Моделирование угроз для систем и зависимостей в области ИИ и ML
Авторы: Эндрю Маршалл (Andrew Marshall), Джугал Парикх (Jugal Parikh), Емре Кисиман (Emre Kiciman) и Рам Шанкар Шива Кумар (Ram Shankar Siva Kumar)
Особая благодарность Раулю Рохасу (Raul Rojas) и комитету AETHER (рабочему потоку обеспечения безопасности)
Ноябрь 2019 г.
Этот документ выработан Рабочей группой инженерных методик для ИИ, входящей в состав комитета AETHER. Он дополняет существующие методы моделирования угроз в рамках SDL и содержит новые рекомендации по регистрации и устранению угроз, разработанные специально для области ИИ и машинного обучения (ML). Документ следует использовать в качестве справки в ходе проверок системы безопасности для таких продуктов и служб:
Продукты и службы, взаимодействующие со службами на основе ИИ/ML или зависящие от них.
Продукты и службы, создаваемые на основе ИИ/ML.
Традиционная защита от угроз безопасности сейчас важнее, чем когда-либо. Требования, установленные в разделе Жизненный цикл разработки защищенных приложений, играют ключевую роль в определении принципов обеспечения безопасности продукта, лежащих в основе данного руководства. Неспособность справиться с традиционными угрозами безопасности открывает возможности для описанных в этом документе атак, нацеленных на системы ИИ/ML (как цифровых, так и физических), а также упрощает распространение угроз в стеке программного обеспечения. Общие сведения о новых угрозах безопасности в этой области см. в статье Безопасное будущее ИИ и машинного обучения в Майкрософт.
Как правило, инженеры по безопасности и специалисты по обработке и анализу данных обладают совершенно разными наборами навыков. Используя это руководство, представители обоих направлений смогут вести структурированные беседы об этих новых угрозах и устранении рисков, причем им не потребуется осваивать вторую профессию.
Документ состоит из двух следующих разделов:
- "Новые ключевые соображения по моделированию угроз". Здесь рассматриваются новые способы мышления и новые вопросы, на которые следует найти ответы при моделировании угроз для систем ИИ и машинного обучения. Специалисты по обработке и анализу данных и инженеры по безопасности должны ознакомиться с этим разделом, так как он станет их "сборником схем" для бесед о моделировании угроз и определения приоритетов в устранении рисков.
- "Угрозы, специфичные для ИИ и машинного обучения, и их устранение". Этот раздел содержит подробные сведения об атаках, направленных на системы ИИ и ML. В нем также описаны конкретные действия по устранению рисков, используемые сегодня для защиты продуктов и служб Майкрософт от этих угроз. Этот раздел в основном предназначен для специалистов по обработке и анализу данных, которым может потребоваться принять определенные меры по предотвращению угроз по результатам процесса моделирования угроз и проверки безопасности.
Это руководство организовано вокруг состязательной Машинное обучение таксономии угроз, созданной Рамом Шенкаром Кумаром, Дэвидом О'Брайен, Кендра Альбертом, Саломом Вильджоэном и Джеффри Snover под названием "Режимы сбоя в Машинное обучение". Рекомендации по управлению инцидентами по устранению угроз безопасности, описанных в этом документе, см. в строке ошибок SDL для угроз ИИ/ML. Все это живые документы, которые будут развиваться со временем с ландшафтом угроз.
Основные новые рекомендации в моделировании угроз: изменение способа просмотра границ доверия
Предполагается компрометация или отравление данных, которые используются для обучения, а также поставщика данных. В этом разделе описано, как обнаруживать аномальные и вредоносные записи данных, как различать их и восстанавливать данные.
Итоги
Задача моделирования угроз в числе прочего охватывает хранилища данных для обучения и системы, в которых они размещены. Наиболее серьезная угроза безопасности в машинном обучении на сегодняшний день — отравление данных. Это связано с нехваткой стандартных средств обнаружения и устранения угроз в этой области, а также с зависимостью от ненадежных или непроверенных общедоступных наборов данных, из которых берутся данные для обучения. Чтобы обеспечить достоверность данных и исключить цикл обучения "мусор на входе — мусор на выходе", очень важно отслеживать их источник и происхождение.
Вопросы, на которые необходимо ответить в ходе проверки безопасности
Если ваши данные отравлены или незаконно изменены, как вы об этом узнаете?
– Какую телеметрию вы используете, чтобы определять отклонения в качестве данных для обучения?
Проводите ли вы обучение на основе данных, которые предоставляют пользователи?
– Какие виды проверки и очистки вы применяете к таким данным?
– Задокументирована ли структура этих данных подобно этим спецификациям наборов данных?
Если для обучения используются данные из сетевых хранилищ, то какие действия вы выполняете, чтобы обеспечить безопасность соединения между моделью и данными?
– Есть ли способ сообщать о компрометации потребителям каналов?
– Существует ли вообще такая возможность??
Насколько конфиденциальны данные, которые вы используете для обучения?
– Выполняете ли вы их каталогизацию, контролируете ли добавление, обновление и удаление записей данных?
Может ли ваша модель давать на выходе конфиденциальные данные?
– Были ли эти данные получены с разрешения источника?
Выдает ли модель только результаты, необходимые для достижения поставленной цели?
Возвращает ли модель предварительные оценки достоверности или какие-либо другие выходные данные, которые можно записать и дублировать?
Как влияет инверсия вашей модели или атака на нее на восстановление данных для обучения?
Если уровни достоверности выходных данных модели внезапно упадут, есть ли возможность узнать, как, почему и из-за каких именно данных это произошло?
Определили ли вы правильный формат входных данных для модели? Как вы обеспечиваете соответствие входных данных этому формату? Что вы делаете, если они ему не соответствуют?
Если выходные данные неверны, но это не вызывает сообщений об ошибках, как вы узнаете о проблеме?
Знаете ли вы, устойчивы ли ваши алгоритмы обучения к состязательным входным данным на математическом уровне?
Как вы выполняете восстановление после загрязнения данных для обучения состязательным содержимым?
– Можете ли вы изолировать или поместить на карантин состязательное содержимое и переучить затронутые модели?
– Можете ли вы выполнить откат или восстановление до модели предыдущей версии с целью повторного обучения?
Используете ли вы обучение с подкреплением на непроверенном общедоступном содержимом?
Подумайте о происхождении ваших данных. При поиске проблемы могли ли вы отследить ее до ее появления в наборе данных? Если нет, не проблема ли это?
Вам нужно знать, откуда берутся данные для обучения, и определить статистические нормы, чтобы понимать, как выглядят аномалии.
– Какие элементы данных для обучения уязвимы для внешнего влияния?
– Кто может наполнять наборы данных, которые вы используете для обучения?
– Как бы вы атаковали свои источники данных для обучения, чтобы навредить конкуренту?
Связанные угрозы и способы их устранения в этом документе
Состязательное искажение (все варианты)
Отравление данных (все варианты)
Примеры атак
Принудительная классификация полезных сообщений как спама или предотвращение обнаружения вредоносного примера.
Создание злоумышленником входных данных, позволяющих снизить уровень достоверности правильной классификации, особенно в сценариях с серьезными последствиями.
Внедрение злоумышленником случайного шума в исходные данные, которые подвергаются классификации, чтобы уменьшить вероятность использования правильной классификации в будущем, что приводит к серьезному ухудшению модели.
Загрязнение данных для обучения с целью неправильной классификации выбранных точек данных, что приводит к выполнению определенных действий или остается незамеченным системой.
Выявление действий, которые может совершить модель, продукт или служба и которые могут навредить клиенту в цифровом или материальном мире
Итоги
Неустраненные атаки на системы ИИ и машинного обучения могут выйти за пределы цифрового мира и нанести вред в мире материальном. Любой сценарий, который можно извратить таким образом, чтобы навредить пользователям психологически или физически, — это катастрофический риск для вашего продукта или службы. Речь идет, в том числе, о любых конфиденциальных данных клиентов, использованных для обучения, и о проектных решениях, которые могут привести к утечке таких частных данных.
Вопросы, на которые необходимо ответить в ходе проверки безопасности
Выполняете ли вы обучение на состязательных примерах? Какое влияние они оказывают на выходные данные модели в материальном мире?
В чем заключается троллинг, если говорить о вашем продукте или службе? Как вы можете выявить его и прореагировать?
Каким образом можно заставить вашу модель возвратить результат, который вынудит службу запретить доступ легальным пользователям?
К каким последствиям приведет копирование или кража модели?
Можно ли использовать вашу модель, чтобы установить принадлежность отдельного лица к определенной группе или просто определить, что оно упоминается в данных для обучения?
Может ли злоумышленник подорвать репутацию вашего продукта или вызвать негативное отношение к нему, принудив его выполнять определенные действия?
Как вы обрабатываете правильно отформатированные, но явно смещенные данные, например полученные от троллей?
Есть ли возможность раскрыть данные для обучения или принципы работы модели, изучив какой-либо из известных способов взаимодействия с ней или отправки запроса к ней?
Связанные угрозы и способы их устранения в этом документе
Определение членства
Инверсия модели
Захват модели
Примеры атак
Реконструкция и извлечение данных для обучения путем многократной отправки запросов к модели для получения максимально достоверных результатов.
Дублирование самой модели с помощью исчерпывающего сопоставления запросов и ответов.
Отправка запросов к модели таким способом, который позволяет раскрыть определенный элемент частных данных, включенных в набор для обучения.
Принуждение беспилотного автомобиля к игнорированию знаков остановки и сигналов светофора.
Манипулирование ботами, чтобы заставить их применять троллинг к обычным пользователям.
Выявление всех источников зависимостей ИИ/ML, а также уровней представления данных для пользователей в цепочке поставок данных и модели.
Итоги
Многие атаки на системы ИИ и машинного обучения начинаются с легального доступа к интерфейсам API, которые предоставляются для обеспечения доступа к модели с помощью запросов. Использование обширных источников данных и многофункциональных пользовательских интерфейсов приводит к тому, что доступ третьих лиц, прошедших аутентификацию, но "неприемлемых" (здесь есть серая зона) несет с собой риск, так как такие лица получают возможность действовать в качестве уровня представления данных поверх службы, которую предоставляет Майкрософт.
Вопросы, на которые необходимо ответить в ходе проверки безопасности
Какие клиенты или партнеры аутентифицированы для доступа к API модели или службы?
– Могут ли они действовать в качестве уровня представления данных поверх вашей службы?
– Можете ли вы немедленно запретить им доступ в случае компрометации?
– Какова ваша стратегия восстановления на случай вредоносного использования вашей службы или зависимостей?
Может ли третье лицо построить фасад вокруг вашей модели, чтобы изменить ее назначение и нанести ущерб корпорации Майкрософт или ее клиентам?
Предоставляют ли клиенты данные для обучения непосредственно вам?
– Как вы защищаете эти данные?
– Что, если они вредоносны, а ваша служба является целью?
Как выглядит ложноположительный результат? Каковы последствия ложноположительного результата?
Можете ли вы отслеживать и измерять отклонение количества истинноположительных и ложноположительных результатов в нескольких моделях?
Какая телеметрия вам нужна, чтобы доказать достоверность выходных данных модели клиентам?
Выявите все зависимости от третьих лиц в своей цепочке поставок данных машинного обучения (не только программное обеспечение с открытым кодом, но и поставщиков данных).
– Почему вы используете их и как проверяете их надежность?
Вы используете готовые модели, полученные от третьих лиц, или отправляете данные для обучения сторонним поставщикам MLaaS (ML как услуга)?
Изучите информационные материалы об атаках на подобные продукты и службы. С учетом того, что многие угрозы для ИИ и ML могут быть направлены на модели разных типов, какие последствия имели бы эти атаки для ваших продуктов?
Связанные угрозы и способы их устранения в этом документе
Перепрограммирование нейронной сети
Состязательные примеры в материальном мире
Восстановление данных для обучения злоумышленниками из числа поставщиков услуг ML
Атака на цепочку поставок услуг ML
Взлом модели с использованием бэкдора
Скомпрометированные зависимости, используемые для ML
Примеры атак
Злоумышленник из числа поставщиков услуг ML внедряет троян в вашу модель, используя обходной путь.
Злоумышленник обнаруживает уязвимость в используемой зависимости от распространенного ПО с открытым кодом и отправляет атакующий код со специально подготовленными данными для обучения, чтобы скомпрометировать вашу службу.
Неразборчивый партнер использует API для распознавания лиц и создает уровень представления данных поверх вашей службы, чтобы синтезировать дипфейки.
Угрозы, специфичные для ИИ и машинного обучения, и их устранение
#1: состязательное возмущение
Description
При искажающих атаках злоумышленник незаметно изменяет запрос, чтобы получить нужный ответ от модели, развернутой в рабочей среде [1]. Это нарушает целостность входных данных модели, что приводит к атакам методом фаззинга, которые не обязательно нацелены на нарушение прав доступа или завершение работы программы. Вместо этого они нарушают способность модели выполнять классификацию. Это могут быть интернет-тролли, использующие определенные слова таким образом, чтобы ИИ запрещал их использование. Такой прием позволяет заставить систему отказывать в обслуживании легальному пользователю, имя которого совпадает с запрещенным словом.
 [24]
[24]
Вариант #1a: целевое неправильное классификация
В этом случае злоумышленники создают пример, который не входит в класс входных данных целевого классификатора, но классифицируется моделью как принадлежащий именно к этому классу входных данных. Для человеческого глаза состязательный пример может выглядеть как случайный шум, но злоумышленники обладают определенными знаниями о целевой системе машинного обучения, что позволяет им создать белый шум, который не является случайным, а использует некоторые специфические аспекты целевой модели. Злоумышленник предоставляет пример входных данных, который не является допустимым, но целевая система классифицирует его как принадлежащий к одному из допустимых классов.
Примеры
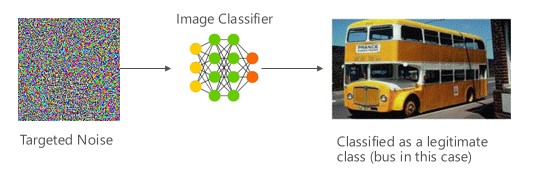 [6]
[6]
Устранение проблем
Усиление состязательности с помощью достоверности модели, вызванной состязательным обучением [19]: авторы предлагают высоко уверенную близкое соседство (HCNN), платформу, которая объединяет сведения о достоверности и ближайшем поиске соседей, чтобы укрепить состязательность базовой модели. Это помогает различать правильные и неправильные прогнозы модели по соседству с точкой из базового обучающего распределения.
Анализ причин, управляемый атрибуцией [20]: авторы изучают связь между устойчивостью к состязательности и объяснениям на основе возмездия отдельных решений, созданных моделями машинного обучения. Авторы сообщают о том, что состязательные входные данные не являются надежными в пространстве атрибуции, т. е. маскировка нескольких признаков с высокой атрибуцией приводит к изменению неправильного решения модели машинного обучения на состязательных примерах. Напротив, естественные входные данные надежны в пространстве атрибуции.
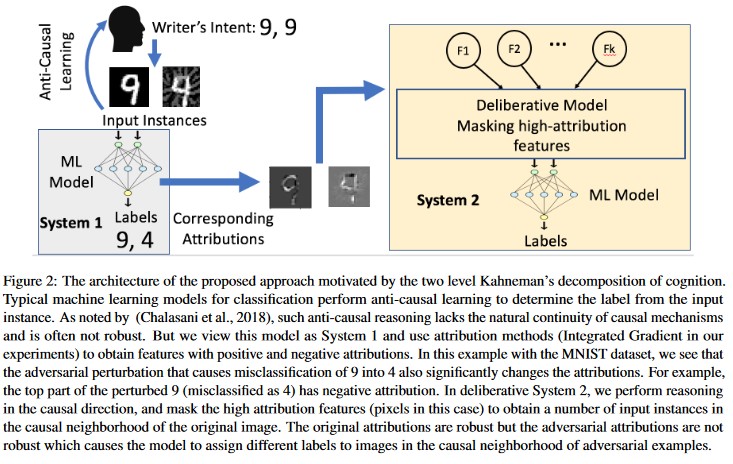 [20]
[20]
Эти подходы могут сделать модели машинного обучения более устойчивыми к состязательным атакам, так как чтобы обмануть систему с двумя уровнями распознавания, нужно не только атаковать исходную модель, но и обеспечить сходство атрибуции, генерируемой для состязательного примера, с атрибуцией для исходных примеров. Чтобы состязательная атака была успешной, обе системы должны быть скомпрометированы одновременно.
Традиционные аналоги
Удаленное повышение привилегий, так как злоумышленник теперь контролирует вашу модель
Важность
Критически важно
Вариант #1b: неправильное классификация исходного или целевого объекта
Это попытка злоумышленника получить модель, которая возвращает нужную метку для конкретных входных данных. Обычно это выражается в том, что модель принудительно возвращает ложноположительный или ложноотрицательный результат. В итоге злоумышленник незаметно получает возможность контролировать точность классификации модели и может произвольно инициировать определенные обходные пути.
Эта атака оказывает серьезное негативное влияние на точность классификации, однако ее проведение требует много времени. Это связано с тем, что злоумышленник должен манипулировать исходными данными таким образом, чтобы им не только перестали присваиваться правильные метки, но и присваивалась особая мошенническая метка. Эти атаки, целью которых является неправильная классификация, часто состоят из нескольких шагов или попыток [3]. Если модель чувствительна к атакам с передачей обучения, которые принуждают ее к нацеленной неправильной классификации, то злоумышленник может и не оставить заметного следа в виде трафика, так как зондирующие атаки могут быть выполнены без подключения к сети.
Примеры
Принудительная классификация полезных сообщений как спама или предотвращение обнаружения вредоносного примера. Эта уловка также известна, как искажение модели или имитационные атаки.
Устранение проблем
Реактивные и оборонительные действия по обнаружению
- Установите минимальное пороговое значение времени между вызовами API, который предоставляет результаты классификации. Это замедлит тестирование многоэтапной атаки, так как увеличится общее время, необходимое для поиска успешного искажения.
Упреждающие и защитные действия
Отмена функции для улучшения состязательности [22]: авторы разрабатывают новую сетевую архитектуру, которая повышает состязательность, выполняя денузирование функций. В частности, сети содержат блоки, которые очищают признаки от шумов с помощью нелокальных средств или других фильтров; целые сети проходят обучение комплексно. В сочетании с состязательным обучением сети с очисткой признаков от шумов значительно повышают устойчивость к состязательным атакам при тестировании по принципам как "белого", так и "черного ящика".
Состязательное обучение и нормализация: обучение с помощью известных состязательности и надежности для вредоносных входных данных. Это можно также рассматривать как форму регуляризации, при которой к норме градиентов входных данных применяется штраф, а функция прогнозирования классификатора сглаживается (расширяются границы входных данных). Это относится и к правильным классификациям с невысокой степенью достоверности.
Инвестируйте в разработку монотонной классификации с выбором монотонных признаков. В этом случае злоумышленник не сможет уклониться от классификатора, просто указывая признаки из негативной группы [13].
Сжатие признаков [18] можно использовать для защиты глубоких нейронных сетей путем обнаружения состязательных примеров. Это сокращает пространство поиска, доступное злоумышленнику, за счет объединения примеров, которые соответствуют многим различным векторам признаков в исходном пространстве, в один пример. Сравнивая прогноз глубокой нейронной сети на основании исходных входных данных с прогнозом на основании сжатых входных данных, можно выявлять состязательные примеры. Если для исходного и сжатого примеров результаты, возвращенные моделью, существенно различаются, то, скорее всего, это состязательный пример. Измерив расхождение между прогнозами и выбрав пороговое значение, система может вывести правильный прогноз для допустимых примеров и отклонить входные данные состязательного примера.

 [18]
[18]Сертифицированные защиты от состязательные примеры [22]: авторы предлагают метод на основе полуопределенного расслабления, который выводит сертификат, который для заданной сети и входных данных теста, атака не может принудительно превысить определенное значение. Кроме того, так как это дифференцируемый сертификат, авторы совместно оптимизируют его с параметрами сети, предоставляя адаптивный регуляризатор, который способствует устойчивости против всех атак.
Ответные действия
- Выдача оповещений о результатах классификации с большим расхождением между классификаторами, особенно если это данные от одного пользователя или небольшой группы.
Традиционные аналоги
Удаленное повышение привилегий
Важность
Критически важно
Вариант #1c: случайное неправильное классификация
Это особый вариант, в котором целевая классификация по замыслу злоумышленника может быть любой, но отличаться от правильной исходной классификации. Такая атака обычно предполагает внедрение случайного шума в исходные данные, которые подвергаются классификации, чтобы уменьшить вероятность использования правильной классификации в будущем [3].
Примеры
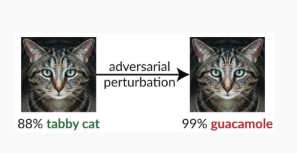
Устранение проблем
Те же методы, что для варианта 1а.
Традиционные аналоги
Непостоянный отказ в обслуживании
Важность
Важно!
Вариант #1d: уменьшение достоверности
Злоумышленник может создать входные данные, позволяющие снизить уровень достоверности правильной классификации, особенно в сценариях с серьезными последствиями. Атака также может осуществляться в виде потока ложноположительных результатов, призванных перегрузить администраторов или системы мониторинга фальшивыми оповещениями, которые невозможно отличить от настоящих [3].
Примеры

Устранение проблем
- Помимо действий, описанных в variant #1a, можно использовать регулирование событий для уменьшения объема оповещений из одного источника.
Традиционные аналоги
Непостоянный отказ в обслуживании
Важность
Важно!
#2a целевое отравление данных
Description
Цель злоумышленника — испортить машинную модель, созданную на этапе обучения, чтобы изменить прогнозы, основанные на новых данных, на этапе тестирования [1]. При целевых атаках с отравлением данных злоумышленник стремится изменить классификационную принадлежность определенных примеров, чтобы заставить систему выполнять или пропускать определенные действия.
Примеры
Антивирусное программное обеспечение преподносится как вредоносное, что позволяет включить его в категорию вредоносного ПО и запретить его использование в клиентских системах.
Устранение проблем
Определение датчиков аномалий для просмотра распределения данных каждый день и создания оповещений об отклонениях.
– Ежедневное измерение данных для обучения, телеметрия для отклонений и смещений.
Проверка входных данных, их очистка и проверка целостности.
При отравлении добавляются примеры для обучения, выпадающие из общего ряда. Для противостояния этой угрозе используются две основные стратегии:
– Очистка и проверка данных: удаление поддельных примеров из данных для обучения — Бэггинг для борьбы с атаками путем отравления [14].
– Защита методом отбраковки при негативном влиянии (Reject-on-Negative-Impact, RONI) [15].
-Надежные Обучение. Выбор алгоритмов обучения, которые являются надежными в присутствии образцов отравлений.
-Один такой подход описан в [21], где авторы решают проблему отравлений данных двумя шагами: 1) вводя новый новый надежный метод факторизации матрицы для восстановления истинного подпространства и 2) новые надежные основные компоненты регрессии для обрезания состязательности экземпляров на основе, восстановленной на шаге (1). Авторы характеризуют необходимые и достаточные условия для успешного восстановления истинного подпространства и представляют предельное значение для ожидаемых потерь прогнозирования по сравнению с контрольным набором данных.
Традиционные аналоги
Узел, зараженный трояном, в результате чего злоумышленник продолжает оставаться в сети. Данные для обучения или данные конфигурации скомпрометированы, но при этом принимаются или считаются надежными для создания модели.
Важность
Критически важно
#2b неизбирательное отравление данных
Description
Цель заключается в том, чтобы уничтожить качество и целостность набора данных, который подвергается атаке. Многие наборы данных являются открытыми, ненадежными или непроверенными, и это создает дополнительные опасения насчет возможности в принципе выявлять такие нарушения целостности данных. Обучение на данных, о которых неизвестно, скомпрометированы ли они, порождает ситуацию "мусор на входе — мусор на выходе". Когда обнаружено отравление, необходимо рассортировать данные, чтобы определить объем повреждений и потребность в карантине и повторном обучении.
Примеры
Компания привлекает хорошо известный и надежный веб-сайт с фьючерсными данными для обучения своих моделей. После этого веб-сайт поставщика данных подвергается атаке путем внедрения кода SQL. Злоумышленник может исказить набор данных в соответствии со своими целями, но обучаемая модель не будет знать о том, что данные подделаны.
Устранение проблем
Те же методы, что для варианта 2а.
Традиционные аналоги
Отказ в обслуживании: пользователю, прошедшему аутентификацию, отказано в доступе к ценному ресурсу
Важность
Важно!
Атаки инверсии модели #3
Description
Частные функции, используемые в моделях машинного обучения, можно восстановить [1]. В частности, возможна реконструкция частных данных, которые использовались для обучения и к которым у злоумышленника нет доступа. В сообществе специалистов по биометрии эти атаки называют "атаками с поиском максимума" [16, 17]. Они осуществляются путем поиска входных данных, максимально увеличивающих возвращаемый доверительный уровень, с учетом классификации, соответствующей целевой модели [4].
Примеры
 [4]
[4]
Устранение проблем
Для интерфейсов моделей, обученных на конфиденциальных данных, требуется строгий контроль доступа.
Частота запросов к модели должна быть ограничена.
Реализуйте шлюзы между пользователями (вызывающими объектами) и фактической моделью: выполняйте проверку входных данных для всех предлагаемых запросов, отклоняйте все, что не соответствует определению правильности входных данных модели, и возвращайте только минимально необходимый объем информации.
Традиционные аналоги
Направленное тайное раскрытие информации
Важность
Согласно стандартной панели ошибок SDL, по умолчанию этой угрозе присваивается уровень "Важно", но если извлекаются конфиденциальные данные или личные сведения, серьезность становится критической.
Атака вывода членства #4
Description
Злоумышленник может определить, является ли указанная запись данных частью набора данных, использованного для обучения модели [1]. Исследователи смогли предсказать основную процедуру пациента (например, хирургия пациента прошла) на основе атрибутов (например, возраст, пол, больница) [1].
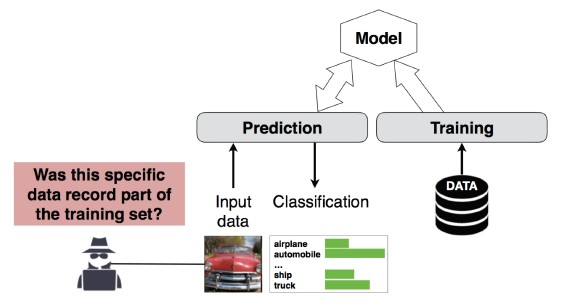 [12]
[12]
Устранение проблем
В исследовательских документах, демонстрирующих жизнеспособность таких атак, отмечается, что эффективным методом защиты от них является дифференциальная приватность [4, 9]. Это довольно новая область для Майкрософт, и комитет AETHER (рабочий поток обеспечения безопасности) рекомендует накапливать опыт и знания в ходе исследований. В ходе этих исследований необходимо определить возможности дифференциальной приватности и оценить их практическую эффективность в качестве мер по устранению риска. Затем требуется разработать способы прозрачного наследования этих средств защиты на наших платформах веб-служб, подобно тому как компиляция кода в Visual Studio обеспечивает защиту по умолчанию, прозрачную для разработчика и пользователей.
Определенный положительный эффект могут дать прореживание нейронов (дропаут) и стек моделей. Прореживание нейронов повышает не только устойчивость нейронной сети к этой атаке, но и производительность модели [4].
Традиционные аналоги
Конфиденциальность данных. Делается заключение о присутствии определенной точки данных в наборе для обучения, но сами данные для обучения при этом не раскрываются.
Важность
Это проблема конфиденциальности, а не безопасности. Она описана в руководстве по моделированию угроз, так как эти области перекрываются. Однако решать такую проблему всегда следует с точки зрения конфиденциальности.
Кража моделей #5
Description
Злоумышленники воссоздают базовую модель с помощью подлинных запросов к модели. Новая модель по своим функциональным возможностям аналогична базовой [1]. По воссозданной модели путем инверсии можно восстановить сведения о признаках или получить представление о данных для обучения.
Решение уравнений. Злоумышленник может создать запросы, позволяющие определить неизвестные переменные в модели, возвращающей вероятности класса через выходные данные API.
Нахождение пути. Эта атака использует особенности API для извлечения "решений", принятых деревом при классификации входных данных [7].
Атака с переносом. Злоумышленник может обучить локальную модель (например, отправляя прогнозирующие запросы к целевой модели) и использовать ее для создания состязательных примеров, которые передаются в целевую модель [8]. Получив копию вашей модели и обнаружив ее уязвимость к определенному типу состязательных входных данных, злоумышленник может в автономном режиме разрабатывать новые атаки на модель, развернутую в вашей рабочей среде.
Примеры
В системах, где модель машинного обучения служит для обнаружения вредоносного поведения, например для идентификации спама, классификации вредоносных программ и обнаружения аномалий в сети, извлечение моделей может облегчить атаки уклонения [7].
Устранение проблем
Упреждающие и защитные действия
Минимизируйте или замаскируйте сведения, возвращаемые API-интерфейсами прогнозирования, при этом сохранив их полезность для "честных" приложений [7].
Определите правильный формат запроса для входных данных модели и возвращайте результаты только в ответ на полные, правильно сформированные входные данные, соответствующие этому формату.
Возвращайте значения округленной достоверности. Большинству легальных авторов запросов не требуется несколько десятичных знаков.
Традиционные аналоги
Несанкционированный доступ только для чтения, незаконное изменение системных данных, направленное раскрытие информации, обладающей высокой ценностью?
Важность
Важно в моделях, чувствительных к безопасности. В остальных случаях умеренная серьезность.
Перепрограммирование нейронной сети #6
Description
С помощью специально созданного запроса злоумышленник может перепрограммировать системы машинного обучения на выполнение задач, не предусмотренных их создателем [1].
Примеры
Неэффективное управление доступом в API распознавания лиц, позволяющее третьим лицам встраивать приложения, которые предназначены для причинения вреда клиентам Майкрософт, например генератор дипфейков.
Устранение проблем
Надежная взаимная проверка подлинности и управление доступом на сервере клиента<> для интерфейсов модели
Устранение учетных записей-нарушителей.
Составление и принудительное применение соглашения об уровне обслуживания для API-интерфейсов. Определите допустимое время для устранения проблемы после сообщения о ней и гарантируйте, что она не будет воспроизводиться, пока действует соглашение об уровне обслуживания.
Традиционные аналоги
Это сценарий неправильного использования. Скорее всего, вы предпочтете просто отключить учетную запись нарушителя, а не открывать инцидент безопасности.
Важность
От важного до критического
#7 Состязательный пример в физическом домене (бит-атомы>)
Description
Пример состязательности — это ввод или запрос от вредоносной сущности, отправленной с единственной целью ввести в заблуждение систему машинного обучения [1]
Примеры
Состязательные примеры способны воздействовать на материальный мир. Например, они могут заставить беспилотный автомобиль проехать на стоп-сигнал светофора, потому что на нем загорелся цвет (вредоносные входные данные), который система распознавания изображений больше не воспринимает как знак обязательной остановки.
Традиционные аналоги
Повышение привилегий, удаленное выполнение кода
Устранение проблем
Эти атаки проявляются сами по себе, потому что проблемы на уровне машинного обучения (уровень данных и алгоритма, находящийся ниже уровня принятия решений с использованием ИИ) не были устранены. Как и в любой другой физической системе программного обеспечения *или*, уровень ниже целевого объекта всегда может быть атакован с помощью традиционных векторов. По этой причине традиционные методы обеспечения безопасности очень важны, особенно при наличии уровня с неустраненными уязвимостями (уровень данных и алгоритма) между ИИ и традиционным программным обеспечением.
Важность
Критически важно
Поставщики вредоносных машинного обучения #8, которые могут восстановить обучающие данные
Description
Поставщик-злоумышленник задействует алгоритм-лазутчик, позволяющий реконструировать частные данные, которые использовались для обучения. Он может воссоздать лица и тексты, используя только модель.
Традиционные аналоги
Направленное раскрытие информации
Устранение проблем
В исследовательских документах, демонстрирующих жизнеспособность таких атак, отмечается, что эффективным методом устранения таких рисков является гомоморфное шифрование. Это довольно новое направление для Майкрософт, и комитет AETHER (рабочий поток обеспечения безопасности) рекомендует накапливать опыт и знания в ходе исследований. В ходе этого исследования потребуется определить принципы гомоморфного шифрования и оценить их практическую эффективность в качестве мер борьбы со злоумышленниками из числа поставщиков MLaaS (ML как услуга).
Важность
Важно, если речь идет о персональных данных, в противном случае — умеренная серьезность
#9 Атака на цепочку поставок машинного обучения
Description
Из-за больших ресурсов (данных и вычислений), необходимых для обучения алгоритмов, текущая практика заключается в повторном использованию моделей, обученных крупными корпорациями, и немного изменять их для задач (например, ResNet является популярной моделью распознавания изображений от Майкрософт). Эти модели размещаются в галерее Model Zoo (на платформе Caffe можно найти популярные модели распознавания изображений). Атака нацелена на модели, размещенные в Caffe, в результате пользователи платформы имеют все шансы получить искаженную модель. [1]
Традиционные аналоги
Компрометация зависимости, не относящейся к безопасности, от третьей стороны
Непреднамеренное размещение вредоносной программы в магазине приложений
Устранение проблем
Уменьшите зависимости от третьих лиц по вопросам моделей и данных в максимально возможной степени.
Учитывайте такие зависимости в процессе моделирования угроз.
При взаимодействии ваших систем со сторонними используйте строгую проверку подлинности, управление доступом и шифрование.
Важность
Критически важно
#10 Backdoor Машинное обучение
Description
Процесс обучения передается на аутсорсинг злонамеренному третьему лицу, которое незаконно изменяет данные для обучения и предоставляет модель, зараженную трояном. Эта модель неправильно классифицирует определенные входные данные, например относит вирус к безопасному ПО [1]. Этот риск присущ сценариям, в которых модель создается по схеме MLaaS (ML как услуга).
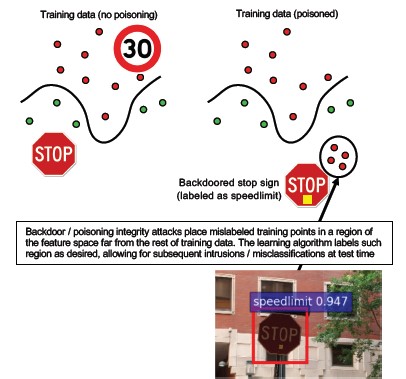 [12]
[12]
Традиционные аналоги
Компрометация зависимости, относящейся к безопасности, от третьей стороны
Компрометация механизма обновления программного обеспечения
Компрометация центра сертификации
Устранение проблем
Реактивные и оборонительные действия по обнаружению
- Если угроза обнаружена, значит, ущерб уже нанесен. Следовательно, нельзя доверять модели и всем данным для обучения, которые предоставил поставщик-злоумышленник.
Упреждающие и защитные действия
Обучение всех конфиденциальных моделей в пределах собственной организации.
Каталогизация данных для обучения или их получение от доверенного третьего лица, применяющего строгие меры безопасности.
Выполните моделирование угроз для взаимодействия между поставщиком MLaaS и вашими системами.
Ответные действия
- Те же, что и при компрометации внешней зависимости
Важность
Критически важно
#11 Зависимости программного обеспечения эксплойтов системы машинного обучения
Description
В этой атаке злоумышленник НЕ управляет алгоритмами. Он использует традиционные уязвимости программного обеспечения, например переполнение буфера или межсайтовые сценарии [1]. Нарушить безопасность программных уровней, располагающихся ниже уровня ИИ и ML, проще, чем атаковать непосредственно уровень обучения. По этой причине важны традиционные методы защиты от угроз безопасности, описанные в разделе "Жизненный цикл разработки защищенных приложений".
Традиционные аналоги
Скомпрометированная зависимость от программного обеспечения с открытым кодом
Уязвимость веб-сервера (XSS, CSRF, сбой проверки входных данных API)
Устранение проблем
Обратитесь к группе обеспечения безопасности, чтобы выполнить применимые рекомендации из разделов, посвященных жизненному циклу разработки защищенных приложений и обеспечению операционной безопасности.
Важность
Серьезность может быть разной, вплоть до критической, в зависимости от типа уязвимости традиционного программного обеспечения.
Список литературы
[1] Режимы сбоев в Машинное обучение, Рам Шанкар Сива Кумар, Дэвид О'Брайен, Кендра Альберт, Салом Вильджоэн и Джеффри Snover,https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] AETHER Security Engineering Workstream, Data Provenance/Lineage v-team.
[3] Примеры состязательности в Deep Обучение: символизация и расхождение, Wei, et al,https://arxiv.org/pdf/1807.00051.pdf
[4] Утечки МАШИНного обучения: атаки и защита независимой от членства в модели и данные в модели Машинное обучение, Салем, и т. д.https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha, and T. Ristenpart, Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures, in Proceedings of the 2015 ACM SIGSAC Conference on Computer and Communications Security (CCS).
[6] Nicolas Papernot & Patrick McDaniel- Adversarial Examples in Machine Learning AIWTB 2017.
[7] Stealing Machine Learning Models via Prediction APIs, Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, The University of North Carolina at Chapel Hill; Thomas Ristenpart, Cornell Tech.
[8] The Space of Transferable Adversarial Examples, Florian Tramèr , Nicolas Papernot , Ian Goodfellow , Dan Boneh , and Patrick McDaniel.
[9] Understanding Membership Inferences on Well-Generalized Learning Models Yunhui Long1 , Vincent Bindschaedler1 , Lei Wang2 , Diyue Bu2 , Xiaofeng Wang2 , Haixu Tang2 , Carl A. Gunter1 , and Kai Chen3,4.
[10] Simon-Gabriel et al., Adversarial vulnerability of neural networks increases with input dimension, ArXiv 2018.
[11] Lyu et al., A unified gradient regularization family for adversarial examples, ICDM 2015.
[12] Дикие шаблоны: Десять лет после подъема состязательности Машинное обучение - NeCS 2019 Battista Biggioa, Fa биография Roli
[13] Adversarially Robust Malware Detection UsingMonotonic Classification Inigo Incer et al.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto, and Fabio Roli. Bagging Classifiers for Fighting Poisoning Attacks in Adversarial Classification Tasks.
[15] Улучшенное отклонение на негативное влияние обороны Хонгцзян Ли и Патрик П.К. Чан
[16] Adler. Vulnerabilities in biometric encryption systems. 5th Int’l Conf. AVBPA, 2005.
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. On the vulnerability of face verification systems to hill-climbing attacks. Patt. Rec., 2010.
[18] Weilin Xu, David Evans, Yanjun Qi. Сжатие признаков: обнаружение состязательные примеры в глубоких нейронных сетях. 2018 Network and Distributed System Security Symposium. 18-21 February.
[19] Reinforcing Adversarial Robustness using Model Confidence Induced by Adversarial Training - Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha.
[20] Attribution-driven Causal Analysis for Detection of Adversarial Examples, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami.
[21] Robust Linear Regression Against Training Data Poisoning – Chang Liu et al.
[22] Feature Denoising for Improving Adversarial Robustness, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He.
[23] Certified Defenses against Adversarial Examples - Aditi Raghunathan, Jacob Steinhardt, Percy Liang.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по