Общие сведения о пуле носителей в Кластеры больших данных SQL Server
Область применения:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
В этой статье описывается роль пула носителей SQL Server в кластере больших данных SQL Server. В следующих разделах содержатся сведения об архитектуре и функциональных возможностях пула носителей.
Важно!
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, а программное обеспечение будет продолжать поддерживаться через SQL Server накопительных обновлений до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
Архитектура пула носителей
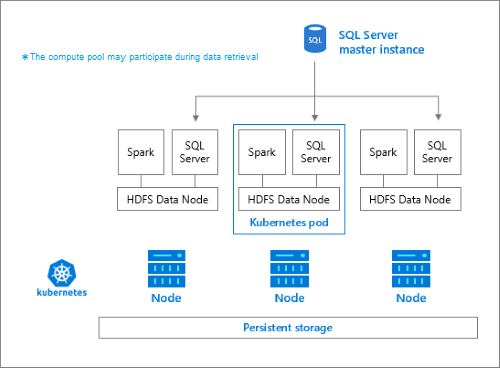
Пул носителей — это локальный кластер HDFS (Hadoop) в кластере больших данных SQL Server. Он предоставляет постоянное хранилище для неструктурированных и частично структурированных данных. Файлы данных, такие как Parquet или текст с разделителями, могут храниться в пуле носителей. Для постоянного хранения к каждому pod в пуле прикреплен постоянный том. Доступ к файлам пула носителей осуществляется через Polybase посредством SQL Server или напрямую с помощью шлюза Apache Knox.
Классическая конфигурация HDFS состоит из набора обычных компьютеров с подключенным хранилищем. Данные распределяются по блокам на узлах, что приводит к отказоустойчивости и возможности использования параллельной обработки. Один из узлов в кластере выступает в качестве узла имен и содержит метаданные о файлах, расположенных в узлах данных.

Пул носителей состоит из узлов хранилища, которые являются членами кластера HDFS. Он выполняет один или несколько pod Kubernetes для каждого pod, в котором размещаются следующие контейнеры:
- Контейнер Hadoop, связанный с постоянным томом (хранилищем). Все контейнеры этого типа вместе образуют кластер Hadoop. В контейнере Hadoop находится процесс диспетчера узлов YARN, который может создавать рабочие процессы Apache Spark по требованию. На головном узле Spark размещаются контейнеры хранилища метаданных Hive, журнала Spark и журнала заданий YARN.
- Экземпляр SQL Server для чтения данных из HDFS с использованием технологии OpenRowSet.
collectdдля сбора данных метрик.fluentbitдля сбора данных журналов.
Обязанности
Узлы хранилища предназначены для выполнения следующих задач:
- Прием данных через Apache Spark.
- Хранение данных в HDFS (Parquet и текстовый формат с разделителями). HDFS также обеспечивает сохраняемость данных, так как данные HDFS распределены по всем узлам хранения в BDC SQL.
- доступ к данным через конечные точки HDFS и SQL Server.
Доступ к данным
Ниже приведены основные методы доступа к данным в пуле носителей.
- Задания Spark.
- Использование внешних таблиц SQL Server для разрешения запросов данных с помощью вычислительных узлов PolyBase и экземпляров SQL Server, выполняющихся на узлах HDFS.
Взаимодействовать с HDFS можно также с помощью следующих средств.
- Azure Data Studio.
- Azure Data CLI (
azdata). - kubectl для отправки команд в контейнер Hadoop.
- Шлюз HTTP HDFS.
Дальнейшие действия
Дополнительные сведения о Кластеры больших данных SQL Server см. в следующих ресурсах.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по