Filformat och komprimeringskodceringar som stöds i Azure Data Factory och Synapse Analytics (äldre)
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln gäller för följande anslutningsappar: Amazon S3, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP och SFTP.
Viktigt!
Tjänsten introducerade en ny formatbaserad datamängdsmodell, se motsvarande formatartikel med information:
- Avro-format
- Binärt format
- Avgränsat textformat
- JSON-format
- ORC-format
- Parquet-format
De restkonfigurationer som nämns i den här artikeln stöds fortfarande som de är för bakåtkompatibelhet. Du rekommenderas att använda den nya modellen framöver.
Textformat (äldre)
Kommentar
Lär dig den nya modellen från artikeln Avgränsat textformat . Följande konfigurationer av filbaserade datalagerdatauppsättningar stöds fortfarande som de är för bakåtkompatibelhet. Du rekommenderas att använda den nya modellen framöver.
Om du vill läsa från en textfil eller skriva till en textfil anger du type egenskapen i format avsnittet i datamängden till TextFormat. Du kan också ange följande valfria egenskaper i avsnittet format. Konfigurationsinformation finns i avsnittet med TextFormat-exempel.
| Property | beskrivning | Tillåtna värden | Obligatoriskt |
|---|---|---|---|
| columnDelimiter | Det tecken som används för att avgränsa kolumner i en fil. Du kan överväga att använda ett sällsynt tecken som inte kan skrivas ut som kanske inte finns i dina data. Ange till exempel "\u0001", som representerar Start of Heading (SOH). | Endast ett tecken är tillåtet. Standardvärdet är kommatecken (,). Om du vill använda ett Unicode-tecken läser du Unicode-tecken för att hämta motsvarande kod för det. |
Nej |
| rowDelimiter | Det tecken som används för att avgränsa rader i en fil. | Endast ett tecken är tillåtet. Standardvärdet är något av följande värden vid läsning: ["\r\n", "\r", "\n"] och "\r\n" vid skrivning. | Nej |
| escapeChar | Det specialtecken som används för att undanta en kolumnavgränsare i innehållet i indatafilen. Du kan inte ange både escapeChar och quoteChar för en tabell. |
Endast ett tecken är tillåtet. Inget standardvärde. Exempel: om du har kommatecken (',') som kolumnavgränsare men vill ha kommatecknet i texten (exempel: "Hello, world"), kan du definiera '$' som escape-tecken och använda strängen "Hello$, world" i källan. |
Nej |
| quoteChar | Det tecken som används för att referera till ett strängvärde. Kolumn- och radavgränsarna innanför citattecknen behandlas som en del av strängvärdet. Den här egenskapen gäller både in- och utdatauppsättningar. Du kan inte ange både escapeChar och quoteChar för en tabell. |
Endast ett tecken är tillåtet. Inget standardvärde. Om du till exempel har kommatecken (',') som kolumnavgränsare men vill ha kommatecken i texten (exempel: <Hello, world>) kan du definiera " (dubbla citattecken) som citattecken och använda strängen "Hello, world" i källan. |
Nej |
| nullValue | Ett eller flera tecken som används för att representera ett null-värde. | Ett eller flera tecken. Standardvärdena är "\N" och "NULL" vid läsning och "\N" vid skrivning. | Nej |
| encodingName | Ange kodningsnamnet. | Ett giltigt kodningsnamn. Se Egenskapen Encoding.EncodingName. Exempel: windows-1250 or shift_jis. Standardvärdet är UTF-8. | Nej |
| firstRowAsHeader | Anger om den första raden ska behandlas som en rubrik. För en indatauppsättning läser tjänsten den första raden som en rubrik. För en utdatauppsättning skriver tjänsten den första raden som en rubrik. Exempelscenarier finns i avsnittet med användningsscenarier för firstRowAsHeader och skipLineCount. |
Sant False (standard) |
Nej |
| skipLineCount | Anger antalet rader som inte är tomma att hoppa över när du läser data från indatafiler. Om både skipLineCount och firstRowAsHeader anges hoppas raderna över först, varefter rubrikinformationen läses från indatafilen. Exempelscenarier finns i avsnittet med användningsscenarier för firstRowAsHeader och skipLineCount. |
Integer | Nej |
| treatEmptyAsNull | Anger om du vill hantera null-strängar eller tomma strängar som ett null-värde vid läsning av data från en indatafil. | True (standard) Falsk |
Nej |
TextFormat-exempel
I följande JSON-definition för en datauppsättning anges några av de valfria egenskaperna.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
Om du vill använda ett escapeChar i stället för quoteChar ersätter du raden med quoteChar med följande escapeChar:
"escapeChar": "$",
Användningsscenarier för firstRowAsHeader och skipLineCount
- Du kopierar från en källa som inte är filbaserad till en textfil och vill lägga till en rubrikrad som innehåller schemametadata (till exempel: SQL-schema). Ange
firstRowAsHeadersom true i utdatauppsättningen för det här scenariot. - Du kopierar från en textfil som innehåller en rubrikrad till en mottagare som inte är filbaserad och vill ignorera raden. Ange
firstRowAsHeadersom true i indatauppsättningen. - Du kopierar från en textfil och vill hoppa över några rader i början som antingen inte innehåller några data eller som innehåller rubrikinformation. Ange
skipLineCountför att ange antalet rader som ska hoppas över. Om resten av filen innehåller en rubrikrad kan du också angefirstRowAsHeader. Om bådeskipLineCountochfirstRowAsHeaderanges hoppas raderna över först, varefter rubrikinformationen läses från indatafilen
JSON-format (äldre)
Kommentar
Lär dig den nya modellen från JSON-formatartikeln . Följande konfigurationer av filbaserade datalagerdatauppsättningar stöds fortfarande som de är för bakåtkompatibelhet. Du rekommenderas att använda den nya modellen framöver.
Information om hur du importerar/exporterar en JSON-fil som den är till/från Azure Cosmos DB finns i avsnittet Importera/exportera JSON-dokument i artikeln Flytta data till/från Azure Cosmos DB .
Om du vill parsa JSON-filerna eller skriva data i JSON-format anger du type egenskapen i format avsnittet till JsonFormat. Du kan också ange följande valfria egenskaper i avsnittet format. Konfigurationsinformation finns i avsnittet med JsonFormat-exempel.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| filePattern | Ange mönstret för de data som lagras i varje JSON-fil. Tillåtna värden är: setOfObjects och arrayOfObjects. Standardvärdet är setOfObjects. Detaljerad information om dessa mönster finns i avsnittet om JSON-filmönster. | Nej |
| jsonNodeReference | Om du vill iterera och extrahera data från objekten i ett matrisfält med samma mönster anger du JSON-sökvägen för matrisen. Den här egenskapen stöds endast vid kopiering av data från JSON-filer. | Nej |
| jsonPathDefinition | Ange JSON-sökvägsuttrycket för varje kolumnmappning med ett anpassat kolumnnamn (inled med liten bokstav). Den här egenskapen stöds endast vid kopiering av data från JSON-filer och du kan extrahera data från objekt eller matris. För fält under rotobjektet börjar du med $; för fält inuti matrisen som väljs av egenskapen jsonNodeReference börjar du från matriselementet. Konfigurationsinformation finns i avsnittet med JsonFormat-exempel. |
Nej |
| encodingName | Ange kodningsnamnet. En lista över giltiga kodningsnamn finns i avsnittet om egenskapen Encoding.EncodingName. Exempel: windows-1250 or shift_jis. Standardvärdet är UTF-8. | Nej |
| nestingSeparator | Tecken som används för att avgränsa kapslingsnivåer. Standardvärdet är ”.” (punkt). | Nej |
Kommentar
När det gäller korsanvända data i matrisen till flera rader (fall 1 –> exempel 2 i JsonFormat-exempel) kan du bara välja att expandera en enskild matris med egenskapen jsonNodeReference.
JSON-filmönster
aktiviteten Kopiera kan parsa följande mönster för JSON-filer:
Typ I: setOfObjects
Varje fil som innehåller ett enskilt objekt eller flera radavgränsade/sammanfogade objekt. När det här alternativet väljs i en utdatauppsättning genererar kopieringsaktiviteten en enskild JSON-fil med ett objekt per rad (radavgränsade).
Exempel på JSON med enskilda objekt
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }Exempel med radavgränsad JSON
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}Exempel med sammanfogad JSON
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Typ II: arrayOfObjects
Varje fil innehåller en matris med objekt.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
JsonFormat-exempel
Fall 1: Kopiera data från JSON-filer
Exempel 1: hämta data från objektet och matrisen
I det här exemplet mappas ett JSON-rotobjekt till en enskild post i tabellformat. Om du har en JSON-fil med följande innehåll:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
och du vill kopiera den till en Azure SQL-tabell i följande format, genom att extrahera data från både objekten och matrisen:
| ID | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | PC | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 1/13/2017 11:24:37 AM |
Indatauppsättningen med typen JsonFormat definieras så här: (partiell definition med endast de relevanta delarna). Mer specifikt:
- Avsnittet
structuredefinierar de anpassade kolumnnamnen och den motsvarande datatypen vid konverteringen till data i tabellformat. Det här avsnittet är valfritt såvida inte kolumnmappning krävs. Mer information finns i Mappa källdatauppsättningskolumner till måldatauppsättningskolumner. jsonPathDefinitionanger JSON-sökvägen för varje kolumn och anger var data ska extraheras från. Om du vill kopiera data från matrisen kan du användaarray[x].propertyför att extrahera värdet för den angivna egenskapen frånxthobjektet, eller så kan du användaarray[*].propertyför att hitta värdet från alla objekt som innehåller den här egenskapen.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
Exempel 2: korstillämpa flera objekt med samma mönster från en matris
I det här exemplet omvandlas ett JSON-rotobjekt till flera poster i tabellform. Om du har en JSON-fil med följande innehåll:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
som du vill kopiera till en Azure SQL-tabell i följande format genom att förenkla data i matrisen och korskoppla med den gemensamma rotinformationen:
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
Indatauppsättningen med typen JsonFormat definieras så här: (partiell definition med endast de relevanta delarna). Mer specifikt:
- Avsnittet
structuredefinierar de anpassade kolumnnamnen och den motsvarande datatypen vid konverteringen till data i tabellformat. Det här avsnittet är valfritt såvida inte kolumnmappning krävs. Mer information finns i Mappa källdatauppsättningskolumner till måldatauppsättningskolumner. jsonNodeReferenceanger att iterera och extrahera data från objekten med samma mönster under matrisenorderlines.jsonPathDefinitionanger JSON-sökvägen för varje kolumn och anger var data ska extraheras från. I det här exempletordernumberär ,orderdateochcityunder rotobjektet med JSON-sökvägen som börjar med$., medanorder_pdochorder_pricedefinieras med sökvägen härledd från matriselementet utan$..
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
Observera följande:
structureOm ochjsonPathDefinitioninte definieras i datauppsättningen identifierar kopieringsaktiviteten schemat från det första objektet och platta ut hela objektet.- Om JSON-indata har en matris konverterar kopieringsaktiviteten som standard hela matrisvärdet till en sträng. Du kan välja att extrahera data från den med hjälp av
jsonNodeReferenceoch/ellerjsonPathDefinition, eller hoppa över det genom att inte ange den ijsonPathDefinition. - Om det finns dubblettnamn på samma nivå väljer kopieringsaktiviteten det sista.
- Egenskapsnamn är skiftlägeskänsliga. Två egenskaper med samma namn men med olika skiftlägen behandlas som två olika egenskaper.
Fall 2: Skriva data till JSON-fil
Om du har följande tabell i SQL Database:
| ID | order_date | order_price | order_by |
|---|---|---|---|
| 1 | 20170119 | 2000 | David |
| 2 | 20170120 | 3500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
och för varje post förväntar du dig att skriva till ett JSON-objekt i följande format:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
Utdatauppsättningen med typen JsonFormat definieras så här: (partiell definition med endast de relevanta delarna). Mer specifikt structure definierar avsnittet de anpassade egenskapsnamnen i målfilen nestingSeparator (standardvärdet är ".") används för att identifiera kapslingsskiktet från namnet. Det här avsnittet är valfritt såvida du inte vill ändra egenskapsnamnet som jämförs med källkolumnnamnet, eller kapsla vissa av egenskaperna.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Parquet-format (äldre)
Kommentar
Lär dig den nya modellen från parquet-formatartikeln . Följande konfigurationer av filbaserade datalagerdatauppsättningar stöds fortfarande som de är för bakåtkompatibelhet. Du rekommenderas att använda den nya modellen framöver.
Om du vill parsa Parquet-filer eller skriva data i Parquet-format anger du egenskapen formattype till ParquetFormat. Du behöver inte ange några egenskaper i avsnittet Format i avsnittet typeProperties. Exempel:
"format":
{
"type": "ParquetFormat"
}
Observera följande:
- Komplexa datatyper stöds inte (MAP, LIST).
- Tomt utrymme i kolumnnamnet stöds inte.
- Parquet-filer har följande komprimeringsrelaterade alternativ: NONE, SNAPPY, GZIP och LZO. Tjänsten stöder läsning av data från Parquet-filen i något av dessa komprimerade format förutom LZO – den använder komprimeringskodc i metadata för att läsa data. Men när du skriver till en Parquet-fil väljer tjänsten SNAPPY, vilket är standard för Parquet-format. För närvarande finns det inget alternativ för att åsidosätta det här beteendet.
Viktigt!
För kopiering som tillhandahålls av lokalt installerad integrationskörning, t.ex. mellan lokala datalager och molndatalager, måste du installera 64-bitars JRE 8 (Java Runtime Environment) eller OpenJDK på din IR-dator om du inte kopierar Parquet-filer som de är. Mer information finns i följande stycke.
För kopiering som körs på lokalt installerad IR med Parquet-filserialisering/deserialisering letar tjänsten upp Java-körningen genom att först kontrollera registret (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) för JRE, om det inte hittas, för det andra genom att kontrollera systemvariabeln JAVA_HOME för OpenJDK.
- För att kunna använda JRE: 64-bitars IR kräver 64-bitars JRE. Du hittar den härifrån.
- Så här använder du OpenJDK: det stöds sedan IR version 3.13. Paketera jvm.dll med alla andra nödvändiga sammansättningar av OpenJDK till en lokalt installerad IR-dator och ange systemmiljövariabeln JAVA_HOME i enlighet med detta.
Dricks
Om du kopierar data till/från Parquet-format med hjälp av lokalt installerad integrationskörning och stöter på felet "Ett fel uppstod när java anropades, meddelande: java.lang.OutOfMemoryError:Java heap space", kan du lägga till en miljövariabel _JAVA_OPTIONS på datorn som är värd för lokalt installerad IR för att justera minsta/max-heapstorleken för JVM för att ge en sådan kopia och sedan köra pipelinen igen.
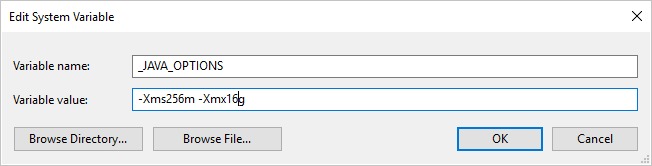
Exempel: ange variabel med _JAVA_OPTIONS värdet -Xms256m -Xmx16g. Flaggan Xms anger den första minnesallokeringspoolen för en virtuell Java-dator (JVM) och Xmx anger den maximala minnesallokeringspoolen. Det innebär att JVM startas med Xms mycket minne och kan använda maximalt Xmx mycket minne. Som standard använder tjänsten min 64MB och max 1G.
Datatypsmappning för Parquet-filer
| Datatyp för interimstjänst | Parquet primitiv typ | Parquet Original Type (Deserialize) | Parquet originaltyp (serialisera) |
|---|---|---|---|
| Booleskt | Booleskt | Saknas | Saknas |
| SByte | Int32 | Int8 | Int8 |
| Byte | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/Binary | UInt64 | Decimal |
| Enstaka | Flyttal | Saknas | Saknas |
| Dubbel | Dubbel | Saknas | Saknas |
| Decimal | Binära | Decimal | Decimal |
| String | Binära | Utf8 | Utf8 |
| Datum/tid | Int96 | Saknas | Saknas |
| TimeSpan | Int96 | Saknas | Saknas |
| DateTimeOffset | Int96 | Saknas | Saknas |
| Bytearray | Binära | Saknas | Saknas |
| GUID | Binära | Utf8 | Utf8 |
| Char | Binära | Utf8 | Utf8 |
| CharArray | Stöds inte | Saknas | Saknas |
ORC-format (äldre)
Kommentar
Lär dig artikeln om den nya modellen från ORC-format . Följande konfigurationer av filbaserade datalagerdatauppsättningar stöds fortfarande som de är för bakåtkompatibelhet. Du rekommenderas att använda den nya modellen framöver.
Om du vill parsa ORC-filerna eller skriva data i ORC-format ange du egenskapen formattype till OrcFormat. Du behöver inte ange några egenskaper i avsnittet Format i avsnittet typeProperties. Exempel:
"format":
{
"type": "OrcFormat"
}
Observera följande:
- Komplexa datatyper stöds inte (STRUCT, MAP, LIST, UNION).
- Tomt utrymme i kolumnnamnet stöds inte.
- ORC-filen har tre komprimeringsrelaterade alternativ: NONE, ZLIB och SNAPPY. Tjänsten stöder läsning av data från ORC-filen i något av dessa komprimerade format. Data Factory använder komprimerings-codec i metadata för att läsa data. När du skriver till en ORC-fil väljer tjänsten dock ZLIB, vilket är standardvärdet för ORC. För närvarande finns det inget alternativ för att åsidosätta det här beteendet.
Viktigt!
För kopiering som tillhandahålls av lokalt installerad integrationskörning, t.ex. mellan lokala datalager och molndatalager, måste du installera 64-bitars JRE 8 (Java Runtime Environment) eller OpenJDK på din IR-dator om du inte kopierar ORC-filer som de är. Mer information finns i följande stycke.
För kopiering som körs på lokalt installerad IR med ORC-filserialisering/deserialisering letar tjänsten upp Java-körningen genom att först kontrollera registret (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) för JRE, om det inte hittas, för det andra genom att kontrollera systemvariabeln JAVA_HOME för OpenJDK.
- För att kunna använda JRE: 64-bitars IR kräver 64-bitars JRE. Du hittar den härifrån.
- Så här använder du OpenJDK: det stöds sedan IR version 3.13. Paketera jvm.dll med alla andra nödvändiga sammansättningar av OpenJDK till en lokalt installerad IR-dator och ange systemmiljövariabeln JAVA_HOME i enlighet med detta.
Datatypsmappning för ORC-filer
| Datatyp för interimstjänst | ORC-typer |
|---|---|
| Booleskt | Booleskt |
| SByte | Byte |
| Byte | Kort |
| Int16 | Kort |
| UInt16 | Int |
| Int32 | Int |
| UInt32 | Long |
| Int64 | Long |
| UInt64 | String |
| Enstaka | Flyttal |
| Dubbel | Dubbel |
| Decimal | Decimal |
| String | String |
| Datum/tid | Tidsstämpel |
| DateTimeOffset | Tidsstämpel |
| TimeSpan | Tidsstämpel |
| Bytearray | Binära |
| GUID | String |
| Char | Tecken(1) |
AVRO-format (äldre)
Kommentar
Läs artikeln om den nya modellen från Avro-format . Följande konfigurationer av filbaserade datalagerdatauppsättningar stöds fortfarande som de är för bakåtkompatibelhet. Du rekommenderas att använda den nya modellen framöver.
Om du vill parsa Avro-filerna eller skriva data i Avro-format anger du egenskapen formattype till AvroFormat. Du behöver inte ange några egenskaper i avsnittet Format i avsnittet typeProperties. Exempel:
"format":
{
"type": "AvroFormat",
}
Om du vill använda Avro-format i en Hive-tabell kan du läsa Apache Hive-självstudien.
Observera följande:
- Komplexa datatyper stöds inte (poster, uppräkningar, matriser, kartor, fackföreningar och fasta).
Stöd för komprimering (äldre)
Tjänsten stöder komprimera/dekomprimera data under kopieringen. När du anger compression egenskapen i en indatauppsättning läser kopieringsaktiviteten komprimerade data från källan och dekomprimeras. När du anger egenskapen i en utdatauppsättning komprimeras kopieringsaktiviteten och skriver sedan data till mottagaren. Här följer några exempelscenarier:
- Läs GZIP-komprimerade data från en Azure-blob, dekomprimera dem och skriv resultatdata till Azure SQL Database. Du definierar indata för Azure Blob-datauppsättningen
compressiontypemed egenskapen som GZIP. - Läs data från en oformaterad fil från det lokala filsystemet, komprimera dem med GZip-format och skriv komprimerade data till en Azure-blob. Du definierar en Azure Blob-datauppsättning med utdata med
compressiontypeegenskapen som GZip. - Läs .zip-filen från FTP-servern, dekomprimera den för att hämta filerna inuti och landa filerna i Azure Data Lake Store. Du definierar en FTP-indatauppsättning med
compressiontypeegenskapen som ZipDeflate. - Läs en GZIP-komprimerad data från en Azure-blob, dekomprimera den, komprimera den med BZIP2 och skriv resultatdata till en Azure-blob. Du definierar indatauppsättningen för Azure Blob med
compressiontypeinställd på GZIP och utdatauppsättningen medcompressiontypeinställd på BZIP2.
Om du vill ange komprimering för en datauppsättning använder du komprimeringsegenskapen i datauppsättningens JSON som i följande exempel:
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Komprimeringsavsnittet har två egenskaper:
Typ: komprimeringskodcen, som kan vara GZIP, Deflate, BZIP2 eller ZipDeflate. Observera att när du använder kopieringsaktivitet för att dekomprimera ZipDeflate-filer och skriva till filbaserat datalager för mottagare, extraheras filerna till mappen:
<path specified in dataset>/<folder named as source zip file>/.Nivå: komprimeringsförhållandet, som kan vara optimalt eller snabbast.
Snabbast: Komprimeringsåtgärden bör slutföras så snabbt som möjligt, även om den resulterande filen inte komprimeras optimalt.
Optimal: Komprimeringsåtgärden bör komprimeras optimalt, även om åtgärden tar längre tid att slutföra.
Mer information finns i avsnittet Komprimeringsnivå .
Kommentar
Komprimeringsinställningar stöds inte för data i AvroFormat, OrcFormat eller ParquetFormat. När du läser filer i dessa format identifierar och använder tjänsten komprimeringskodcen i metadata. När du skriver till filer i dessa format väljer tjänsten standardkomprimeringskodc för det formatet. Till exempel ZLIB för OrcFormat och SNAPPY för ParquetFormat.
Filtyper och komprimeringsformat som inte stöds
Du kan använda utökningsbarhetsfunktionerna för att transformera filer som inte stöds. Två alternativ är Azure Functions och anpassade uppgifter med hjälp av Azure Batch.
Du kan se ett exempel som använder en Azure-funktion för att extrahera innehållet i en tar-fil. Mer information finns i Azure Functions-aktivitet.
Du kan också skapa den här funktionen med hjälp av en anpassad dotnet-aktivitet. Mer information finns här
Relaterat innehåll
Lär dig de senaste filformat och komprimeringar som stöds från filformat och komprimering som stöds.