Koppla data
Den här artikeln beskriver hur du använder komponenten Join Data i Azure Machine Learning-designern för att sammanfoga två datauppsättningar med hjälp av en kopplingsåtgärd i databasformat.
Så här konfigurerar du kopplingsdata
Om du vill utföra en koppling på två datauppsättningar bör de vara relaterade till en nyckelkolumn. Sammansatta nycklar som använder flera kolumner stöds också.
Lägg till de datauppsättningar som du vill kombinera och dra sedan komponenten Join Data (Koppla data ) till din pipeline.
Du hittar komponenten i kategorin Datatransformering under Manipulation.
Anslut datauppsättningarna till komponenten Join Data (Koppla data ).
Välj Starta kolumnväljaren för att välja nyckelkolumner. Kom ihåg att välja kolumner för både vänster och höger indata.
För en enda nyckel:
Välj en enda nyckelkolumn för båda indata.
För en sammansatt nyckel:
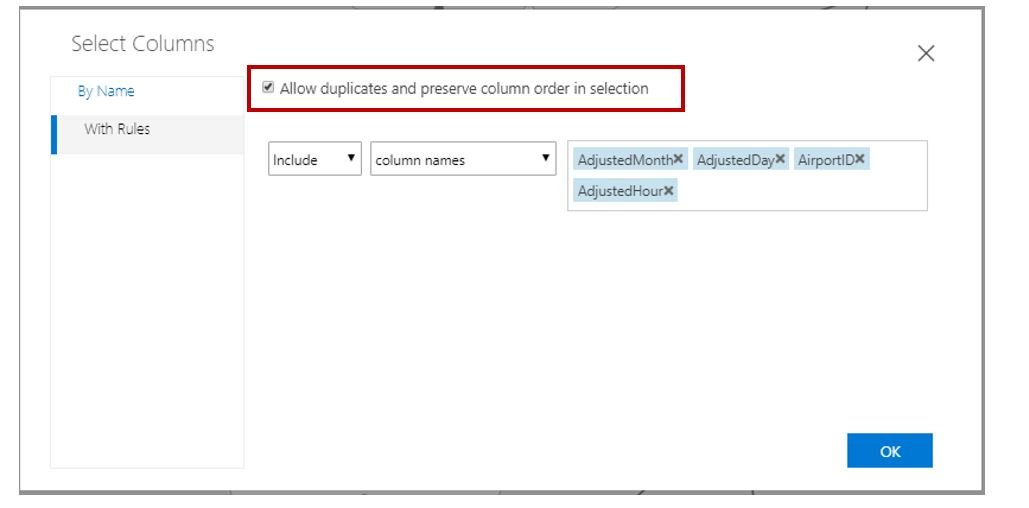
Markera alla nyckelkolumner från vänster indata och höger indata i samma ordning. Komponenten Join Data ansluter tabellerna när alla nyckelkolumner matchar. Markera alternativet Tillåt dubbletter och bevara kolumnordningen om kolumnordningen inte är samma som den ursprungliga tabellen.
Välj alternativet Matcha skiftläge om du vill bevara skiftlägeskänsligheten för en textkolumnkoppling.
Använd listrutan Kopplingstyp för att ange hur datauppsättningarna ska kombineras.
Inre koppling: En inre koppling är den vanligaste kopplingsåtgärden. Den returnerar endast de kombinerade raderna när värdena för nyckelkolumnerna matchar.
Vänster yttre koppling: En vänster yttre koppling returnerar kopplade rader för alla rader från den vänstra tabellen. När en rad i den vänstra tabellen inte har några matchande rader i den högra tabellen innehåller den returnerade raden saknade värden för alla kolumner som kommer från den högra tabellen. Du kan också ange ett ersättningsvärde för saknade värden.
Fullständig yttre koppling: En fullständig yttre koppling returnerar alla rader från den vänstra tabellen (table1) och från den högra tabellen (table2).
För var och en av raderna i någon av tabellerna som inte har några matchande rader i den andra innehåller resultatet en rad som innehåller saknade värden.
Vänster halvkoppling: En vänster halvkoppling returnerar bara värdena från den vänstra tabellen när värdena för nyckelkolumnerna matchar.
För alternativet Behåll höger nyckelkolumner i den kopplade tabellen:
- Välj det här alternativet om du vill visa nycklarna från båda indatatabellerna.
- Avmarkera om du bara vill returnera nyckelkolumnerna från den vänstra inmatningen.
Skicka pipelinen.
Om du vill visa resultatet högerklickar du på Anslut till data och väljer Visualisera.
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Machine Learning.