Filterbaserat funktionsval
I den här artikeln beskrivs hur du använder komponenten Filterbaserad funktionsval i Azure Machine Learning-designern. Den här komponenten hjälper dig att identifiera de kolumner i din indatauppsättning som har störst förutsägelsekraft.
I allmänhet syftar funktionsval på processen att tillämpa statistiska tester på indata, givet en angiven utdata. Målet är att avgöra vilka kolumner som är mer förutsägande för utdata. Komponenten Filterbaserad funktionsval innehåller flera algoritmer för funktionsval att välja mellan. Komponenten innehåller korrelationsmetoder som Pearson-korrelation och chi2-värden.
När du använder komponenten Filterbaserad funktionsval anger du en datauppsättning och identifierar kolumnen som innehåller etiketten eller den beroende variabeln. Sedan anger du en enda metod som ska användas för att mäta funktionsvikt.
Komponenten matar ut en datauppsättning som innehåller de bästa funktionskolumnerna, rangordnade efter förutsägelsekraft. Den matar också ut namnen på funktionerna och deras poäng från det valda måttet.
Vad filterbaserad funktionsval är
Den här komponenten för funktionsval kallas "filterbaserad" eftersom du använder det valda måttet för att hitta irrelevanta attribut. Sedan filtrerar du bort redundanta kolumner från din modell. Du väljer ett enda statistiskt mått som passar dina data och komponenten beräknar en poäng för varje funktionskolumn. Kolumnerna returneras rangordnade efter deras funktionspoäng.
Genom att välja rätt funktioner kan du förbättra klassificeringens noggrannhet och effektivitet.
Du använder vanligtvis bara kolumnerna med de bästa poängen för att skapa din förutsägelsemodell. Kolumner med dåliga resultat för funktionsval kan lämnas i datauppsättningen och ignoreras när du skapar en modell.
Så här väljer du ett mått för funktionsval
Komponenten Filter-Based Funktionsval innehåller en mängd olika mått för att utvärdera informationsvärdet i varje kolumn. Det här avsnittet innehåller en allmän beskrivning av varje mått och hur det tillämpas. Du hittar ytterligare krav för att använda varje mått i de tekniska anteckningarna och i anvisningarna för att konfigurera varje komponent.
Pearson-korrelation
Pearsons korrelationsstatistik, eller Pearsons korrelationskoefficient, är också känd i statistiska modeller som
rvärdet. För två variabler returneras ett värde som anger korrelationens styrka.Pearsons korrelationskoefficient beräknas genom att ta kovariansen för två variabler och dividera med produkten av deras standardavvikelser. Skalningsändringar i de två variablerna påverkar inte koefficienten.
Chi i kvadrat
Tvåvägs chi2-testet är en statistisk metod som mäter hur nära förväntade värden är för faktiska resultat. Metoden förutsätter att variabler är slumpmässiga och hämtas från ett adekvat urval av oberoende variabler. Den resulterande chi2-statistiken anger hur långt resultatet är från det förväntade (slumpmässiga) resultatet.
Tips
Om du behöver ett annat alternativ för den anpassade funktionsvalsmetoden använder du komponenten Execute R Script (Kör R-skript ).
Så här konfigurerar du Filter-Based funktionsval
Du väljer ett statistiskt standardmått. Komponenten beräknar korrelationen mellan ett par kolumner: etikettkolumnen och en funktionskolumn.
Lägg till komponenten Filter-Based Funktionsval i pipelinen. Du hittar den i kategorin Funktionsval i designern.
Anslut en indatauppsättning som innehåller minst två kolumner som är potentiella funktioner.
För att säkerställa att en kolumn analyseras och en funktionspoäng genereras använder du komponenten Redigera metadata för att ange Attributet IsFeature .
Viktigt
Se till att de kolumner som du anger som indata är potentiella funktioner. Till exempel har en kolumn som innehåller ett enda värde inget informationsvärde.
Om du vet att vissa kolumner skulle göra felaktiga funktioner kan du ta bort dem från kolumnmarkeringen. Du kan också använda komponenten Redigera metadata för att flagga dem som kategoriska.
För Funktionsbedömningsmetod väljer du någon av följande etablerade statistiska metoder som ska användas vid beräkning av poäng.
Metod Krav Pearson-korrelation Etiketten kan vara text eller numerisk. Funktionerna måste vara numeriska. Chi i kvadrat Etiketter och funktioner kan vara text eller numeriska. Använd den här metoden för att beräkna funktionsvikt för två kategoriska kolumner. Tips
Om du ändrar det valda måttet återställs alla andra val. Så se till att ange det här alternativet först.
Välj alternativet Använd endast funktionskolumner för att generera en poäng endast för kolumner som tidigare har markerats som funktioner.
Om du avmarkerar det här alternativet skapar komponenten en poäng för alla kolumner som annars uppfyller kriterierna, upp till det antal kolumner som anges i Antal önskade funktioner.
För Målkolumn väljer du Starta kolumnväljaren för att välja etikettkolumnen antingen efter namn eller efter dess index. (Index är enbaserade.)
En etikettkolumn krävs för alla metoder som inbegriper statistisk korrelation. Komponenten returnerar ett designtidsfel om du inte väljer någon etikettkolumn eller flera etikettkolumner.För Antal önskade funktioner anger du antalet funktionskolumner som du vill ska returneras som ett resultat:
Det minsta antalet funktioner som du kan ange är en, men vi rekommenderar att du ökar det här värdet.
Om det angivna antalet önskade funktioner är större än antalet kolumner i datauppsättningen returneras alla funktioner. Även funktioner med noll poäng returneras.
Om du anger färre resultatkolumner än det finns funktionskolumner rangordnas funktionerna efter fallande poäng. Endast de viktigaste funktionerna returneras.
Skicka pipelinen.
Viktigt
Om du ska använda filterbaserad funktionsval i slutsatsdragningen måste du använda Transformera välj kolumner för att lagra det valda resultatet och Tillämpa transformering för att tillämpa den valda funktionens transformering på bedömningsdatauppsättningen.
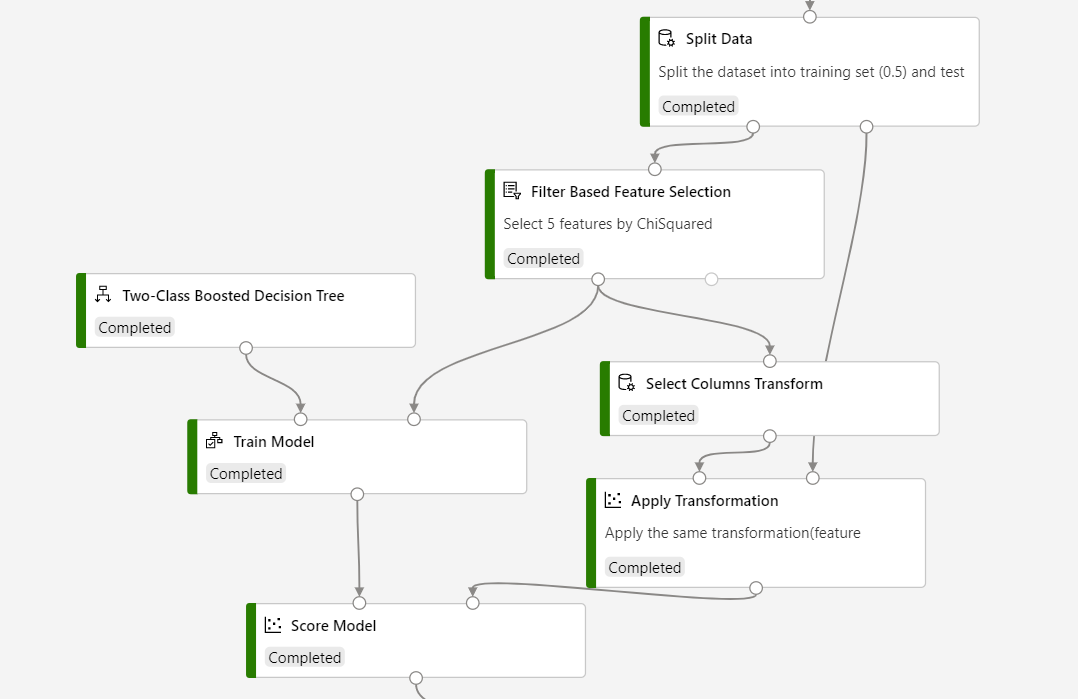
Se följande skärmbild för att skapa din pipeline för att se till att kolumnvalen är desamma för bedömningsprocessen.
Resultat
När bearbetningen är klar:
Om du vill se en fullständig lista över de analyserade funktionskolumnerna och deras resultat högerklickar du på komponenten och väljer Visualisera.
Om du vill visa datauppsättningen baserat på dina kriterier för funktionsval högerklickar du på komponenten och väljer Visualisera.
Om datauppsättningen innehåller färre kolumner än förväntat kontrollerar du komponentinställningarna. Kontrollera även datatyperna för kolumnerna som anges som indata. Om du till exempel anger Antal önskade funktioner till 1 innehåller utdatauppsättningen bara två kolumner: etikettkolumnen och den mest rankade funktionskolumnen.
Tekniska anteckningar
Implementeringsdetaljer
Om du använder Pearson-korrelation för en numerisk funktion och en kategorisk etikett beräknas funktionspoängen på följande sätt:
För varje nivå i den kategoriska kolumnen beräknar du det villkorsstyrda medelvärdet av den numeriska kolumnen.
Korrelera kolumnen för villkorsstyrda medel med den numeriska kolumnen.
Krav
Det går inte att generera en funktionsmarkeringspoäng för en kolumn som har angetts som en etikett eller poängkolumn .
Om du försöker använda en bedömningsmetod med en kolumn av en datatyp som metoden inte stöder, utlöser komponenten ett fel. Eller så tilldelas en nollpoäng till kolumnen.
Om en kolumn innehåller logiska (sant/falskt) värden bearbetas de som
True = 1ochFalse = 0.En kolumn kan inte vara en funktion om den har utsetts till en etikett eller en poäng.
Hur saknade värden hanteras
Du kan inte ange en kolumn som innehåller alla saknade värden som målkolumn (etikett).
Om en kolumn innehåller saknade värden ignorerar komponenten dem när den beräknar poängen för kolumnen.
Om en kolumn som har angetts som en funktionskolumn har alla saknade värden tilldelar komponenten noll poäng.
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Machine Learning.