Normalisera datakomponent
Den här artikeln beskriver en komponent i Azure Machine Learning-designern.
Använd den här komponenten för att transformera en datauppsättning genom normalisering.
Normalisering är en teknik som ofta används som en del av förberedelsen av data för maskininlärning. Målet med normaliseringen är att ändra värdena för numeriska kolumner i datauppsättningen så att de använder en gemensam skala, utan att förvränga skillnaderna i värdenas intervall eller förlora information. Normalisering krävs också för att vissa algoritmer ska kunna modellera data korrekt.
Anta till exempel att din indatauppsättning innehåller en kolumn med värden mellan 0 och 1 och en annan kolumn med värden mellan 10 000 och 100 000. Den stora skillnaden i siffrornas skala kan orsaka problem när du försöker kombinera värdena som funktioner under modellering.
Normalisering undviker dessa problem genom att skapa nya värden som upprätthåller den allmänna fördelningen och förhållandet i källdata, samtidigt som värden i en skala som tillämpas på alla numeriska kolumner som används i modellen bevaras.
Den här komponenten erbjuder flera alternativ för att transformera numeriska data:
- Du kan ändra alla värden till en skala mellan 0 och 1 eller transformera värdena genom att representera dem som percentilrankning snarare än absoluta värden.
- Du kan tillämpa normalisering på en enda kolumn eller på flera kolumner i samma datauppsättning.
- Om du behöver upprepa pipelinen eller tillämpa samma normaliseringssteg på andra data kan du spara stegen som en normaliseringstransformering och tillämpa den på andra datauppsättningar som har samma schema.
Varning
Vissa algoritmer kräver att data normaliseras innan en modell tränas. Andra algoritmer utför sin egen dataskalning eller normalisering. När du väljer en maskininlärningsalgoritm som ska användas för att skapa en förutsägelsemodell bör du därför granska datakraven för algoritmen innan du tillämpar normalisering på träningsdata.
Konfigurera Normalisera data
Du kan bara använda en normaliseringsmetod i taget med den här komponenten. Därför tillämpas samma normaliseringsmetod på alla kolumner som du väljer. Om du vill använda olika normaliseringsmetoder använder du en andra instans av Normalisera data.
Lägg till komponenten Normalize Data (Normalisera data ) i pipelinen. Du hittar komponenten I Azure Machine Learning, under Datatransformering, i kategorin Skala och minska .
Anslut en datauppsättning som innehåller minst en kolumn med alla tal.
Använd kolumnväljaren för att välja de numeriska kolumner som ska normaliseras. Om du inte väljer enskilda kolumner inkluderas som standard alla kolumner av numerisk typ i indata och samma normaliseringsprocess tillämpas på alla markerade kolumner.
Detta kan leda till konstiga resultat om du inkluderar numeriska kolumner som inte bör normaliseras! Kontrollera alltid kolumnerna noggrant.
Om inga numeriska kolumner identifieras kontrollerar du kolumnmetadata för att kontrollera att datatypen för kolumnen är en numerisk typ som stöds.
Tips
Om du vill se till att kolumner av en viss typ tillhandahålls som indata kan du prova att använda komponenten Välj kolumner i datauppsättning innan du normaliserar data.
Använd 0 för konstanta kolumner när det är markerat: Välj det här alternativet när en numerisk kolumn innehåller ett enda oförändrat värde. Detta säkerställer att sådana kolumner inte används i normaliseringsåtgärder.
I listrutan Transformeringsmetod väljer du en enda matematisk funktion som ska tillämpas på alla valda kolumner.
Zscore: Konverterar alla värden till en z-score.
Värdena i kolumnen transformeras med hjälp av följande formel:
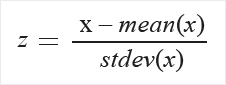
Medelvärde och standardavvikelse beräknas för varje kolumn separat. Populationens standardavvikelse används.
MinMax: Normaliseraren min-max linjärt omskalar varje funktion till intervallet [0,1].
Omskalning till intervallet [0,1] görs genom att flytta värdena för varje funktion så att det minimala värdet är 0 och sedan dividera med det nya maximala värdet (vilket är skillnaden mellan de ursprungliga maximala och minimala värdena).
Värdena i kolumnen transformeras med hjälp av följande formel:

Logistik: Värdena i kolumnen transformeras med hjälp av följande formel:

LogNormal: Det här alternativet konverterar alla värden till en lognormal skala.
Värdena i kolumnen transformeras med hjälp av följande formel:

Här μ och σ är parametrarna för fördelningen, beräknade empiriskt från data som maximal sannolikhetsuppskattningar, för varje kolumn separat.
TanH: Alla värden konverteras till en hyperbolisk tangens.
Värdena i kolumnen transformeras med hjälp av följande formel:

Skicka pipelinen eller dubbelklicka på komponenten Normalisera data och välj Kör vald.
Resultat
Komponenten Normalize Data genererar två utdata:
Om du vill visa transformerade värden högerklickar du på komponenten och väljer Visualisera.
Som standard transformeras värden på plats. Om du vill jämföra transformerade värden med de ursprungliga värdena använder du komponenten Lägg till kolumner för att rekombinera datauppsättningarna och visa kolumnerna sida vid sida.
Om du vill spara omvandlingen så att du kan använda samma normaliseringsmetod för en annan datauppsättning väljer du komponenten och väljer Registrera datauppsättning under fliken Utdata på den högra panelen.
Du kan sedan läsa in de sparade omvandlingarna från gruppen Transformeringar i det vänstra navigeringsfönstret och tillämpa dem på en datauppsättning med samma schema med hjälp av Tillämpa transformering.
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Machine Learning.