Skapa ditt första arbetsflöde med ett Azure Databricks-jobb
Den här artikeln visar ett Azure Databricks-jobb som samordnar uppgifter för att läsa och bearbeta en exempeldatauppsättning. I den här snabbstarten kommer du att göra följande:
- Skapa en ny notebook-fil och lägg till kod för att hämta en exempeldatauppsättning som innehåller populära babynamn per år.
- Spara exempeldatauppsättningen i Unity Catalog.
- Skapa en ny notebook-fil och lägg till kod för att läsa datamängden från Unity Catalog, filtrera den efter år och visa resultatet.
- Skapa ett nytt jobb och konfigurera två uppgifter med hjälp av notebook-filerna.
- Kör jobbet och visa resultatet.
Krav
Om din arbetsyta är Unity Catalog-aktiverad och serverlösa arbetsflöden är aktiverade körs jobbet som standard på serverlös beräkning. Du behöver inte behörighet att skapa kluster för att köra jobbet med serverlös beräkning.
Annars måste du ha behörighet att skapa kluster för att skapa jobbberäkning eller behörigheter till beräkningsresurser för alla syften.
Du måste ha en volym i Unity Catalog. Den här artikeln använder en volym med namnet my-volume i ett schema med namnet default i en katalog med namnet main. Du måste också ha följande behörigheter i Unity Catalog:
READ VOLUMEochWRITE VOLUME, ellerALL PRIVILEGES, förmy-volumevolymen.USE SCHEMAellerALL PRIVILEGESfördefaultschemat.USE CATALOGellerALL PRIVILEGESförmainkatalogen.
Information om hur du anger dessa behörigheter finns i Behörigheter för Databricks-administratören eller Unity Catalog och skyddsbara objekt.
Skapa anteckningsböckerna
Hämta och spara data
Så här skapar du en notebook-fil för att hämta exempeldatauppsättningen och spara den i Unity Catalog:
Gå till din Azure Databricks-landningssida och klicka på
 Nytt i sidofältet och välj Notebook. Databricks skapar och öppnar en ny tom anteckningsbok i standardmappen. Standardspråket är det språk som du senast använde och notebook-filen kopplas automatiskt till den beräkningsresurs som du senast använde.
Nytt i sidofältet och välj Notebook. Databricks skapar och öppnar en ny tom anteckningsbok i standardmappen. Standardspråket är det språk som du senast använde och notebook-filen kopplas automatiskt till den beräkningsresurs som du senast använde.Om det behövs ändrar du standardspråket till Python.
Kopiera följande Python-kod och klistra in den i den första cellen i notebook-filen.
import requests response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv') csvfile = response.content.decode('utf-8') dbutils.fs.put("/Volumes/main/default/my-volume/babynames.csv", csvfile, True)
Läsa och visa filtrerade data
Så här skapar du en notebook-fil för att läsa och presentera data för filtrering:
Gå till din Azure Databricks-landningssida och klicka på
Nytt i sidofältet och välj Notebook. Databricks skapar och öppnar en ny tom anteckningsbok i standardmappen. Standardspråket är det språk som du senast använde och notebook-filen kopplas automatiskt till den beräkningsresurs som du senast använde.Om det behövs ändrar du standardspråket till Python.
Kopiera följande Python-kod och klistra in den i den första cellen i notebook-filen.
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv") babynames.createOrReplaceTempView("babynames_table") years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist() years.sort() dbutils.widgets.dropdown("year", "2014", [str(x) for x in years]) display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
Skapa ett jobb
Klicka på
 Arbetsflöden i sidofältet.
Arbetsflöden i sidofältet.Klicka på
 .
.Fliken Uppgifter visas med dialogrutan Skapa aktivitet.
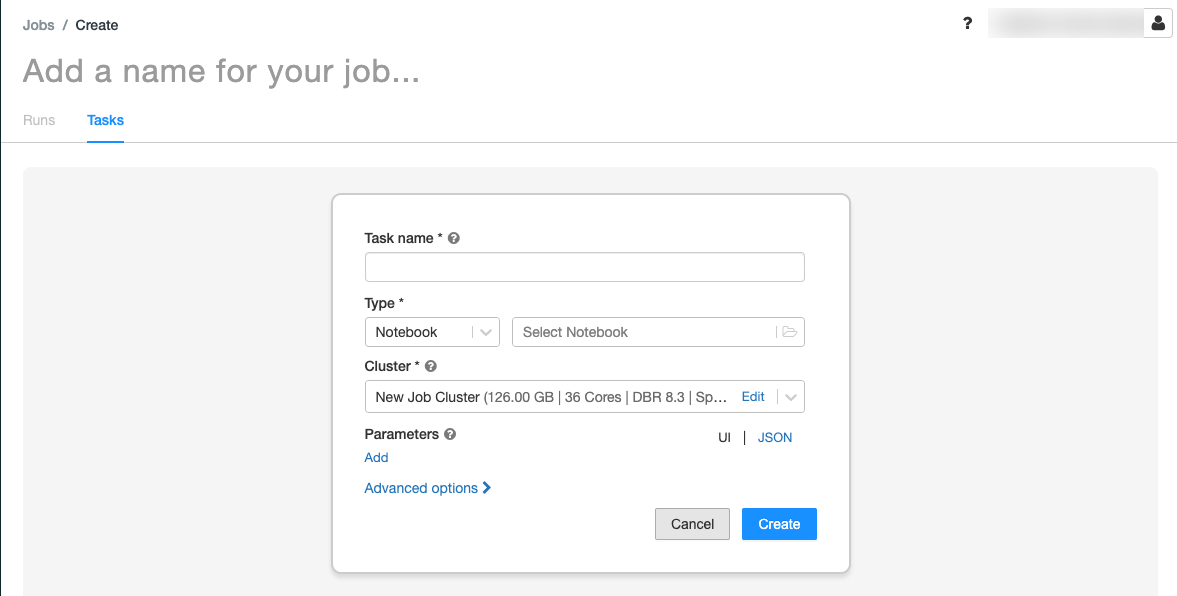
Ersätt Lägg till ett namn för jobbet... med jobbets namn.
I fältet Aktivitetsnamn anger du ett namn för aktiviteten, till exempel retrieve-baby-names.
I listrutan Typ väljer du Anteckningsbok.
Använd filläsaren för att hitta den första notebook-filen som du skapade, klicka på anteckningsbokens namn och klicka på Bekräfta.
Klicka på Skapa uppgift.
Klicka
 under den uppgift som du nyss skapade för att lägga till en annan uppgift.
under den uppgift som du nyss skapade för att lägga till en annan uppgift.I fältet Aktivitetsnamn anger du ett namn för aktiviteten, till exempel filter-baby-names.
I listrutan Typ väljer du Anteckningsbok.
Använd filläsaren för att hitta den andra anteckningsboken som du skapade, klicka på anteckningsbokens namn och klicka på Bekräfta.
Klicka på Lägg till under Parametrar. I fältet Nyckel anger du
year. I fältet Värde anger du2014.Klicka på Skapa uppgift.
Kör jobbet
Om du vill köra jobbet direkt klickar du  i det övre högra hörnet. Du kan också köra jobbet genom att klicka på fliken Körningar och klicka på Kör nu i tabellen Aktiva körningar .
i det övre högra hörnet. Du kan också köra jobbet genom att klicka på fliken Körningar och klicka på Kör nu i tabellen Aktiva körningar .
Visa körningsinformation
Klicka på fliken Körningar och klicka på länken för körningen i tabellen Aktiva körningar eller i tabellen Slutförda körningar (senaste 60 dagarna).
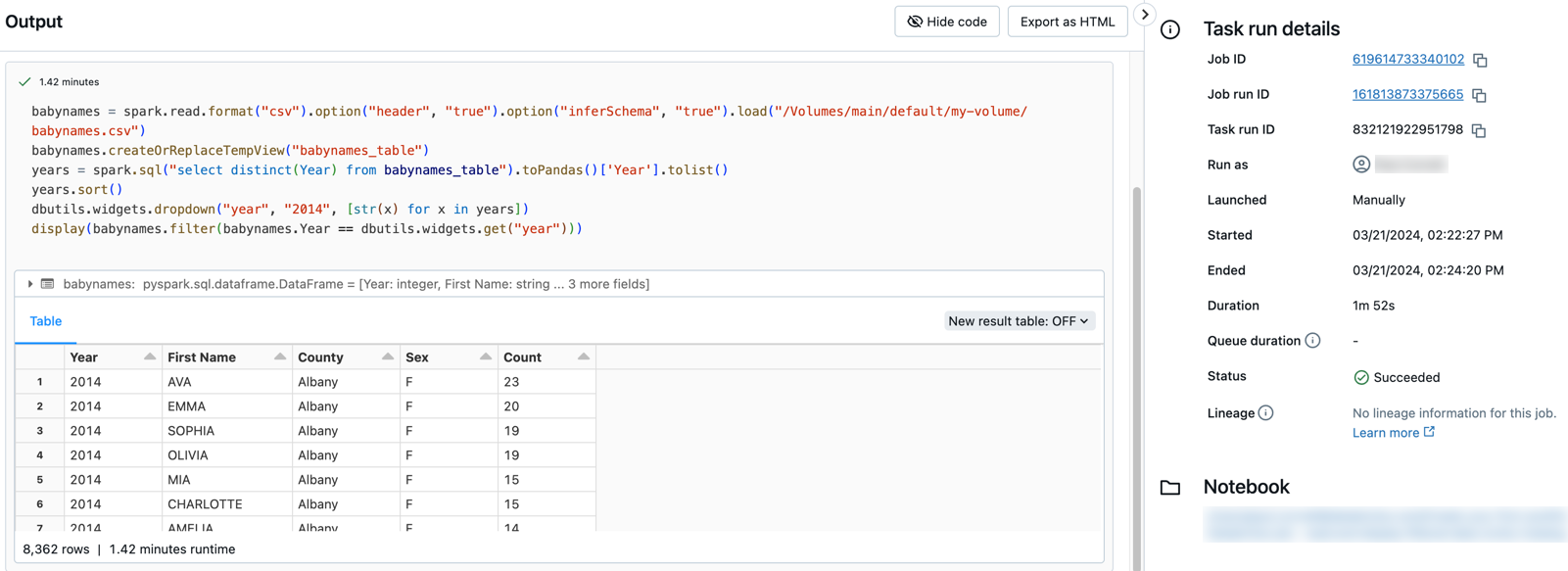
Klicka på någon av aktiviteterna för att se utdata och information. Klicka till exempel på aktiviteten filter-baby-names för att visa utdata och köra information för filteraktiviteten:
Kör med olika parametrar
Så här kör du jobbet igen och filtrerar babynamn under ett annat år:
- Klicka
 bredvid Kör nu och välj Kör nu med olika parametrar eller klicka på Kör nu med olika parametrar i tabellen Aktiva körningar.
bredvid Kör nu och välj Kör nu med olika parametrar eller klicka på Kör nu med olika parametrar i tabellen Aktiva körningar. - I fältet Värde anger du
2015. - Klicka på Kör.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för