Förbearbeta text
I den här artikeln beskrivs en komponent i Azure Machine Learning-designern.
Använd komponenten Preprocess Text för att rensa och förenkla text. Den stöder dessa vanliga textbearbetningsåtgärder:
- Borttagning av stoppord
- Använda reguljära uttryck för att söka efter och ersätta specifika målsträngar
- Lemmatisering, som konverterar flera relaterade ord till en enda kanonisk form
- Skiftlägesnormalisering
- Borttagning av vissa teckenklasser, till exempel siffror, specialtecken och sekvenser med upprepade tecken, till exempel "aaaa"
- Identifiering och borttagning av e-postmeddelanden och URL:er
Förbearbetningstextkomponenten stöder för närvarande endast engelska.
Konfigurera förbearbetning av text
Lägg till komponenten Preprocess Text i din pipeline i Azure Machine Learning. Du hittar den här komponenten under Textanalys.
Anslut en datauppsättning som har minst en kolumn som innehåller text.
Välj språk i listrutan Språk .
Textkolumn som ska rensas: Välj den kolumn som du vill förbearbeta.
Ta bort stoppord: Välj det här alternativet om du vill använda en fördefinierad stoppordslista i textkolumnen.
Stoppordslistor är språkberoende och anpassningsbara.
Lemmatisering: Välj det här alternativet om du vill att ord ska representeras i kanonisk form. Det här alternativet är användbart för att minska antalet unika förekomster av annars liknande texttoken.
Lemmatiseringsprocessen är mycket språkberoende.
Identifiera meningar: Välj det här alternativet om du vill att komponenten ska infoga en meningsgränsmarkering vid analys.
Den här komponenten använder en serie med tre vertikalstreck
|||för att representera meningsavgränsaren.Utför valfria sök-och-ersätt-åtgärder med hjälp av reguljära uttryck. Det reguljära uttrycket bearbetas först, före alla andra inbyggda alternativ.
- Anpassat reguljärt uttryck: Definiera den text som du söker efter.
- Anpassad ersättningssträng: Definiera ett enda ersättningsvärde.
Normalisera skiftläge till gemener: Välj det här alternativet om du vill konvertera ASCII-versaler till deras gemener.
Om tecknen inte normaliseras betraktas samma ord i versaler och gemener som två olika ord.
Du kan också ta bort följande typer av tecken eller teckensekvenser från den bearbetade utdatatexten:
Ta bort tal: Välj det här alternativet om du vill ta bort alla numeriska tecken för det angivna språket. Identifieringsnummer är domänberoende och språkberoende. Om numeriska tecken är en integrerad del av ett känt ord kanske talet inte tas bort. Läs mer i Tekniska anteckningar.
Ta bort specialtecken: Använd det här alternativet om du vill ta bort icke-alfanumeriska specialtecken.
Ta bort dubbletttecken: Välj det här alternativet om du vill ta bort extra tecken i sekvenser som upprepas i mer än två gånger. Till exempel skulle en sekvens som "aaaaaa" reduceras till "aa".
Ta bort e-postadresser: Välj det här alternativet om du vill ta bort alla sekvenser i formatet
<string>@<string>.Ta bort URL:er: Välj det här alternativet om du vill ta bort sekvenser som innehåller följande URL-prefix:
http,https,ftp,www
Expandera verbkontraktioner: Det här alternativet gäller endast för språk som använder verbkontraktioner; för närvarande endast engelska.
Om du till exempel väljer det här alternativet kan du ersätta frasen "skulle inte stanna där" med "skulle inte stanna där".
Normalisera omvända snedstreck till snedstreck: Välj det här alternativet om du vill mappa alla instanser av
\\till/.Dela token för specialtecken: Välj det här alternativet om du vill dela upp ord på tecken som
&,-och så vidare. Det här alternativet kan också minska specialtecken när det upprepas mer än två gånger.Strängen
MS---WORDskulle till exempel delas upp i tre token,MS,-ochWORD.Skicka pipelinen.
Tekniska anteckningar
Komponenten preprocess-text i Studio (klassisk) och designer använder olika språkmodeller. Designern använder en CNN-tränad modell med flera uppgifter från spaCy. Olika modeller ger olika tokenizer och en del av tal-tagger, vilket leder till olika resultat.
Här följer några exempel:
| Konfiguration | Utdataresultat |
|---|---|
| När alla alternativ har valts Förklaring: För fall som "3test" i "WC-3 3test 4test" tar designern bort hela ordet "3test", eftersom komponenten i den här kontexten anger den här token "3test" som siffror, och enligt deltal tar komponenten bort den. |
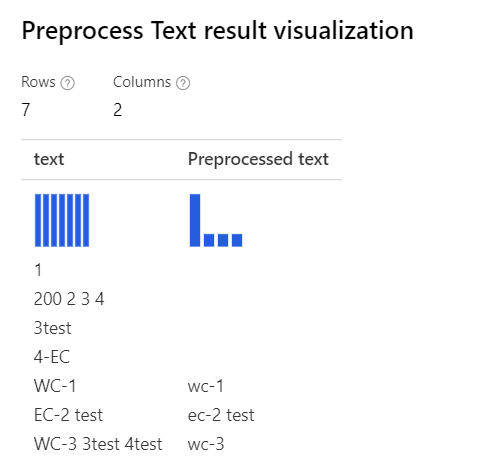
|
Med endast Removing number vald förklaring: För fall som "3test", "4-EC" delar inte designertokeniserardosen upp dessa fall och behandlar dem som hela token. Så det tar inte bort talen med dessa ord. |

|
Du kan också använda reguljära uttryck för att mata ut anpassade resultat:
| Konfiguration | Utdataresultat |
|---|---|
| Med alla alternativ markerade Anpassade reguljära uttryck: (\s+)*(-|\d+)(\s+)*Anpassad ersättningssträng: \1 \2 \3 |

|
Med endast Removing number valt Anpassat reguljärt uttryck: (\s+)*(-|\d+)(\s+)*Anpassad ersättningssträng: \1 \2 \3 |
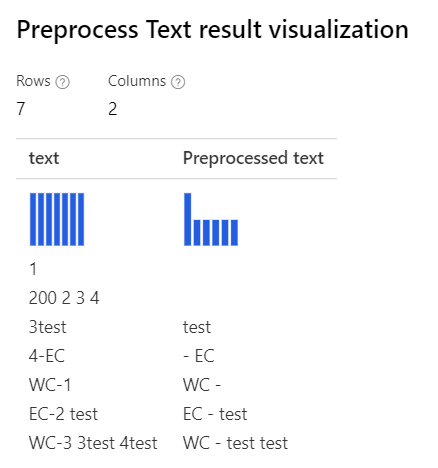
|
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Machine Learning.