Den här referensarkitekturen visar hur du tränar en rekommendationsmodell med hjälp av Azure Databricks och sedan distribuerar modellen som ett API med hjälp av Azure Cosmos DB, Azure Machine Learning och Azure Kubernetes Service (AKS). En referensimplementering av den här arkitekturen finns i Skapa ett API för realtidsrekommendationer på GitHub.
Arkitektur
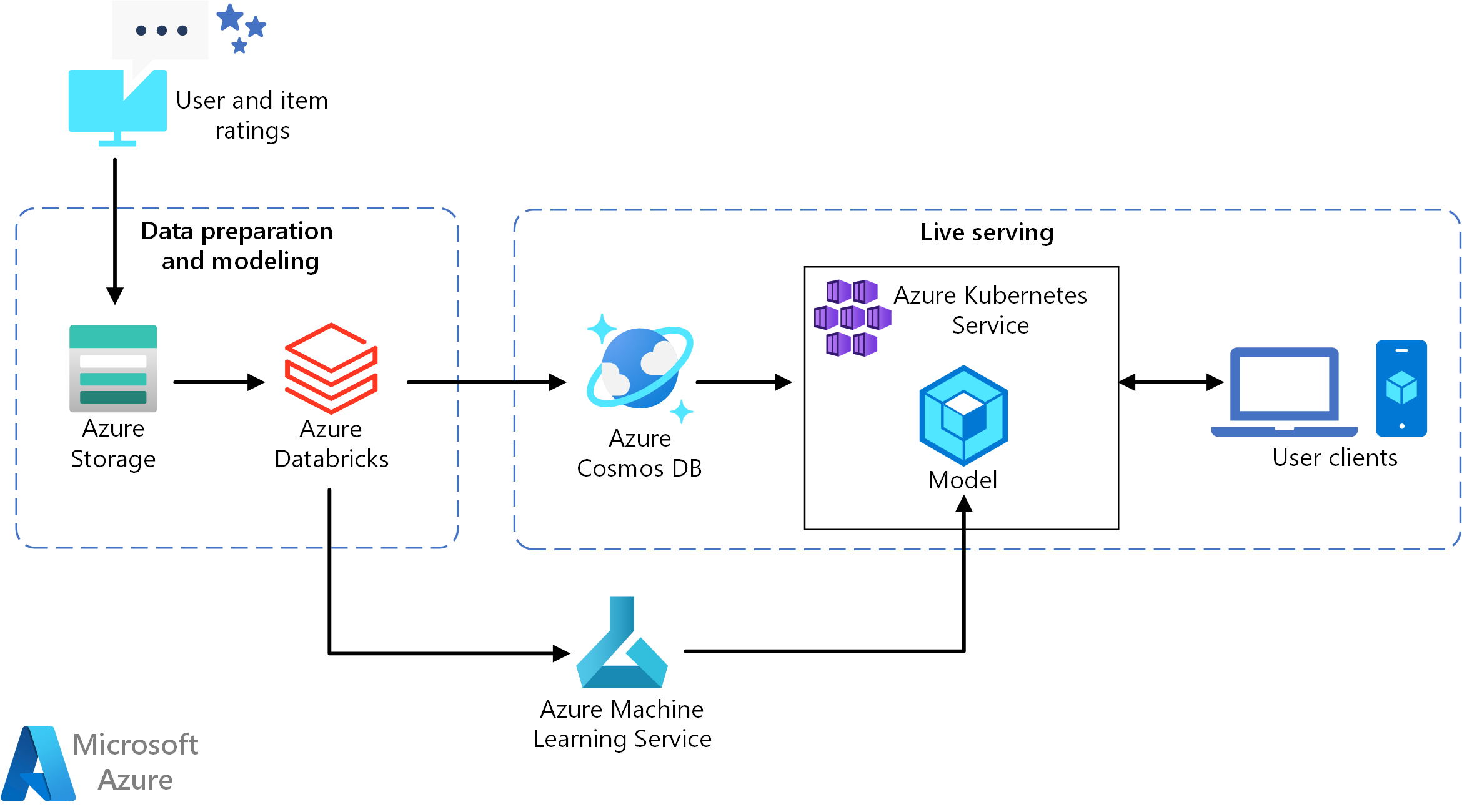
Ladda ned en Visio-fil med den här arkitekturen.
Den här referensarkitekturen är avsedd för träning och distribution av ett API för rekommenderande realtidstjänst som kan ge de 10 bästa filmrekommendationerna för en användare.
Dataflöde
- Spåra användarbeteenden. En serverdelstjänst kan till exempel logga när en användare betygsätter en film eller klickar på en produkt eller nyhetsartikel.
- Läs in data i Azure Databricks från en tillgänglig datakälla.
- Förbered data och dela upp dem i tränings- och testuppsättningar för att träna modellen. (Den här guiden beskriver alternativ för att dela upp data.)
- Anpassa Spark Collaborative Filtering-modellen till data.
- Utvärdera modellens kvalitet med hjälp av klassificerings- och rangordningsmått. (Den här guiden innehåller information om de mått som du kan använda för att utvärdera din rekommenderare.)
- Förberäkna de 10 främsta rekommendationerna per användare och lagra som en cache i Azure Cosmos DB.
- Distribuera en API-tjänst till AKS med hjälp av Machine Learning-API:erna för att containerisera och distribuera API:et.
- När serverdelstjänsten får en begäran från en användare anropar du api:et för rekommendationer som finns i AKS för att få de 10 främsta rekommendationerna och visa dem för användaren.
Komponenter
- Azure Databricks. Databricks är en utvecklingsmiljö som används för att förbereda indata och träna rekommendationsmodellen i ett Spark-kluster. Azure Databricks tillhandahåller också en interaktiv arbetsyta för att köra och samarbeta i notebook-filer för databearbetning eller maskininlärningsuppgifter.
- Azure Kubernetes Service (AKS). AKS används för att distribuera och operationalisera ett TJÄNST-API för maskininlärningsmodell i ett Kubernetes-kluster. AKS är värd för den containerbaserade modellen, vilket ger skalbarhet som uppfyller dina dataflödeskrav, identitets- och åtkomsthantering samt loggning och hälsoövervakning.
- Azure Cosmos DB. Azure Cosmos DB är en globalt distribuerad databastjänst som används för att lagra de 10 bästa rekommenderade filmerna för varje användare. Azure Cosmos DB passar bra för det här scenariot eftersom det ger låg svarstid (10 ms vid den 99:e percentilen) för att läsa de vanligaste rekommenderade objekten för en viss användare.
- Maskininlärning. Den här tjänsten används för att spåra och hantera maskininlärningsmodeller och sedan paketera och distribuera dessa modeller till en skalbar AKS-miljö.
- Microsoft-rekommenderare. Den här lagringsplatsen med öppen källkod innehåller verktygskod och exempel som hjälper användarna att komma igång med att skapa, utvärdera och operationalisera ett rekommenderande system.
Information om scenario
Den här arkitekturen kan generaliseras för de flesta rekommendationsmotorscenarier, inklusive rekommendationer för produkter, filmer och nyheter.
Potentiella användningsfall
Scenario: En medieorganisation vill ge film- eller videorekommendationer till sina användare. Genom att tillhandahålla anpassade rekommendationer uppfyller organisationen flera affärsmål, inklusive ökade klickfrekvenser, ökat engagemang på sin webbplats och högre användarnöjdhet.
Den här lösningen är optimerad för detaljhandeln och för medie- och underhållningsindustrin.
Att tänka på
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser som kan användas för att förbättra kvaliteten på en arbetsbelastning. Mer information finns i Microsoft Azure Well-Architected Framework.
Batchbedömning av Spark-modeller i Azure Databricks beskriver en referensarkitektur som använder Spark och Azure Databricks för att köra schemalagda batchbedömningsprocesser. Vi rekommenderar den här metoden för att generera nya rekommendationer.
Prestandaeffektivitet
Prestandaeffektivitet handlar om att effektivt skala arbetsbelastningen baserat på användarnas behov. Mer information finns i Översikt över grundpelare för prestandaeffektivitet.
Prestanda är ett primärt övervägande för realtidsrekommendationer, eftersom rekommendationer vanligtvis faller i den kritiska sökvägen för en användarbegäran på din webbplats.
Kombinationen av AKS och Azure Cosmos DB gör att den här arkitekturen kan ge en bra utgångspunkt för att ge rekommendationer för en medelstor arbetsbelastning med minimala omkostnader. Under ett belastningstest med 200 samtidiga användare ger den här arkitekturen rekommendationer med en mediansvarstid på cirka 60 ms och utförs med ett dataflöde på 180 begäranden per sekund. Belastningstestet kördes mot standarddistributionskonfigurationen (ett AKS-kluster med 3 x D3 v2 med 12 vCPU:er, 42 GB minne och 11 000 enheter för begäranden (RU:er) per sekund som etablerats för Azure Cosmos DB).
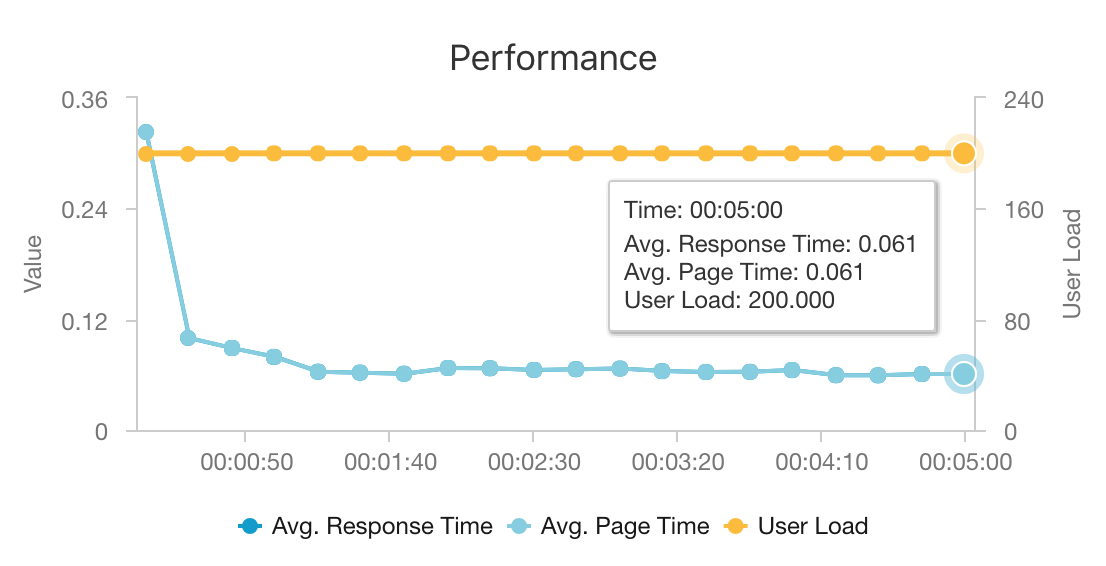
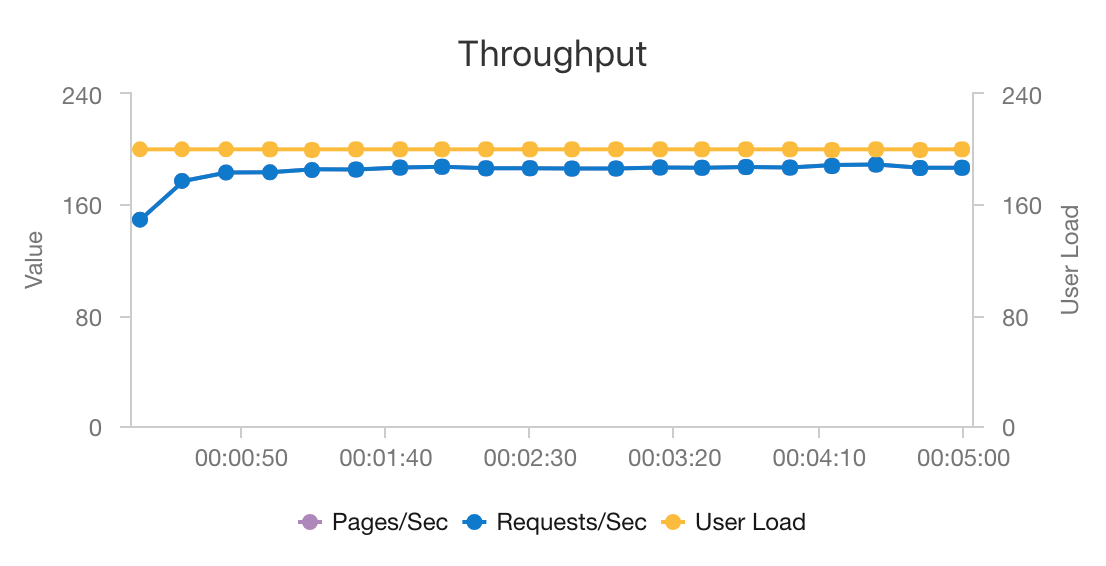
Azure Cosmos DB rekommenderas för dess nyckelfärdiga globala distribution och användbarhet för att uppfylla alla databaskrav som din app har. Om du vill minska svarstiden något kan du överväga att använda Azure Cache for Redis i stället för Azure Cosmos DB för att hantera sökningar. Azure Cache for Redis kan förbättra prestanda för system som är starkt beroende av data i serverdelslager.
Skalbarhet
Om du inte planerar att använda Spark eller om du har en mindre arbetsbelastning som inte behöver distribueras kan du överväga att använda en Datavetenskap virtuell dator (DSVM) i stället för Azure Databricks. En DSVM är en virtuell Azure-dator med ramverk för djupinlärning och verktyg för maskininlärning och datavetenskap. Precis som med Azure Databricks kan alla modeller som du skapar i en DSVM operationaliseras som en tjänst på AKS via Machine Learning.
Under träningen etablerar du antingen ett större Spark-kluster med fast storlek i Azure Databricks eller konfigurerar automatisk skalning. När automatisk skalning är aktiverat övervakar Databricks belastningen på klustret och skalar upp och ned efter behov. Etablera eller skala ut ett större kluster om du har en stor datastorlek och vill minska den tid det tar för dataförberedelser eller modelleringsuppgifter.
Skala AKS-klustret för att uppfylla dina prestanda- och dataflödeskrav. Var noga med att skala upp antalet poddar för att fullt ut utnyttja klustret och skala noderna i klustret för att möta efterfrågan på din tjänst. Du kan också ange automatisk skalning i ett AKS-kluster. Mer information finns i Distribuera en modell till ett Azure Kubernetes Service-kluster.
För att hantera Azure Cosmos DB-prestanda beräknar du antalet läsningar som krävs per sekund och etablerar antalet RU:er per sekund (dataflöde) som behövs. Använd metodtips för partitionering och horisontell skalning.
Kostnadsoptimering
Kostnadsoptimering handlar om att titta på sätt att minska onödiga utgifter och förbättra drifteffektiviteten. Mer information finns i Översikt över kostnadsoptimeringspelare.
De viktigaste kostnadsfaktorerna i det här scenariot är:
- Den Azure Databricks-klusterstorlek som krävs för träning.
- AKS-klusterstorleken som krävs för att uppfylla dina prestandakrav.
- Azure Cosmos DB RU:er har etablerats för att uppfylla dina prestandakrav.
Hantera Azure Databricks-kostnaderna genom att träna om mindre ofta och stänga av Spark-klustret när det inte används. AKS- och Azure Cosmos DB-kostnaderna är knutna till det dataflöde och prestanda som krävs av din webbplats och skalas upp och ned beroende på mängden trafik till din webbplats.
Distribuera det här scenariot
Om du vill distribuera den här arkitekturen följer du anvisningarna för Azure Databricks i installationsdokumentet. Kortfattat kräver instruktionerna att du:
- Skapa en Azure Databricks-arbetsyta.
- Skapa ett nytt kluster med följande konfiguration i Azure Databricks:
- Klusterläge: Standard
- Databricks-körningsversion: 4.3 (inkluderar Apache Spark 2.3.1, Scala 2.11)
- Python-version: 3
- Drivrutinstyp: Standard_DS3_v2
- Arbetstyp: Standard_DS3_v2 (min och max efter behov)
- Automatisk avslutning: (efter behov)
- Spark-konfiguration: (efter behov)
- Miljövariabler: (efter behov)
- Skapa en personlig åtkomsttoken på Azure Databricks-arbetsytan. Mer information finns i dokumentationen för Azure Databricks-autentisering.
- Klona Microsoft Recommenders-lagringsplatsen till en miljö där du kan köra skript (till exempel din lokala dator).
- Följ installationsanvisningarna för snabbinstallation för att installera relevanta bibliotek i Azure Databricks.
- Följ installationsanvisningarna för snabbinstallation för att förbereda Azure Databricks för driftsättning.
- Importera anteckningsboken ALS Movie Operationalization till din arbetsyta. När du har loggat in på din Azure Databricks-arbetsyta gör du följande:
- Klicka på Start till vänster på arbetsytan.
- Högerklicka på tomt utrymme i hemkatalogen. Välj Importera.
- Välj URL och klistra in följande i textfältet:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - Klicka på Importera.
- Öppna anteckningsboken i Azure Databricks och koppla det konfigurerade klustret.
- Kör notebook-filen för att skapa de Azure-resurser som krävs för att skapa ett rekommendations-API som innehåller de 10 bästa filmrekommendationerna för en viss användare.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudsakliga författare:
- Miguel Fierro | Chef för huvudnamn Dataforskare
- Nikhil Joglekar | Product Manager, Azure-algoritmer och datavetenskap
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
- Skapa ett API för rekommendation i realtid
- Vad är Azure Databricks?
- Azure Kubernetes Service
- Välkommen till Azure Cosmos DB
- Vad är Azure Machine Learning?