Установка и включение дедупликации данных
Область применения: Windows Server 2022, Windows Server 2019, Windows Server 2016, Azure Stack HCI, версии 21H2 и 20H2
В этой статье описано, как установить дедупликацию данных, оценить рабочие нагрузки для дедупликации, а также включить дедупликацию данных для отдельных томов.
Примечание.
Если вы планируете запустить дедупликацию данных в отказоустойчивом кластере, каждый узел в кластере должен иметь роль сервера дедупликации данных.
Установка дедупликации данных
Внимание
КБ 4025334 содержит свод исправлений для дедупликации данных, включая важные исправления надежности, и настоятельно рекомендуется установить его при использовании дедупликации данных с Windows Server 2016.
Установка дедупликации данных с помощью диспетчера сервера
- В мастере добавления ролей и компонентов выберите Роли сервера, а затем Дедупликация данных.
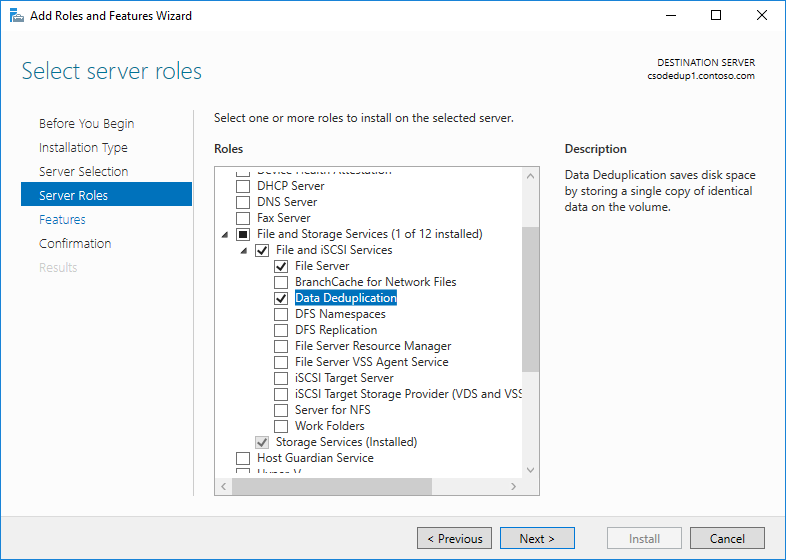
- Нажимайте кнопку Далее , пока не будет активирована кнопка Установить , а затем щелкните Установить.
Установка дедупликации данных с помощью PowerShell
Чтобы установить дедупликацию данных, выполните следующую команду PowerShell от имени администратора: Install-WindowsFeature -Name FS-Data-Deduplication
Чтобы установить дедупликацию данных, выполните приведенные действия.
На сервере под управлением Windows Server 2016 или более поздней версии или на компьютере с Windows с установленными средствами удаленного управления Администратор istration Tools (RSAT) установите дедупликацию данных с явной ссылкой на имя сервера (замените MyServer реальным именем экземпляра сервера):
Install-WindowsFeature -ComputerName <MyServer> -Name FS-Data-DeduplicationOr
Подключение удаленно к экземпляру сервера с помощью удаленного взаимодействия PowerShell и установки дедупликации данных с помощью DISM:
Enter-PSSession -ComputerName MyServer dism /online /enable-feature /featurename:dedup-core /all
Включение дедупликации данных
Определение рабочих нагрузок для дедупликации
Дедупликация данных может очень эффективно снизить затраты, связанные с потреблением данных серверного приложения, уменьшая объем, занимаемый избыточными данными на дисках. Прежде чем включать дедупликацию, очень важно определить характеристики рабочей нагрузки. Это позволит добиться максимальной производительности хранилища. Существует два класса рабочих нагрузок, для которых стоит применять дедупликацию.
- Рекомендуемые рабочие нагрузки — используют наборы данных, для которых дедупликация крайне эффективна. Такие нагрузки также используют схемы потребления ресурсов, которые совместимы с моделью постобработки, применяемой при дедупликации данных. Мы рекомендуем всегда включить дедупликацию данных для этих рабочих нагрузок:
- файловые серверы общего назначения (GPFS) с такими общими ресурсами, как общие групповые папки, домашние папки пользователей, рабочие папки и общие ресурсы для разработки программного обеспечения;
- серверы инфраструктуры виртуальных рабочих столов (VDI);
- виртуализированные приложения резервного копирования, например Microsoft Data Protection Manager (DPM).
- Рабочие нагрузки, для которых дедупликация может дать преимущества, но только при соблюдении некоторых условий. Например, следующие рабочие нагрузки могут работать хорошо с дедупликацией, но сначала следует оценить преимущества дедупликации:
- узлы Hyper-V общего назначения;
- Серверы SQL
- производственные серверы.
Оценка дедупликации данных для рабочих нагрузок
Внимание
Если вы используете рекомендуемые рабочие нагрузки, можно пропустить этот раздел и сразу включить дедупликацию данных.
Чтобы определить, применимость дедупликации для рабочей нагрузки, ответьте на следующие вопросы. Если вы не уверены в характеристиках рабочей нагрузки, можно выполнить пилотное развертывание дедупликации данных на тестовом наборе данных этой рабочей нагрузки.
Есть ли в наборе данных рабочей нагрузки достаточный объем дублирующихся данных, чтобы включение дедупликации дало ощутимый эффект? Прежде чем включать дедупликацию данных для рабочей нагрузки, оцените объем дублирующихся данных в наборе данных, используя средство оценки экономии от дедупликации данных (DDPEval). После установки дедупликации данных это средство можно найти здесь:
C:\Windows\System32\DDPEval.exe. DDPEval поможет вам оценить потенциальный эффект оптимизации для непосредственно подключенных томов (включая локальные диски или общие тома кластера), а также для сопоставленных или несопоставленных сетевых папок.При выполнении DDPEval.exe вы получите выходные данные следующего вида:
Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:\Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0Какие сценарии ввода-вывода использует рабочая нагрузка? Какая производительность у этой рабочей нагрузки? Дедупликация данных оптимизирует файлы, выполняя периодическое задание, а не во время сохранения файла на диск. В связи с этим сначала следует оценить ожидаемые шаблоны рабочей нагрузки на чтение из дедуплицированного тома. Поскольку дедупликация данных перемещает содержимое файла в хранилище блоков и пытается как можно плотнее заполнять его файлами, более эффективно будут выполняться операции чтения из последовательных диапазонов файла.
Рабочие нагрузки баз данных обычно имеют более случайный характер операций чтения, так как база данных не гарантирует оптимальную структуру данных для всех возможных выполняемых запросов. Данные из одного раздела хранилища блоков могут располагаться в разных частях тома, поэтому обращение к хранилищу данных может приводить к дополнительным задержкам. Высокопроизводительные рабочие нагрузки особенно чувствительны к таким задержкам, но это справедливо не для всех баз данных.
Примечание.
Эти проблемы особенно важны для рабочих нагрузок, которые хранят данные на томах, состоящих из традиционных носителей с вращающимися дисками (жесткие диски или HDD). Любая инфраструктура флэш-памяти (твердотельные накопители или SSD) менее подвержена проблемам случайных операций ввода-вывода, так как флэш-память обеспечивает одинаковое время доступа ко всем расположениям на носителе. Таким образом, дедупликация будет сопряжена с разной величиной задержки при операциях чтения в зависимости от того, где хранятся наборы данных рабочей нагрузки: на носителях на основе флэш-памяти или на традиционных вращающихся дисках.
Какие требования к ресурсам сервера предъявляет рабочая нагрузка? Так как дедупликация данных использует модель постобработки, она предполагает периодическое выделение значительных системных ресурсов для выполнения оптимизации и других заданий. Это означает, что рабочие нагрузки с определенными периодами простоя (например, в вечернее время или выходные дни) прекрасно подходят для дедупликации, в отличие от рабочих нагрузок, выполняемых круглосуточно изо дня в день. Но при этом дедупликацию можно успешно применить и для рабочих нагрузок без периодов простоя, если такие нагрузки не имеют высоких требований к ресурсам сервера.
Включение дедупликации данных
Перед включением дедупликации данных следует выбрать тип использования, который соответствует вашей рабочей нагрузке. Существует три типа использования для дедупликации данных:
- По умолчанию — оптимальные настройки для файлового сервера общего назначения.
- Hyper-V — настройки специально для серверов VDI.
- Резервное копирование — оптимальные настройки для виртуализированных приложений резервного копирования, таких как Microsoft DPM.
Включение дедупликации данных с помощью диспетчера сервера
- Выберите Файловые службы и службы хранения в диспетчере серверов.
- Во всплывающем меню Файловые службы и службы хранилища выберите Тома.
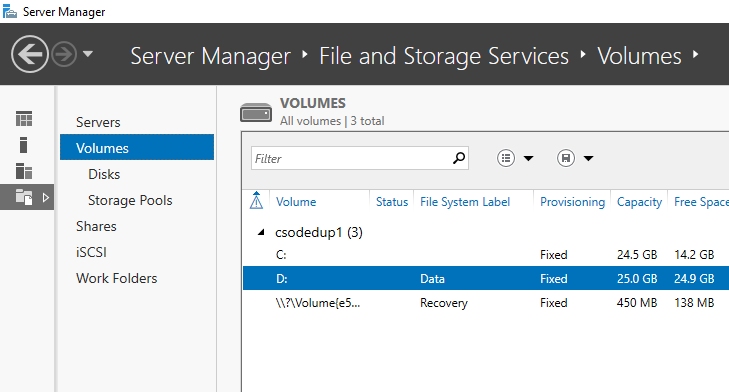
- Щелкните правой кнопкой мыши нужный том и выберите пункт Настройка дедупликации данных.

- Выберите в раскрывающемся списке нужный тип использования и нажмите ОК.
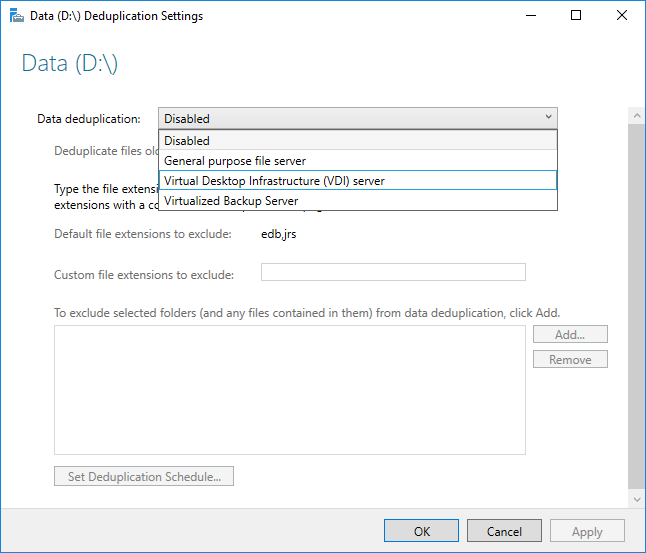
- Если вы используете рекомендуемую рабочую нагрузку, на этом процесс окончен. Для других рабочих нагрузок изучите раздел Дополнительные вопросы.
Примечание.
Дополнительные сведения об исключении определенных расширений файлов или папок, а также о создании расписания дедупликации (включая описание причин этих изменений), см. на странице Настройка дедупликации данных.
Включение дедупликации данных с помощью PowerShell
Выполните следующую команду PowerShell с правами администратора:
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Selected-Usage-Type>Если вы используете рекомендуемую рабочую нагрузку, на этом процесс окончен. Для других рабочих нагрузок изучите раздел Дополнительные вопросы.
Примечание.
Командлеты PowerShell для дедупликации данных, включая Enable-DedupVolume, можно запустить удаленно, добавив параметр -CimSession с сеансом CIM. Это особенно полезно для удаленного выполнения командлетов PowerShell дедупликации данных для экземпляра сервера. Для создания нового сеанса CIM запустите New-CimSession.
Другие вопросы
Внимание
Если ваша рабочая нагрузка относится к категории рекомендуемых, этот раздел можно пропустить.
- Типы использования, доступные при дедупликации данных, предусматривают практические стандартные значения для рекомендуемых рабочих нагрузок, а также используются в качестве отправной точки для остальных рабочих нагрузок. Для рабочих нагрузок, не входящих в категорию рекомендуемых, вы можете изменить дополнительные параметры дедупликации данных, чтобы повысить ее эффективность.
- Если рабочая нагрузка характеризуется высокими требованиями к ресурсам сервера, задания дедупликации данных следует запланировать на период ожидаемого простоя рабочей нагрузки. Это особенно важно, если дедупликация выполняется на гиперконвергированном узле, ведь в рабочее время процессы дедупликации могут истощить ресурсы виртуальных машин.
- Если рабочая нагрузка не особо требовательна к ресурсам или быстрое выполнение заданий оптимизации важнее, чем обслуживание запросов рабочей нагрузки, вы можете настроить параметры выделения памяти, ЦП и приоритета для заданий дедупликации.
Вопросы и ответы
Я хочу выполнить дедупликацию данных в наборе данных для определенной рабочей нагрузки. Это возможно? Мы полностью гарантируем целостность данных при применении дедупликации данных с любой рабочей нагрузкой, кроме включенных в список несовместимых с дедупликацией. Для рекомендуемых рабочих нагрузок корпорация Майкрософт также гарантирует повышение производительности. Производительность других рабочих нагрузок в значительной мере зависит от того, какие действия они выполняют на сервере. Необходимо определить, каким образом дедупликация данных повлияла на вашу рабочую нагрузку и допустимо ли такое влияние для этой нагрузки.
Каковы требования к размеру тома для дедуплицированных томов? В Windows Server 2012 и Windows Server 2012 R2 размер тома следует выбирать осторожно, чтобы дедупликация данных выполнялась в соответствии со скоростью обновления данных в томе. В большинстве случаев максимальный размер дедуплицированного тома для рабочей нагрузки с высокой скоростью обновления данных составляет 1–2 ТБ. Мы рекомендуем в любом случае не превышать размер 10 ТБ. Эти ограничения устранены в Windows Server 2016. Дополнительные сведения см. в статье Новые возможности функции дедупликации данных.
Стоит ли изменять расписание или другие параметры дедупликации данных для рекомендуемых рабочих нагрузок? Нет. Предлагаемые типы использования предусматривают рациональные стандартные значения для всех рекомендуемых рабочих нагрузок.
Каковы требования к памяти для дедупликации данных?
При дедупликации данных следует выделить по меньшей мере 300 МБ, а также дополнительно 50 МБ на каждый терабайт логических данных. Например, если вы оптимизируете том размером 10 ТБ, для дедупликации следует выделить не менее 800 МБ памяти (300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB). Дедупликация данных может выполняться и с меньшим объемом памяти, но такое ограничение ресурсов замедлит выполнение заданий этой функции.
Лучше всего, если для дедупликации данных будет выделено по 1 ГБ памяти на каждый 1 ТБ логических данных. Например, если вы оптимизируете том размером 10 ТБ, оптимальный объем памяти для дедупликации составит 10 ГБ (1 GB * 10). Такое соотношение обеспечит максимальную производительность для заданий дедупликации данных.
Каковы требования к объему хранилища для дедупликации данных? В Windows Server 2016 дедупликация данных может поддерживать тома размером до 64 ТБ. Дополнительные сведения см. в статье What's new in Data Deduplication (Новые возможности функции дедупликации данных).