Felsöka Apache Spark-jobb som körs i Azure HDInsight
I den här artikeln får du lära dig hur du spårar och felsöker Apache Spark-jobb som körs i HDInsight-kluster. Felsöka med apache Hadoop YARN-användargränssnittet, Spark-användargränssnittet och Spark-historikservern. Du startar ett Spark-jobb med en notebook-fil som är tillgänglig med Spark-klustret Machine learning: Predictive analysis on food inspection data using MLLib. Följ stegen nedan för att spåra ett program som du skickade med någon annan metod, till exempel spark-submit.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
Ett Apache Spark-kluster i HDInsight. Anvisningar finns i Skapa Apache Spark-kluster i Azure HDInsight.
Du borde ha börjat köra notebook-filen Machine Learning: Predictive analysis on food inspection data using MLLib (Förutsägande analys av matinspektionsdata med MLLib). Anvisningar om hur du kör den här notebook-filen finns på länken.
Spåra ett program i YARN-användargränssnittet
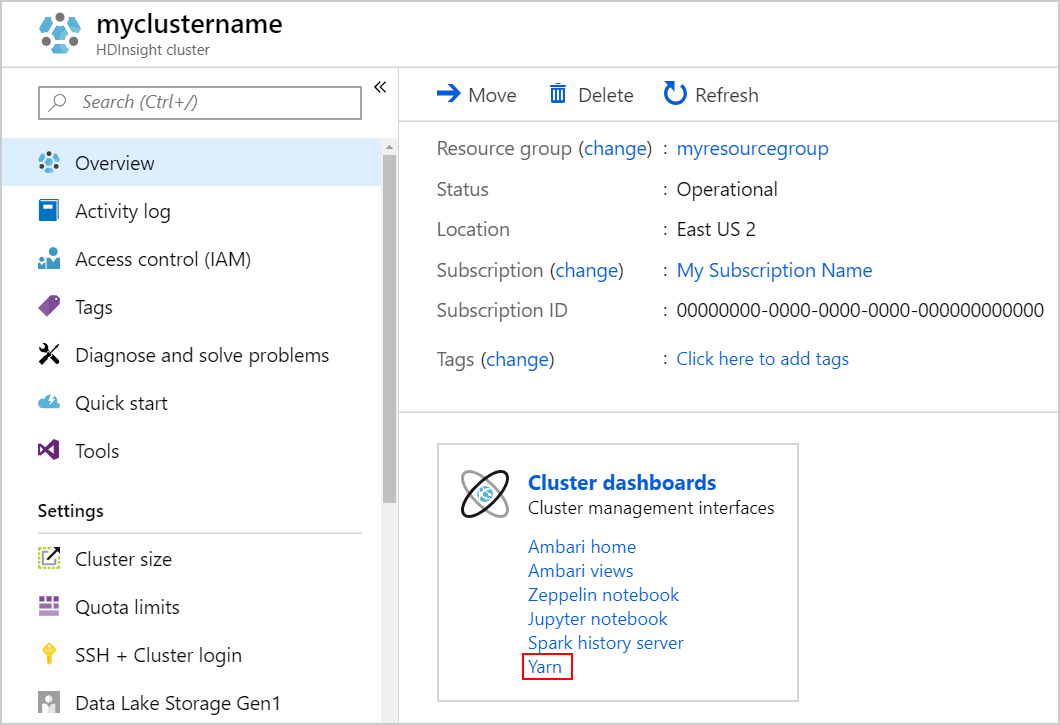
Starta YARN-användargränssnittet. Välj Yarn under Klusterinstrumentpaneler.
Dricks
Du kan också starta YARN-användargränssnittet från Ambari-användargränssnittet. Om du vill starta Ambari-användargränssnittet väljer du Ambari home under Klusterinstrumentpaneler. Från Ambari-användargränssnittet går du till YARN>Snabblänkar> det aktiva Resource Manager >Resource Manager-användargränssnittet.
Eftersom du startade Spark-jobbet med Jupyter Notebooks har programmet namnet remotesparkmagics (namnet för alla program som startats från notebook-filerna). Välj program-ID:t mot programnamnet för att få mer information om jobbet. Den här åtgärden startar programvyn.
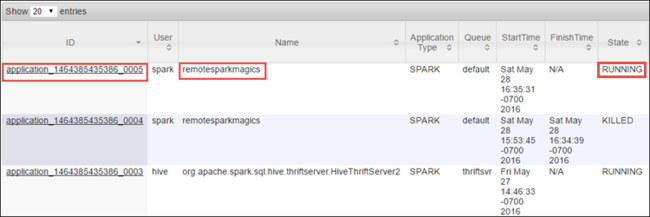
För sådana program som startas från Jupyter Notebooks körs statusen alltid tills du avslutar notebook-filen.
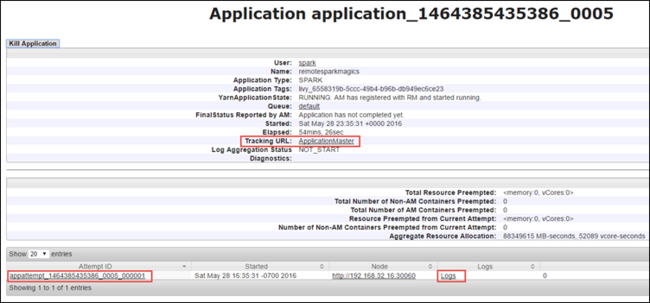
Från programvyn kan du öka detaljnivån ytterligare för att ta reda på de containrar som är associerade med programmet och loggarna (stdout/stderr). Du kan också starta Spark-användargränssnittet genom att klicka på länken som motsvarar spårnings-URL :en enligt nedan.
Spåra ett program i Spark-användargränssnittet
I Spark-användargränssnittet kan du öka detaljnivån i Spark-jobben som skapas av programmet som du startade tidigare.
Om du vill starta Spark-användargränssnittet från programvyn väljer du länken mot spårnings-URL :en, som du ser i skärmdumpen ovan. Du kan se alla Spark-jobb som startas av programmet som körs i Jupyter Notebook.
Välj fliken Köre för att se bearbetnings- och lagringsinformation för varje köre. Du kan också hämta anropsstacken genom att välja länken Tråddump .
Välj fliken Faser för att se de faser som är associerade med programmet.
Varje steg kan ha flera uppgifter som du kan visa körningsstatistik för, som du ser nedan.
På sidan med sceninformation kan du starta DAG Visualisering. Expandera länken DAG Visualisering överst på sidan, enligt nedan.
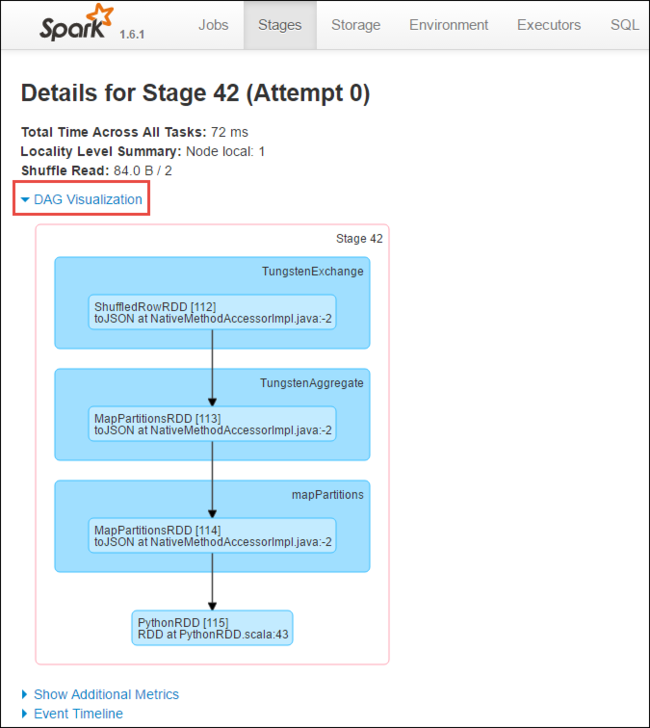
DAG eller Direct Aclyic Graph representerar de olika stegen i programmet. Varje blå ruta i diagrammet representerar en Spark-åtgärd som anropas från programmet.
På sidan med sceninformation kan du även starta tidslinjevyn för programmet. Expandera länken Händelsetidslinje överst på sidan enligt nedan.
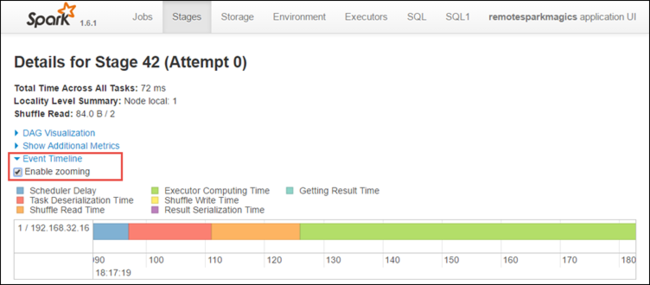
Den här bilden visar Spark-händelserna i form av en tidslinje. Tidslinjevyn är tillgänglig på tre nivåer, mellan jobb, inom ett jobb och inom en fas. Bilden ovan fångar tidslinjevyn för en viss fas.
Dricks
Om du markerar kryssrutan Aktivera zoomning kan du rulla åt vänster och höger i tidslinjevyn.
Andra flikar i Spark-användargränssnittet ger även användbar information om Spark-instansen.
- Fliken Lagring – Om ditt program skapar en RDD hittar du information på fliken Lagring.
- Fliken Miljö – Den här fliken innehåller användbar information om din Spark-instans, till exempel:
- Scala-version
- Händelseloggkatalog som är associerad med klustret
- Antal körkärnor för programmet
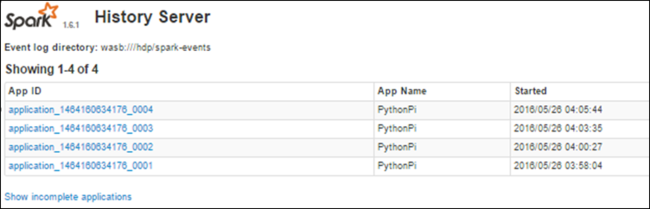
Hitta information om slutförda jobb med Spark-historikservern
När ett jobb har slutförts sparas informationen om jobbet i Spark-historikservern.
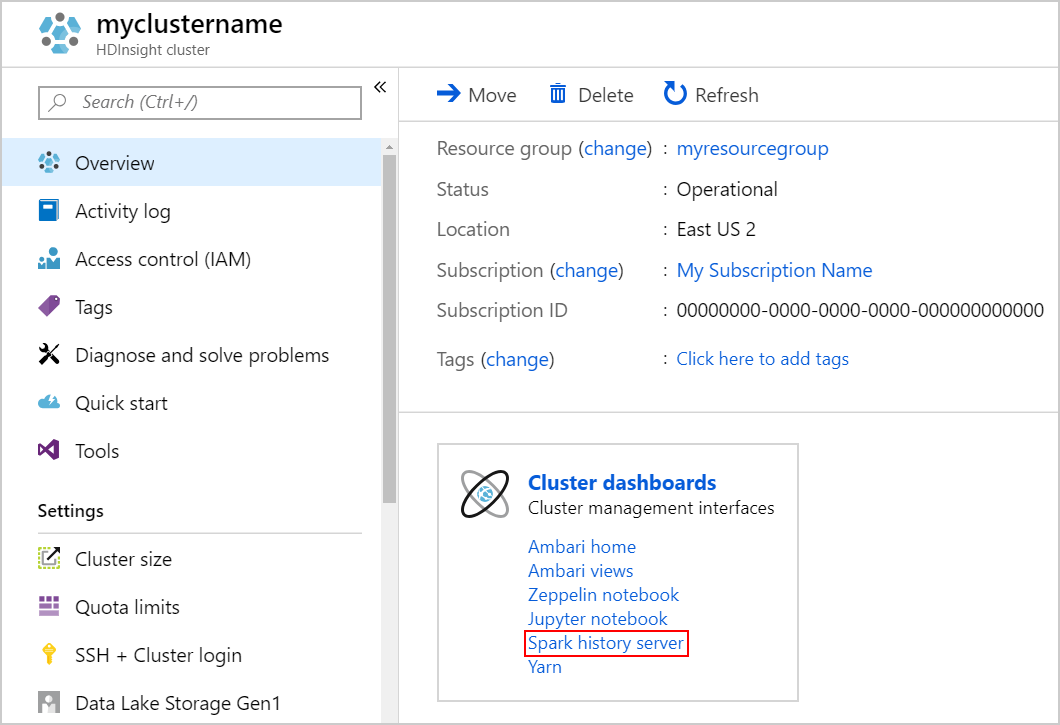
Om du vill starta Spark-historikservern går du till sidan Översikt och väljer Spark-historikserver under Klusterinstrumentpaneler.
Dricks
Du kan också starta Spark History Server-användargränssnittet från Ambari-användargränssnittet. Om du vill starta Ambari-användargränssnittet går du till bladet Översikt och väljer Ambari home under Klusterinstrumentpaneler. Från Ambari-användargränssnittet går du till Spark2>Quick Links>Spark2 History Server UI.
Du ser alla slutförda program i listan. Välj ett program-ID för att öka detaljnivån i ett program för mer information.