Använda Apache Hive som ett ETL-verktyg (Extract, Transform, and Load)
Du behöver vanligtvis rensa och transformera inkommande data innan du läser in dem till ett mål som är lämpligt för analys. Åtgärder för att extrahera, transformera och läsa in (ETL) används för att förbereda data och läsa in dem i ett datamål. Apache Hive på HDInsight kan läsa i ostrukturerade data, bearbeta data efter behov och sedan läsa in data i ett relationsdatalager för beslutsstödsystem. I den här metoden extraheras data från källan. Lagras sedan i anpassningsbar lagring, till exempel Azure Storage-blobar eller Azure Data Lake Storage. Data transformeras sedan med hjälp av en sekvens med Hive-frågor. Mellanlagras sedan i Hive som förberedelse för massinläsning till måldatalagret.
Översikt över användningsfall och modell
Följande bild visar en översikt över användningsfall och modell för ETL-automatisering. Indata transformeras för att generera lämpliga utdata. Under den omvandlingen ändrar data form, datatyp och till och med språk. ETL-processer kan konvertera Imperial till mått, ändra tidszoner och förbättra precisionen så att de stämmer överens med befintliga data i målet. ETL-processer kan också kombinera nya data med befintliga data för att hålla rapporteringen uppdaterad eller för att ge ytterligare insikt i befintliga data. Program som rapporteringsverktyg och tjänster kan sedan använda dessa data i önskat format.
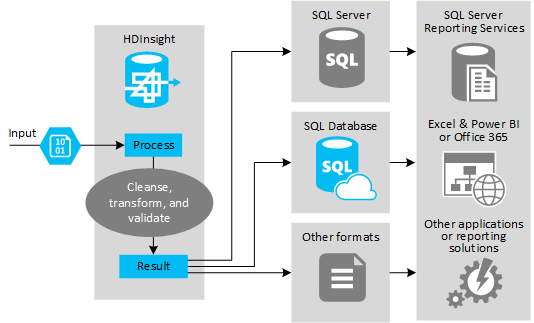
Hadoop används vanligtvis i ETL-processer som importerar antingen ett stort antal textfiler (som CSV:er). Eller ett mindre men ofta föränderligt antal textfiler, eller båda. Hive är ett bra verktyg att använda för att förbereda data innan de läses in i datamålet. Med Hive kan du skapa ett schema över CSV:en och använda ett SQL-liknande språk för att generera MapReduce-program som interagerar med data.
De vanliga stegen för att använda Hive för att utföra ETL är följande:
Läs in data i Azure Data Lake Storage eller Azure Blob Storage.
Skapa en Metadata Store-databas (med Azure SQL Database) för användning av Hive när du lagrar dina scheman.
Skapa ett HDInsight-kluster och anslut datalagret.
Definiera schemat som ska tillämpas vid lästid över data i datalagret:
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';Transformera data och läs in dem till målet. Det finns flera sätt att använda Hive under omvandlingen och inläsningen:
- Fråga efter och förbereda data med Hive och spara dem som en CSV i Azure Data Lake Storage eller Azure Blob Storage. Använd sedan ett verktyg som SQL Server Integration Services (SSIS) för att hämta dessa CSV:er och läsa in data i en målrelationsdatabas, till exempel SQL Server.
- Fråga data direkt från Excel eller C# med hive ODBC-drivrutinen.
- Använd Apache Sqoop för att läsa de förberedda flata CSV-filerna och läsa in dem i målrelationsdatabasen.
Datakällor
Datakällor är vanligtvis externa data som kan matchas mot befintliga data i ditt datalager, till exempel:
- Sociala mediedata, loggfiler, sensorer och program som genererar datafiler.
- Datauppsättningar som hämtas från dataleverantörer, till exempel väderstatistik eller leverantörsförsäljningsnummer.
- Strömmande data som samlas in, filtreras och bearbetas via ett lämpligt verktyg eller ramverk.
Utdatamål
Du kan använda Hive för att mata ut data till olika typer av mål, inklusive:
- En relationsdatabas, till exempel SQL Server eller Azure SQL Database.
- Ett informationslager, till exempel Azure Synapse Analytics.
- Excel.
- Azure-tabell och bloblagring.
- Program eller tjänster som kräver att data bearbetas i specifika format eller som filer som innehåller specifika typer av informationsstruktur.
- Ett JSON-dokumentarkiv som Azure Cosmos DB.
Att tänka på
ETL-modellen används vanligtvis när du vill:
* Läs in dataström eller stora volymer halvstrukturerade eller ostrukturerade data från externa källor till en befintlig databas eller ett befintligt informationssystem.
* Rensa, transformera och verifiera data innan de läses in, kanske genom att använda mer än en transformering genom klustret.
* Generera rapporter och visualiseringar som uppdateras regelbundet. Om rapporten till exempel tar för lång tid att generera under dagen kan du schemalägga rapporten så att den körs på natten. Om du vill köra en Hive-fråga automatiskt kan du använda Azure Logic Apps och PowerShell.
Om målet för data inte är en databas kan du generera en fil i lämpligt format i frågan, till exempel en CSV. Den här filen kan sedan importeras till Excel eller Power BI.
Om du behöver köra flera åtgärder på data som en del av ETL-processen bör du överväga hur du hanterar dem. Med åtgärder som styrs av ett externt program, i stället för som ett arbetsflöde i lösningen, avgör du om vissa åtgärder kan köras parallellt. Och för att identifiera när varje jobb slutförs. Det kan vara enklare att använda en arbetsflödesmekanism som Oozie i Hadoop än att försöka samordna en sekvens med åtgärder med hjälp av externa skript eller anpassade program.