Мониторинг производительности для групп доступности Always On
Применимо к:![]() SQL Server
SQL Server
Аспект производительности групп доступности AlwaysOn играет важную роль с точки зрения соблюдения соглашения об уровне обслуживания (SLA) для критически важных баз данных. Понимание того, как группы доступности поставляют журналы вторичным репликам, может помочь оценить цель времени восстановления (RTO) и целевую точку восстановления (RPO) для вашей реализации доступности, а также выявить узкие места в малоэффективных репликах группах доступности. Эта статья описывает процесс синхронизации, показывает, как вычислить некоторые основные метрики, а также содержит ссылки на некоторые распространенные сценарии по устранению неполадок с производительностью.
Процесс синхронизации данных
Чтобы оценить время полной синхронизации и выявить узкое место, вам нужно понять процесс синхронизации. Узкое место производительности может находиться в любом месте процесса, и его обнаружение может помочь вам лучше разобраться связанных с ним проблемах. Приведенные ниже рисунок и таблица иллюстрируют процесс синхронизации данных:

| Sequence | Описание шага | Комментарии | Полезные метрики |
|---|---|---|---|
| 1 | Создание журнала | Данные журнала записываются на диск. Этот журнал должен реплицироваться на вторичные реплики. Записи журнала попадают в очередь отправки. | SQL Server: база данных > освобождено байтов журнала в секунду |
| 2 | Capture | Журналы для каждой базы данных собираются и отправляются в соответствующую очередь партнера (по одной для каждой пары из базы данных и реплики). Этот процесс сбора выполняется непрерывно, пока реплика доступности подключена, а перемещение данных не приостановлено по какой-либо причине. При этом пара из базы данных и реплики отображается как выполняющая синхронизацию или синхронизированная. Если процессу сбора не удается достаточно быстро сканировать сообщения и ставить их в очередь, очередь отправки журнала разрастается. | SQL Server: реплика доступности > отправлено байт в реплику в секунду, что является агрегатом суммы всех сообщений баз данных, помещенных в очередь для этой реплики доступности. log_send_queue_size (КБ) и log_bytes_send_rate (КБ/с) на первичной реплике. |
| 3 | Отправить | Сообщения в каждой очереди базы данных и реплики удаляются из очереди и через проводную сеть передаются в соответствующую вторичную реплику. | SQL Server: реплика доступности > отправлено байт для транспортировки в секунду |
| 4 | Получение и кэширование | Каждая вторичная реплика получает и кэширует сообщение. | Счетчик производительности SQL Server: реплика доступности > Получено байт из журнала в секунду |
| 5 | Сохранение | Журнал записывается во вторичную реплику для сохранения. После записи журнала обратно в первичную реплику отправляется подтверждение. После сохранения журнала потеря данных исключается. |
Счетчик производительности SQL Server: база данных > освобождено байтов журнала в секунду Тип ожидания HADR_LOGCAPTURE_SYNC |
| 6 | Вернуть | Повторная обработка записанных страниц на вторичной реплике. Страницы хранятся в очереди повтора, так как ожидают повторной обработки. | SQL Server: реплика базы данных > повторено байтов в секунду redo_queue_size (КБ) и redo_rate. Тип ожидания REDO_SYNC |
Шлюзы управления потоком
Для групп доступности предусмотрены шлюзы управления потоком на первичной реплике, позволяющие предотвратить чрезмерное потребление ресурсов, например сетевых ресурсов и ресурсов памяти, на всех репликах доступности. Эти шлюзы управления потоком не влияют на состояние работоспособности синхронизации у реплик доступности, но могут повлиять на общую производительность баз данных доступности, включая RPO.
После записи журналов на основной реплика они подвергаются двум уровням элементов управления потоками. После достижения порога сообщений для любого из шлюзов сообщения журнала перестают отправляться в конкретную реплику или базу данных. Отправка сообщений возможна после получения подтверждений для отправленных сообщений, в результате чего число отправленных сообщений опускается ниже порогового значения.
Кроме шлюзов управления потоком существует и другой фактор, который может препятствовать отправке сообщений журнала. Синхронизация реплик гарантирует, что сообщения отправляются и применяются в порядке регистрационных номеров транзакции в журнале (LSN). Перед отправкой сообщения журнала его номер LSN также проверяются на соответствие наименьшему подтвержденному номеру LSN, чтобы убедиться, что он меньше одного из пороговых значений (в зависимости от типа сообщения). Если разрыв между двумя номерами LSN больше порогового значения, сообщения не отправляются. Когда разрыв меньше порогового значения, сообщения отправляются.
SQL Server 2022 увеличивает ограничения на количество сообщений, разрешенных каждым шлюзом. С помощью флага трассировки 12310 увеличенный предел также доступен для следующих версий SQL Server, начиная с: SQL Server 2019 CU9, SQL Server 2017 CU18 и SQL Server 2016 с пакетом обновления 1 (SP1) с накопительным пакетом обновления 16 (CU1).
В следующей таблице сравниваются ограничения сообщений:
SQL Server 2022 и поддерживаемые версии SQL Server (начиная с SQL Server 2019 CU9, SQL Server 2017 CU18 и SQL Server 2016 с пакетом обновления 1 (SP1) с накопительным пакетом обновления 16 (CU16), которые обеспечивают флаг трассировки 12310, см. следующие ограничения:
| Уровень | Количество шлюзов | Количество сообщений | Полезные метрики |
|---|---|---|---|
| Транспорт | 1 на реплику доступности | 16384 | Расширенное событие database_transport_flow_control_action |
| База данных | 1 на базу данных доступности | 7168 | DBMIRROR_SEND Расширенное событие hadron_database_flow_control_action |
Два полезных счетчика производительности — SQL Server: реплика доступности > поток управления в секунду и SQL Server: реплика доступности > время управления потоком (мс/с) — показывают, сколько раз активировалось управление потоком и сколько времени ушло на ожидание управления потоком за последнюю секунду. Повышенное время ожидания управления потоком приводит к завышению RPO. Дополнительные сведения о типах проблем, которые могут привести к высокому времени ожидания для управления потоком, см. в разделе Устранение неполадок: превышение RPO в группе доступности.
Оценка времени перехода на другой ресурс (RTO)
RTO в соглашении об уровне обслуживания зависит от времени перехода на другой ресурс для вашей реализации AlwaysOn в любой момент времени, что можно выразить следующей формулой:

Важно!
Если группа доступности содержит более одной базы данных доступности, то база данных доступности с наибольшим значением Tfailover становится ограничивающим фактором для соблюдения RTO.
Время обнаружения ошибки Tdetection — это время, необходимое системе для обнаружения сбоя. Это время зависит от параметров на уровне кластера, а не от отдельных реплик доступности. В зависимости от настроенного условия автоматического перехода на другой ресурс, переход можно запустить в качестве мгновенного ответа на критическую внутреннюю ошибку SQL Server, такую как потерянные спин-блокировки. В этом случае обнаружение может выполняться настолько же быстро, насколько отчет об ошибке sp_server_diagnostics (Transact-SQL) отправляется в кластер WSFC (интервал по умолчанию составляет 1/3 времени ожидания проверки работоспособности). Переход на другой ресурс также может запускаться из-за истечения времени ожидания, например при истечении времени ожидания для проверки работоспособности кластера (по умолчанию 30 секунд), или истечения срока аренды между библиотекой ресурсов и экземпляром SQL Server (по умолчанию 20 секунд). В этом случае время обнаружения равно времени ожидания. Дополнительные сведения см. в разделе о гибкой политике автоматического перехода на другой ресурс группы доступности (SQL Server).
Для готовности к переходу на другой ресурс вторичной реплике нужно только то, чтобы повтор дошел до конца журнала. Время повтора — Tredo — рассчитывается по следующей формуле:

где redo_queue — это значение в redo_queue_size, а redo_rate — это значение в redo_rate.
Дополнительные временные затраты при переходе на другой ресурс — Toverhead — включают время, необходимое для перехода кластера WSFC на другой ресурс и перевода базы данных в оперативный режим. Это время обычно короткое и постоянное.
Оценка возможной потери данных (RPO)
RTO в соглашении об уровне обслуживания зависит от возможной потери данных для вашей реализации AlwaysOn в любой момент времени. Эту возможную потерю данных можно выразить следующей формулой:

где log_send_queue — это значение log_send_queue_size, а скорость создания журнала — это значение SQL Server: база данных > сброшено байтов журнала в секунду.
Предупреждение
Если группа доступности содержит более одной базы данных доступности, то база данных доступности с наибольшим значением Tdata_loss становится ограничивающим фактором для соблюдения RPO.
Очередь отправки журнала представляет все данные, которые могут быть потеряны при неустранимом сбое. На первый взгляд, может показаться странным, что используется скорость создания журнала вместо скорости отправки журнала (см. log_send_rate). Однако не забывайте, что использование скорости отправки журнала дает вам лишь время для синхронизации, а RPO измеряет потерю данных с учетом скорости их создания или синхронизации.
Еще проще оценить Tdata_loss можно с помощью last_commit_time. Динамическое административное представление на первичной реплике сообщает это значение для всех реплик. Вы можете вычислить разницу между значением для первичной и вторичной реплик, чтобы оценить, как быстро журнал во вторичной реплике доходит до первичной реплики. Как уже говорилось ранее, этот расчет не показывает возможную потерю данных в зависимости от скорости создания журнала, однако он обеспечивает довольно точное приближение.
Оценка RTO и RPO с помощью панели мониторинга SSMS
В группах доступности AlwaysOn значение RTO и RPO вычисляется и отображается для баз данных, размещенных на вторичных репликах. На панели мониторинга первичной реплики RTO и RPO группируются по вторичной реплике.
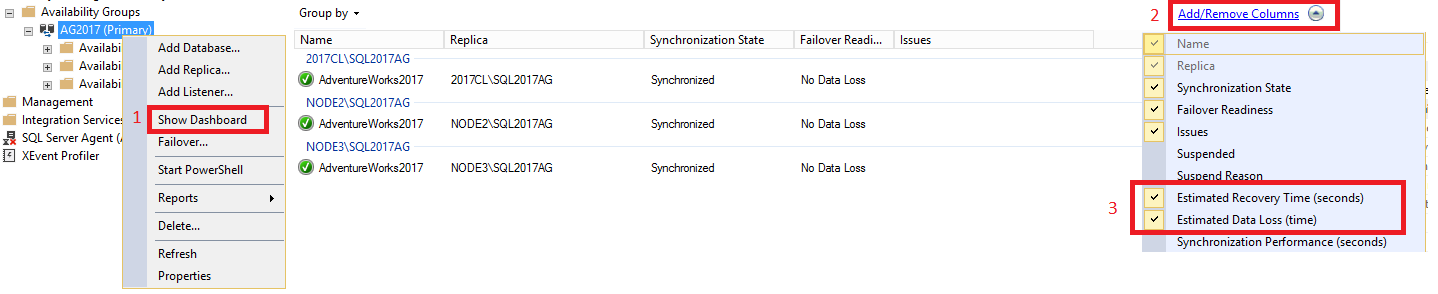
Чтобы просмотреть RTO и RPO в панели мониторинга, сделайте следующее.
В SQL Server Management Studio разверните узел Высокий уровень доступности AlwaysOn, щелкните правой кнопкой мыши имя группы доступности и выберите команду Показать панель мониторинга.
Выберите "Добавить и удалить столбцы" на вкладке "Группа" на вкладке. Проверьте как предполагаемое время восстановления (секунды) [RTO], так и предполагаемую потерю данных (время) [RPO].
Расчет RTO базы данных-получателя
Вычисление времени восстановления определяет, сколько времени требуется для восстановления базы данных-получателя после отработки отказа. Это время обычно короткое и постоянное. Время обнаружения зависит от параметров на уровне кластера, а не от отдельных реплик доступности.
У базы данных-получателя (DB_sec) вычисление и отображение RTO основаны на значениях redo_queue_size и redo_rate:
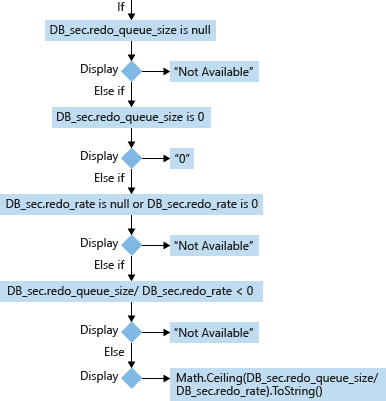
За исключением тупиковых ситуаций, формула для вычисления RTO базы данных-получателя такова:

Расчет RPO базы данных-получателя
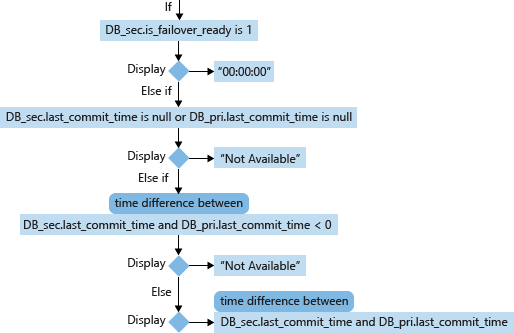
Для базы данных-получателя (DB_sec) вычисление и отображение RPO основаны на значениях is_failover_ready, last_commit_time и коррелированном значении last_commit_time ее базы данных-источника (DB_pri). Если в базе данных-получателе is_failover_ready = 1, то данные синхронизированы и потери данных при отработке отказа не происходит. Если же это значение равно 0, то есть разрыв между last_commit_time базы данных-источника и last_commit_time базы данных-получателя.
Для базы данных-источника last_commit_time — это время, когда зафиксирована последняя транзакция. Для базы данных-получателя last_commit_time — время последнего успешного закрепления фиксации транзакции базы данных-источника в базе данных-получателе. Это число должно быть одинаковым для обеих баз данных. Разрыв между этими двумя значениями — время, в течение которого незавершенные транзакции остаются незафиксированными в базе данных-получателе; они будут потеряны при отработке отказа.
Счетчики производительности, которые используются в формулах RTO и RPO
- redo_queue_size (КБ) [используется в RTO]: размер очереди повтора — это размер журнала транзакций между его last_received_lsn и last_redone_lsn. Значение last_received_lsn — это идентификатор блока журнала, указывающий точку, вплоть до которой все блоки журнала были получены вторичной репликой, на которой размещена эта база данных-получатель. Значение last_redone_lsn — это фактический регистрационный номер транзакции последней записи в журнале, повторенной в базе данных-получателе. Исходя из этих двух значений, можно найти идентификаторы начала блока журнала (last_received_lsn) и конечного блока журнала (last_redone_lsn). Расстояние между этими блоками журнала может указывать, какие блоки журнала транзакций еще не были выполнены повторно. Оно измеряется в КБ.
- redo_rate (КБ/с) [используется в RTO]: накапливаемое значение, указывающее на определенный период прошедшего времени, какой объем журнала транзакций (в КБ) был восстановлен в базе данных-получателе. Измеряется в КБ/с.
- last_commit_time (Datetime) [используется в RPO]: для базы данных-источника last_commit_time — это время, когда зафиксирована последняя транзакция. Для базы данных-получателя last_commit_time — время последнего успешного закрепления фиксации транзакции базы данных-источника в базе данных-получателе. Так как это значение на вторичной реплике должно быть синхронизировано с тем же значением на сервере-источнике, зазор между этими двумя значениями и есть оценка потери данных (RPO).
Оценка RTO и RPO с помощью динамических административных представлений
Существует возможность запроса динамических административных представлений sys.dm_hadr_database_replica_states и sys.dm_hadr_database_replica_cluster_states для оценки значений RPO и RTO базы данных. Ниже приведены запросы, которые создают хранимые процедуры, выполняющие обе эти задачи.
Примечание.
Создание и запуск хранимой процедуры для оценки RTO следует выполнять в первую очередь, так как значения, которые она создает, необходимы хранимой процедуре для оценки RPO.
Создание хранимой процедуры для оценки RTO
- На целевой вторичной реплике создайте хранимую процедуру proc_calculate_RTO. Если эта хранимая процедура уже существует, сначала удалите и заново создайте ее.
if object_id(N'proc_calculate_RTO', 'p') is not null
drop procedure proc_calculate_RTO
go
raiserror('creating procedure proc_calculate_RTO', 0,1) with nowait
go
--
-- name: proc_calculate_RTO
--
-- description: Calculate RTO of a secondary database.
--
-- parameters: @secondary_database_name nvarchar(max): name of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RTO
(
@secondary_database_name nvarchar(max)
)
as
begin
declare @db sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @redo_queue_size bigint
declare @redo_rate bigint
declare @replica_id uniqueidentifier
declare @group_database_id uniqueidentifier
declare @group_id uniqueidentifier
declare @RTO float
select
@is_primary_replica = dbr.is_primary_replica,
@is_failover_ready = dbcs.is_failover_ready,
@redo_queue_size = dbr.redo_queue_size,
@redo_rate = dbr.redo_rate,
@replica_id = dbr.replica_id,
@group_database_id = dbr.group_database_id,
@group_id = dbr.group_id
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbcs.database_name = @secondary_database_name
if @is_primary_replica is null or @is_failover_ready is null or @redo_queue_size is null or @replica_id is null or @group_database_id is null or @group_id is null
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else if @is_primary_replica = 1
begin
print 'You are visiting wrong replica';
return
end
if @redo_queue_size = 0
set @RTO = 0
else if @redo_rate is null or @redo_rate = 0
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else
set @RTO = CAST(@redo_queue_size AS float) / @redo_rate
print 'RTO of Database '+ @secondary_database_name +' is ' + convert(varchar, ceiling(@RTO))
print 'group_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_id)
print 'replica_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @replica_id)
print 'group_database_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_database_id)
end
- Выполните proc_calculate_RTO, указав имя целевой базы данных-получателя:
exec proc_calculate_RTO @secondary_database_name = N'DB_sec'
Выходные данные содержат значение RTO для целевой базы данных вторичной реплики. Сохраните group_id, replica_id, и group_database_id для использования в хранимой процедуре оценки RPO.
Пример выходных данных:
RTO базы данных DB_sec' — 0
group_id базы данных DB4 — F176DD65-C3EE-4240-BA23-EA615F965C9B
реплика_id базы данных DB4 — 405554F6-3FDC-4593-A650-2067F5FABFFD
group_database_id of Database DB4 is 39F7942F-7B5E-42C5-977D-02E7FFA6C392
Создание хранимой процедуры для оценки RPO
- На первичной реплике создайте хранимую процедуру proc_calculate_RPO. Если эта хранимая процедура уже существует, сначала удалите и заново создайте ее.
if object_id(N'proc_calculate_RPO', 'p') is not null
drop procedure proc_calculate_RPO
go
raiserror('creating procedure proc_calculate_RPO', 0,1) with nowait
go
--
-- name: proc_calculate_RPO
--
-- description: Calculate RPO of a secondary database.
--
-- parameters: @group_id uniqueidentifier: group_id of the secondary database.
-- @replica_id uniqueidentifier: replica_id of the secondary database.
-- @group_database_id uniqueidentifier: group_database_id of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RPO
(
@group_id uniqueidentifier,
@replica_id uniqueidentifier,
@group_database_id uniqueidentifier
)
as
begin
declare @db_name sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @is_local bit
declare @last_commit_time_sec datetime
declare @last_commit_time_pri datetime
declare @RPO nvarchar(max)
-- secondary database's last_commit_time
select
@db_name = dbcs.database_name,
@is_failover_ready = dbcs.is_failover_ready,
@last_commit_time_sec = dbr.last_commit_time
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.replica_id = @replica_id and dbr.group_database_id = @group_database_id
-- correlated primary database's last_commit_time
select
@last_commit_time_pri = dbr.last_commit_time,
@is_local = dbr.is_local
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.is_primary_replica = 1 and dbr.group_database_id = @group_database_id
if @is_local is null or @is_failover_ready is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
if @is_local = 0
begin
print 'You are visiting wrong replica'
return
end
if @is_failover_ready = 1
set @RPO = '00:00:00'
else if @last_commit_time_sec is null or @last_commit_time_pri is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
begin
if DATEDIFF(ss, @last_commit_time_sec, @last_commit_time_pri) < 0
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
set @RPO = CONVERT(varchar, DATEADD(ms, datediff(ss ,@last_commit_time_sec, @last_commit_time_pri) * 1000, 0), 114)
end
print 'RPO of database '+ @db_name +' is ' + @RPO
end
- Выполните proc_calculate_RPO, указав значения group_id, replica_id, и group_database_id целевой базы данных-получателя.
exec proc_calculate_RPO @group_id= 'F176DD65-C3EE-4240-BA23-EA615F965C9B',
@replica_id = '405554F6-3FDC-4593-A650-2067F5FABFFD',
@group_database_id = '39F7942F-7B5E-42C5-977D-02E7FFA6C392'
- Выходные данные содержат значение RPO для целевой базы данных вторичной реплики.
Отслеживание RTO и RPO
Этот раздел описывает, как отслеживать метрики RTO и RPO в группах доступности. Эта демонстрация аналогична приведенной в учебнике по графическому пользовательскому интерфейсу Модель работоспособности AlwaysOn, часть 2. Расширение модели работоспособности.
Элементы расчетов для времени перехода на другой ресурс и возможной потери данных, описанные в разделах Оценка времени перехода на другой ресурс (RTO) и Оценка возможной потери данных (RPO), удобно предоставлены в виде метрик производительности в аспекте управления политиками Состояние реплики базы данных (см. раздел Просмотр аспектов управления на основе политик в объекте SQL Server). Вы можете отслеживать эти две метрики по расписанию и получать оповещения, когда метрики превышают значения RTO и RPO.
Приведенные скрипты создают две системные политики, выполняемые по собственным расписаниям со следующими характеристиками:
Политика RTO, которая завершается со сбоем, если оценочное время перехода на другой ресурс превышает 10 минут (вычисляется каждые 5 минут).
Политика RPO, которая завершается со сбоем, если оценочная потеря данных превышает 1 час (вычисляется каждые 30 минут).
Две эти политики имеют идентичную конфигурацию на всех репликах доступности.
Политики оцениваются на всех серверах, но только в группах доступности, для которых локальная реплика доступности является первичной. Если локальная реплика доступности не является первичной, политики не оцениваются.
Ошибки политик отображаются на панели мониторинга AlwaysOn, открытой для первичной реплики.
Чтобы создать политики, выполните приведенные ниже инструкции на всех экземплярах сервера, входящих в группу доступности:
Запустите службу агента SQL Server, если она еще не запущена.
В SQL Server Management Studio в меню Сервис выберите пункт Параметры.
На вкладке SQL Server AlwaysOn выберите Включить определяемую пользователем политику AlwaysOn и нажмите кнопку ОК.
Этот параметр позволяет отобразить правильно настроенные пользовательские политики на панели мониторинга AlwaysOn.
Создайте условие управления на основе политик, используя следующие спецификации:
Имя:
RTOАспект: Состояние реплики базы данных
Поле:
Add(@EstimatedRecoveryTime, 60)Оператор: <=
Значение:
600
Это условие не выполняется, когда потенциальное время для перехода на другой ресурс превышает 10 минут, включая дополнительные 60 секунд для обнаружения сбоя и перехода на другой ресурс.
Создайте второе условие управления на основе политик, используя следующие спецификации:
Имя:
RPOАспект: Состояние реплики базы данных
Поле:
@EstimatedDataLossОператор: <=
Значение:
3600
Это условие не выполняется, когда потенциальная потеря данных превышает 1 час.
Создайте третье условие управления на основе политик, используя следующие спецификации:
Имя:
IsPrimaryReplicaАспект: Группа доступности
Поле:
@LocalReplicaRoleОператор: =
Значение:
Primary
Это условие проверяет, является ли локальная реплика доступности первичной для данной группы доступности.
Создайте политику управления на основе политик, используя следующие спецификации:
Страница Общие:
Имя:
CustomSecondaryDatabaseRTOПроверка условия:
RTOПрименить к: каждый DatabaseReplicaState в IsPrimaryReplica AvailabilityGroup
Этот параметр обеспечивает, что политика оценивается только в группах доступности, для которых локальная реплика доступности является первичной.
Режим оценки: По расписанию
Расписание: CollectorSchedule_Every_5min
Включено: выбрано
Страница Описание:
Категория: Предупреждения базы данных доступности
Этот параметр позволяет отобразить результаты оценки политики на панели мониторинга AlwaysOn.
Описание. Текущий реплика имеет RTO, превышающий 10 минут, при условии, что затраты на обнаружение и отработку отказа занимает 1 минуту. Необходимо немедленно изучить проблемы с производительностью на соответствующем экземпляре сервера.
Отображаемый текст: Превышено значение RTO.
Создайте вторую политику управления на основе политик, используя следующие спецификации:
Страница Общие:
Имя:
CustomAvailabilityDatabaseRPOПроверка условия:
RPOПрименить к: каждый DatabaseReplicaState в IsPrimaryReplica AvailabilityGroup
Режим оценки: По расписанию
Расписание: CollectorSchedule_Every_30min
Включено: выбрано
Страница Описание:
Категория: Предупреждения базы данных доступности
Описание. База данных доступности превысила RPO в 1 час. Необходимо немедленно изучить проблемы с производительностью в реплика доступности.
Отображаемый текст: Превышено значение RPO.
Когда вы закончите, создаются два задания агента SQL Server — по одному для каждого расписания оценки политики. Эти задания должны иметь имена, начинающиеся с syspolicy_check_schedule.
Вы можете просмотреть журнал заданий, чтобы изучить результаты оценки. Ошибки оценки также заносятся в журнал приложений Windows (в средстве просмотра событий) с кодом события 34052. Можно также настроить агент SQL Server для отправки предупреждений о сбоях политик. Дополнительные сведения см. в разделе Настройка предупреждений для администраторов политик о сбоях политики.
Сценарии устранения неполадок с производительностью
Ниже перечислены распространенные сценарии устранения неполадок, связанные с производительностью.
| Сценарий | Description |
|---|---|
| Устранение неполадок: превышение RTO в группе доступности | После автоматического перехода на другой ресурс или планового перехода на другой ресурс вручную без потери данных время перехода на другой ресурс превышает цель времени восстановления (RTO). Или при оценке времени перехода на другой ресурс для вторичной реплики с синхронной фиксацией (например, партнера по обеспечению автоматической отработки отказа) вы обнаруживаете, что оно превышает RTO. |
| Устранение неполадок: превышение RPO в группе доступности | После принудительного перехода на другой ресурс вручную потеря данных превышает RPO. Или при расчете возможной потери данных для вторичной реплики с асинхронной фиксацией вы обнаруживаете, что она превышает RPO. |
| Устранение неполадок: изменения в первичной реплике не отражены во вторичной | Клиентское приложение успешно изменяет первичную реплику, но запрос вторичной реплики показывает, что это изменение не отражено. |
Полезные расширенные события
Приведенные ниже расширенные события полезны при устранении неполадок с репликами в состоянии Синхронизируется.
| Имя события | Категория | Канал | Реплика доступности |
|---|---|---|---|
| redo_caught_up | транзакции; | Отладка | Вторичные |
| redo_worker_entry | транзакции; | Отладка | Вторичные |
| hadr_transport_dump_message | alwayson |
Отладка | Основной |
| hadr_worker_pool_task | alwayson |
Отладка | Основной |
| hadr_dump_primary_progress | alwayson |
Отладка | Основной |
| hadr_dump_log_progress | alwayson |
Отладка | Основной |
| hadr_undo_of_redo_log_scan | alwayson |
Аналитический | Вторичные |
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по