Подключение к кластеру больших данных SQL Server с помощью Azure Data Studio
Область применения:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
В этой статье описывается, как подключиться к Кластеры больших данных SQL Server 2019 из Azure Data Studio.
Важно!
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, а программное обеспечение будет по-прежнему поддерживаться с помощью SQL Server накопительных обновлений до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
Предварительные требования
- Развернутый кластер больших данных SQL Server 2019.
- Средства для работы с большими данными SQL Server 2019
- Azure Data Studio
- Расширение SQL Server 2019
- kubectl
- azdata
Подключение к кластеру
Чтобы подключиться к кластеру больших данных с помощью Azure Data Studio, установите новое подключение к главному экземпляру SQL Server в кластере. Это делается так.
Найдите конечную точку главного экземпляра SQL Server:
azdata bdc endpoint list -e sql-server-masterСовет
Дополнительные сведения об извлечении конечных точек см. в разделе Извлечение конечных точек.
В Azure Data Studio нажмите F1>Создать подключение.
В разделе Тип подключения выберите Microsoft SQL Server.
Введите название конечной точки, которую вы нашли для главного экземпляра SQL Server, в текстовом поле Имя сервера (например: <IP_Address>,31433).
Выберите тип проверки подлинности. Для основного экземпляра SQL Server, выполняемого в кластере больших данных, поддерживаются только проверка подлинности Windows и вход с учетными данными SQL.
Если вы используете вход с учетными данными SQL, введите Имя пользователя и Пароль из этих данных.
Совет
По умолчанию имя пользователя SA отключено во время развертывания кластера больших данных. Новый пользователь sysadmin подготавливается во время развертывания; ему присваивается имя и пароль, соответствующие переменным среды AZDATA_USERNAME и AZDATA_PASSWORD, которые были заданы до или во время развертывания.
В поле Имя базы данных укажите в качестве целевой одну из ваших реляционных баз данных.
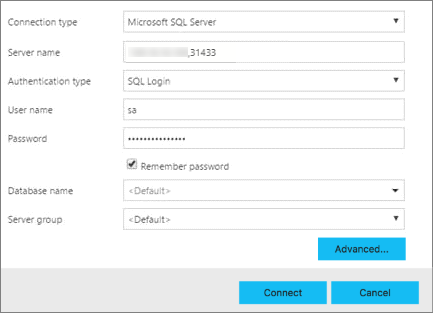
Нажмите Подключить. Откроется панель мониторинга сервера.
В выпуске Azure Data Studio, который вышел в феврале 2019 года, после установления подключения к главному экземпляру SQL Server вы также сможете работать с шлюзом HDFS/Spark. Это значит, что вам не потребуется отдельное подключение для HDFS и Spark, которое описывается в следующем разделе.
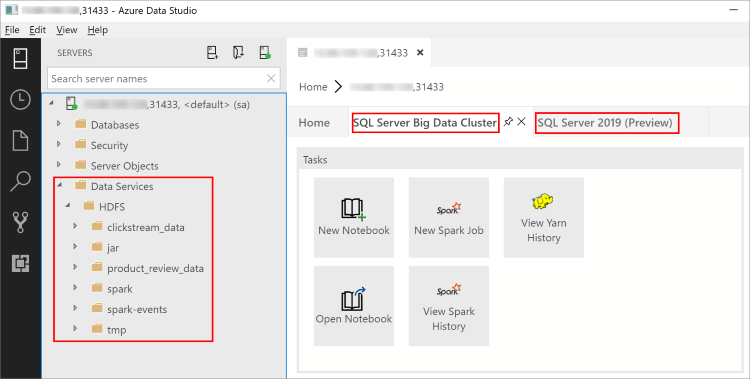
В обозревателе объектов появится новый узел Службы данных. В вызываемом с помощью правой кнопки мыши меню этого узла будут представлены задачи для работы с кластером больших данных, например для создания новых записных книжек или отправки заданий Spark.
Узел Службы данных также содержит папку HDFS, что позволяет изучать содержимое HDFS и выполнять стандартные задачи, затрагивающие HDFS (например, создание внешней таблицы или открытие записной книжки для анализа содержимого HDFS).
Если установлено расширение, панель мониторинга сервера для подключения также содержит вкладки Кластер больших данных SQL Server и SQL Server 2019.
Дальнейшие действия
Дополнительные сведения о Кластеры больших данных SQL Server 2019 см. в статье Что такое Кластеры больших данных SQL Server 2019.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по