Bearbetning av naturligt språk (NLP) har många användningsområden: attitydanalys, ämnesidentifiering, språkidentifiering, extrahering av nyckelfraser och kategorisering av dokument.
Mer specifikt kan du använda NLP för att:
- Klassificera dokument. Du kan till exempel märka dokument som känsliga eller skräppost.
- Utför efterföljande bearbetning eller sökningar. Du kan använda NLP-utdata för dessa ändamål.
- Sammanfatta text genom att identifiera de entiteter som finns i dokumentet.
- Tagga dokument med nyckelord. För nyckelorden kan NLP använda identifierade entiteter.
- Gör innehållsbaserad sökning och hämtning. Taggning gör den här funktionen möjlig.
- Sammanfatta ett dokuments viktiga ämnen. NLP kan kombinera identifierade entiteter i ämnen.
- Kategorisera dokument för navigering. I det här syftet använder NLP identifierade ämnen.
- Räkna upp relaterade dokument baserat på ett valt ämne. I det här syftet använder NLP identifierade ämnen.
- Poängsätta text för sentiment. Med den här funktionen kan du utvärdera den positiva eller negativa tonen i ett dokument.
Apache®, Apache Spark och flamlogotypen är antingen registrerade varumärken eller varumärken som tillhör Apache Software Foundation i USA och/eller andra länder. Inget godkännande från Apache Software Foundation underförstås av användningen av dessa märken.
Potentiella användningsfall
Affärsscenarier som kan dra nytta av anpassad NLP är:
- Dokumentinformation för handskrivna eller maskinskapade dokument inom ekonomi, sjukvård, detaljhandel, myndigheter och andra sektorer.
- Branschoberoende NLP-uppgifter för textbearbetning, till exempel namnentitetsigenkänning (NER), klassificering, sammanfattning och relationsextrahering. Dessa uppgifter automatiserar processen för att hämta, identifiera och analysera dokumentinformation som text och ostrukturerade data. Exempel på dessa uppgifter är riskstratifieringsmodeller, ontologiklassificering och detaljhandelssammanfattningar.
- Informationshämtning och skapande av kunskapsdiagram för semantisk sökning. Den här funktionen gör det möjligt att skapa medicinska kunskapsdiagram som stöder läkemedelsidentifiering och kliniska prövningar.
- Textöversättning för konversations-AI-system i kundinriktade program inom detaljhandel, ekonomi, resor och andra branscher.
Apache Spark som ett anpassat NLP-ramverk
Apache Spark är ett ramverk för parallellbearbetning som stöder minnesintern bearbetning för att öka prestanda i program för stordataanalys. Azure Synapse Analytics, Azure HDInsight och Azure Databricks ger åtkomst till Spark och drar nytta av dess bearbetningskraft.
För anpassade NLP-arbetsbelastningar fungerar Spark NLP som ett effektivt ramverk för bearbetning av en stor mängd text. Det här NLP-biblioteket med öppen källkod innehåller Python-, Java- och Scala-bibliotek som erbjuder alla funktioner i traditionella NLP-bibliotek som spaCy, NLTK, Stanford CoreNLP och Open NLP. Spark NLP erbjuder även funktioner som stavningskontroll, attitydanalys och dokumentklassificering. Spark NLP förbättrar tidigare insatser genom att tillhandahålla toppmodern noggrannhet, hastighet och skalbarhet.
Senaste offentliga riktmärken visar Spark NLP som 38 och 80 gånger snabbare än spaCy, med jämförbar noggrannhet för träning av anpassade modeller. Spark NLP är det enda bibliotek med öppen källkod som kan använda ett distribuerat Spark-kluster. Spark NLP är ett inbyggt tillägg för Spark ML som fungerar direkt på dataramar. Därför resulterar speedups i ett kluster i en annan storleksordning av prestandavinst. Eftersom varje Spark NLP-pipeline är en Spark ML-pipeline passar Spark NLP bra för att skapa enhetliga NLP- och maskininlärningspipelines som dokumentklassificering, riskförutsägelse och rekommenderade pipelines.
Förutom utmärkta prestanda levererar Spark NLP också toppmodern noggrannhet för ett växande antal NLP-uppgifter. Spark NLP-teamet läser regelbundet de senaste relevanta akademiska uppsatserna och implementerar toppmoderna modeller. Under de senaste två till tre åren har de bäst presterande modellerna använt djupinlärning. Biblioteket levereras med fördefinierade djupinlärningsmodeller för namngiven entitetsigenkänning, dokumentklassificering, sentiment- och känsloidentifiering och meningsidentifiering. Biblioteket innehåller också dussintals förtränade språkmodeller som innehåller stöd för ord-, segment-, menings- och dokumentinbäddningar.
Biblioteket har optimerade versioner för processorer, GPU:er och de senaste Intel Xeon-chipsen. Du kan skala träning och slutsatsdragningsprocesser för att dra nytta av Spark-kluster. Dessa processer kan köras i produktion på alla populära analysplattformar.
Utmaningar
- Bearbetning av en samling textdokument i fritt format kräver en betydande mängd beräkningsresurser. Bearbetningen är också tidsintensiv. Sådana processer omfattar ofta GPU-beräkningsdistribution.
- Utan ett standardiserat dokumentformat kan det vara svårt att uppnå konsekvent korrekta resultat när du använder textbearbetning i fritt format för att extrahera specifika fakta från ett dokument. Tänk till exempel på en textrepresentation av en faktura – det kan vara svårt att skapa en process som extraherar fakturanumret och datumet när fakturor kommer från olika leverantörer.
Kriterier för nyckelval
I Azure tillhandahåller Spark-tjänster som Azure Databricks, Azure Synapse Analytics och Azure HDInsight NLP-funktioner när du använder dem med Spark NLP. Azure Cognitive Services är ett annat alternativ för NLP-funktioner. Tänk på följande frågor för att avgöra vilken tjänst som ska användas:
Vill du använda fördefinierade eller förträade modeller? Om ja kan du överväga att använda de API:er som Azure Cognitive Services erbjuder. Eller ladda ned valfri modell via Spark NLP.
Behöver du träna anpassade modeller mot en stor mängd textdata? Om ja kan du överväga att använda Azure Databricks, Azure Synapse Analytics eller Azure HDInsight med Spark NLP.
Behöver du NLP-funktioner på låg nivå som tokenisering, härstamning, lemmatisering och termfrekvens/inverterad dokumentfrekvens (TF/IDF)? Om ja kan du överväga att använda Azure Databricks, Azure Synapse Analytics eller Azure HDInsight med Spark NLP. Eller använd ett programbibliotek med öppen källkod i det bearbetningsverktyg du väljer.
Behöver du enkla NLP-funktioner på hög nivå som entitets- och avsiktsidentifiering, ämnesidentifiering, stavningskontroll eller attitydanalys? Om ja kan du överväga att använda DE API:er som Cognitive Services erbjuder. Eller ladda ned valfri modell via Spark NLP.
Kapacitetsmatris
I följande tabeller sammanfattas de viktigaste skillnaderna i funktionerna i NLP-tjänster.
Allmänna funktioner
| Kapacitet | Spark-tjänsten (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) med Spark NLP | Azure Cognitive Services |
|---|---|---|
| Tillhandahåller förtränad modeller som en tjänst | Ja | Ja |
| REST-API | Ja | Ja |
| Programmerbarhet | Python, Scala | Mer information om språk som stöds finns i Ytterligare resurser |
| Stöder bearbetning av stordatamängder och stora dokument | Ja | Nej |
NLP-funktioner på låg nivå
| Funktion för anteckningar | Spark-tjänsten (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) med Spark NLP | Azure Cognitive Services |
|---|---|---|
| Meningsdetektor | Ja | Nej |
| Djup meningsdetektor | Ja | Ja |
| Tokenizer | Ja | Ja |
| N-gramgenerator | Ja | Nej |
| Word-segmentering | Ja | Ja |
| Stemmer | Ja | Nej |
| Lemmatizer | Ja | Nej |
| Del av tal-märkning | Ja | Nej |
| Beroendeparser | Ja | Nej |
| Översättning | Ja | Nej |
| Stoppordsrengöringsmedel | Ja | Nej |
| Stavningskorrigering | Ja | Nej |
| Normalizer | Ja | Ja |
| Textmatchning | Ja | Nej |
| TF/IDF | Ja | Nej |
| Matchning av reguljära uttryck | Ja | Inbäddad i Language Understanding Service (LUIS). Stöds inte i Conversational Language Understanding (CLU), som ersätter LUIS. |
| Datummatchning | Ja | Möjligt i LUIS och CLU via DateTime-identifierare |
| Segment | Ja | Nej |
NLP-funktioner på hög nivå
| Kapacitet | Spark-tjänsten (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) med Spark NLP | Azure Cognitive Services |
|---|---|---|
| Stavningskontroll | Ja | Nej |
| Summering | Ja | Ja |
| Frågor och svar | Ja | Ja |
| Identifiering av attityder | Ja | Ja |
| Känsloidentifiering | Ja | Stöder åsiktsutvinning |
| Tokenklassificering | Ja | Ja, via anpassade modeller |
| Textklassificering | Ja | Ja, via anpassade modeller |
| Textrepresentation | Ja | Nej |
| NER | Ja | Ja – textanalys ger en uppsättning NER och anpassade modeller är i entitetsigenkänning |
| Igenkänning av enhet | Ja | Ja, via anpassade modeller |
| Språkidentifiering | Ja | Ja |
| Stöder språk förutom engelska | Ja, stöder över 200 språk | Ja, stöder över 97 språk |
Konfigurera Spark NLP i Azure
Om du vill installera Spark NLP använder du följande kod, men ersätter <version> med det senaste versionsnumret. Mer information finns i Spark NLP-dokumentationen.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Utveckla NLP-pipelines
För körningsordningen för en NLP-pipeline följer Spark NLP samma utvecklingskoncept som traditionella Spark ML-maskininlärningsmodeller. Men Spark NLP tillämpar NLP-tekniker.
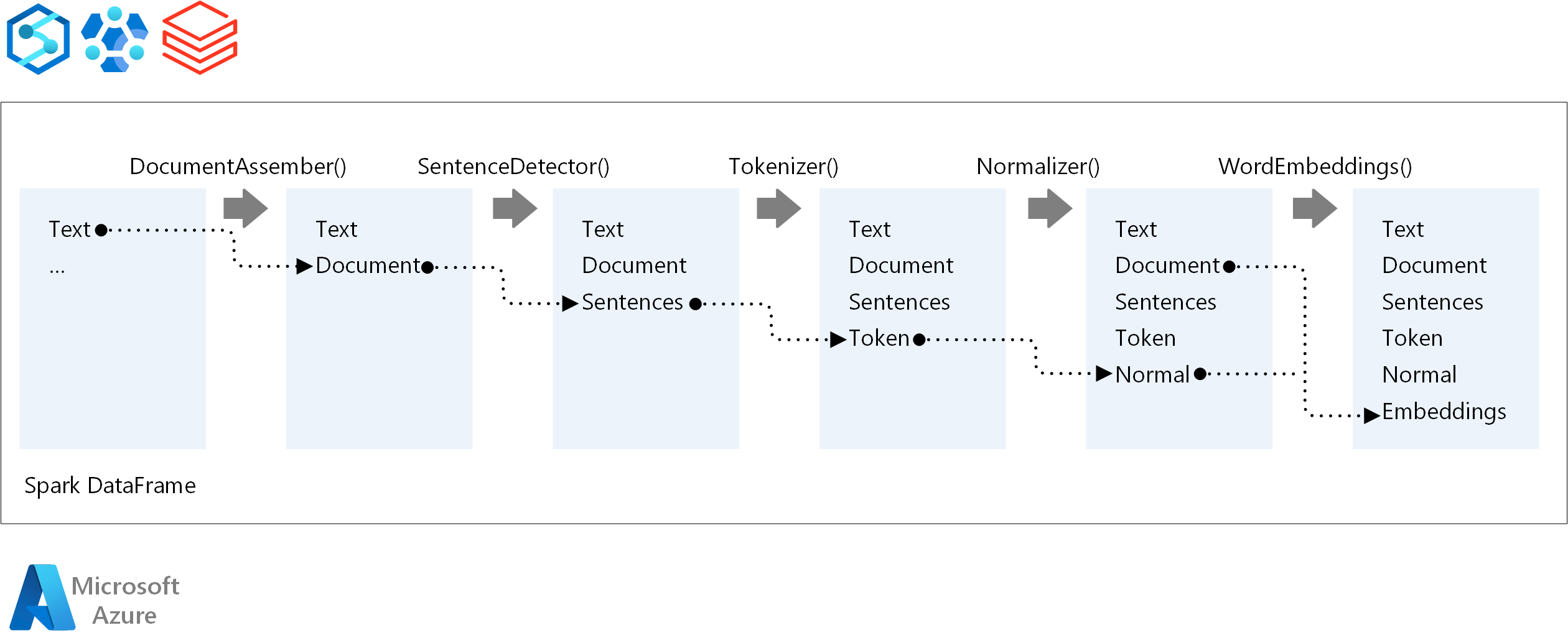
Huvudkomponenterna i en Spark NLP-pipeline är:
DocumentAssembler: En transformerare som förbereder data genom att ändra den till ett format som Spark NLP kan bearbeta. Det här steget är startpunkten för varje Spark NLP-pipeline. DocumentAssembler kan läsa antingen en
Stringkolumn eller enArray[String]. Du kan användasetCleanupModeförbearbetning av texten. Som standard är det här läget inaktiverat.SentenceDetector: En kommenterare som identifierar meningsgränser med hjälp av den metod som anges. Den här anteckningen kan returnera varje extraherad mening i en
Array. Den kan också returnera varje mening i en annan rad, om du angerexplodeSentencessant.Tokenizer: En anteckning som separerar råtext i token, eller enheter som ord, siffror och symboler, och returnerar token i en
TokenizedSentencestruktur. Den här klassen är inte anpassad. Om du passar en tokenizer använder den internaRuleFactoryindatakonfigurationen för att konfigurera regler för tokenisering. Tokenizer använder öppna standarder för att identifiera token. Om standardinställningarna inte uppfyller dina behov kan du lägga till regler för att anpassa Tokenizer.Normalizer: En anteckning som rensar token. Normalizer kräver stjälkar. Normalizer använder reguljära uttryck och en ordlista för att transformera text och ta bort felaktiga tecken.
WordEmbeddings: Uppslagsanteckningar som mappar token till vektorer. Du kan använda
setStoragePathför att ange en anpassad uppslagsordlista för token för inbäddningar. Varje rad i ordlistan måste innehålla en token och dess vektorrepresentation, avgränsade med blanksteg. Om en token inte hittas i ordlistan blir resultatet en nollvektor med samma dimension.
Spark NLP använder Spark MLlib-pipelines, som MLflow internt stöder. MLflow är en plattform med öppen källkod för maskininlärningslivscykeln. Dess komponenter omfattar:
- Mlflow Tracking: Registrerar experiment och ger ett sätt att fråga efter resultat.
- MLflow-projekt: Gör det möjligt att köra datavetenskapskod på valfri plattform.
- MLflow-modeller: Distribuerar modeller till olika miljöer.
- Modellregister: Hanterar modeller som du lagrar på en central lagringsplats.
MLflow är integrerat i Azure Databricks. Du kan installera MLflow i andra Spark-baserade miljöer för att spåra och hantera dina experiment. Du kan också använda MLflow Model Registry för att göra modeller tillgängliga i produktionssyfte.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudsakliga författare:
- Moritz Steller | Senior Cloud Solution Architect
- Zoiner Tejada | VD och arkitekt
Nästa steg
Spark NLP-dokumentation:
Azure-komponenter:
Lär dig resurser:
Relaterade resurser
- Storskalig bearbetning av anpassat naturligt språk i Azure
- Välj en Microsoft Cognitive Services-teknik
- Jämför maskininlärningsprodukter och -tekniker från Microsoft
- MLflow och Azure Machine Learning
- AI-berikande med bild- och naturligt språkbearbetning i Azure Cognitive Search
- Analysera nyhetsflöden med analys i nära realtid med hjälp av bild- och bearbetning av naturligt språk
- Föreslå innehållstaggar med NLP med djupinlärning