Sprievodný materiál k zloženému modelu v aplikácii Power BI Desktop
Tento článok je určený pre modelárov údajov, ktorí vyvíjajú zložené modely v službe Power BI. Popisuje prípady použitia zložených modelov a poskytuje pokyny na navrhovanie. Pokyny vám konkrétne pomôžu určiť, či je zložený model vhodný pre vaše riešenie. Ak áno, tento článok vám tiež pomôže navrhnúť optimálne zložené modely a zostavy.
Poznámka
Úvod do zložených modelov nie je zahrnutý v tomto článku. Ak nie ste úplne oboznámení so zloženými modelmi, odporúčame najskôr si prečítať článok Použitie zložených modelov v aplikácii Power BI Desktop .
Keďže zložené modely pozostávajú aspoň z jedného zdroja DirectQuery, je tiež dôležité, aby ste dôkladne pochopili vzťahy modelov, modely DirectQuery a pokyny na navrhovanie modelov DirectQuery.
Prípady použitia zložených modelov
Podľa definície zložený model kombinuje viacero skupín zdrojov. Skupina zdrojov môže predstavovať importované údaje alebo pripojenie k zdroju DirectQuery. Zdrojom DirectQuery môže byť relačná databáza alebo iný tabuľkový model, ktorý môže byť sémantickým modelom služby Power BI (predtým známym ako množina údajov) alebo tabuľkovým modelom služby Analysis Services. Keď sa tabuľkový model pripojí k inému tabuľkovému modelu, označuje sa ako reťazenie. Ďalšie informácie nájdete v téme Používanie režimu DirectQuery pre sémantické modely služby Power BI a Analysis Services.
Poznámka
Keď sa model pripojí k tabuľkovému modelu, ale netiahne ho o ďalšie údaje, nejde o zložený model. V tomto prípade ide o model DirectQuery, ktorý sa pripája k vzdialenému modelu – takže pozostáva len z jednej skupiny zdrojov. Tento typ modelu môžete vytvoriť na úpravu vlastností objektu zdrojového modelu, ako je napríklad názov tabuľky, spôsob zoradenia stĺpcov alebo reťazec formátu.
Pripojenie na tabuľkové modely je dôležité najmä pri rozširovaní podnikového sémantického modelu (keď ide o sémantický model služby Power BI alebo model služby Analysis Services). Podnikový sémantický model je základom pre vývoj a prevádzku skladu údajov. Poskytuje abstraktnú vrstvu údajov v sklade údajov, aby bolo možné prezentovať definície a terminológiu podniku. Bežne sa používa ako prepojenie medzi fyzickými dátovými modelmi a nástrojmi na vytváranie zostáv, ako je napríklad Power BI. Vo väčšine organizácií ho spravuje centrálny tím a preto sa popisuje ako podnik. Ďalšie informácie nájdete v scenári používania služby Enterprise BI .
Vývoj zloženého modelu môžete zvážiť v nasledujúcich situáciách.
- Váš model by mohol byť model DirectQuery a chcete zvýšiť výkon. V zloženom modeli môžete zvýšiť výkon nastavením vhodného ukladacieho priestoru pre každú tabuľku. Môžete tiež pridať používateľom definované agregácie. Obe tieto optimalizácie sú popísané ďalej v tomto článku.
- Chcete skombinovať model DirectQuery s viacerými údajmi, ktoré je potrebné importovať do modelu. Importované údaje môžete načítať z iného zdroja údajov alebo z vypočítavaných tabuliek.
- Chcete skombinovať dva alebo viaceré zdroje údajov DirectQuery do jedného modelu. Tieto zdroje môžu byť relačné databázy alebo iné tabuľkové modely.
Poznámka
Zložené modely nemôžu obsahovať pripojenia k určitým externým analytickým databázam. Tieto databázy zahŕňajú SAP Business Warehouse a SAP HANA, keď považujú databázu SAP HANA za multidimenzionálny zdroj.
Vyhodnotenie ďalších možností návrhu modelu
Hoci zložené modely Power BI dokážu vyriešiť konkrétne problémy pri navrhovaní, môžu prispieť k pomalému výkonu. V niektorých situáciách sa môžu vyskytnúť aj neočakávané výsledky výpočtu (popísané ďalej v tomto článku). Z týchto dôvodov môžete vyhodnotiť ďalšie možnosti návrhu modelu, keď existujú.
Vždy, keď je to možné, je najlepšie vyvíjať model v režime importu. Tento režim zabezpečuje najvyššiu flexibilitu návrhu a najlepší výkon.
Problémy súvisiace s veľkými objemami údajov alebo vykazovaním údajov takmer v reálnom čase však nie je možné vždy vyriešiť modelmi importu. V ľubovoľnom z týchto prípadov môžete zvážiť model DirectQuery za predpokladu, že sú údaje uložené v jednom zdroji údajov, ktorý je podporovaný režimom DirectQuery. Ďalšie informácie nájdete v téme Modely DirectQuery v aplikácii Power BI Desktop.
Prepitné
Ak je vaším cieľom rozšírenie existujúceho tabuľkového modelu o viac údajov vždy, keď je to možné, pridajte tieto údaje do existujúceho zdroja údajov.
Režim úložiska tabuliek
V zloženom modeli môžete nastaviť režim úložiska pre každú tabuľku (okrem vypočítavaných tabuliek).
- DirectQuery: Odporúčame nastaviť tento režim pre tabuľky, ktoré predstavujú veľké objemy údajov, alebo ktoré musia zabezpečiť výsledky takmer v reálnom čase. Do týchto tabuliek sa nikdy nebudú importovať údaje. Tieto tabuľky budú zvyčajne tabuľky faktov, čo sú tabuľky, ktoré sú sumarizované.
- Import: Tento režim odporúčame nastaviť pre tabuľky, ktoré sa nepoužívajú na filtrovanie a zoskupovanie tabuliek faktov v režime DirectQuery alebo hybridnom režime. Je to tiež jedinou možnosťou pre tabuľky založené na zdrojoch, ktoré nie sú podporované režimom DirectQuery. Vypočítavané tabuľky sú vždy tabuľky importu.
- Dual: Tento režim odporúčame nastaviť pre tabuľky dimenzií, keď existuje možnosť, že sa budú dotazované spolu s tabuľkami faktov DirectQuery z rovnakého zdroja.
- Hybridné: Tento režim odporúčame nastaviť pridaním oblastí importu a jednej oblasti DirectQuery do tabuľky faktov, keď chcete zahrnúť najnovšie zmeny údajov v reálnom čase, alebo keď chcete poskytnúť rýchly prístup k najčastejšie používaným údajom prostredníctvom oblastí importu a zároveň ponechať väčšinu zriedkavo používaných údajov v sklade údajov.
Existuje niekoľko možných scenárov, keď služba Power BI dotazuje zložený model.
- Dotazy len importujú alebo duálne tabuľky: Power BI načíta všetky údaje z vyrovnávacej pamäte modelu. Zabezpečí najvyšší možný výkon. Tento scenár je bežný pre tabuľky typu dimenzií dotazované pomocou filtrov alebo vizuálov rýchleho filtra.
- Dotazuje duálne tabuľky alebo tabuľky DirectQuery z rovnakého zdroja: Power BI načíta všetky údaje odoslaním jedného alebo viacerých natívnych dotazov do zdroja DirectQuery. Prinesie dobrý výkon, najmä ak existujú vhodné indexy v zdrojových tabuľkách. Tento scenár je bežný pri dotazoch, ktoré sa týkajú tabuliek s dvomi tabuľkami dimenzií a tabuľkami faktov DirectQuery. Tieto dotazy sú v rámci skupiny zdrojov, a preto sa všetky vzťahy typu one-to-one alebo one-to-many vyhodnotia ako pravidelné vzťahy.
- Dotazuje duálne tabuľky alebo hybridné tabuľky z rovnakého zdroja: Tento scenár je kombináciou predchádzajúcich dvoch scenárov. Power BI načíta údaje z vyrovnávacej pamäte modelu, keď je k dispozícii v oblasti importu, v opačnom prípade odošle jeden alebo viac natívnych dotazov do zdroja DirectQuery. Zabezpečí najvyšší možný výkon, pretože v sklade údajov je dotazovaný iba rýchly filter údajov, najmä ak existujú vhodné indexy v zdrojových tabuľkách. Čo sa týka duálnych tabuliek dimenzií a tabuliek faktov DirectQuery, tieto dotazy sú v rámci skupiny zdrojov, a preto sa všetky vzťahy typu one-to-one alebo one-to-many vyhodnotia ako pravidelné vzťahy.
- Všetky ostatné dotazy: Tieto dotazy zahŕňajú vzťahy medzi skupinami zdrojov. Je to buď pretože tabuľka importu sa vzťahuje na tabuľku DirectQuery, alebo duálna tabuľka sa vzťahuje na tabuľku DirectQuery z iného zdroja – a v takom prípade sa správa ako tabuľka importu. Všetky vzťahy sa vyhodnotia ako obmedzené vzťahy. Znamená to tiež, že zoskupenia použité v tabuľkách iných ako DirectQuery sa musia odoslať do zdroja DirectQuery ako realizované poddotazy (virtuálne tabuľky). V tomto prípade môže byť natívny dotaz neefektívny, najmä pre veľké množiny zoskupení.
Keď to zhrneme, odporúčame:
- Dôkladne zvážte, či je zložený model správnym riešením – hoci umožňuje integráciu rôznych zdrojov údajov na úrovni modelu, prináša tiež konštrukčné komplikácie s možnými následkami (popísané ďalej v tomto článku).
- Nastavte režim úložiska na DirectQuery , keď tabuľka je tabuľka faktov, ktorá ukladá veľké objemy údajov, alebo keď je potrebné zabezpečiť výsledky takmer v reálnom čase.
- Zvážte použitie hybridného režimu definovaním politiky prírastkového obnovenia a údajov v reálnom čase alebo rozdelením tabuľky faktov pomocou jazyka TOM, TMSL alebo nástroja tretej strany. Ďalšie informácie nájdete v téme Prírastkové obnovenie a údaje v reálnom čase pre sémantické modely a Scenár využitia na pokročilú správu dátových modelov.
- Nastavte režim úložiska na duálny , keď je tabuľka dimenzií a bude dotazovaná spolu s režimom DirectQuery alebo hybridnými tabuľkami faktov, ktoré sa nachádzajú v rovnakej skupine zdrojov.
- Nastavte vhodné frekvencie obnovovania na zachovanie vyrovnávacej pamäte modelu pre duálne a hybridné tabuľky (a všetky závislé vypočítavané tabuľky) synchronizované so zdrojovými databázami.
- Snažiť sa zabezpečiť integritu údajov v rámci skupín zdrojov (vrátane vyrovnávacej pamäte modelu), pretože keď sa hodnoty súvisiaceho stĺpca nezhodujú, obmedzené vzťahy odstránia riadky vo výsledkoch dotazu.
- Vždy, keď je to možné, optimalizujte zdroje údajov DirectQuery s vhodnými indexmi pre efektívne spojenia, filtrovanie a zoskupovanie.
Používateľom definované agregácie
Do tabuliek DirectQuery môžete pridávať agregácie definované používateľom. Ich účelom je zlepšiť výkon dotazov s vyššou granularnou .
Keď sú agregácie uložené vo vyrovnávacej pamäti v modeli, správajú sa ako tabuľky importu (aj keď ich nemožno používať ako tabuľku modelu). Pridanie agregácií importu do modelu DirectQuery bude mať za následok zložený model.
Poznámka
Hybridné tabuľky nepodporujú agregácie, pretože niektoré oblasti fungujú v režime importu. Nie je možné pridať agregácie na úrovni individuálnej oblasti DirectQuery.
Odporúčame, aby agregácia dodržiavala základné pravidlo: Počet riadkov musí byť najmenej 10-násobne menší ako základná tabuľka. Ak napríklad základná tabuľka obsahuje 1 miliardu riadkov, tabuľka agregácie by nemala presiahnuť 100 miliónov riadkov. Toto pravidlo zaistí adekvátny výkon v porovnaní s nákladmi na vytváranie a udržiavanie agregácie.
Vzťahy medzi skupinami zdrojov
Keď modelový vzťah zahŕňa skupiny zdrojov, označuje sa ako vzťah medzi skupinami zdrojov. Vzťahy medzi skupinami zdrojov sú tiež obmedzené vzťahy, pretože neexistuje žiadna zaručená strana "one". Ďalšie informácie nájdete v téme Vyhodnocovanie vzťahov.
Poznámka
V niektorých situáciách sa môžete vyhnúť vytvoreniu vzťahu medzi skupinami zdrojov. Pozrite si tému Používanie synchronizácie rýchlych filtrov ďalej v tomto článku.
Pri definovaní vzťahov medzi skupinami zdrojov zvážte nasledujúce odporúčania.
- Použitie stĺpcov vzťahov s nízkou kardinalitou: Na zabezpečenie najlepšieho výkonu odporúčame, aby boli stĺpce vzťahu s nízkou kardinalitou, čo znamená, že by mali uchovávať menej ako 50 000 jedinečných hodnôt. Toto doporučenie platí najmä pri kombinovaní tabuľkových modelov a netextových stĺpcov.
- Nepoužívajte veľké stĺpce textových vzťahov: Ak musíte vo vzťahu použiť textové stĺpce, vypočítajte očakávanú dĺžku textu filtra vynásobením kardinality priemernou dĺžkou textového stĺpca. Možná dĺžka textu by nemala presiahnuť 1 000 000 znakov.
- Zvýšiť granularitu vzťahu: Ak je to možné, vytvorte vzťahy na vyššej úrovni granularity. Namiesto toho, aby ste napríklad vytvoriť vzťah medzi tabuľkou dátumov s jej kľúčom dátumu, použite namiesto toho jej kľúč mesiaca. Tento prístup k návrhu vyžaduje, aby súvisiaca tabuľka obsahuje kľúčový stĺpec mesiaca a zostavy nemohli zobrazovať každodenné fakty.
- Snažiť sa o dosiahnutie jednoduchého návrhu vzťahu: Ak je to potrebné, vytvorte vzťah medzi skupinami zdrojov a skúste obmedziť počet tabuliek, ktoré sú v ceste vzťahu. Tento prístup k návrhu pomôže zlepšiť výkon a vyhnúť sa nejednoznačným cesty vzťahov.
Upozornenie
Keďže Power BI Desktop dôkladne neoveruje vzťahy medzi skupinami zdrojov, je možné vytvoriť nejednoznačné vzťahy.
Scenár vzťahov medzi skupinami zdrojov 1
Uvažujme o scenári zložitého návrhu vzťahov a o tom, ako by sa mohli vytvoriť odlišné, ale platné výsledky.
V tomto scenári má tabuľka Oblasť v skupine zdrojov A vzťah s tabuľkou Date (Dátum) a Sales (Predaj) v skupine zdrojov B. Vzťah medzi tabuľkou Region (Oblasť ) a tabuľkou Date (Dátum) je aktívny, zatiaľ čo vzťah medzi tabuľkou Region (Oblasť ) a tabuľkou Sales (Predaj ) je neaktívny. Okrem toho existuje aktívny vzťah medzi tabuľkou Region (Oblasť ) a tabuľkou Sales (Predaj ), pričom obe tieto tabuľky sú v skupine zdrojov B. Tabuľka Predaj obsahuje mierku s názvom TotalSales a tabuľka Region obsahuje dve mierky s názvom RegionalSales a RegionalSalesDirect.
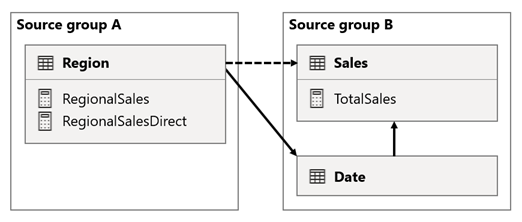
Tu sú definície mierky.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Všimnite si, ako mierka RegionalSales odkazuje na mierku TotalSales (CelkovýPredaj), zatiaľ čo mierka RegionalSalesDirect nie je. Namiesto toho mierka RegionalSalesDirect používa výraz SUM(Sales[Sales]), čo je výraz mierky TotalSales .
Rozdiel vo výsledku je malý. Keď Power BI vyhodnotí mierku RegionalSales, použije filter z tabuľky Region v tabuľke Sales (Predaj) aj na tabuľku Date (Dátum). Preto sa filter rozšíri aj z tabuľky Dátum do tabuľky Sales . Naopak, keď služba Power BI vyhodnotí mierku RegionalSalesDirect , filter z tabuľky Region sa rozšíri len do tabuľky Predaj . Výsledky vrátené mierkou RegionalSales a mierkou RegionalSalesDirect sa môžu líšiť, aj keď sú výrazy sémanticky rovnocenné.
Dôležité
Vždy, keď použijete CALCULATE funkciu s výrazom, ktorý je mierkou v skupine vzdialených zdrojov, dôkladne otestujte výsledky výpočtu.
Scenár pre vzťah medzi skupinami zdrojov 2
Uvažujme o scenári, keď vzťah typu medzi skupinami zdrojov obsahuje stĺpce vzťahov s vysokou kardinalitou.
V tomto scenári tabuľka Dátum súvisí s tabuľkou Sales (Predaj) v stĺpcoch DateKey (KľúčDátumu). Typ údajov stĺpcov DateKey je celé číslo, v rámci ktoré sa ukladajú celé čísla používajúci formát rrrrmmdd . Tabuľky patria do rôznych skupín zdrojov. Okrem toho ide o vzťah s vysokou kardinalitou, pretože najskorší dátum v tabuľke Date je 1. január 1900 a najnovším dátumom je 31. december 2100. To znamená, že v tabuľke je celkovo 73 414 riadkov (jeden riadok pre každý dátum v časovom rozpätí 1900 – 2100).
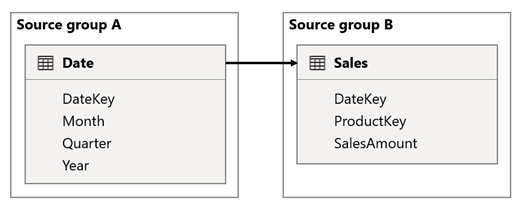
Oba prípady vzbudzujú obavy.
Keď najprv použijete stĺpce tabuľky Date (Dátum) ako filtre, šírenie filtra vyfiltruje stĺpec DateKey (KódDátumu) tabuľky Sales (Predaj) a vyhodnotí mierky. Pri filtrovaní podľa jedného roka, napríklad roku 2022, bude dotaz DAX obsahovať výraz filtra, ako napríklad Sales[DateKey] IN { 20220101, 20220102, …20221231 }. Veľkosť textu dotazu sa môže zväčšiť a stať sa veľmi veľkým, keď je počet hodnôt vo výraze filtra veľký alebo keď sú hodnoty filtra dlhými reťazcami. Pre službu Power BI je náročné vygenerovať dlhý dotaz a dotaz spustiť zdroj údajov.
Po druhé, ak použijete stĺpce tabuľky Dátum , ako napríklad Rok, Štvrťrok alebo Mesiac, ako zoskupovacie stĺpce, výsledkom budú filtre, ktoré obsahujú všetky jedinečné kombinácie hodnôt roka, štvrťroka alebo mesiaca ahodnoty stĺpca DateKey . Veľkosť reťazca dotazu, ktorý obsahuje filtre v zoskupovacích stĺpcoch a stĺpci vzťahov, môže byť veľmi veľká. Platí to najmä v prípade, keď je počet zoskupených stĺpcov a/alebo kardinalita stĺpca spojenia ( stĺpec DateKey ) veľká.
Ak chcete riešiť problémy s výkonom, môžete:
- Pridajte tabuľku Date (Dátum ) do zdroja údajov, čo má za následok model jednej skupiny zdrojov (čo znamená, že už nejde o zložený model).
- Zvýšiť granularitu vzťahu. Môžete napríklad pridať stĺpec MonthKey do oboch tabuliek a vytvoriť vzťah v týchto stĺpcoch. Vyvolaním granularity vzťahu však stratíte možnosť hlásiť dennú aktivitu predaja (pokiaľ nepoužívate stĺpec DateKey z tabuľky Predaj ).
Scenár pre vzťah medzi skupinami zdrojov 3
Uvažujme o scenári, v prípade, že medzi tabuľkami vo vzťahu medzi skupinami zdrojov nie sú zhodné hodnoty.
V tomto scenári má tabuľka Date (Dátum ) v skupine zdrojov B vzťah s tabuľkou Sales (Predaj ) v tejto skupine zdrojov a tiež s tabuľkou Target v skupine zdrojov A. Všetky vzťahy sú typu One-to-many z tabuľky Dátum týkajúcej sa stĺpcov Year . Tabuľka Sales (Predaj) obsahuje stĺpec SalesAmount (ObjemPredaja), ktorý ukladá sumy predaja, zatiaľ čo tabuľka Target obsahuje stĺpec TargetAmount (Cieľová čiastka), ktorý ukladá cieľové čiastky.

Tabuľka Date ukladá roky 2021 a 2022. Tabuľka Sales (Predaj ) ukladá čiastky predaja za roky 2021 (100) a 2022 (200), zatiaľ čo tabuľka Target ukladá cieľové čiastky na rok 2021 (100), 2022 (200) a 2023 (300) – budúci rok.
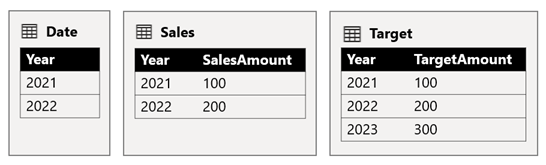
Keď vizuál tabuľky Power BI dotazuje zložený model zoskupením stĺpca Year (Rok ) z tabuľky Date (Dátum ) a sčítaním stĺpcov SalesAmount (ObjemPredaja ) a TargetAmount (Cieľová čiastka), cieľová čiastka pre rok 2023 sa nezobrazí. Je to spôsobené tým, že vzťah medzi skupinami zdrojov je obmedzený vzťah, a preto používa INNER JOIN sémantiku, ktorá eliminuje riadky, v ktorých sa na oboch stranách nenachádza žiadna zodpovedajúca hodnota. Vytvorí však správnu cieľovú čiastku súčtu (600), pretože filter tabuľky dátumov sa nepoužije na jeho vyhodnotenie.
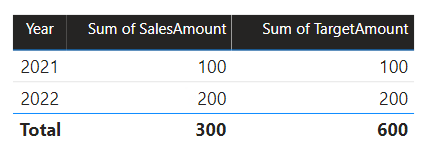
Ak je vzťah medzi tabuľkou Date (Dátum ) a tabuľkou Target vzťahom v rámci skupiny zdrojov (za predpokladu , že tabuľka Target patrila do skupiny zdrojov B), vizuál bude obsahovať (prázdny) rok, aby sa zobrazila cieľová hodnota 2023 (a všetky ostatné nezhodné roky).
Dôležité
Ak sa chcete vyhnúť nesprávnym zostavám, zabezpečte, aby sa vo stĺpcoch vzťahu nachádzali zhodné hodnoty, keď sa tabuľky dimenzií a faktov nachádzajú v rôznych skupinách zdrojov.
Ďalšie informácie o obmedzených vzťahoch nájdete v téme Vyhodnocovanie vzťahov.
Výpočty
Pri pridávaní vypočítaných stĺpcov a skupín výpočtov do zloženého modelu by ste mali zvážiť konkrétne obmedzenia.
Vypočítané stĺpce
Vypočítané stĺpce pridané do tabuľky DirectQuery, ktoré získavajú údaje z relačnej databázy, ako je napríklad Microsoft SQL Server, sú obmedzené na výrazy, ktoré pracujú s jedným riadkom po jednom riadku. Tieto výrazy nemôžu používať iteračné funkcie DAX, ako SUMXnapríklad funkcie na úpravu kontextu filtra, ako napríklad CALCULATE.
Poznámka
Nie je možné pridať vypočítané stĺpce alebo vypočítané tabuľky, ktoré závisia od zreťazených tabuľkových modelov.
Výraz vypočítaného stĺpca vo vzdialenej tabuľke DirectQuery je obmedzený len na vyhodnocovanie v rámci riadka. Takýto výraz však môžete vytvoriť, ale pri použití vo vizuáli to bude mať za následok chybu. Ak napríklad pridáte vypočítaný stĺpec do vzdialenej tabuľky DirectQuery s názvom DimProduct pomocou výrazu [Product Sales] / SUM (DimProduct[ProductSales]), výraz budete môcť úspešne uložiť v modeli. Bude to však mať za následok chybu, keď sa použije vo vizuáli, pretože porušuje obmedzenie hodnotenia v rámci riadka.
Naopak, vypočítané stĺpce pridané do vzdialenej tabuľky DirectQuery, ktorá je tabuľkovým modelom, ktorý je buď sémantickým modelom služby Power BI, alebo modelom analysis services, sú flexibilnejšie. V tomto prípade sú všetky funkcie jazyka DAX povolené, pretože výraz sa bude vyhodnocovať v rámci zdrojového tabuľkového modelu.
Mnohé výrazy vyžadujú, aby služba Power BI naplnila vypočítaný stĺpec a potom ho použila ako skupinu, filter alebo agregáciu. Keď sa vypočítaný stĺpec realizuje vo veľkej tabuľke, môže to byť nákladné z hľadiska procesora a pamäte, v závislosti od kardinality stĺpcov, od nich vypočítaný stĺpec závisí. V tomto prípade odporúčame pridať tieto vypočítané stĺpce do zdrojového modelu.
Poznámka
Keď pridáte vypočítané stĺpce do zloženého modelu, nezabudnite otestovať všetky výpočty modelu. Výpočty upstreamu nemusia fungovať správne, pretože nezovažovali svoj vplyv na kontext filtra.
Skupiny výpočtov
Ak existujú skupiny výpočtov v skupine zdrojov, ktorá sa pripája k sémantickému modelu služby Power BI alebo modelu služby Analysis Services, služba Power BI môže vrátiť neočakávané výsledky. Ďalšie informácie nájdete v téme Skupiny výpočtov, dotazy a vyhodnocovanie mierok.
Návrh modelu
Vždy by ste mali model Power BI optimalizovať prijatím návrhu hviezdicovej schémy.
Prepitné
Ďalšie informácie nájdete v téme Vysvetlenie hviezdicovej schémy a dôležitosti pre Power BI.
Nezabudnite vytvoriť tabuľky dimenzií oddelené od tabuliek faktov, aby služba Power BI dokáže správne interpretovať spojenia a vytvoriť efektívne plány dotazov. Hoci toto usmernenie platí pre každý model Power BI, platí to najmä pre modely, ktoré rozpoznáte, že sa stanú zdrojovou skupinou zloženého modelu. To umožní jednoduchšiu a efektívnejšiu integráciu ostatných tabuliek v následných modeloch.
Vždy, keď je to možné, vyhnite sa tomu, aby ste tabuľky dimenzií mali v jednej skupine zdrojov, ktoré súvisia s tabuľkou faktov, v inej skupine zdrojov. Je to spôsobené tým, že je lepšie mať vzťahy v rámci skupiny zdrojov ako vzťahy medzi skupinami zdrojov, najmä v prípade stĺpcov vzťahov s vysokou kardinalitou. Ako sme už uviedli skôr, vzťahy medzi skupinami zdrojov sa spoliehajú na zhodné hodnoty v stĺpcoch vzťahu, v opačnom prípade sa vo vizuáloch zostáv môžu zobraziť neočakávané výsledky.
Zabezpečenie na úrovni riadkov
Ak váš model obsahuje agregácie definované používateľom, vypočítané stĺpce v tabuľkách importu alebo vypočítané tabuľky, uistite sa, že zabezpečenie na úrovni riadkov je správne nastavené a testované.
Ak sa zložený model pripája k iným tabuľkovým modelom, pravidlá zabezpečenia na úrovni riadkov sa použijú len na skupinu zdrojov (lokálny model), kde sú definované. Nepoužijú sa na iné skupiny zdrojov (vzdialené modely). Nemôžete tiež definovať pravidlá zabezpečenia na úrovni riadkov pre tabuľku z inej skupiny zdrojov, ani definovať pravidlá zabezpečenia na úrovni riadkov pre lokálnu tabuľku, ktorá má vzťah k inej skupine zdrojov.
Návrh zostavy
V niektorých situáciách môžete zvýšiť výkon zloženého modelu navrhovaním optimalizovaného rozloženia zostavy.
Vizuály jednej skupiny zdrojov
Vždy, keď je to možné, vytvorte vizuály, ktoré používajú polia z jednej skupiny zdrojov. Dôvodom je, že dotazy vygenerované vizuálmi budú fungovať lepšie pri načítavaní výsledku z jednej skupiny zdrojov. Zvážte vytvorenie dvoch vizuálov umiestnených vedľa seba, ktoré načítajú údaje z dvoch rôznych skupín zdrojov.
Používanie synchronizácie rýchlych filtrov
V niektorých situáciách môžete nastaviť synchronizáciu rýchlych filtrov , aby ste nevytvorili vzťah medzi skupinami zdrojov v modeli. To vám umožní vizuálne kombinovať zdrojové skupiny, ktoré dokážu fungovať lepšie.
Predstavte si scenár, keď váš model obsahuje dve skupiny zdrojov. Každá zdrojová skupina obsahuje tabuľku dimenzií produktov, ktorá sa používa na filtrovanie predajcov a internetového predaja.
V tomto scenári skupina zdrojov A obsahuje tabuľku Produkt súvisiacu s tabuľkou PredajPredajcov . Skupina zdrojov B obsahuje tabuľku Product2 súvisiacu s tabuľkou InternetovýPredaj . Medzi skupinami zdrojov nie sú žiadne vzťahy.
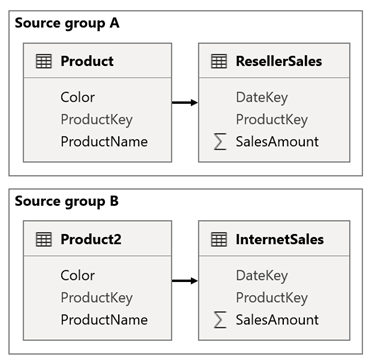
V zostave pridáte rýchly filter, ktorý filtruje stranu pomocou stĺpca Farba v tabuľke Produkt . V predvolenom nastavení rýchly filter filtruje tabuľku PredajPredajcov , ale nie tabuľku InternetovýPredaj . Potom pridáte skrytý rýchly filter pomocou stĺpca Color (Farba) tabuľky Product2 (Produkt2). Nastavením identického názvu skupiny (nachádza sa v časti Synchronizovať rýchle filtre v rozšírených možnostiach) sa filtre použité vo viditeľnom rýchlom filtri automaticky rozšíria do skrytého rýchleho filtra.
Poznámka
Používaním synchronizácie rýchlych filtrov sa môžete vyhnúť nutnosti vytvorenia vzťahu medzi skupinami zdrojov, ale tým sa zvyšuje zložitosť návrhu modelu. Uistite sa, že ste informovali ostatných používateľov o tom, prečo ste navrhli model s duplicitnými tabuľkami dimenzií. Predídete zámene tým, že skryjete tabuľky dimenzií, ktoré nechcete, aby ostatní používatelia používali. Môžete tiež pridať text popisu do skrytých tabuliek a zdokumentovať tak ich účel.
Ďalšie informácie nájdete v téme Synchronizácia samostatných rýchlych filtrov.
Ďalšie pokyny
Tu je niekoľko ďalších pokynov, ktoré vám pomôžu navrhnúť a zachovať zložené modely.
- Výkon a rozsah: Ak boli vaše zostavy predtým dynamicky pripojené k sémantickému modelu služby Power BI alebo modelu služby Analysis Services, služba Power BI môže opätovne použiť vyrovnávacie pamäte vizuálov v rámci zostáv. Keď skonvertujete dynamické pripojenie na vytvorenie lokálneho modelu DirectQuery, zostavy už nebudú môcť využívať tieto vyrovnávacie pamäte. V dôsledku toho sa môže vyskytnúť pomalší výkon alebo dokonca zlyhania obnovenia. Zároveň sa zvýši aj vyťaženie služba Power BI, čo môže vyžadovať zvýšenie kapacity alebo distribúciu vyťaženia v rámci iných kapacít. Ďalšie informácie o obnovení údajov a ukladaní do vyrovnávacej pamäte nájdete v téme Obnovenie údajov v službe Power BI.
- Premenovanie: Neodporúčame premenovať sémantické modely používané zloženými modelmi alebo premenovať ich pracovné priestory. Dôvodom je, že zložené modely sa pripájajú k sémantickým modelom služby Power BI pomocou názvov pracovných priestorov a sémantických modelov (a nie ich interných jedinečných identifikátorov). Premenovanie sémantického modelu alebo pracovného priestoru by mohlo prerušiť pripojenia používané vaším zloženým modelom.
- Riadenie: Neodporúčame, aby bola vaša jediná verzia modelu pravdy zloženým modelom. To preto, že by to záviselo od iných zdrojov údajov alebo modelov, ktoré by v prípade aktualizácie mohli viesť k porušeniu zloženého modelu. Namiesto toho odporúčame publikovať podnikový sémantický model ako jedinú verziu pravdy. Tento model považujte za spoľahlivý základ. Ostatní modelári údajov potom môžu vytvárať zložené modely, ktoré rozširujú základný model a vytvárajú špecializované modely.
- Pôvod údajov: Pred publikovaním zmien zloženého modelu použite funkcie analýzy vplyvu pôvodu údajov a sémantického modelu. Tieto funkcie sú k dispozícii v služba Power BI a môžu vám pomôcť pochopiť, ako sémantické modely súvisia a používajú. Je dôležité vedieť, že nemôžete vykonávať analýzu vplyvu na externé sémantické modely, ktoré sa zobrazujú v zobrazení pôvodu, ale v skutočnosti sa nachádzajú v inom pracovnom priestore. Ak chcete vykonať analýzu vplyvu na externý sémantický model, musíte prejsť do zdrojového pracovného priestoru.
- Aktualizácie schémy: Zložený model by ste mali obnoviť v aplikácii Power BI Desktop pri vykonaní zmien schémy v zdrojoch údajov instream. Potom bude potrebné model znova publikovať do služba Power BI. Nezabudnite dôkladne otestovať výpočty a závislé zostavy.
Súvisiaci obsah
Ďalšie informácie súvisiace s týmto článkom nájdete v nasledujúcich zdrojoch.
- Používanie zložených modelov v aplikácii Power BI Desktop
- Vzťahy modelov v aplikácii Power BI Desktop
- Modely DirectQuery v aplikácii Power BI Desktop
- Používanie režimu DirectQuery v aplikácii Power BI Desktop
- Používanie režimu DirectQuery pre sémantické modely služby Power BI a Analysis Services
- Režim úložiska v aplikácii Power BI Desktop
- Používateľom definované agregácie
- Máte nejaké otázky? Skúste sa spýtať Komunita Power BI
- Návrhy? Prispejte nápadmi na zlepšenie služby Power BI
Pripomienky
Pripravujeme: V priebehu roka 2024 postupne zrušíme službu Problémy v službe GitHub ako mechanizmus pripomienok týkajúcich sa obsahu a nahradíme ju novým systémom pripomienok. Ďalšie informácie nájdete na stránke: https://aka.ms/ContentUserFeedback.
Odoslať a zobraziť pripomienky pre