Fulltextsökning i Azure AI Search
Fulltextsökning är en metod för informationshämtning som matchar oformaterad text som lagras i ett index. Till exempel, med tanke på en frågesträng "hotell i San Diego på stranden", söker sökmotorn efter tokeniserade strängar baserat på dessa termer. För att göra genomsökningar mer effektiva genomgår frågesträngar lexikal analys: lägre hölje för alla termer, borttagning av stoppord som "the" och minskning av termer till primitiva rotformulär. När matchande termer hittas hämtar sökmotorn dokument, rangordnar dem efter relevans och returnerar de högsta resultaten.
Frågekörning kan vara komplext. Den här artikeln är avsedd för utvecklare som behöver en djupare förståelse för hur fulltextsökning fungerar i Azure AI Search. För textfrågor levererar Azure AI Search sömlöst förväntade resultat i de flesta scenarier, men ibland kan du få ett resultat som verkar "av" på något sätt. I dessa situationer kan en bakgrund i de fyra stegen i Lucene-frågekörningen (frågeparsing, lexikal analys, dokumentmatchning, bedömning) hjälpa dig att identifiera specifika ändringar i frågeparametrar eller indexkonfiguration som ger önskat resultat.
Kommentar
Azure AI Search använder Apache Lucene för fulltextsökning, men Lucene-integreringen är inte fullständig. Vi exponerar och utökar lucene-funktioner selektivt för att aktivera scenarier som är viktiga för Azure AI Search.
Arkitekturöversikt och diagram
Frågekörningen har fyra steg:
- Frågeparsning
- Lexikal analys
- Dokumenthämtning
- Resultat
En fulltextsökningsfråga börjar med att parsa frågetexten för att extrahera söktermer och operatorer. Det finns två parsers så att du kan välja mellan hastighet och komplexitet. En analysfas är nästa, där enskilda frågetermer ibland delas upp och återskapas i nya formulär. Det här steget hjälper till att kasta ett bredare nät över vad som kan betraktas som en potentiell matchning. Sökmotorn söker sedan igenom indexet för att hitta dokument med matchande termer och poäng varje matchning. En resultatuppsättning sorteras sedan efter en relevanspoäng som tilldelas varje enskilt matchande dokument. De överst i den rankade listan returneras till det anropande programmet.
Diagrammet nedan visar de komponenter som används för att bearbeta en sökbegäran.
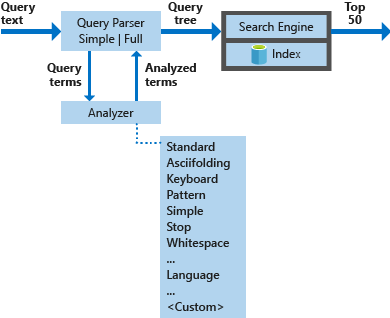
| Nyckelkomponenter | Funktionsbeskrivning |
|---|---|
| Frågeparsers | Avgränsa frågetermer från frågeoperatorer och skapa frågestrukturen (ett frågeträd) som ska skickas till sökmotorn. |
| Analysatorer | Utför lexikal analys på frågetermer. Den här processen kan omfatta transformering, borttagning eller utökning av frågetermer. |
| Index | En effektiv datastruktur som används för att lagra och organisera sökbara termer som extraherats från indexerade dokument. |
| Sökmotor | Hämtar och poängsätter matchande dokument baserat på innehållet i det inverterade indexet. |
Anatomy of a Search Request
En sökbegäran är en fullständig specifikation av vad som ska returneras i en resultatuppsättning. I enklaste form är det en tom fråga utan några kriterier av något slag. Ett mer realistiskt exempel innehåller parametrar, flera frågetermer, kanske begränsade till vissa fält, med eventuellt ett filteruttryck och ordningsregler.
Följande exempel är en sökbegäran som du kan skicka till Azure AI Search med hjälp av REST-API:et.
POST /indexes/hotels/docs/search?api-version=2020-06-30
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
För den här begäran utför sökmotorn följande åtgärder:
Hittar dokument där priset är minst $60 och mindre än $300.
Kör frågan. I det här exemplet består sökfrågan av fraser och termer:
"Spacious, air-condition* +\"Ocean view\""(användare anger vanligtvis inte skiljetecken, men genom att inkludera den i exemplet kan vi förklara hur analysverktyg hanterar den).För den här frågan söker sökmotorn igenom de beskrivnings- och rubrikfält som anges i "searchFields" efter dokument som innehåller
"Ocean view", och dessutom på termen"spacious", eller på termer som börjar med prefixet"air-condition". Parametern "searchMode" används för att matcha på valfri term (standard) eller alla av dem, för fall där en term inte uttryckligen krävs (+).Beställer den resulterande uppsättningen hotell efter närhet till en viss geografisk plats och returnerar sedan resultatet till det anropande programmet.
De flesta den här artikeln handlar om bearbetning av sökfrågan: "Spacious, air-condition* +\"Ocean view\"". Filtrering och ordning ligger utanför omfånget. Mer information finns i sök-API-referensdokumentationen.
Steg 1: Frågeparsing
Som nämnts är frågesträngen den första raden i begäran:
"search": "Spacious, air-condition* +\"Ocean view\"",
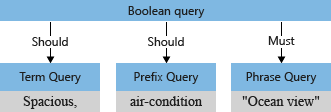
Frågeparsern separerar operatorer (till exempel och + i exemplet) från söktermer och dekonstruerar sökfrågan i underfrågor av en typ som * stöds:
- term query for standalone terms (like spacious)
- frasfråga för citerade termer (till exempel oceanvy)
- prefixfråga för termer följt av en prefixoperator
*(till exempel luftkonditionering)
En fullständig lista över frågetyper som stöds finns i Lucene-frågesyntax
Operatorer som är associerade med en underfråga avgör om frågan "måste vara" eller "ska vara" uppfylld för att ett dokument ska betraktas som en matchning. Till exempel +"Ocean view" är "måste" på grund av operatorn + .
Frågeparsern omstrukturerar underfrågorna till ett frågeträd (en intern struktur som representerar frågan) som den skickar vidare till sökmotorn. I den första fasen av frågeparsing ser frågeträdet ut så här.
Parsers som stöds: Enkel och fullständig Lucene
Azure AI Search exponerar två olika frågespråk( simple standard) och full. Genom att ange parametern queryType med sökbegäran anger du för frågeparsern vilket frågespråk du väljer så att den vet hur operatorerna och syntaxen ska tolkas.
Det enkla frågespråket är intuitivt och robust, ofta lämpligt för att tolka användarindata som det är utan bearbetning på klientsidan. Den stöder frågeoperatorer som är bekanta från webbsökmotorer.
Det fullständiga Lucene-frågespråket, som du får genom att ange
queryType=full, utökar standardspråket enkel fråga genom att lägga till stöd för fler operatorer och frågetyper som jokertecken, fuzzy, regex och fältomfattande frågor. Ett reguljärt uttryck som skickas i Enkel frågesyntax tolkas till exempel som en frågesträng och inte som ett uttryck. Exempelbegäran i den här artikeln använder frågespråket Fullständig Lucene.
Effekten av searchMode på parsern
En annan parameter för sökbegäran som påverkar parsning är parametern "searchMode". Den styr standardoperatorn för booleska frågor: alla (standard) eller alla.
När "searchMode=any", som är standard, är blankstegsavgränsaren mellan rymlig och luftkonditionering OR (||), vilket gör att exempelfrågetexten motsvarar:
Spacious,||air-condition*+"Ocean view"
Explicita operatorer, till exempel + i +"Ocean view", är entydiga i boolesk frågekonstruktion (termen måste matcha). Mindre uppenbart är hur man tolkar de återstående termerna: rymliga och luftkonditionering. Ska sökmotorn hitta matchningar på havsutsikt och rymligt och luftkonditionering? Eller ska den hitta havsutsikt plus någon av de återstående termerna?
Som standard ("searchMode=any" förutsätter sökmotorn den bredare tolkningen. Båda fälten ska matchas, vilket återspeglar "eller" semantik. Det första frågeträdet som illustreras tidigare, med de två "should"-åtgärderna, visar standardvärdet.
Anta att vi nu ställer in "searchMode=all". I det här fallet tolkas utrymmet som en "och"-åtgärd. Var och en av de återstående villkoren måste båda finnas i dokumentet för att kvalificeras som en matchning. Den resulterande exempelfrågan tolkas på följande sätt:
+Spacious,+air-condition*+"Ocean view"
Ett ändrat frågeträd för den här frågan skulle vara följande, där ett matchande dokument är skärningspunkten för alla tre underfrågorna:

Kommentar
Att välja "searchMode=any" framför "searchMode=all" är ett beslut som bäst nås genom att köra representativa frågor. Användare som sannolikt kommer att inkludera operatorer (vanliga när de söker i dokumentarkiv) kan hitta resultat som är mer intuitiva om "searchMode=all" informerar booleska frågekonstruktioner. Mer information om samspelet mellan "searchMode" och operatorer finns i Enkel frågesyntax.
Steg 2: Lexikal analys
Lexikala analysverktyg bearbetar termfrågor och frasfrågor efter att frågeträdet har strukturerats. En analysator accepterar de textindata som ges till den av parsern, bearbetar texten och skickar sedan tillbaka tokeniserade termer som ska införlivas i frågeträdet.
Den vanligaste formen av lexikal analys är *språklig analys som transformerar frågetermer baserat på regler som är specifika för ett visst språk:
- Minska en frågeterm till rotformen för ett ord
- Ta bort icke-väsentliga ord (stoppord, till exempel "" eller "och" på engelska)
- Dela upp ett sammansatt ord i komponentdelar
- Nedre hölje ett versalord
Alla dessa åtgärder tenderar att radera skillnader mellan textindata som tillhandahålls av användaren och de termer som lagras i indexet. Sådana åtgärder går längre än textbearbetning och kräver djupgående kunskaper om själva språket. För att lägga till det här skiktet av språkmedvetenhet stöder Azure AI Search en lång lista över språkanalysverktyg från både Lucene och Microsoft.
Kommentar
Analyskraven kan variera från minimala till avancerade beroende på ditt scenario. Du kan kontrollera komplexiteten i lexikal analys genom att välja en av de fördefinierade analysverktygen eller genom att skapa en egen anpassad analysator. Analysverktyg är begränsade till sökbara fält och anges som en del av en fältdefinition. På så sätt kan du variera lexikal analys per fält. Ospecificerad används lucene-standardanalyseraren .
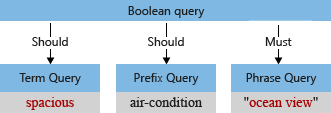
I vårt exempel, före analysen, har det första frågeträdet termen "Spacious", med versaler "S" och ett kommatecken som frågeparsern tolkar som en del av frågetermen (ett kommatecken betraktas inte som en frågespråksoperator).
När standardanalysatorn bearbetar termen kommer den att ge gemener "ocean view" och "spacious" och ta bort kommatecknet. Det ändrade frågeträdet ser ut så här:
Testa analysbeteenden
Beteendet för en analysator kan testas med hjälp av analys-API:et. Ange den text som du vill analysera för att se vilka termer som en given analysator genererar. Om du till exempel vill se hur standardanalysatorn skulle bearbeta texten "luftkonditionering" kan du utfärda följande begäran:
{
"text": "air-condition",
"analyzer": "standard"
}
Standardanalysen delar upp indatatexten i följande två token och kommenterar dem med attribut som start- och slutförskjutningar (används för träffmarkering) samt deras position (används för frasmatchning):
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Undantag till lexikal analys
Lexikal analys gäller endast för frågetyper som kräver fullständiga termer – antingen en termfråga eller en frasfråga. Den gäller inte för frågetyper med ofullständiga termer – prefixfråga, jokerteckenfråga, regex-fråga – eller för en fuzzy-fråga. Dessa frågetyper, inklusive prefixfrågan med termen air-condition* i vårt exempel, läggs till direkt i frågeträdet och kringgår analyssteget. Den enda transformering som utförs på frågetermer för dessa typer är att sänka.
Steg 3: Dokumenthämtning
Dokumenthämtning syftar på att hitta dokument med matchande termer i indexet. Den här fasen tolkas bäst genom ett exempel. Vi börjar med att ett hotellindex har följande enkla schema:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Anta vidare att det här indexet innehåller följande fyra dokument:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
Så här indexeras termerna
För att förstå hämtning hjälper det dig att känna till några grunderna om indexering. Lagringsenheten är ett inverterat index, ett för varje sökbart fält. I ett inverterat index finns en sorterad lista över alla termer från alla dokument. Varje term mappas till listan över dokument där den inträffar, vilket framgår av exemplet nedan.
För att skapa termerna i ett inverterat index utför sökmotorn lexikal analys av innehållet i dokument, ungefär som vad som händer under frågebearbetningen:
- Textindata skickas till en analysator, gemener, fråntagen skiljetecken och så vidare, beroende på analysatorns konfiguration.
- Token är utdata från lexikal analys.
- Termer läggs till i indexet.
Det är vanligt, men inte nödvändigt, att använda samma analysverktyg för sök- och indexeringsåtgärder så att frågetermerna ser mer ut som termer i indexet.
Kommentar
Med Azure AI Search kan du ange olika analysverktyg för indexering och sökning via ytterligare indexAnalyzer parametrar och searchAnalyzer fältparametrar. Om den är ospecificerad används analysverktygsuppsättningen analyzer med egenskapen för både indexering och sökning.
Inverterat index till exempel dokument
När vi går tillbaka till vårt exempel för rubrikfältet ser det inverterade indexet ut så här:
| Period | Dokumentlista |
|---|---|
| Atman | 1 |
| Beach | 2 |
| Hotel | 1, 3 |
| Ocean | 4 |
| Playa | 3 |
| Resort | 3 |
| Retreat | 4 |
I rubrikfältet visas endast hotell i två dokument: 1, 3.
För beskrivningsfältet är indexet följande:
| Period | Dokumentlista |
|---|---|
| Luft | 3 |
| and | 4 |
| Beach | 1 |
| Villkorade | 3 |
| Bekväma | 3 |
| avstånd | 1 |
| ö | 2 |
| kauaʻi | 2 |
| Belägna | 2 |
| north | 2 |
| Ocean | 1, 2, 3 |
| av | 2 |
| on | 2 |
| Lugnt | 4 |
| Rum | 1, 3 |
| Avskilda | 4 |
| Stranden | 2 |
| Rymliga | 1 |
| Det | 1, 2 |
| to | 1 |
| vy | 1, 2, 3 |
| Promenader | 1 |
| med | 3 |
Matcha frågetermer mot indexerade termer
Med tanke på de inverterade indexen ovan ska vi gå tillbaka till exempelfrågan och se hur matchande dokument hittas för vår exempelfråga. Kom ihåg att det sista frågeträdet ser ut så här:
Under frågekörningen körs enskilda frågor mot sökbara fält oberoende av varandra.
TermQuery, "rymlig", matchar dokument 1 (Hotel Atman).
PrefixQuery, "air-condition*", matchar inte några dokument.
Det här är ett beteende som ibland förvirrar utvecklare. Även om termen luftkonditionerad finns i dokumentet delas den upp i två termer som standardanalysator. Kom ihåg att prefixfrågor, som innehåller partiella termer, inte analyseras. Därför letas termer med prefixet "air-condition" upp i det inverterade indexet och hittas inte.
PhraseQuery, "ocean view", letar upp termerna "ocean" och "view" och kontrollerar närheten till termer i det ursprungliga dokumentet. Dokument 1, 2 och 3 matchar den här frågan i beskrivningsfältet. Observera att dokument 4 har termen ocean i rubriken men anses inte vara en matchning, eftersom vi letar efter frasen "ocean view" i stället för enskilda ord.
Kommentar
En sökfråga körs oberoende av alla sökbara fält i Azure AI Search-indexet om du inte begränsar fälten som angetts med parametern searchFields , vilket visas i exempelsökningsbegäran. Dokument som matchar i något av de markerade fälten returneras.
För frågan i fråga är dokumenten som matchar på det hela taget 1, 2, 3.
Steg 4: Poängsättning
Varje dokument i en sökresultatuppsättning tilldelas en relevanspoäng. Funktionen för relevanspoängen är att rangordna högre de dokument som bäst besvarar en användarfråga som uttrycks i sökfrågan. Poängen beräknas baserat på statistiska egenskaper för termer som matchade. Kärnan i bedömningsformeln är TF/IDF (termfrekvens-inverterad dokumentfrekvens). I frågor som innehåller sällsynta och vanliga termer främjar TF/IDF resultat som innehåller den sällsynta termen. I till exempel ett hypotetiskt index med alla Wikipedia-artiklar, från dokument som matchade frågan till presidenten, anses dokument som matchar presidentenvara mer relevanta än dokument som matchar på.
Bedömningsexempel
Kom ihåg de tre dokument som matchade vår exempelfråga:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
Dokument 1 matchade frågan bäst eftersom både termen rymlig och den nödvändiga frasen havsvy förekommer i beskrivningsfältet. De följande två dokumenten matchar bara frasen ocean view. Det kan vara förvånande att relevanspoängen för dokument 2 och 3 skiljer sig även om de matchade frågan på samma sätt. Det beror på att bedömningsformeln har fler komponenter än bara TF/IDF. I det här fallet tilldelades dokument 3 en något högre poäng eftersom beskrivningen är kortare. Lär dig mer om Lucene's Practical Scoring Formula för att förstå hur fältlängd och andra faktorer kan påverka relevanspoängen.
Vissa frågetyper (jokertecken, prefix, regex) bidrar alltid med en konstant poäng till den övergripande dokumentpoängen. Detta gör att matchningar som hittas via frågeexpansion kan inkluderas i resultaten, men utan att påverka rangordningen.
Ett exempel illustrerar varför detta är viktigt. Jokerteckensökningar, inklusive prefixsökningar, är tvetydiga per definition eftersom indata är en partiell sträng med potentiella matchningar på ett mycket stort antal olika termer (överväg indata från "tour*", med matchningar som finns på "turer", "tourettes" och "tourmaline"). Med tanke på arten av dessa resultat finns det inget sätt att rimligen härleda vilka termer som är mer värdefulla än andra. Därför ignorerar vi termfrekvenser vid bedömning av resultat i frågor av typen jokertecken, prefix och regex. I en sökbegäran i flera delar som innehåller partiella och fullständiga termer införlivas resultat från de partiella indata med en konstant poäng för att undvika bias mot potentiellt oväntade matchningar.
Relevansjustering
Det finns två sätt att justera relevanspoäng i Azure AI Search:
Bedömningsprofiler höjer upp dokument i den rankade listan med resultat baserat på en uppsättning regler. I vårt exempel kan vi överväga dokument som matchade i rubrikfältet mer relevanta än dokument som matchade i beskrivningsfältet. Om vårt index dessutom hade ett prisfält för varje hotell skulle vi kunna höja upp dokument med lägre pris. Läs mer om att lägga till bedömningsprofiler i ett sökindex.
Termförstärkning (endast tillgängligt i fullständig Lucene-frågesyntax) ger en boostoperator
^som kan tillämpas på alla delar av frågeträdet. I vårt exempel, i stället för att söka på prefixets luftkonditionering*, kan man söka efter antingen den exakta termen luftkonditionering eller prefixet, men dokument som matchar på den exakta termen rangordnas högre genom att tillämpa boost på termfrågan: luftkonditionering^2||luftkonditionering*. Läs mer om termstädning i en fråga.
Bedömning i ett distribuerat index
Alla index i Azure AI Search delas automatiskt upp i flera shards, vilket gör att vi snabbt kan distribuera indexet mellan flera noder när tjänsten skalas upp eller skalas ned. När en sökbegäran utfärdas utfärdas den separat mot varje fragment. Resultatet från varje shard sammanfogas och sorteras efter poäng (om ingen annan ordning definieras). Det är viktigt att veta att bedömningsfunktionen viktar frågetermfrekvensen mot dess inverterade dokumentfrekvens i alla dokument i fragmentet, inte över alla shards!
Det innebär att en relevanspoäng kan skilja sig åt för identiska dokument om de finns på olika shards. Lyckligtvis tenderar sådana skillnader att försvinna när antalet dokument i indexet växer på grund av en jämnare termfördelning. Det går inte att anta vilken fragmentering ett visst dokument ska placeras på. Men förutsatt att en dokumentnyckel inte ändras tilldelas den alltid till samma fragment.
I allmänhet är dokumentpoäng inte det bästa attributet för att beställa dokument om orderstabilitet är viktigt. Med tanke på två dokument med samma poäng finns det till exempel ingen garanti för att ett visas först i efterföljande körningar av samma fråga. Dokumentpoäng bör endast ge en allmän känsla av dokumentrelevans i förhållande till andra dokument i resultatuppsättningen.
Slutsats
Framgången för kommersiella sökmotorer har höjt förväntningarna på fulltextsökning över privata data. För nästan alla typer av sökupplevelser förväntar vi oss nu att motorn förstår vår avsikt, även när termerna är felstavade eller ofullständiga. Vi kan till och med förvänta oss matchningar baserat på nästan motsvarande termer eller synonymer som vi aldrig har angett.
Ur teknisk synvinkel är fulltextsökning mycket komplext, vilket kräver avancerad språkanalys och en systematisk metod för bearbetning på sätt som destillera, expandera och transformera frågetermer för att leverera ett relevant resultat. Med tanke på den inneboende komplexiteten finns det många faktorer som kan påverka resultatet av en fråga. Därför ger investeringar i tid för att förstå mekaniken för fulltextsökning påtagliga fördelar när du försöker arbeta igenom oväntade resultat.
I den här artikeln utforskades fulltextsökning i samband med Azure AI Search. Vi hoppas att det ger dig tillräcklig bakgrund för att identifiera potentiella orsaker och lösningar för att hantera vanliga frågeproblem.
Nästa steg
Skapa exempelindexet, prova olika frågor och granska resultaten. Anvisningar finns i Skapa och fråga efter ett index i portalen.
Prova annan frågesyntax från exempelavsnittet Sökdokument eller från Enkel frågesyntax i Sökutforskaren i portalen.
Granska bedömningsprofiler om du vill justera rangordningen i sökprogrammet.
Lär dig hur du använder språkspecifika lexikala analysverktyg.
Konfigurera anpassade analysverktyg för minimal bearbetning eller specialiserad bearbetning på specifika fält.