Отправка заданий Spark в кластере больших данных SQL Server в Visual Studio Code
Важно!
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, и программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений SQL Server до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
Вы можете узнать, как с помощью Spark & Hive Tools для Visual Studio Code создавать и отправлять скрипты PySpark для Apache Spark. Сначала мы расскажем, как установить Spark & Hive tools в Visual Studio Code, а затем рассмотрим, как отправлять задания в Spark.
Spark & Hive Tools можно установить на платформах, поддерживаемых Visual Studio Code, включая Windows, Linux и macOS. Ниже указаны необходимые условия для различных платформ.
Необходимые компоненты
Для выполнения действий, описанных в этой статье, необходимо следующее:
- Кластер больших данных SQL Server. См. Кластеры больших данных SQL Server.
- Visual Studio Code.
- Python и расширение Python в Visual Studio Code.
- Mono. Mono требуется только для Linux и macOS.
- Настройка интерактивной среды PySpark для Visual Studio Code.
- Локальный каталог SQLBDCexample. В этой статье используется C:\SQLBDC\SQLBDCexample.
Установка Spark & Hive Tools
После выполнения предварительных требований можно установить Spark & Hive Tools для Visual Studio Code. Для этого выполните следующие шаги:
Откройте Visual Studio Code.
В строке меню выберите Вид>Расширения.
В поле поиска введите Spark & Hive.
Выберите Spark & Hive Tools от Майкрософт в результатах поиска и щелкните Установить.

При необходимости выполните перезагрузку.
Открытие рабочей папки
Выполните следующие действия, чтобы открыть рабочую папку и создать файл в Visual Studio Code:
В строке меню выберите Файл>Открыть папку...>C:\SQLBDC\SQLBDCexample, а затем нажмите кнопку Выбрать папку. Папка отображается в представлении проводника слева.
В представлении проводника выберите эту папку, элемент SQLBDCexample и значок Новый файл рядом с рабочей папкой.
Присвойте новому файлу имя с расширением
.py(скрипт Spark). В этом примере используется HelloWorld.py.Скопируйте и вставьте в файл скрипта следующий код:
import sys from operator import add from pyspark.sql import SparkSession, Row spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() data = [Row(col1='pyspark and spark', col2=1), Row(col1='pyspark', col2=2), Row(col1='spark vs hadoop', col2=2), Row(col1='spark', col2=2), Row(col1='hadoop', col2=2)] df = spark.createDataFrame(data) lines = df.rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counters.collect() sortedCollection = sorted(output, key = lambda r: r[1], reverse = True) for (word, count) in sortedCollection: print("%s: %i" % (word, count))
Связывание кластера больших данных SQL Server
Прежде чем отправлять скрипты в кластеры из Visual Studio Code, нужно связать кластер больших данных SQL Server.
В строке меню выберите Вид>Палитра команд... и введите Spark / Hive: Link a Cluster.

Выберите тип связанного кластера SQL Server Big Data (Большие данные SQL Server).
Введите конечную точку больших данных SQL Server.
Введите имя пользователя кластера больших данных SQL Server.
Введите пароль для администратора пользователей.
Задайте отображаемое имя кластера больших данных (необязательно).
Выведите список кластеров и просмотрите представление OUTPUT для проверки.
список кластеров
В строке меню выберите Вид>Палитра команд... и введите Spark / Hive: List Cluster.
Просмотрите представление OUTPUT. В нем отображаются связанные кластеры.

Задание кластера по умолчанию
Снова откройте созданную ранее папку SQLBDCexample, если она была закрыта.
Выберите созданный ранее файл HelloWorld.py, чтобы открыть его в редакторе скриптов.
Свяжите кластер, если вы еще не сделали этого.
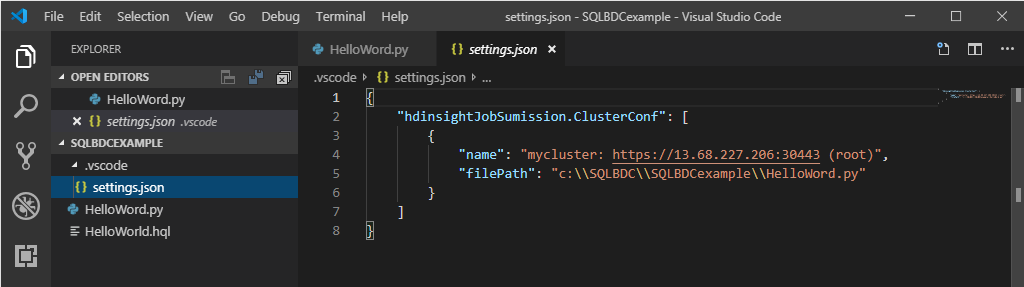
Щелкните редактор скриптов правой кнопкой мыши и выберите Spark / Hive: задать кластер по умолчанию.
Выберите кластер в качестве используемого по умолчанию для текущего файла скрипта. Средства автоматически обновляют файл конфигурации .VSCode\settings.json.
Отправка интерактивных запросов PySpark
Вы можете отправлять интерактивные запросы PySpark, выполнив следующие действия:
Снова откройте созданную ранее папку SQLBDCexample, если она была закрыта.
Выберите созданный ранее файл HelloWorld.py, чтобы открыть его в редакторе скриптов.
Свяжите кластер, если вы еще не сделали этого.
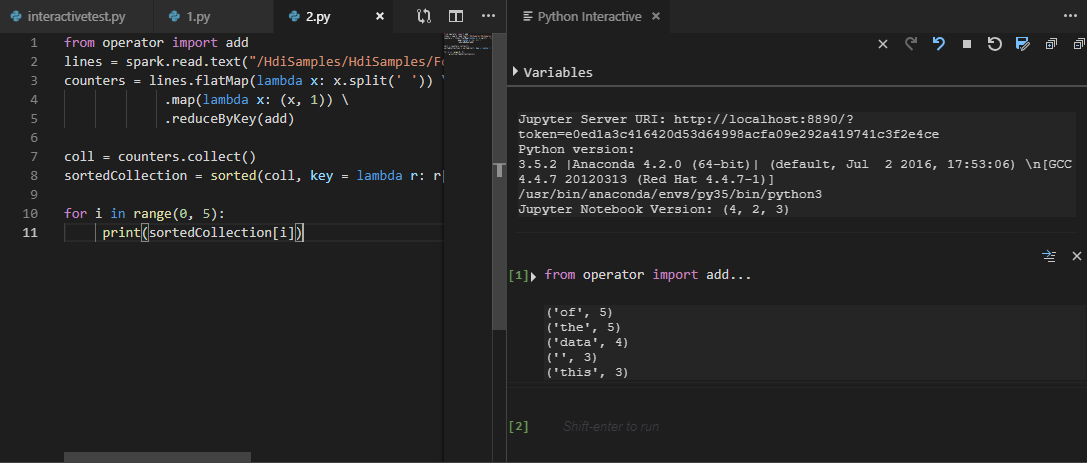
Выберите весь код и щелкните правой кнопкой мыши редактор скриптов, выберите Spark: PySpark Interactive, чтобы отправить запрос, или используйте сочетание клавиш CTRL+ALT+I.

Выберите кластер, если вы не указали кластер по умолчанию. Через несколько секунд результаты Python Interactive отобразятся на новой вкладке. Средства также позволяют отправить блок кода вместо всего файла скрипта с помощью контекстного меню.
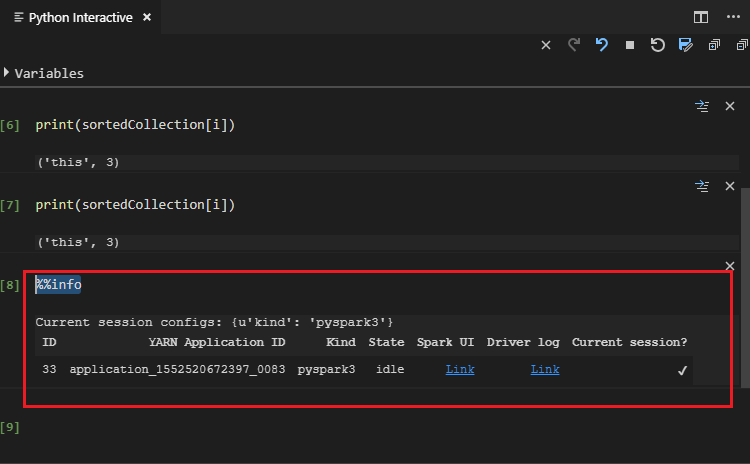
Введите "%%info" и нажмите клавиши SHIFT+ВВОД для просмотра сведений о задании. (Необязательно)
Примечание.
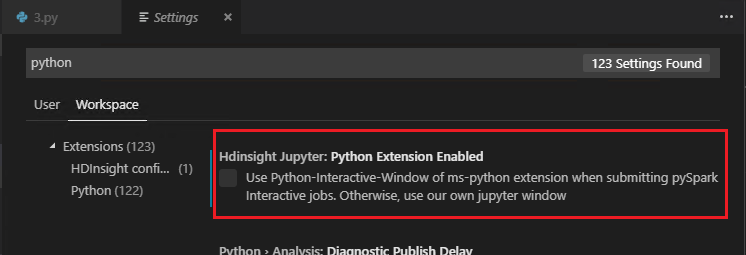
Если флажок Python Extension Enabled (Расширение Python включено) в параметрах снят (параметр по умолчанию установлен), отправленные результаты интерактивной среды pyspark будут использовать старое окно.
Отправка пакетного задания PySpark
Снова откройте созданную ранее папку SQLBDCexample, если она была закрыта.
Выберите созданный ранее файл HelloWorld.py, чтобы открыть его в редакторе скриптов.
Свяжите кластер, если вы еще не сделали этого.
Щелкните правой кнопкой мыши окно редактора скриптов, а затем выберите Spark: PySpark Batch или воспользуйтесь сочетанием клавиш CTRL+ALT+H.
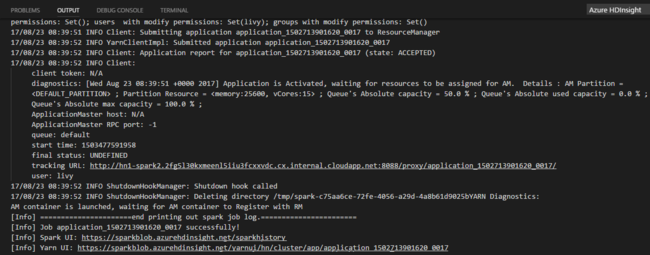
Выберите кластер, если вы не указали кластер по умолчанию. После отправки задания Python журналы отправки отображаются в окне вывода в Visual Studio Code. Также отображаются Spark UI URL (URL-адрес пользовательского интерфейса Spark) и Yarn UI URL (URL-адрес пользовательского интерфейса Yarn). Вы можете открыть этот URL-адрес в браузере для отслеживания состояния задания.
Конфигурация Apache Livy
Конфигурация Apache Livy поддерживается, и ее можно настроить в файле .VSCode\settings.json в папке рабочей области. Сейчас конфигурация Livy поддерживает только скрипт Python. Дополнительные сведения см. в файле сведений Livy.
Активация конфигурации Livy
Метод 1
- В строке меню выберите Файл>Настройки>Параметры.
- В текстовое поле Параметры поиска введите HDInsight Job Submission: Livy Conf.
- Выберите Изменить в settings.json для соответствующего результата поиска.
Метод 2.
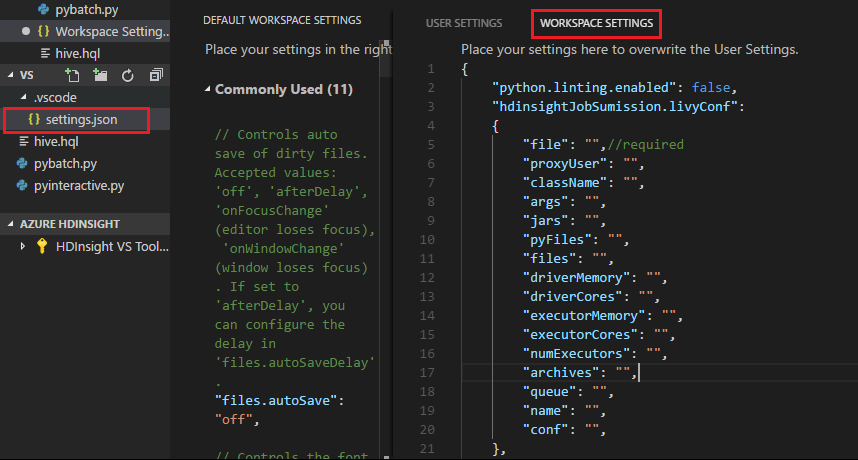
Отправьте файл и обратите внимание, что папка .vscode автоматически добавляется в рабочую папку. Чтобы найти конфигурацию Livy, щелкните settings.json в .vscode.
Параметры проекта:
Примечание.
Для параметров driverMemory и executorMemory задайте значение с единицей измерения, например 1gb или 1024mb.
Поддерживаемые конфигурации Livy
POST /batches
Текст запроса
| name | description | type |
|---|---|---|
| файл | Файл, содержащий приложение для выполнения | путь (обязательно) |
| proxyUser | Пользователь, олицетворяемый при выполнении задания | строка |
| className | Класс main приложения в Java/Spark | строка |
| args | Аргументы командной строки для приложения | список строк |
| jars | Файлы JAR для использования в этом сеансе | список строк |
| pyFiles | Файлы Python для использования в этом сеансе | список строк |
| files | Файлы для использования в этом сеансе | список строк |
| driverMemory | Объем памяти, используемый для процесса драйвера | строка |
| driverCores | Число ядер, используемых для процесса драйвера | INT |
| executorMemory | Объем памяти, используемый для каждого процесса исполнителя | строка |
| executorCores | Число ядер, используемых для каждого исполнителя | INT |
| numExecutors | Число исполнителей, которые должны быть запущены для этого сеанса | INT |
| archives | Архивы для использования в этом сеансе | список строк |
| очередь | Имя очереди YARN, куда выполнена отправка | строка |
| name | Имя сеанса | строка |
| conf | Свойства конфигурации Spark | Сопоставление key=val |
| :- | :- | :- |
Текст ответа
Созданный объект пакета.
| name | description | type |
|---|---|---|
| id | Идентификатор сеанса | INT |
| appId | Идентификатор приложения для этого сеанса | Строка |
| appInfo | Подробные сведения о приложении | Сопоставление key=val |
| Журнал | Строки журнала | список строк |
| state | Состояние пакета | строка |
| :- | :- | :- |
Примечание.
Назначенная конфигурация Livy будет отображена в области вывода при отправке скрипта.
Дополнительные функции
В Spark & Hive для Visual Studio Code поддерживаются следующие функции:
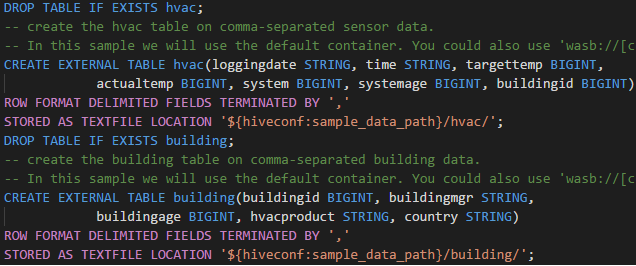
Автозавершение IntelliSense. Всплывающие предложения для ключевых слов, методов, переменных и пр. Разные значки представляют различные типы объектов.
Маркер ошибок IntelliSense. Языковая служба подчеркивает ошибки редактирования для скрипта Hive.
Выделение синтаксиса. Языковая служба использует разные цвета, чтобы вам было легче различать переменные, ключевые слова, типы данных, функции и пр.
Удаление связи кластера
В строке меню выберите Вид>Палитра команд и введите Spark / Hive: Unlink a Cluster.
Выберите кластер для удаления связи.
Просмотрите представление OUTPUT для проверки.
Следующие шаги
Дополнительные сведения о кластере больших данных SQL Server и связанных сценариях см. в Кластеры больших данных SQL Server.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по