Parsa transformering i mappning av dataflöde
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Dataflöden är tillgängliga både i Azure Data Factory och Azure Synapse Pipelines. Den här artikeln gäller för mappning av dataflöden. Om du är nybörjare på transformeringar kan du läsa den inledande artikeln Transformera data med hjälp av ett mappningsdataflöde.
Använd parsningstransformeringen för att parsa textkolumner i dina data som är strängar i dokumentformulär. De aktuella typerna av inbäddade dokument som kan parsas är JSON, XML och avgränsad text.
Konfiguration
I konfigurationspanelen för parsningstransformering väljer du först den typ av data som finns i kolumnerna som du vill parsa infogade. Parsningstransformeringen innehåller också följande konfigurationsinställningar.

Column
På samma sätt som härledda kolumner och aggregeringar ändrar du antingen en befintlig kolumn genom att välja den i listrutan. Eller så kan du skriva in namnet på en ny kolumn här. ADF lagrar parsade källdata i den här kolumnen. I de flesta fall vill du definiera en ny kolumn som parsar det inkommande inbäddade dokumentsträngsfältet.
Uttryck
Använd uttrycksverktyget för att ange källan för parsningen. Detta kan vara så enkelt som att bara välja källkolumnen med de fristående data som du vill parsa, eller så kan du skapa komplexa uttryck att parsa.
Exempel på uttryck
Källsträngsdata:
chrome|steel|plastic- Uttryck:
(desc1 as string, desc2 as string, desc3 as string)
- Uttryck:
JSON-källdata:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- Uttryck:
(level as string, registration as long)
- Uttryck:
Käll kapslade JSON-data:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- Uttryck:
(car as (model as string, year as integer), color as string, transmission as string)
- Uttryck:
Käll-XML-data:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- Uttryck:
(Customers as (Customer as integer, CompanyName as string))
- Uttryck:
Käll-XML med attributdata:
<cars><car model="camaro"><year>1989</year></car></cars>- Uttryck:
(cars as (car as ({@model} as string, year as integer)))
- Uttryck:
Obs! Om du stöter på fel när du extraherar attribut (t.ex. @model) från en komplex typ är en lösning att konvertera den komplexa typen till en sträng, ta bort @-symbolen (dvs. ersätt(toString(your_xml_string_parsed_column_name.cars.car),'@'''') ) och sedan använda parsa JSON-transformeringsaktiviteten.
Utdatakolumntyp
Här konfigurerar du målutdataschemat från parsningen som skrivs till en enda kolumn. Det enklaste sättet att ange ett schema för dina utdata från parsning är att välja knappen Identifiera typ längst upp till höger i uttrycksverktyget. ADF försöker identifiera schemat automatiskt från strängfältet, som du parsar och ställer in det åt dig i utdatauttrycket.
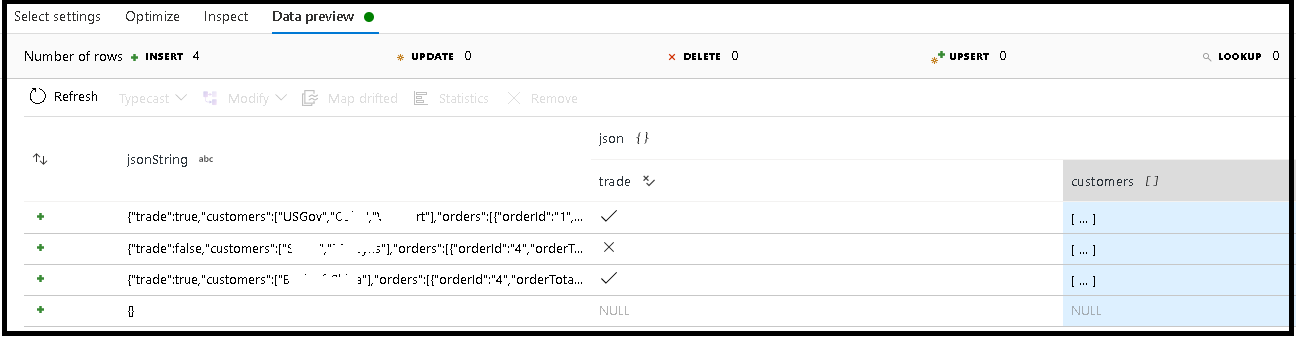
I det här exemplet har vi definierat parsning av det inkommande fältet "jsonString", som är oformaterad text, men formaterad som en JSON-struktur. Vi ska lagra de tolkade resultaten som JSON i en ny kolumn med namnet "json" med det här schemat:
(trade as boolean, customers as string[])
Kontrollera att dina utdata har mappats korrekt på fliken Granska och förhandsgranskning av data.
Använd aktiviteten Härledd kolumn för att extrahera hierarkiska data (d.v.s. your_complex_column_name.car.model i uttrycksfältet)
Exempel
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
Dataflödesskript
Syntax
Exempel
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
Relaterat innehåll
- Använd transformeringen Platta ut för att pivotleda rader till kolumner.
- Använd transformering av härledda kolumner för att transformera rader.