необходим для обучения их моделей.
В [2] авторы также изучают различные методы машинного обучения, чтобы классифицировать ошибки как ООБ или ООНБ (отчеты об ошибках, не связанных с безопасностью) на основе их описаний. Они предлагают конвейер для обработки данных и обучения модели на основе TFIDF. Они сравнивают предложенный конвейер с моделью, основанной на наборах слов и упрощенном алгоритме Байеса. Вижайасекара (Wijayasekara) и соавторы [16] также используют методы интеллектуального анализа текста для создания вектора характеристик каждого отчета об ошибках на основе часто встречающихся слов для обнаружения ошибок со скрытым влиянием (ОСВ). Ян (Yang) и соавторы [17] заявляют, что определяли отчеты об ошибках с высоким влиянием (например, ООБ) с помощью меры TF (частота термина) и упрощенного алгоритма Байеса. В [9] авторы предлагают модель для прогнозирования серьезности ошибки.
ПОМЕХИ МЕТОК
Проблема работы с наборами данных, содержащими помехи меток, широко изучается. Френе (Frenay) и Верлейсен (Verleysen) в [6] предлагают таксономию помех меток, чтобы различать разные типы меток с помехами. Авторы предлагают три различных типа помех: помехи меток, которые происходят независимо от истинного класса и значений характеристик экземпляра; помехи меток, зависящие только от истинной метки; и помехи меток, где вероятность неправильных меток также зависит от значений характеристик. В своей работе мы изучаем первые два типа помех. С теоретической точки зрения, помехи меток обычно сокращают производительность модели [10], за исключением некоторых конкретных случаев [14]. В общем случае устойчивые методы обработки помех меток полагаются на избегание лжевзаимосвязи [15]. Исследование влияния помех на классификацию проводилось раньше во многих областях, таких как классификация спутниковых изображений [13], классификация качества программного обеспечения [4] и классификация в медицинской сфере [12]. Насколько нам известно, не существует опубликованных работ, изучающих точную квантификацию воздействия меток с помехами в проблеме классификации ООБ. В данном сценарии точная связь между уровнями помех, типами помех и снижением производительности не была установлена. Более того, следует понимать, как работают различные классификаторы при наличии помех. В более широком смысле, нам не известно о какой-либо работе, которая систематически изучает влияние наборов данных с помехами на производительность различных алгоритмов машинного обучения в контексте отчетов об ошибках программного обеспечения.
III. ОПИСАНИЕ НАБОРА ДАННЫХ
Наш набор данных состоит из 1 073 149 заголовков ошибок, 552 073 из которых соответствуют ООБ и 521 076 — ООНБ. Данные были получены от разных команд в корпорации Майкрософт в 2015, 2016, 2017 и 2018 годах. Все метки были получены системами проверки ошибок на основе подписей или проставлены людьми. Заголовки ошибок в нашем наборе данных — это очень короткие фрагменты текста, содержащие около 10 слов, с описанием проблемы.
А. Предварительная обработка данных. Мы анализируем каждый заголовок ошибки по содержащимся в нем пробелам, в результате получая список маркеров. Мы обрабатываем каждый список маркеров следующим образом:
удаляем все маркеры, являющиеся путями к файлам;
разделяем маркеры, содержащие следующие символы: { , (, ), -, }, {, [, ], };
удаляем стоп-слова, маркеры, состоящие только из числовых символов, и маркеры, которые встречаются менее 5 раз во всем корпусе.
IV. МЕТОДОЛОГИЯ
Процесс обучения наших моделей машинного обучения состоит из двух основных этапов: кодирование данных в векторы характеристик и обучение контролируемых классификаторов машинного обучения.
А. Векторы характеристик и методы машинного обучения
Первая часть включает в себя кодирование данных в векторы характеристик с использованием алгоритма TF-IDF (частота термина — обратная частота документа), который использовался в [2]. TF-IDF — это метод получения информации, который взвешивает частоту термина (TF) и обратную частоту документа (IDF). Каждое слово, или термин, имеет соответствующие оценки TF и IDF. Алгоритм TF-IDF присваивает этому слову важность в зависимости от числа его появлений в документе и, что более важно, проверяет, насколько релевантным является ключевое слово в коллекции заголовков в наборе данных. Мы обучали и сравнивали три метода классификации: упрощенный алгоритм Байеса (NB), улучшенные деревья принятия решений (AdaBoost) и логистическую регрессию (LR). Мы выбрали эти методы, так как они продемонстрировали хорошую производительность для связанной задачи выявления отчетов об ошибках безопасности на основе полных отчетов, согласно описаниям в литературе. Эти результаты были подтверждены в предварительном анализе, где эти три классификатора показали лучшие результаты, чем метод опорных векторов и алгоритм случайных лесов. В своих экспериментах мы используем библиотеку scikit-learn для кодирования и обучения моделей.
B. Типы помех
Изучаемые в этой работе помехи — это помехи в метке класса в обучающих данных. Вследствие присутствия таких помех процесс обучения и результирующая модель ухудшаются из-за примеров с неправильными метками. Мы анализируем влияние разных уровней помех, применяемых к информации о классе. Типы помех меток обсуждались в литературе ранее с применением различной терминологии. В своей работе мы анализируем влияние двух различных помех меток в наших классификаторах: независящие от класса помехи меток, которые появляются при случайном выборе экземпляров и изменении их меток; и зависящие от класса помехи, когда классы имеют разную вероятность наличия помех.
a) Независимый от класса шум: независимо от класса шум относится к шуму, который возникает независимо от истинного класса экземпляров. В этом типе помех вероятность ошибочного проставления меток pоо одинакова для всех экземпляров в наборе данных. Мы добавляем независящие от класса помехи в наши наборы данных, меняя каждую метку в наборе данных случайным образом с вероятностью pоо.
b) Шум, зависящий от класса: шум, зависящий от класса, относится к шуму, который зависит от истинного класса экземпляров. В этом типе помех вероятность ошибочной метки в классе ООБ составляет pооб, а в классе ООНБ — pоонб. Мы добавляем зависящие от класса помехи в наш набор данных, меняя каждую запись в наборе данных, имеющую истинную метку ООБ, с вероятностью pооб. Аналогично, мы меняем метку класса экземпляров ООНБ с вероятностью pоонб.
c) Шум с одним классом: шум с одним классом — это особый случай шума, зависяющего от класса, где pnsbr = 0 и psbr> 0. Обратите внимание, что для помех, независящих от класса, pооб = pоонб = pоо.
C. Генерирование помех
В своих экспериментах мы анализируем влияние различных типов и уровней помех при обучении классификаторов SBR. В своих экспериментах мы установили 25% набора данных в качестве тестовых данных, 10% в качестве проверочных и 65% в качестве обучающих данных.
Мы добавили помехи в наборы данных для обучения и проверки на различных уровнях pоо, pооб и pоонб. Мы не вносим никаких изменений в набор тестовых данных. Используются различные уровни шума : P = {0,05 × i|0 < i < 10}.
В экспериментах с помехами, независящими от класса, для pbr ∈ P мы делаем следующее:
создаем помехи для наборов данных для обучения и проверки;
обучаем модели логистической регрессии, упрощенного алгоритма Байеса и AdaBoost с помощью набора данных для обучения (с помехами); * настраиваем модели с помощью набора данных для проверки (с помехами);
тестируем модели с помощью набора тестовых данных (без помех).
В экспериментах с помехами, зависящими от класса, мы выполняем описанное ниже для pооб ∈ P и pоонб ∈ P для всех комбинаций pооб и pоонб:
создаем помехи для наборов данных для обучения и проверки;
обучаем модели логистической регрессии, упрощенного алгоритма Байеса и AdaBoost с помощью набора данных для обучения (с помехами);
настраиваем модели с помощью набора проверочных данных (с помехами);
тестируем модели с помощью набора тестовых данных (без помех).
V. РЕЗУЛЬТАТЫ ЭКСПЕРИМЕНТОВ
В этом разделе анализируются результаты экспериментов, проведенных в соответствии с методологией, описанной в разделе IV.
a) Производительность модели без шума в наборе обучающих данных. Одним из вкладов этого документа является предложение модели машинного обучения для выявления ошибок безопасности с использованием только названия ошибки в качестве данных для принятия решений. Это позволяет обучать модели машинного обучения, даже если группы разработчиков не хотят предоставлять доступ к полным отчетам об ошибках из-за наличия в них конфиденциальных данных. Мы сравниваем производительность трех моделей машинного обучения при обучении с использованием только заголовков ошибок.
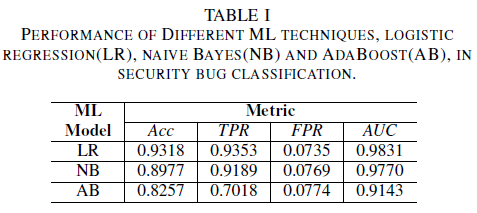
Модель логистической регрессии оказалась наиболее производительным классификатором. Это классификатор с наибольшим значением AUC (0,9826) и откликом 0,9353 для значения FPR 0,0735. Упрощенный алгоритм Байеса демонстрирует немного более низкую производительность по сравнению с классификатором логистической регрессии с AUC 0,9779 и откликом 0,9189 для FPR 0,0769. Классификатор AdaBoost демонстрирует более низкую производительность в сравнении с двумя вышеупомянутыми классификаторами. Он достигает значения AUC 0,9143 и отклика 0,7018 для FPR 0,0774. Область под кривой ROC (AUC) является хорошей метрикой для сравнения производительности нескольких моделей, так как она суммирует в одном значении отношение TPR и FPR. При последующем анализе мы будем ограничивать сравнительный анализ до значений AUC.
А. Помехи относительно класса: один класс
Можно представить ситуацию, когда по умолчанию все ошибки назначены классу ООНБ, а классу ООБ ошибка будет назначена только в том случае, если репозиторий ошибок будет просматривать эксперт по безопасности. Этот сценарий представлен в экспериментальном параметре одного класса, где предполагается, что pnsbr = 0 и 0 psbr< 0,5.<

В таблице II мы наблюдаем очень небольшое воздействие на AUC для всех трех классификаторов. AUC-ROC из модели, обученной при pооб = 0, по сравнению с AUC-ROC модели, где pооб = 0,25, отличается на 0,003 для логистической регрессии, на 0,006 для упрощенного алгоритма Байеса и 0,006 для AdaBoost. В случае с pооб = 0,50 AUC, измеряемый для каждой модели, отличается от модели, обученной при pооб = 0 на 0,007 для логистической регрессии, 0,011 для упрощенного алгоритма Байеса и на 0,010 для AdaBoost. Классификатор логистической регрессии, обученный при наличии помех одного класса, демонстрирует наименьшую вариацию в его метрике AUC, т. е. более устойчивое поведение по сравнению с нашими упрощенным алгоритмом Байеса и классификатором AdaBoost.
B. Помехи относительно класса: независящие от класса
Мы сравниваем производительность наших трех классификаторов для случая, когда обучающий набор ухудшен независящими от класса помехами. Мы измеряем AUC для каждой модели, обученной с различными уровнями pоо в обучающих данных.

В таблице III мы наблюдаем уменьшение AUC-ROC для каждого приращения помех в эксперименте. Значение AUC-ROC, измеренное для модели, обученной на основе данных без помех, по сравнению с AUC-ROC модели, обученной с независящими от класса помехами, с pоо = 0,25 отличается на 0,011 для логистической регрессии, на 0,008 для упрощенного алгоритма Байеса и на 0,0038 для AdaBoost. Мы видим, что помехи меток не влияют на AUC упрощенного алгоритм Байеса и классификатора AdaBoost, когда уровни помех ниже 40%. С другой стороны, классификатор логистической регрессии испытывает влияние на значение AUC для уровней помех меток выше 30%.

Рис. 1. Вариация AUC-ROC в независящих от класса помехах. Для уровня помех pоо = 0,5 классификатор действует как случайный классификатор, т. е. AUC ≈ 0,5. Но можно заметить, что для более низких уровней помех (pоо ≤ 0,30) обучение с логистической регрессией имеет более высокую производительность по сравнению с двумя другими моделями. Однако для 0,35 ≤ pоо ≤ 0,45 обучение с упрощенным алгоритмом Байеса обеспечивает лучшие метрики AUCROC.
C. Помехи относительно класса: зависящие от класса
В последнем наборе экспериментов мы рассмотрим сценарий, в котором различные классы содержат разные уровни шума, т. е. psbr ≠ pnsbr. Мы систематически независимо увеличиваем pооб и pоонб на 0,05 в обучающих данных и наблюдаем за изменениями в поведении этих трех классификаторов.

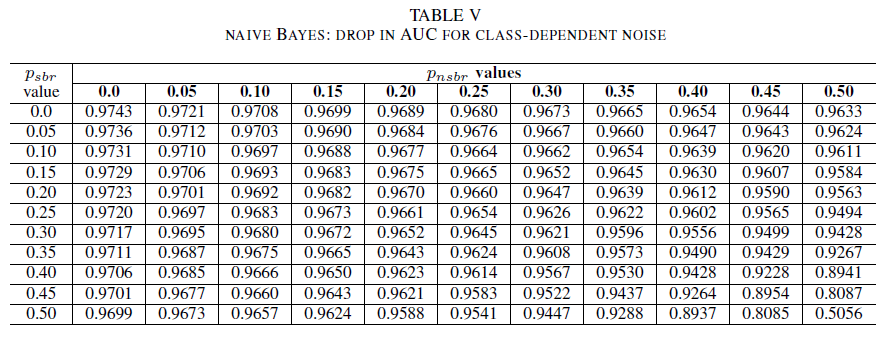
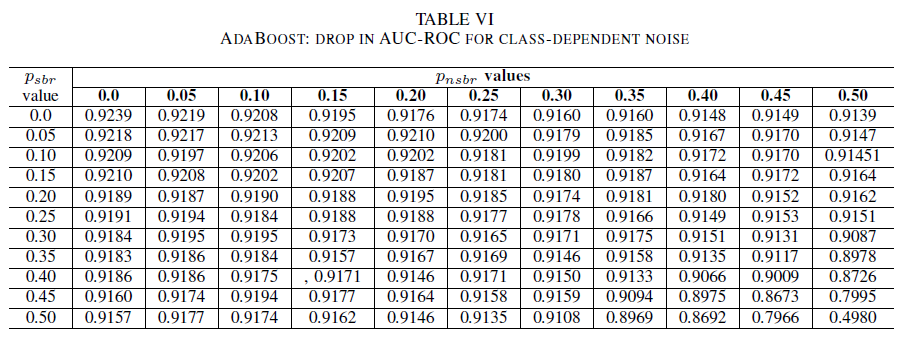
В таблицах IV, V, VI показана вариация AUC при увеличении помех на разных уровнях в каждом классе: для логистической регрессии в таблице IV, для упрощенного алгоритма Байеса в таблице V и для AdaBoost в таблице VI. Для всех классификаторов мы заметили влияние на метрику AUC, когда оба класса содержат уровень помех выше 30%. Упрощенный алгоритм Байеса обеспечивает более высокую устойчивость. Влияние на AUC очень мало, даже если изменено 50% метки в позитивном классе, при условии, что негативный класс содержит 30% или меньше меток с помехами. В этом случае падение в AUC имеет значение 0,03. Классификатор AdaBoost продемонстрировал наиболее устойчивое поведение среди всех трех классификаторов. Значительное изменение в AUC будет происходить только для уровней помех, превышающих 45% в обоих классах. В этом случае мы начнем наблюдать снижение AUC выше 0,02.
D. При наличии остаточных помех в исходном наборе данных
Наш набор данных был помечен автоматическими системами на основе подписей и экспертами-людьми. Кроме того, все отчеты об ошибках были прорецензированы и закрыты экспертами-людьми. Хотя мы предполагаем, что количество помех в нашем наборе данных минимально и не является статистически значимым, присутствие остаточных помех не опровергает наши выводы. Действительно, для иллюстрации предположим, что исходный набор данных поврежден независимо от класса шум равен 0 < p < 1/2 независимо и идентично распределен (i.d) для каждой записи.
Если поверх исходных помех мы добавим независящие от класса помехи из независящих одинаково распределенных случайных величин с вероятностью pоо, полученные помехи для каждой записи будут равны p∗ = p(1 − pоо) + (1 − p)pоо. Для 0 < p,p< 1/2 у нас есть, что фактический шум на метку p∗ строго больше, чем шум, который мы искусственно добавляем к набору данных pbr. Таким образом, производительность наших классификаторов была бы еще выше, если бы они изначально были обучены с помощью абсолютно не содержащего помех набора данных (p = 0). Таким образом, наличие остаточных помех в фактическом наборе данных означает, что устойчивость наших классификаторов к помехам лучше, чем представленные здесь результаты. Более того, если бы остаточные помехи в нашем наборе данных были статистически релевантными, AUC классификаторов стал бы равен 0,5 (случайное предположение) для уровня помех строго ниже 0,5. Мы не наблюдаем такого поведения в наших результатах.
VI. ВЫВОДЫ И БУДУЩИЕ РАБОТЫ
Наш вклад в этом документе — двойной.
Во-первых, мы продемонстрировали осуществимость классификации отчетов об ошибках безопасности только на основе заголовка отчета. Это особенно важно в сценариях, где полный отчет об ошибках недоступен из-за ограничений, связанных с конфиденциальностью. Например, в нашем случае отчеты об ошибках содержали конфиденциальную информацию, такую как пароли и криптографические ключи, и не были доступны для обучения классификаторов. Наш результат показывает, что идентификация ООБ может выполняться с высокой точностью, даже когда доступны только заголовки отчетов. Наша модель классификации, в которой используется сочетание TF-IDF и логистической регрессии, демонстрирует производительность AUC = 0,9831.
Во-вторых, мы проанализировали влияние обучения с неправильными метками и данных проверки. Мы сравнивали три хорошо известных метода классификации машинного обучения (упрощенный алгоритм Байеса, логистическая регрессия и AdaBoost) с точки зрения их устойчивости к различным типам и уровням помех. Все три классификатора являются устойчивыми к помехам одного класса. Помехи в обучающих данных не оказывают существенного влияния на полученный классификатор. Уменьшение AUC очень мало (0,01) для уровня помех, равного 50%. Для помех, которые присутствуют в обоих классах и не зависят от класса, модели с упрощенным алгоритмом Байеса и AdaBoost демонстрируют существенные вариации в AUC только при обучении на наборе данных с уровнями помех выше 40%.
Наконец, зависящие от класса помехи значительно влияют на AUC только в том случае, если в обоих классах более 35% помех. Наибольшую устойчивость продемонстрировал классификатор AdaBoost. Влияние на AUC очень мало, даже если 50% меток в позитивном классе имеют помехи, при условии, что негативный класс содержит 45% или меньше меток с помехами. В этом случае падение AUC составляет меньше 0,03. Насколько нам известно, это первое систематическое исследование влияния содержащих помехи наборов данных на выявление отчетов об ошибках, связанных с безопасностью.
БУДУЩИЕ РАБОТЫ
В этом документе мы начали систематическое изучение влияния помех на производительность классификаторов машинного обучения для выявления ошибок, связанных с безопасностью. У этой работы есть несколько интересных продолжений, включая исследование влияния содержащих помехи наборов данных на определение степени серьезности ошибок безопасности; понимание влияния несбалансированности класса на устойчивость обученных моделей к помехам; понимание влияния помех, добавляемых в набор данных с целью его ухудшения.
ССЫЛКИ
[1] Джон Анвик (John Anvik), Линдон Хью (Lyndon Hiew) и Гейл Мерфи (Gail C Murphy). Who should fix this bug? (Кто должен исправить эту ошибку?) В Proceedings of the 28th international conference on Software engineering (Материалы 28-й международной конференции по программной инженерии), страницы 361–370. ACM, 2006 г.
[2] Дикша Бехл (Diksha Behl), Сахил Ханда (Sahil Handa) и Анужа Арора (Anuja Arora). A bug mining tool to identify and analyze security bugs using naive bayes and tf-idf (Средство интеллектуального анализа ошибок для выявления и анализа ошибок безопасности с помощью упрощенного алгоритма Байеса и алгоритма TF-IDF). В Optimization, Reliabilty, and Information Technology (Оптимизация, надежность и информационные технологии) (ICROIT), международная конференция 2014 г., страницы 294–299. IEEE, 2014 г.
[3] Николас Беттенбург (Nicolas Bettenburg), Рахуль Премраж (Rahul Premraj), Томас Зиммерманн (Thomas Zimmermann) и Сунхунь Ким (Sunghun Kim). Duplicate bug reports considered harmful really? (Действительно ли дублированные отчеты об ошибках вредны?) В обслуживании программного обеспечения 2008 г. ICSM 2008. Международная конференция IEEE на страницах 337–345. IEEE, 2008 г.
[4] Андрес Фоллеко (Andres Folleco), Тагхи М. Хошгофтаар (Taghi M Khoshgoftaar), Джейсон Ван Хулсе (Jason Van Hulse) и Лофтон Буллард (Lofton Bullard). Identifying learners robust to low quality data (Выявление обучаемых алгоритмов, устойчивых к низкому качеству данных). В разделе "Повторное использование и интеграция информации" 2008 г. IRI 2008. Международная конференция IEEE на страницах 190–195. IEEE, 2008 г.
[5] Беноа Френе (Benoˆıt Frenay). Uncertainty and label noise in machine learning (Неопределенность и помехи меток в машинном обучении). Кандидатская диссертация, Лёвенский католический университет, Лёвен, Бельгия, 2013 г.
[6] Беноа Френе (Benoˆıt Frenay) и Мишель Верлейсен (Michel Verleysen). Classification in the presence of´ label noise: a survey (Классификация с присутствием помех в метках: исследование). IEEE: transactions on neural networks and learning systems (Транзакции в нейронных сетях и системах обучения), 25(5):845–869, 2014 г.
[7] Майкл Джегик (Michael Gegick), Пит Ротелла (Pete Rotella) и Тао Се (Tao Xie). Определение отчетов об ошибках безопасности с помощью интеллектуального анализа текста: промышленное исследование. В Mining software repositories (MSR), 2010 7th IEEE working conference (Интеллектуальный анализ репозиториев программного обеспечения, 7-я рабочая конференция IEEE) 2010 г., страницы 11–20. IEEE, 2010 г.
[8] Катерина Госева-Попстоянова (Katerina Goseva-Popstojanova) и Якоб Тио (Jacob Tyo). Identification of security related bug reports via text mining using supervised and unsupervised classification (Идентификация отчетов об ошибках безопасности с помощью интеллектуального анализа текста с использованием контролируемой и неконтролируемой классификации). В 2018 IEEE International Conference on Software Quality, Reliability and Security (QRS) (Международная конференция по качеству, надежности и безопасности программного обеспечения IEEE) 2018 г., страницы 344—355, 2018 г.
[9] Ахмед Ламканфи (Ahmed Lamkanfi), Серж Демейе (Serge Demeyer), Эмануэль Жиже (Emanuel Giger) и Барт Гоэтальс (Bart Goethals). Predicting the severity of a reported bug (Прогнозирование серьезности обнаруженной ошибки). В Mining software repositories (MSR), 2010 7th IEEE working conference (Интеллектуальный анализ репозиториев программного обеспечения, 7-я рабочая конференция IEEE) 2010 г., страницы 1–10. IEEE, 2010 г.
[10] Нареш Манвани (Naresh Manwani) и П. С. Састри (PS Sastry). Noise tolerance under risk minimization (Толерантность к помехам в условиях снижения рисков). IEEE transactions on cybernetics (Транзакции IEEE в кибернетике), 43(3):1146–1151, 2013 г.
[11] Дж. Мерфи и Д. Кубраник (G Murphy and D Cubranic). Automatic bug triage using text categorization (Автоматическое рассмотрение ошибок с помощью классификации текста). В Proceedings of the Sixteenth International Conference on Software Engineering & Knowledge Engineering (Материалы 16-й международной конференции по программной инженерии и инженерии знаний). Citeseer, 2004 г.
[12] Мыкола Печенизький (Mykola Pechenizkiy), Алексей Цимбал (Alexey Tsymbal), Сеппо Пууронен (Seppo Puuronen) и Олександр Печенизький (Oleksandr Pechenizkiy). Шум класса и защищенное обучение в медицинских доменах: эффект извлечения признаков. В null, страницы 708–713. IEEE, 2006 г.
[13] Шарлотта Пеллетие (Charlotte Pelletier), Сильвия Валеро (Silvia Valero), Джорди Инглада (Jordi Inglada), Николас Чемпион (Nicolas Champion), Клэр Мерэ Сикр (Claire Marais Sicre) и Жерар Дедье (Gerard Dedieu).´ Effect of training class label noise on classification performances for land cover mapping with satellite image time series (Воздействие помех меток класса обучения на производительность классов для отображения карт местности с помощью временного ряда спутниковых изображений). Remote Sensing (Дистанционное зондирование), 9(2):173, 2017 г.
[14] П. С. Састри (PS Sastry), Г. Д. Нагендра (GD Nagendra) и Нареш Манвани (Naresh Manwani). Группа по автоматам обучения непрерывного действия для толерантного к помехам обучения полупространств. IEEE: Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) (Транзакции с участием систем, людей и кибернетики, часть B (Кибернетика)), 40(1):19–28, 2010 г.
[15] Чо-Мань Тэн (Choh-Man Teng). A comparison of noise handling techniques (Сравнение методов обработки помех). В FLAIRS Conference (Конференция FLAIRS), страницы 269–273, 2001.
[16] Думиду Вижайасекара (Dumidu Wijayasekara), Милос Манич (Milos Manic), и Майлс Макквин (Miles McQueen). Vulnerability identification and classification via text mining bug databases (Выявление и классификация уязвимостей через базы данных ошибок интеллектуального анализа текста). В промышленном обществе электроники, IECON 2014-40-й ежегодной конференции IEEE, страницы 3612–3618. IEEE, 2014.
[17] Синьли Ян (Xinli Yang), Дэвид Ло (David Lo), Цяо Хуань (Qiao Huan), Синь Ся (Xin Xia) и Цзяньлин Сунь (Jianling Sun). Automated identification of high impact bug reports leveraging imbalanced learning strategies (Автоматическое определение отчетов об ошибках с высоким влиянием с помощью стратегий несбалансированного обучения). В Computer Software and Applications Conference (COMPSAC), 2016 IEEE 40th Annual (40-я ежегодная конференция по программному обеспечению и приложениям IEEE), 2016 г., том 1, страницы 227–232. IEEE, 2016 г.
[18] Децин Цзоу (Deqing Zou), Чжицзюнь Дэн (Zhijun Deng), Чжень Ли (Zhen Li) и Хай Цзинь (Hai Jin). Automatically identifying security bug reports via multitype features analysis (Автоматическое определение отчетов об ошибках безопасности с помощью анализа многотиповых характеристик). В Australasian Conference on Information Security and Privacy (Австралийская конференция по информационной безопасности и конфиденциальности), страницы 619–633. Springer, 2018 г.