Automatické agregácie
Automatické agregácie využívajú najmodernejšie strojové učenie (ML) na nepretržitú optimalizáciu sémantických modelov DirectQuery s cieľom dosiahnuť maximálny výkon dotazov na zostavu. Automatické agregácie sú vytvorené na základe infraštruktúry existujúcich agregácií definovaných používateľom, ktorá sa najprv zaviedla so zloženými modelmi pre službu Power BI. Na rozdiel od používateľom definovaných agregácií automatické agregácie na konfiguráciu a údržbu nevyžadujú rozsiahle modelovanie údajov a optimalizáciu dotazov. Automatické agregácie predstavujú samotrénovanie aj samo optimalizáciu. Umožňujú vlastníkom modelov ľubovoľnej úrovne zručností zlepšiť výkon dotazov a poskytovať rýchlejšie vizualizácie zostáv pre veľké modely.
S automatickými agregáciami:
- Vizualizácie zostáv sú rýchlejšie – Optimálne percento dotazov zostavy vracia automaticky udržiavaná vyrovnávacia pamäť agregácií v pamäti namiesto serverových systémov zdroja údajov. Dotazy odchýlok, ktoré vyrovnávacia pamäť v pamäti nevráti, sa odovzdávajú priamo do zdroja údajov pomocou režimu DirectQuery.
- Vyvážená architektúra – v porovnaní s čistým režimom DirectQuery vráti väčšina výsledkov dotazov nástroja dotazu Power BI a vyrovnávacej pamäte agregácií v pamäti. Zaťaženie spracovania dotazov v systémoch zdrojov údajov v špičke možno výrazne znížiť, čo znamená zvýšenú škálovateľnosť v serverovom servere zdroja údajov.
- Jednoduché nastavenie – vlastníci modelov môžu povoliť automatické trénovanie agregácií a naplánovať jedno alebo viacero obnovení modelu. S prvým trénovaním a obnovením začínajú automatické agregácie vytvárať architektúru agregácií a optimálne agregácie. Systém automaticky ladí sám v priebehu času.
- Doladenie – s jednoduchým a intuitívnym používateľským rozhraním v nastaveniach modelu môžete odhadnúť zisky z výkonu za iné percento dotazov vrátených z vyrovnávacej pamäte agregácií v pamäti a vykonať úpravy, aby ste dosiahli ešte väčšie zisky. Ovládací prvok jedného panela s jazdcom vám pomôže jednoducho vyladiť prostredie.
Požiadavky
Podporované plány
Automatické agregácie sú podporované pre službu Power BI Premium na kapacitu, Premium na používateľa a modely služby Power BI Embedded.
Podporované zdroje údajov
Automatické agregácie sú podporované v týchto zdrojoch údajov:
- Databáza Azure SQL
- Fond Azure Synapse Dedicated SQL
- SQL Server 2019 alebo novšia verzia
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
Podporované režimy
Automatické agregácie sú podporované pre modely v režime DirectQuery. Modely zloženého modelu s tabuľkami importu aj pripojeniami DirectQuery sú podporované. Automatické agregácie sú podporované len pre pripojenie DirectQuery.
Povolenia
Ak chcete povoliť a nakonfigurovať automatické agregácie, musíte byť vlastníkom modelu. Správcovia pracovného priestoru môžu ako vlastník nakonfigurovať nastavenia automatických agregácií.
Konfigurácia automatických agregácií
Automatické agregácie sú nakonfigurované v modeli Nastavenia. Konfigurácia je jednoduchá – povoľte školenie automatických agregácií a naplánujte si jedno alebo viacero obnovení. Pred konfiguráciou automatických agregácií pre svoj model si nezabudnite v plnom rozsahu prečítať tento článok. Vďaka tomu dobre rozumiete tomu, ako automatické agregácie fungujú, a dokáže vám pomôcť pri rozhodovaní, či sú automatické agregácie pre vaše prostredie vhodné. Ak ste pripravení na podrobné pokyny na povolenie automatického trénovania agregácií, konfiguráciu plánu obnovenia a doladenie vášho prostredia, pozrite si tému Konfigurácia automatických agregácií.
Výhody
V režime DirectQuery sa vždy, keď používateľ modelu otvorí zostavu alebo interaguje s vizualizáciou zostavy, dotazy DAX (Data Analysis Expressions) sa odovzdajú do nástroja dotazov a potom do serverového zdroja údajov ako dotazy SQL. Zdroj údajov musí vypočítať a vrátiť výsledky pre každý dotaz. V porovnaní s modelmi režimu importu uloženými v pamäti môže byť proces zaokrúhľovania zdroja údajov DirectQuery náročný na čas aj proces, čo často spôsobuje pomalé časy odozvy dotazu vo vizualizáciách zostavy.
Keď je táto možnosť povolená pre model DirectQuery, automatické agregácie môžu zvýšiť výkon dotazu zostavy tak, že sa vyhnete zaokrúhleniu dotazu zdroja údajov. Vopred agregované výsledky dotazu sa automaticky vrátia vyrovnávacou pamäťou agregácií v pamäti, namiesto toho, aby ich zdroj údajov poslal a vrátil. Množstvo vopred agregovaných údajov vo vyrovnávacej pamäti agregácií v pamäti je len malou časťou množstva údajov uložených v skutočnosti a tabuliek s podrobnosťami v zdroji údajov. Výsledkom nie je len lepší výkon dotazu na zostavu, ale aj znížené zaťaženie serverových systémov zdrojov údajov. V prípade automatických agregácií sa do serverového zdroja údajov odovzdáva len malá časť zostáv a ad hoc dotazov, ktoré vyžadujú agregácie, ktoré nie sú zahrnuté vo vyrovnávacej pamäti, do serverového zdroja údajov, rovnako ako v prípade čistého režimu DirectQuery.
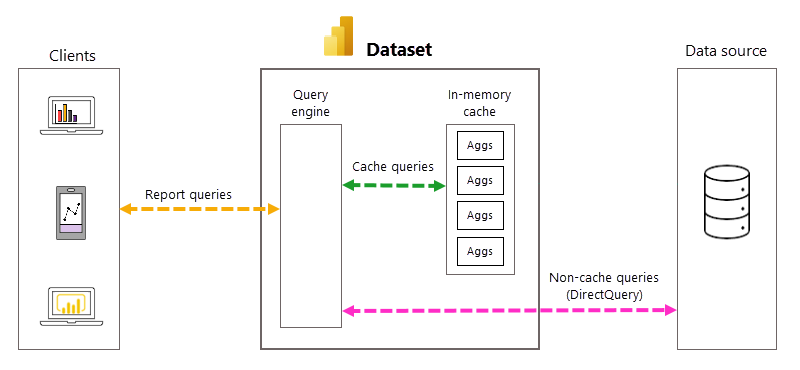
Spravovanie automatických dotazov a agregácií
Hoci automatické agregácie eliminujú potrebu vytvárať používateľom definované agregačné tabuľky a výrazne zjednodušujú implementáciu vopred agregovaného riešenia údajov, hlbšia znalosť základných procesov a závislostí je užitočná pre pochopenie fungovania automatických agregácií. Pri vytváraní a spravovaní automatických agregácií využíva Power BI nasledujúce funkcie.
Denník dotazov
Služba Power BI sleduje dotazy modelov a zostáv používateľov v denníku dotazov. Power BI spravuje sedem dní údajov denníka dotazov pre každý model. Údaje denníka dotazov sa každý deň posúvajú dopredu. Denník dotazov je zabezpečený a nezobrazuje sa používateľom ani cez koncový bod XMLA.
Operácie trénovaia
V rámci prvej operácie plánovaného obnovenia modelu pre vybratú frekvenciu (deň alebo týždeň) služba Power BI najskôr spustí operáciu trénovania, ktorá vyhodnotí denník dotazu a zabezpečí, aby sa agregácie vo vyrovnávacej pamäti agregácií vo vyrovnávacej pamäti prispôsobili meniacim sa vzorom dotazu. V pamäti agregačné tabuľky sa vytvárajú, aktualizujú alebo vynechajú a do zdroja údajov sa odosielajú špeciálne dotazy na určenie agregácií, ktoré sa majú zahrnúť do vyrovnávacej pamäte. Vypočítané údaje agregácií sa však do vyrovnávacej pamäte v pamäti nenačítajú počas trénovania – načítajú sa počas nasledujúcej operácie obnovenia.
Ak napríklad vyberiete frekvenciu dňa a plánované obnovenia o 4:00, 9:00, 14:00 a 19:00, bude každé obnovenie zahŕňať len operáciu trénovania a operáciu obnovenia. Následné plánované obnovenia o 9:00, 14:00 a 19:00 pre daný deň sú operácie obnovenia, ktoré aktualizujú existujúce agregácie vo vyrovnávacej pamäti.

Hoci operácie trénovania vyhodnocujú minulé dotazy z denníka dotazu, výsledky sú dostatočne presné, aby sa zabezpečilo, že sa pokryjú budúce dotazy. Nie je však zaručené, že vyrovnávacia pamäť agregácií v pamäti vráti budúce dotazy, pretože tieto nové dotazy sa môžu líšiť od dotazov odvodených z denníka dotazov. Dotazy, ktoré nie sú vrátené vyrovnávacou pamäťou agregácií v pamäti, sa odovzdajú do zdroja údajov pomocou režimu DirectQuery. V závislosti od frekvencie a poradia týchto nových dotazov môžu byť agregácie pre ne zahrnuté do vyrovnávacej pamäte agregácií v pamäti s ďalšou operáciou trénovania.
Operácia trénovania má 60-minútový časový limit. Ak sa pri trénovaní nepodarilo spracovať celý denník dotazu v rámci časového limitu, v modeli sa pri ďalšom spustení znova zobrazí oznámenie s históriou obnovení a trénovaním. Trénovací cyklus sa dokončí a nahradí existujúce automatické agregácie počas spracovania celého denníka dotazu.
Operácie obnovenia
Ako už bolo uvedené skôr, po dokončení trénovania ako súčasť prvého plánovaného obnovenia pre vybratú frekvenciu vykoná Power BI operáciu obnovenia, ktorá dotazuje a načíta nové a aktualizované údaje agregácií do vyrovnávacej pamäte agregácií v pamäti, a odstráni všetky agregácie, ktoré už nie sú dostatočne vysoké (podľa určenia algoritmu trénovania). Všetky následné obnovenia pre vybratú frekvenciu dňa alebo týždňa sú operácie obnovenia, ktoré dotazujú zdroj údajov na aktualizáciu existujúcich údajov agregácií vo vyrovnávacej pamäti. Na základe nášho predchádzajúceho príkladu sú plánované obnovenia o 9:00, 16:00 a 19:00 na daný deň operáciami obnovenia.
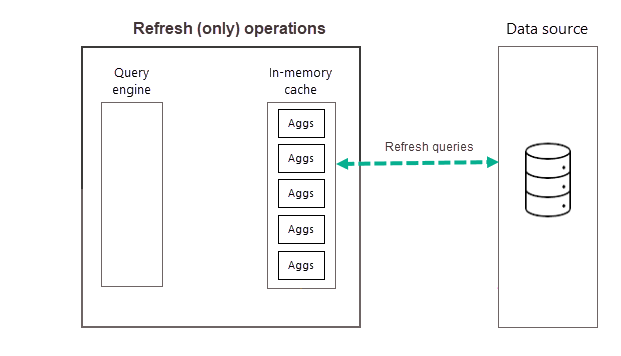
Pravidelné plánované obnovenia po celý deň (alebo týždeň) zabezpečujú, že agregácie údajov vo vyrovnávacej pamäti sú viac aktuálne s údajmi zo serverového zdroja údajov. Prostredníctvom Nastavenia modelu môžete naplánovať až 48 obnovení za deň, aby sa zabezpečilo, že dotazy zostáv, ktoré sú vrátené vyrovnávacou pamäťou agregácií, budú získavať výsledky na základe najnovších obnovených údajov zo serverového zdroja údajov.
Upozornenie
Operácie trénovania a obnovenia sú náročné na spracovanie a zdroje pre služba Power BI aj pre systémy zdrojov údajov. Zvýšenie percenta dotazov, ktoré používajú agregácie, znamená, že je potrebné dotazovať a vypočítať viac agregácií zo zdrojov údajov počas školení a operácií obnovenia, čím sa zvýši pravdepodobnosť nadmerného používania systémových zdrojov a môže to spôsobiť časové limity. Ďalšie informácie nájdete v téme Doladenie.
Školenia na vyžiadanie
Ako už bolo spomenuté, trénovací cyklus sa nemusí dokončiť v rámci časových limitov jedného cyklu obnovenia údajov. Ak nechcete čakať do ďalšieho plánovaného cyklu obnovenia, ktorý zahŕňa trénovanie, môžete tiež spustiť trénovanie automatických agregácií na požiadanie výberom položky Trénovať a Obnoviť v modeli Nastavenia. Použitím funkcie Train (Trénovať) a Refresh Now (Obnoviť) sa spustí operácia trénovania aj operácia obnovenia. Skontrolujte históriu obnovovania modelu a zistite, či je aktuálna operácia dokončená, a potom v prípade potreby vykonajte ďalšie trénovanie a obnovenie na požiadanie.
História obnovení
Každá operácia obnovenia sa zaznamená v histórii obnovení modelu. Zobrazia sa dôležité informácie o každom obnovení vrátane počtu agregácií pamäte vo vyrovnávacej pamäti, ktoré sa spotrebúvajú v percentách nakonfigurovaných dotazov. Ak chcete zobraziť históriu obnovení, na stránke Nastavenia modelu vyberte položku História obnovení. Ak chcete prejsť na detaily trochu ďalej, vyberte položku Zobraziť podrobnosti.

Pravidelnou kontrolou histórie obnovení môžete zabezpečiť dokončenie plánovaných operácií obnovenia v prijateľnom období. Uistite sa, že operácie obnovenia sa pred začatím ďalšieho plánovaného obnovenia úspešne dokončujú.
Zlyhania trénovania a obnovenia
Hoci služba Power BI vykonáva operácie trénovania a obnovenia ako súčasť prvého plánovaného obnovenia pre vybratú frekvenciu dňa alebo týždňa, tieto operácie sa implementujú ako samostatné transakcie. Ak operácia trénovania nedokáže úplne spracovať denník dotazu v rámci časových limitov, Power BI bude pokračovať v obnovení existujúcich agregácií (a bežných tabuliek v zloženom modeli) pomocou predchádzajúceho stavu trénovania. V tomto prípade bude história obnovení indikovať, že obnovenie bolo úspešné a trénovanie bude pokračovať v spracovaní denníka dotazu pri ďalšom spustení trénovania. Výkon dotazov môže byť menej optimalizovaný, ak sa zmenili vzory dotazov klientskych zostáv a agregácie sa ešte neupravovali, ale dosiahnutá úroveň výkonu by mala byť stále oveľa lepšia ako čistý model DirectQuery bez agregácií.
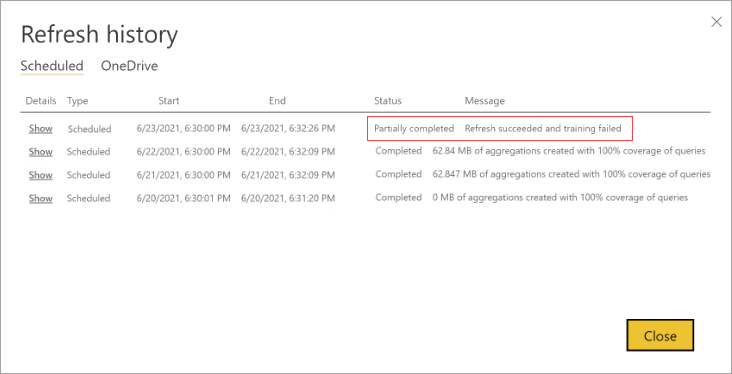
Ak na dokončenie spracovania denníka dotazu vyžaduje trénovanie príliš veľa cyklov, zvážte zníženie percenta dotazov, ktoré používajú vyrovnávaciu pamäť agregácií v modeli Nastavenia. Zníži sa tým počet agregácií vytvorených vo vyrovnávacej pamäti, ale poskytne sa viac času na dokončenie operácií trénovania a obnovenia. Ďalšie informácie nájdete v téme Doladenie.
Ak je trénovanie úspešné, ale obnovenie zlyhá, celé obnovenie je označené ako Neúspešné, pretože výsledkom je nedostupná vyrovnávacia pamäť agregácií v pamäti.
Pri plánovaní obnovenia môžete zadať e-mailové oznámenia v prípade zlyhania obnovenia.
Používateľom definované a automatické agregácie
Používateľom definované agregácie v službe Power BI je možné nakonfigurovať manuálne na základe skrytých agregovaných tabuliek v modeli. Konfigurácia agregácií definovaných používateľom je často zložitá a vyžaduje si väčšiu úroveň modelovania údajov a zručností na optimalizáciu dotazov. Automatické agregácie naopak túto zložitosť eliminujú ako súčasť systému riadeného umelou inteligenciou. Na rozdiel od používateľom definovaných agregácií, ktoré zostávajú statické, Power BI nepretržite spravuje denníky dotazov a z týchto denníkov určuje vzory dotazov na základe algoritmov prediktívneho modelovania strojového učenia. Vopred agregované údaje sa vypočítajú a uložia do pamäte na základe analýzy vzoru dotazu. Vďaka automatickým agregáciám sú modely samotrénované aj optimalizované. Keď sa menia vzory dotazov zostáv klienta, automatické agregácie sa upravia, upravia a uprednostnia a budú ukladanie týchto agregácií do vyrovnávacej pamäte používať najčastejšie.
Keďže automatické agregácie sú vytvorené na základe existujúcej infraštruktúry agregácií definovaných používateľom, v tom istom modeli je možné spoločne používať používateľom definované aj automatické agregácie. Kvalifikovaní modelári údajov môžu definovať agregácie pre tabuľky pomocou režimu DirectQuery, importu (s prírastkovým obnovením alebo bez neho) alebo duálneho režimu úložiska a zároveň majú výhody viacerých automatických agregácií pre dotazy cez pripojenia DirectQuery, ktoré nezasiahnu používateľom definované agregačné tabuľky. Táto flexibilita umožňuje vyvážené architektúry, ktoré môžu znížiť zaťaženie dotazu a vyhnúť sa kritickým miestam.
Agregácie vytvorené vo vyrovnávacej pamäti pamäte algoritmom automatického trénovania agregácií sa identifikujú ako System agregácie. Algoritmus trénovania vytvára a odstraňuje iba tieto agregácie, System pretože sa analyzujú dotazy vytvárania zostáv a vykonávajú sa úpravy na zachovanie optimálnych agregácií pre model. Používateľom definované aj automatické agregácie sa obnovujú obnovením. Automatické spracovanie agregácií je zahrnuté iba tých agregácií, ktoré boli vytvorené automatickými agregáciami a označené ako agregácie generované systémom.
Ukladanie dotazov do vyrovnávacej pamäte a automatické agregácie
Služba Power BI Premium tiež podporuje ukladanie dotazov do vyrovnávacej pamäte v službe Power BI Premium/Embedded s cieľom zachovať výsledky dotazu. Ukladanie dotazov do vyrovnávacej pamäte je iná funkcia ako automatické agregácie. Pri používaní ukladania dotazov do vyrovnávacej pamäte používa Power BI Premium vlastnú službu ukladania do vyrovnávacej pamäte na implementáciu ukladania do vyrovnávacej pamäte, zatiaľ čo automatické agregácie sa implementujú na úrovni modelu. Pri ukladaní dotazov do vyrovnávacej pamäte služba ukladá dotazy iba na počiatočné načítanie strany zostavy, preto výkon dotazov nie je vylepšený, keď používatelia interagujú so zostavou. Naopak automatické agregácie optimalizujú väčšinu dotazov zostáv predbežnou ukladanie agregovaných výsledkov dotazov do vyrovnávacej pamäte vrátane dotazov vygenerovaných pri interakcii používateľov so zostavami. Ukladanie dotazov do vyrovnávacej pamäte aj automatické agregácie môžu byť pre model povolené, ale pravdepodobne to nie je potrebné.
Monitorovanie pomocou služby Azure Log Analytics
Azure Log Analytics (LA) je služba v rámci služby Azure Monitor, ktorú môže Power BI použiť na ukladanie denníkov aktivity. S balíkom Azure Monitor môžete zhromažďovať, analyzovať a pracovať s telemetrické údaje zo služby Azure a lokálnych prostredí. Ponúka dlhodobé úložisko, rozhranie dotazu ad hoc a prístup k rozhraniu API, ktoré umožňujú export údajov a integráciu s inými systémami. Ďalšie informácie nájdete v téme Používanie služby Azure Log Analytics v službe Power BI.
Ak je služba Power BI nakonfigurovaná s kontom AZURE LA, ako je popísané v téme Konfigurácia služby Azure Log Analytics pre Power BI, môžete analyzovať mieru úspešnosti automatických agregácií. Okrem iného môžete určiť, či sú dotazy zostáv zodpovedané z vyrovnávacej pamäte v pamäti.
Ak chcete použiť túto možnosť, stiahnite si šablónu PBIT a pripojte ju k svojmu kontu analýzy denníkov, ako je popísané v tomto blogovom príspevku o službe Power BI. V zostave môžete zobraziť údaje na troch rôznych úrovniach: zobrazenie súhrnu, zobrazenie na úrovni dotazu DAX a zobrazenie na úrovni dotazu SQL.
Nasledujúci obrázok zobrazuje stránku súhrnu pre všetky dotazy. Ako vidíte, označený graf zobrazuje percento celkových dotazov, ktoré boli splnené agregáciami v porovnaní s tými, ktoré museli využívať zdroj údajov.

Ďalším krokom je podrobnejšie skúmanie použitia agregácií na úrovni dotazu DAX. Kliknite pravým tlačidlom myši na dotaz DAX v zozname (vľavo dolu) >Analýza>histórie dotazov.
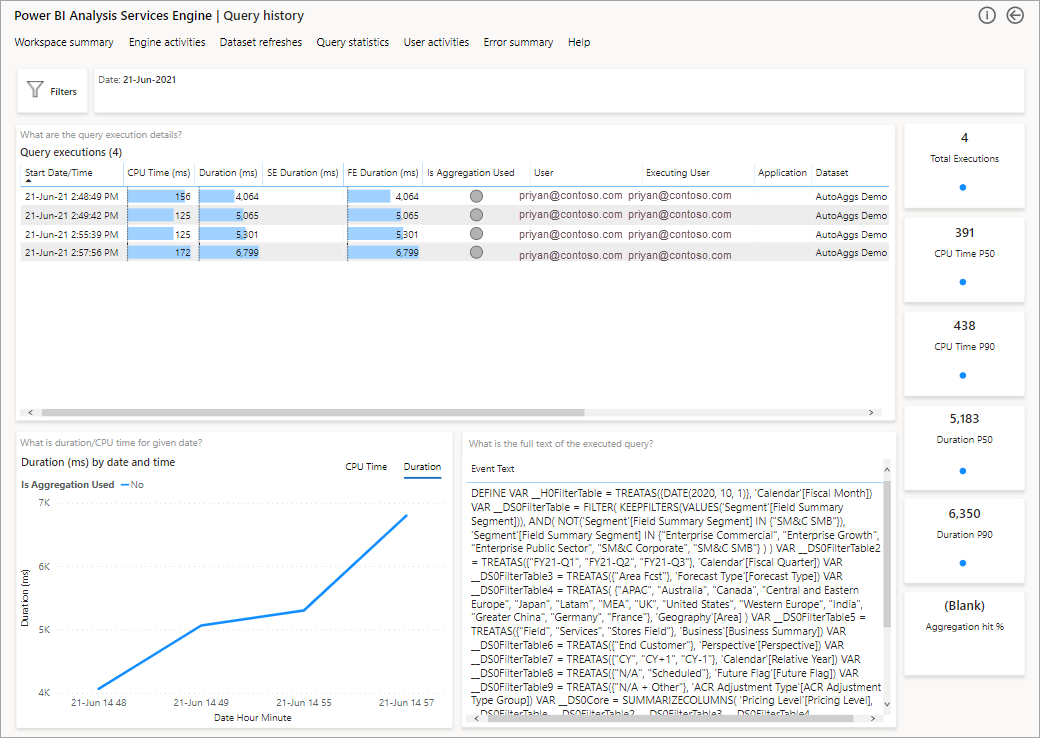
Získate tak zoznam všetkých relevantných dotazov. Podrobnejšími analýzami na ďalšiu úroveň zobrazíte viac podrobností agregácie.

Správa životného cyklu aplikácie
Modely s povolenými automatickými agregáciami majú špeciálne požiadavky na riešenia ALM od vývoja po testovanie a od testu po výrobu.
Kanály nasadenia
Pomocou kanálov nasadenia môže služba Power BI kopírovať modely pomocou ich konfigurácie modelu z aktuálnej fázy do cieľovej fázy. Automatické agregácie sa však musia v cieľovej fáze resetovať, pretože sa z aktuálnej do cieľovej fázy neprenesú žiadne nastavenia. Obsah môžete nasadiť aj pomocou programovania pomocou kanálov nasadenia REST API. Ďalšie informácie o tomto procese nájdete v téme Automatizácia kanála nasadenia pomocou rozhraní API a devOps.
Vlastné riešenia ALM
Ak používate vlastné riešenie ALM založené na koncových bodoch XMLA, majte na pamäti, že vaše riešenie môže byť schopné kopírovať tabuľky agregácií generované systémom a používateľom vytvorené ako súčasť metaúdajov modelu. Po každom kroku nasadenia v cieľovej fáze je však potrebné povoliť automatické agregácie manuálne. Power BI konfiguráciu zachová, ak prepíšete existujúci model.
Poznámka
Ak nahráte alebo opätovne publikujte model ako súčasť súboru aplikácie Power BI Desktop (.pbix), agregačné tabuľky vytvorené systémom sa stratia, keďže Power BI nahradí existujúci model všetkými jeho metaúdajmi a údajmi v cieľovom pracovnom priestore.
Zmena modelu
Po zmene modelu s automatickými agregáciami povolenými prostredníctvom koncových bodov XMLA, ako je napríklad pridávanie alebo odstraňovanie tabuliek, power BI zachová všetky existujúce agregácie, ktoré môžu byť a odstraňujú tie, ktoré už nie sú potrebné alebo relevantné. Výkon dotazov môže byť ovplyvnený, až kým sa nespustí ďalšia fáza trénovania.
Prvky metaúdajov
Modely s povolenými automatickými agregáciami obsahujú jedinečné tabuľky agregácií generované systémom. Tabuľky agregácií sa používateľom nezobrazujú v nástrojoch na vytváranie zostáv. Sú viditeľné prostredníctvom koncového bodu XMLA pomocou nástrojov s klientskymi knižnicami Analysis Services vo verzii 19.22.5 a novšej. Keď pracujete s modelmi s povolenými automatickými agregáciami, nezabudnite inovovať nástroje modelovania a správy údajov na najnovšiu verziu klientskych knižníc. Pre sql Server Management Studio (SSMS) inovujte na verziu SSMS 18.9.2 alebo novšiu. Staršie verzie SSMS nie sú schopné vyčísliť tabuľky ani skriptovať tieto modely.
Tabuľky automatických agregácií sú identifikované vlastnosťou SystemManaged tabuľky, ktorá je novšia ako tabuľkový objektový model (TOM) v klientskych knižniciach služby Analysis Services verzie 19.22.5 a novšej. Nasledujúci zlomok kódu zobrazuje SystemManaged vlastnosť nastavenú na true hodnotu pre tabuľky automatických agregácií a false pre bežné tabuľky.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
Po spustení tohto výstupu úryvku sú v konzole zahrnuté tabuľky automatických agregácií.

Pamätajte, že tabuľky agregácií sa neustále menia, pretože operácie trénovania určujú optimálne agregácie, ktoré sa majú zahrnúť do vyrovnávacej pamäte agregácií v pamäti.
Dôležité
Power BI plne spravuje automatické agregácie objekty tabuľky generované systémom. Tieto tabuľky neodstraňujte ani neupravujte sami. Môže to spôsobiť zníženie výkonu.
Power BI spravuje konfiguráciu modelu mimo modelu. Prítomnosť tabuľky agregácií spravovaných systémom v modeli nemusí nevyhnutne znamenať, že model je v skutočnosti povolený pre trénovanie automatických agregácií. Inými slovami, ak skriptujete úplnú definíciu modelu pre model s povolenými automatickými agregáciami a vytvoríte novú kópiu modelu (s iným názvom, pracovným priestorom alebo kapacitou), nový výsledný model nie je povolený pre trénovanie automatických agregácií. Stále je potrebné povoliť automatické trénovanie agregácií pre nový model v modeli Nastavenia.
Dôležité informácie a obmedzenia
Pri používaní automatických agregácií majte na pamäti:
- Agregácie nepodporujú dynamické parametre dotazu jazyka M.
- Dotazy SQL vygenerované počas počiatočnej fázy trénovania môžu generovať značné zaťaženie pre sklad údajov. Ak trénovanie nedokončuje dokončenie a na strane skladu údajov môžete overiť, či sa na dotazoch vyskytol časový limit, zvážte dočasné zvýšenie škálovania skladu údajov tak, aby vyhovovalo požiadavke na trénovanie.
- Agregácie uložené vo vyrovnávacej pamäti agregácií v pamäti sa nemusia vypočítať z najnovších údajov v zdroji údajov. Na rozdiel od čistého režimu DirectQuery a bežných tabuliek importu existuje oneskorenie medzi aktualizáciami v zdroji údajov a údajmi agregácií uloženými vo vyrovnávacej pamäti agregácií v pamäti. Hoci vždy bude existovať určitá miera latencie, dá sa zmierniť prostredníctvom efektívneho plánu obnovenia.
- Ak chcete ešte viac optimalizovať výkon, nastavte všetky tabuľky dimenzií do režimu Dual a tabuľky faktov ponechajte v režime DirectQuery.
- Automatické agregácie nie sú k dispozícii v power BI Pro, Azure Analysis Services ani SQL Server Analysis Services.
- Power BI nepodporuje sťahovanie modelov s povolenými automatickými agregáciami. Ak ste do služby Power BI nahrali alebo publikovali súbor aplikácie Power BI Desktop (.pbix) a potom povolili automatické agregácie, súbor PBIX už nebudete môcť stiahnuť. Nezabudnite zachovať kópiu súboru PBIX lokálne.
- Automatické agregácie s externými tabuľkami v službe Azure Synapse Analytics nie sú podporované. Vyčíslenie externých tabuliek v Synapse môžete vyčísliť pomocou nasledujúceho dotazu SQL:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables. - Automatické agregácie sú k dispozícii len pre modely s použitím rozšírených metaúdajov. Ak chcete povoliť automatické agregácie pre starší model, inovujte model na rozšírené metaúdaje. Ďalšie informácie nájdete v téme Používanie rozšírených metaúdajov modelu.
- Nepovoľujte automatické agregácie, ak je zdroj údajov DirectQuery nakonfigurovaný pre jediné prihlásenie, a používa dynamické zobrazenia údajov alebo ovládacie prvky zabezpečenia na obmedzenie údajov, ku ktorých má používateľ prístup. Automatické agregácie o týchto ovládacích prvkoch na úrovni zdroja údajov neumožňujú zabezpečenie správnych údajov podľa jednotlivých používateľov. Trénovaním sa zapíše do denníka upozornenie v histórii obnovení, že sa zistil zdroj údajov nakonfigurovaný na jediné prihlásenie a vynechal tabuľky, ktoré používajú tento zdroj údajov. Ak je to možné, zakážte jediné prihlásenie pre tieto zdroje údajov, aby ste plne využili optimalizované automatické agregácie výkonu dotazov.
- Nepovoľujte automatické agregácie, ak model obsahuje iba hybridné tabuľky, aby sa predišlo zbytočným režijným nákladom na spracovanie. Hybridná tabuľka používa oblasti importu aj oblasť DirectQuery. Bežným scenárom je prírastkové obnovenie s údajmi v reálnom čase, v rámci ktorého oblasť DirectQuery načíta transakcie zo zdroja údajov, ku ktorým došlo po poslednom obnovení údajov. Power BI však importuje agregácie počas obnovovania. Automatické agregácie nemôžu obsahovať transakcie, ku ktorým došlo po poslednom obnovení údajov. Trénovaním sa zapíše upozornenie do histórie obnovení, ktoré sa zistilo a vynechalo hybridné tabuľky.
- Vypočítané stĺpce sa pre automatické agregácie nepočítajú. Ak použijete vypočítaný stĺpec v režime DirectQuery, napríklad pomocou
COMBINEVALUESfunkcie DAX na vytvorenie vzťahu založeného na viacerých stĺpcoch z dvoch tabuliek DirectQuery, príslušné dotazy zostavy nezasiahnú do vyrovnávacej pamäte agregácií v pamäti. - Automatické agregácie sú k dispozícii iba v služba Power BI. Aplikácia Power BI Desktop nevytvára systémom generované tabuľky agregácií.
- Ak upravíte metaúdaje modelu s povolenými automatickými agregáciami, výkon dotazov sa môže znížiť, kým sa nespustí ďalší proces trénovania. Najvhodnejšími postupmi by ste mali zrušiť automatické agregácie, vykonať zmeny a potom znova trénovať.
- Neupravujte ani neodstraňujte tabuľky agregácií generované systémom, pokiaľ nemáte automatické agregácie zakázané a nevyčistíte model. Systém preberá zodpovednosť za spravovanie týchto objektov.
Komunita
Služba Power BI je pulzujúca komunita, v ktorej poslanci, profesionáli v oblasti BI a rovesníci zdieľajú odborné znalosti v diskusných skupinách, videách, blogoch a ďalších. Keď sa učíte o automatických agregáciách, pozrite si tieto ďalšie zdroje:
Súvisiaci obsah
Pripomienky
Pripravujeme: V priebehu roka 2024 postupne zrušíme službu Problémy v službe GitHub ako mechanizmus pripomienok týkajúcich sa obsahu a nahradíme ju novým systémom pripomienok. Ďalšie informácie nájdete na stránke: https://aka.ms/ContentUserFeedback.
Odoslať a zobraziť pripomienky pre