Развертывание узла имен HDFS и общих служб Spark в конфигурации с высоким уровнем доступности
Область применения:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Важно!
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, а программное обеспечение будет продолжать поддерживаться через SQL Server накопительных обновлений до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
Помимо развертывания главного экземпляра SQL Server в конфигурации с высоким уровнем доступности с помощью групп доступности можно развернуть другие критически важные службы в кластере больших данных, чтобы обеспечить повышенный уровень надежности. Вы можете настроить HDFS name node и общие службы Spark, сгруппированные в sparkhead, с помощью дополнительной реплики. В этом случае Zookeeper также развертывается в кластере больших данных на сервере в качестве координатора кластера и хранилища метаданных для следующих служб:
- узла имен HDFS;
- Livy и Yarn Resource Manager.
Журнал Spark, журнал заданий и служба метаданных Hive — это службы без отслеживания состояния. Zookeeper не участвует в обеспечении работоспособности служб для этих компонентов.
Развертывание нескольких реплик для этих служб обеспечивает повышенную масштабируемость, надежность и балансировку рабочих нагрузок между доступными репликами.
Примечание
Следующие службы развертываются в виде контейнеров в pod sparkhead.
- Livy
- Yarn Resource Manager
- Журнал Spark
- Журнал заданий
- Служба метаданных Hive
На следующем рисунке показано развертывание Spark с высоким уровнем доступности в кластере больших данных SQL Server.
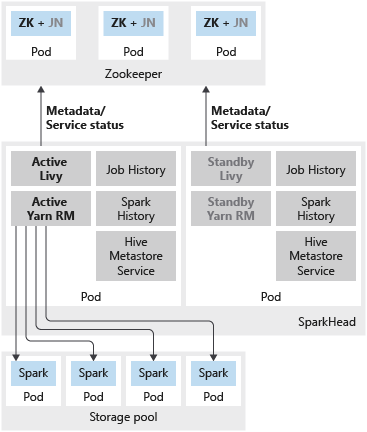
На следующем рисунке показано развертывание HDFS с высоким уровнем доступности в кластере больших данных SQL Server.

Развернуть
Если узел имен или SparkHead настроены с двумя репликами, необходимо также настроить ресурс Zookeeper с тремя репликами. В конфигурации с высоким уровнем доступности для узла имен HDFS две реплики размещаются в двух pod. Это pod nmnode-0 и pod nmnode-1. Это конфигурация "активный-пассивный". В каждый момент времени активен только один из узлов имен. Второй находится в режиме ожидания и становится активным в результате события отработки отказа.
Чтобы начать настройку развертывания кластера больших данных, можно использовать встроенные профили конфигурации aks-dev-test-ha или kubeadm-prod. Эти профили включают необходимые для ресурсов параметры, которые можно дополнительно настроить для высокого уровня доступности. Например, ниже приведен раздел файла конфигурации bdc.json, который относится к развертыванию узла имен HDFS, Zookeeper и общих ресурсов Spark (sparkhead) с высоким уровнем доступности.
{
...
"nmnode-0": {
"spec": {
"replicas": 2
}
},
"sparkhead": {
"spec": {
"replicas": 2
}
},
"zookeeper": {
"spec": {
"replicas": 3
}
},
...
}
В рабочем развертывании рекомендуется также задать значение 3 для репликации блоков HDFS. В профилях aks-dev-test-ha и kubeadm-prod этот параметр уже задан. См. ниже раздел из файла конфигурации bdc.json.
{
...
"hdfs": {
"resources": [
"nmnode-0",
"zookeeper",
"storage-0",
"sparkhead"
],
"settings": {
"hdfs-site.dfs.replication": "3"
}
},
...
}
Известные ограничения
Ниже перечислены известные проблемы и ограничения, связанные с настройкой высокого уровня доступности для служб Hadoop в Кластерах больших данных SQL Server.
- Все конфигурации должны быть заданы во время развертывания кластера больших данных. В выпуске SQL Server 2019 CU1 нельзя включить конфигурацию с высоким уровнем доступности после развертывания.
Дальнейшие действия
- Дополнительные сведения об использовании файлов конфигурации в развертываниях кластеров больших данных см. в статье Развертывание Кластеры больших данных SQL Server в Kubernetes.
- Дополнительные сведения о вариантах главного экземпляра SQL Server с высоким уровнем доступности в кластерах больших данных см. в разделе Развертывание главного экземпляра SQL Server с высоким уровнем доступности.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по