Ресурсы, развернутые с Кластеры больших данных SQL Server
Область применения:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Важно!
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, а программное обеспечение будет по-прежнему поддерживаться с помощью SQL Server накопительных обновлений до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
Эта статья описывает ресурсы, развертываемые кластером больших данных SQL Server.
Кластер больших данных развертывает объекты pod на основе профиля развертывания. Дополнительные сведения см. в разделе Конфигурации по умолчанию.
Эта статья описывает объекты pod, развертываемые с использованием профиля aks-dev-test-ha, и пул Spark. Для просмотра объектов pod, развернутых в кластере, отправьте запрос в Kubernetes. Следующий пример возвращает список объектов pod в определенном пространстве имен.
kubectl get pods -n <namespace>
Замените <namespace> именем кластера больших данных.
Дополнительные сведения см. в статье Развертывание Кластеры больших данных SQL Server в Kubernetes.
На следующей схеме показаны компоненты, развернутые в кластере больших данных:
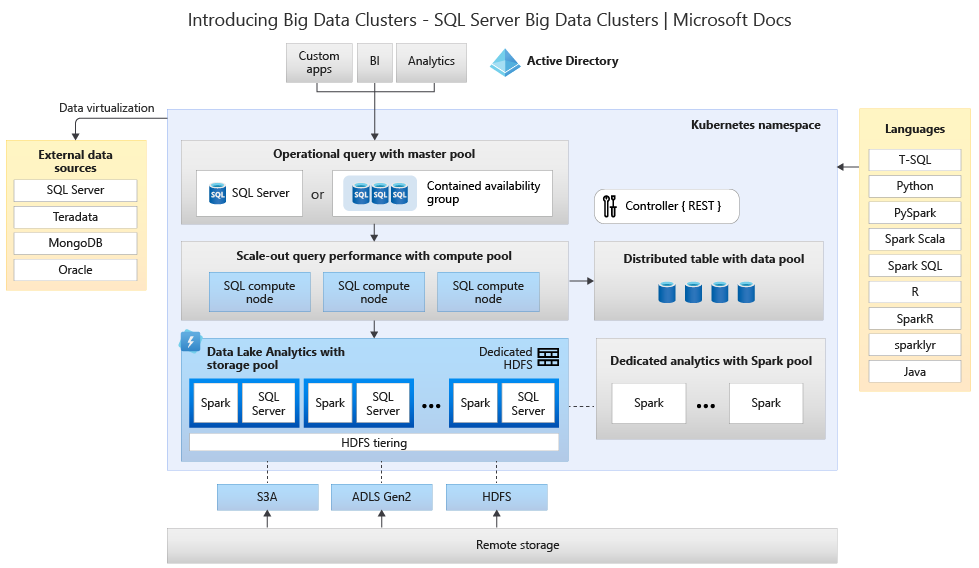
Дополнительные сведения об архитектуре см. в разделе Общие сведения о Кластеры больших данных SQL Server.
Развернутые модули
В следующей таблице приведен список объектов pod, развернутых в кластере больших данных.
| Имя | Область |
|---|---|
control-<nnnn> |
Управление |
controldb-<#> |
Управление |
controlwd-<nnnn> |
Управление |
logsdb-<#> |
Управление |
logsui-<nnnn> |
Управление |
metricsdb-<#> |
Управление |
metricsdc-<nnnn> |
Управление |
metricsui-<nnnn> |
Управление |
mgmtproxy-<nnnn> |
Управление |
zookeeper-<#> |
Управление |
dns-<nnnn> |
Управление |
master-<#n> |
Главный экземпляр |
operator-<nnnn> |
Главный экземпляр |
compute-<#n>-<#m> |
Вычислительный пул |
data-<#>-<#> |
Пул данных |
storage-<#>-<#> |
Пул носителей |
nmnode-<#>-<#> |
Пул носителей |
sparkhead-<#> |
Пул носителей |
appproxy-<#m> |
Пул приложений |
gateway-<#> |
Служба шлюза |
Не все объекты pod включены в каждый кластер больших данных. Развертывания с высоким уровнем доступности или интеграции с Active Directory включают специальные объекты pod.
Объекты pod, связанные с высокой доступностью:
operator-<nnnn>zookeeper-<#>
Объекты pod, связанные с Active Directory:
dns-<nnnn>
В следующих разделах описаны объекты pod и перечислены контейнеры в каждом из объектов.
Control
Объекты pod управления предоставляют службу управления.
| Имя объекта pod | Count | Тип контроллера Kubernetes | Контейнеры |
|---|---|---|---|
control-# |
1 | ReplicaSet | - controller- security-support- fluentbit |
controldb |
1 | StatefulSet | - mssql-server- fluentbit |
controlwd |
1 | ReplicaSet | - controlwatchdog |
logsdb-# |
1 | StatefulSet | - elasticsearch |
logsui |
1 | ReplicaSet | - kibana |
metricsdb-# |
1 | StatefulSet | - influxdb |
metricsdc |
1 на узел Kubernetes. | DaemonSet | - telegraf |
metricsui-nnnn |
1 | ReplicaSet | - grafana |
mgmtproxy-nnnn |
1 | ReplicaSet | - service-proxy- fluentbit |
dns-nnnn |
0 или 1 для интеграции с Active Directory | ReplicaSet | - dns- fluentbit |
Главный экземпляр
master-<#n> — это главный экземпляр SQL Server.
- Управляет пулом данных с помощью языка DDL.
- Управляет данными в пуле данных с помощью языка DML.
- Разгружает выполнение аналитического запроса в пул данных.
| Имя объекта pod | Count | Тип контроллера Kubernetes | Контейнеры |
|---|---|---|---|
master-<#n> |
1 или более для высокого уровня доступности. | StatefulSet | - mssql-server- fluentbit- collectd- mssql-ha-supervisor * |
operator* |
0 или 1 для высокого уровня доступности | ReplicaSet | - mssql-ha-operator |
* Только развертывания с высоким уровнем доступности. Оператор реализует и регистрирует определение пользовательского ресурса для SQL Server и ресурсы группы доступности. При развертывании оператор регистрирует себя в качестве прослушивателя для уведомлений о ресурсах SQL Server, развертываемых в кластере Kubernetes. mssql-ha-supervisor поддерживает группу доступности.
Каждый объект pod master содержит один экземпляр SQL Server. Развертывание с высоким уровнем доступности включает 3 объекта pod. Каждый объект pod содержит экземпляр SQL Server с базами данных в группе доступности AlwaysOn SQL Server.
Вы можете включать дополнительные объекты pod во время развертывания, в зависимости от рабочей нагрузки.
Вычислительный пул
Вычислительный пул предоставляет экземпляр SQL Server для вычислений.
| Имя объекта pod | Count | Тип контроллера Kubernetes | Контейнеры |
|---|---|---|---|
compute-<#n>-<#m> |
1 или более. | StatefulSet | - mssql-server- fluentbit- collectd |
#nидентифицирует вычислительный пул.#mидентифицирует идентификатор экземпляра в пуле.
Экземпляры SQL Server вычислительного пула не учитывают состояние. Им требуется хранилище только для tempdb.
Вы можете включать дополнительные объекты pod во время развертывания, в зависимости от рабочей нагрузки.
Пул данных
Пул данных предоставляет экземпляры SQL Server для хранения и вычислений.
| Имя объекта pod | Count | Тип контроллера Kubernetes | Контейнеры |
|---|---|---|---|
data-<#n>-<#m> |
0 или больше | StatefulSet | - mssql-server - fluentbit- collectd |
#nидентифицирует пул данных.#mидентифицирует идентификатор экземпляра в пуле.
Вы можете включать дополнительные объекты pod во время развертывания, в зависимости от рабочей нагрузки.
Пул носителей
Пул носителей обеспечивает прием данных через Spark, хранилище в HDFS, доступ к данным через HDFS и конечные точки SQL Server.
| Имя объекта pod | Count | Тип контроллера Kubernetes | Контейнеры |
|---|---|---|---|
storage-0-# |
1 или более. Вы можете включать дополнительные объекты pod во время развертывания, в зависимости от рабочей нагрузки. | StatefulSet | - hadoop- mssql-server- fluentbit |
nmnode-0-# |
1 или более для высокого уровня доступности. | StatefulSet | - hadoop- fluentbit |
sparkehead-# |
1 или более для высокого уровня доступности. | StatefulSet | - hadoop-yarn-jobhistory- hadoop-livy-sparkhistory- hadoop-hivemetastore-- fluentbit |
zookeeper |
0 или 3 для высокого уровня доступности. | StatefulSet | - zookeeper- fluentbit |
Пул приложений
Пул приложений включен в некоторые профили конфигурации теста. В пуле приложений размещаются прокси-серверы службы приложений, которые вы определяете при развертывании приложений для кластеров больших данных.
appproxy — это веб-API, располагающийся перед приложениями пула приложений. Он выполняет проверку подлинности пользователей, а затем направляет запросы в приложения.
| Имя объекта pod | Тип контроллера Kubernetes | Контейнеры |
|---|---|---|
appproxy |
ReplicaSet | - app-service-proxy- fluentbit |
Дополнительные сведения см. в разделе Общие сведения о развертывании приложения в Кластере больших данных.
Вы можете включать дополнительные объекты pod во время развертывания, в зависимости от рабочей нагрузки.
Служба шлюза
Службы шлюза предоставляют шлюз Knox для Spark, HDFS, Yarn, пользовательский интерфейс Yarn и пользовательский интерфейс Spark.
| Имя объекта pod | Тип контроллера Kubernetes | Контейнеры |
|---|---|---|
gateway-<#> |
StatefulSet | - knox- fluentbit |
Поддерживается только один шлюз.
Ссылки на контейнеры с открытым исходным кодом
Список проектов с открытым кодом и версий см. в статье Справочник по ПО с открытым кодом.
Дальнейшие действия
Дополнительные сведения о Кластеры больших данных SQL Server см. в следующих ресурсах.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по