Hög tillgänglighet för SAP HANA-uppskalning med Azure NetApp Files på RHEL
Den här artikeln beskriver hur du konfigurerar SAP HANA-systemreplikering i uppskalningsdistribution, när HANA-filsystemen monteras via NFS med hjälp av Azure NetApp Files. I exempelkonfigurationer och installationskommandon används instansnummer 03 och HANA System ID HN1 . SAP HANA System Replication består av en primär nod och minst en sekundär nod.
När stegen i det här dokumentet markeras med följande prefix är innebörden följande:
- [A]: Steget gäller för alla noder
- [1]: Steget gäller endast för node1
- [2]: Steget gäller endast för node2
Förutsättningar
Läs följande SAP-anteckningar och dokument först:
- SAP Note 1928533, som har:
- Listan över storlekar för virtuella Azure-datorer (VM) som stöds för distribution av SAP-programvara.
- Viktig kapacitetsinformation för vm-storlekar i Azure.
- Sap-programvara och operativsystem (OS) och databaskombinationer som stöds.
- Den nödvändiga SAP-kernelversionen för Windows och Linux på Microsoft Azure.
- SAP Note 2015553 listar krav för SAP-programdistributioner som stöds i Azure.
- SAP Note 405827 listar rekommenderade filsystem för HANA-miljöer.
- SAP Obs 2002167 har rekommenderade operativsysteminställningar för Red Hat Enterprise Linux.
- SAP Note 2009879 har SAP HANA-riktlinjer för Red Hat Enterprise Linux.
- SAP Note 3108302 har SAP HANA-riktlinjer för Red Hat Enterprise Linux 9.x.
- SAP Note 2178632 innehåller detaljerad information om alla övervakningsmått som rapporterats för SAP i Azure.
- SAP Note 2191498 har den sap-värdagentversion som krävs för Linux i Azure.
- SAP Note 2243692 har information om SAP-licensiering på Linux i Azure.
- SAP Note 1999351 innehåller mer felsökningsinformation för Azure Enhanced Monitoring Extension för SAP.
- SAP Community Wiki har alla nödvändiga SAP-anteckningar för Linux.
- Planering och implementering av Azure Virtual Machines för SAP i Linux
- Distribution av virtuella Azure-datorer för SAP i Linux
- Azure Virtual Machines DBMS-distribution för SAP på Linux
- SAP HANA-systemreplikering i Pacemaker-kluster
- Allmän Dokumentation om Red Hat Enterprise Linux (RHEL):
- Azure-specifik RHEL-dokumentation:
- Supportprinciper för RHEL-kluster med hög tillgänglighet – Microsoft Azure Virtual Machines som klustermedlemmar
- Installera och konfigurera ett Red Hat Enterprise Linux 7.4-kluster (och senare) med hög tillgänglighet i Microsoft Azure
- Konfigurera SAP HANA-uppskalningssystemreplikering i ett Pacemaker-kluster när HANA-filsystemen finns på NFS-resurser
- NFS v4.1-volymer på Azure NetApp Files för SAP HANA
Översikt
Traditionellt i en uppskalningsmiljö monteras alla filsystem för SAP HANA från lokal lagring. Konfiguration av hög tillgänglighet (HA) för SAP HANA System Replication på Red Hat Enterprise Linux publiceras i Konfigurera SAP HANA System Replication på RHEL.
För att uppnå SAP HANA HA för ett uppskalningssystem på Azure NetApp Files NFS-resurser behöver vi lite mer resurskonfiguration i klustret för att HANA-resurser ska kunna återställas när en nod förlorar åtkomsten till NFS-resurserna i Azure NetApp Files. Klustret hanterar NFS-monteringarna så att det kan övervaka resursernas hälsotillstånd. Beroendena mellan filsystemmonteringarna och SAP HANA-resurserna tillämpas.
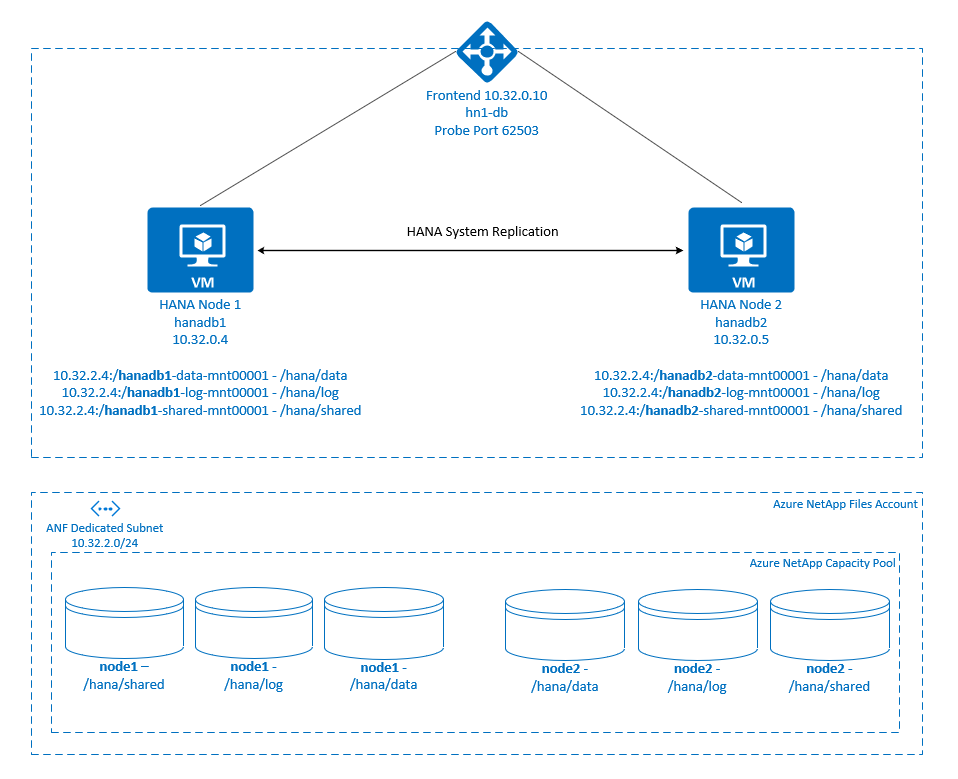 .
.
SAP HANA-filsystem monteras på NFS-resurser med hjälp av Azure NetApp Files på varje nod. Filsystem /hana/data, /hana/logoch /hana/shared är unika för varje nod.
Monterad på node1 (hanadb1):
- 10.32.2.4:/hanadb1-data-mnt00001 på /hana/data
- 10.32.2.4:/hanadb1-log-mnt00001 på /hana/log
- 10.32.2.4:/hanadb1-shared-mnt00001 på /hana/shared
Monterad på node2 (hanadb2):
- 10.32.2.4:/hanadb2-data-mnt00001 på /hana/data
- 10.32.2.4:/hanadb2-log-mnt00001 på /hana/log
- 10.32.2.4:/hanadb2-shared-mnt00001 på /hana/shared
Kommentar
Filsystem /hana/shared, /hana/dataoch /hana/log delas inte mellan de två noderna. Varje klusternod har egna separata filsystem.
Konfigurationen för SAP HANA-systemreplikering använder ett dedikerat virtuellt värdnamn och virtuella IP-adresser. I Azure krävs en lastbalanserare för att använda en virtuell IP-adress. Konfigurationen som visas här har en lastbalanserare med:
- Ip-adress för klientdelen: 10.32.0.10 för hn1-db
- Avsökningsport: 62503
Konfigurera Azure NetApp Files-infrastrukturen
Innan du fortsätter med konfigurationen för Azure NetApp Files-infrastrukturen bör du bekanta dig med Dokumentationen om Azure NetApp Files.
Azure NetApp Files är tillgängligt i flera Azure-regioner. Kontrollera om den valda Azure-regionen erbjuder Azure NetApp Files.
Information om tillgängligheten för Azure NetApp Files per Azure-region finns i Tillgänglighet för Azure NetApp Files per Azure-region.
Viktigt!
När du skapar dina Azure NetApp Files-volymer för SAP HANA-uppskalningssystem bör du vara medveten om de viktiga överväganden som beskrivs i NFS v4.1-volymer på Azure NetApp Files för SAP HANA.
Storleksändring av HANA-databas på Azure NetApp Files
Dataflödet för en Azure NetApp Files-volym är en funktion av volymstorleken och tjänstnivån, enligt beskrivningen i Tjänstnivå för Azure NetApp Files.
När du utformar infrastrukturen för SAP HANA i Azure med Azure NetApp Files bör du vara medveten om rekommendationerna i NFS v4.1-volymer på Azure NetApp Files för SAP HANA.
Konfigurationen i den här artikeln visas med enkla Azure NetApp Files-volymer.
Viktigt!
För produktionssystem, där prestanda är en nyckel, rekommenderar vi att du utvärderar och överväger att använda Azure NetApp Files-programvolymgruppen för SAP HANA.
Distribuera Azure NetApp Files-resurser
Följande instruktioner förutsätter att du redan har distribuerat ditt virtuella Azure-nätverk. Azure NetApp Files-resurser och virtuella datorer, där Azure NetApp Files-resurserna ska monteras, måste distribueras i samma virtuella Azure-nätverk eller i peerkopplade virtuella Azure-nätverk.
Skapa ett NetApp-konto i din valda Azure-region genom att följa anvisningarna i Skapa ett NetApp-konto.
Konfigurera en Azure NetApp Files-kapacitetspool genom att följa anvisningarna i Konfigurera en Azure NetApp Files-kapacitetspool.
HANA-arkitekturen som visas i den här artikeln använder en enda Azure NetApp Files-kapacitetspool på Ultra-tjänstnivå . För HANA-arbetsbelastningar i Azure rekommenderar vi att du använder en Azure NetApp Files Ultra- eller Premium-tjänstnivå.
Delegera ett undernät till Azure NetApp Files enligt anvisningarna i Delegera ett undernät till Azure NetApp Files.
Distribuera Azure NetApp Files-volymer genom att följa anvisningarna i Skapa en NFS-volym för Azure NetApp Files.
När du distribuerar volymerna måste du välja NFSv4.1-versionen. Distribuera volymerna i det avsedda Azure NetApp Files-undernätet. IP-adresserna för Azure NetApp-volymerna tilldelas automatiskt.
Tänk på att Azure NetApp Files-resurserna och de virtuella Azure-datorerna måste finnas i samma virtuella Azure-nätverk eller i peerkopplade virtuella Azure-nätverk. Till exempel,
hanadb1-data-mnt00001ochhanadb1-log-mnt00001är volymnamnen ochnfs://10.32.2.4/hanadb1-data-mnt00001ochnfs://10.32.2.4/hanadb1-log-mnt00001är filsökvägarna för Azure NetApp Files-volymerna.På hanadb1:
- Volym hanadb1-data-mnt00001 (nfs://10.32.2.4:/hanadb1-data-mnt00001)
- Volym hanadb1-log-mnt00001 (nfs://10.32.2.4:/hanadb1-log-mnt00001)
- Volym hanadb1-shared-mnt00001 (nfs://10.32.2.4:/hanadb1-shared-mnt00001)
På hanadb2:
- Volym hanadb2-data-mnt00001 (nfs://10.32.2.4:/hanadb2-data-mnt00001)
- Volym hanadb2-log-mnt00001 (nfs://10.32.2.4:/hanadb2-log-mnt00001)
- Volym hanadb2-shared-mnt00001 (nfs://10.32.2.4:/hanadb2-shared-mnt00001)
Kommentar
Alla kommandon som ska monteras /hana/shared i den här artikeln visas för NFSv4.1-volymer /hana/shared .
Om du har distribuerat volymerna /hana/shared som NFSv3-volymer ska du inte glömma att justera monteringskommandona för /hana/shared NFSv3.
Förbered infrastrukturen
Azure Marketplace innehåller avbildningar som är kvalificerade för SAP HANA med tillägget Hög tillgänglighet, som du kan använda för att distribuera nya virtuella datorer med hjälp av olika versioner av Red Hat.
Distribuera virtuella Linux-datorer manuellt via Azure-portalen
Det här dokumentet förutsätter att du redan har distribuerat en resursgrupp, ett virtuellt Azure-nätverk och ett undernät.
Distribuera virtuella datorer för SAP HANA. Välj en lämplig RHEL-avbildning som stöds för HANA-systemet. Du kan distribuera en virtuell dator i något av tillgänglighetsalternativen: VM-skalningsuppsättning, tillgänglighetszon eller tillgänglighetsuppsättning.
Viktigt!
Kontrollera att operativsystemet du väljer är SAP-certifierat för SAP HANA för de specifika VM-typer som du planerar att använda i distributionen. Du kan leta upp SAP HANA-certifierade VM-typer och deras OS-versioner i SAP HANA-certifierade IaaS-plattformar. Se till att du tittar på informationen om vm-typen för att få en fullständig lista över SAP HANA-versioner som stöds av operativsystemet för den specifika typen av virtuell dator.
Konfigurera Azure-lastbalanserare
Under konfigurationen av den virtuella datorn kan du skapa eller välja att avsluta lastbalanseraren i nätverksavsnittet. Följ stegen nedan för att konfigurera standardlastbalanserare för installation av HANA-databas med hög tillgänglighet.
Följ stegen i Skapa lastbalanserare för att konfigurera en standardlastbalanserare för ett SAP-system med hög tillgänglighet med hjälp av Azure-portalen. Tänk på följande under installationen av lastbalanseraren:
- IP-konfiguration för klientdelen: Skapa en klientdels-IP-adress. Välj samma virtuella nätverk och undernätsnamn som dina virtuella databasdatorer.
- Serverdelspool: Skapa en serverdelspool och lägg till virtuella databasdatorer.
- Regler för inkommande trafik: Skapa en belastningsutjämningsregel. Följ samma steg för båda belastningsutjämningsreglerna.
- Klientdels-IP-adress: Välj en klientdels-IP-adress.
- Serverdelspool: Välj en serverdelspool.
- Portar med hög tillgänglighet: Välj det här alternativet.
- Protokoll: Välj TCP.
- Hälsoavsökning: Skapa en hälsoavsökning med följande information:
- Protokoll: Välj TCP.
- Port: Till exempel 625<instans-no.>.
- Intervall: Ange 5.
- Tröskelvärde för avsökning: Ange 2.
- Tidsgräns för inaktivitet (minuter): Ange 30.
- Aktivera flytande IP: Välj det här alternativet.
Kommentar
Konfigurationsegenskapen numberOfProbesför hälsoavsökningen , även kallad Tröskelvärde för fel i portalen, respekteras inte. Om du vill kontrollera antalet lyckade eller misslyckade efterföljande avsökningar anger du egenskapen probeThreshold till 2. Det går för närvarande inte att ange den här egenskapen med hjälp av Azure-portalen, så använd antingen Azure CLI eller PowerShell-kommandot .
Mer information om de portar som krävs för SAP HANA finns i kapitlet Anslut ions till klientdatabaser i guiden FÖR SAP HANA-klientdatabaser eller SAP Note 2388694.
Viktigt!
Flytande IP stöds inte på en sekundär IP-konfiguration för nätverkskort i belastningsutjämningsscenarier. Mer information finns i Begränsningar för Azure Load Balancer. Om du behöver en annan IP-adress för den virtuella datorn distribuerar du ett andra nätverkskort.
Kommentar
När virtuella datorer utan offentliga IP-adresser placeras i serverdelspoolen för en intern (ingen offentlig IP-adress) instans av Standard Azure Load Balancer finns det ingen utgående Internetanslutning, såvida inte mer konfiguration utförs för att tillåta routning till offentliga slutpunkter. Mer information om hur du uppnår utgående anslutning finns i Offentlig slutpunktsanslutning för virtuella datorer som använder Standard Azure Load Balancer i SAP-scenarier med hög tillgänglighet.
Viktigt!
Aktivera inte TCP-tidsstämplar på virtuella Azure-datorer som placeras bakom Azure Load Balancer. Om du aktiverar TCP-tidsstämplar kan hälsoavsökningarna misslyckas. Ange parametern net.ipv4.tcp_timestamps till 0. Mer information finns i Load Balancer-hälsoavsökningar och SAP Note 2382421.
Montera Azure NetApp Files-volymen
[A] Skapa monteringspunkter för HANA-databasvolymerna.
sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/shared[A] Verifiera NFS-domäninställningen. Kontrollera att domänen är konfigurerad som standarddomänen för Azure NetApp Files, det vill defaultv4iddomain.com och att mappningen inte är inställd på någon.
sudo cat /etc/idmapd.confExempel på utdata>
[General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobodyViktigt!
Se till att ange NFS-domänen
/etc/idmapd.confpå den virtuella datorn så att den matchar standarddomänkonfigurationen på Azure NetApp Files: defaultv4iddomain.com. Om det finns ett matchningsfel mellan domänkonfigurationen på NFS-klienten (dvs. den virtuella datorn) och NFS-servern (dvs. Konfigurationen av Azure NetApp Files) visas behörigheterna för filer på Azure NetApp Files-volymer som är monterade på de virtuella datorerna somnobody.[1] Montera de nodspecifika volymerna på node1 (hanadb1).
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-data-mnt00001 /hana/data[2] Montera de nodspecifika volymerna på node2 (hanadb2).
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-data-mnt00001 /hana/data[A] Kontrollera att alla HANA-volymer är monterade med NFS-protokollversionen NFSv4.
sudo nfsstat -mKontrollera att flaggan
versär inställd på 4.1. Exempel från hanadb1:/hana/log from 10.32.2.4:/hanadb1-log-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/data from 10.32.2.4:/hanadb1-data-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/shared from 10.32.2.4:/hanadb1-shared-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4[A] Kontrollera nfs4_disable_idmapping. Den ska vara inställd på Y. Kör monteringskommandot för att skapa katalogstrukturen där nfs4_disable_idmapping finns. Du kan inte skapa katalogen manuellt under
/sys/moduleseftersom åtkomst är reserverad för kerneln och drivrutinerna.Kontrollera
nfs4_disable_idmapping.sudo cat /sys/module/nfs/parameters/nfs4_disable_idmappingOm du behöver ställa in
nfs4_disable_idmappingpå:sudo echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmappingGör konfigurationen permanent.
sudo echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confMer information om hur du ändrar parametern
nfs_disable_idmappingfinns i Red Hat Knowledge Base.
SAP HANA-installation
[A] Konfigurera värdnamnsmatchning för alla värdar.
Du kan antingen använda en DNS-server eller ändra
/etc/hostsfilen på alla noder. Det här exemplet visar hur du använder/etc/hostsfilen. Ersätt IP-adressen och värdnamnet i följande kommandon:sudo vi /etc/hostsInfoga följande rader i
/etc/hostsfilen. Ändra IP-adressen och värdnamnet så att de matchar din miljö.10.32.0.4 hanadb1 10.32.0.5 hanadb2[A] Förbered operativsystemet för att köra SAP HANA på Azure NetApp med NFS, enligt beskrivningen i SAP Note 3024346 – Linux Kernel Inställningar för NetApp NFS. Skapa konfigurationsfil
/etc/sysctl.d/91-NetApp-HANA.confför NetApp-konfigurationsinställningarna.sudo vi /etc/sysctl.d/91-NetApp-HANA.confLägg till följande poster i konfigurationsfilen.
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] Skapa konfigurationsfilen
/etc/sysctl.d/ms-az.confmed fler optimeringsinställningar.sudo vi /etc/sysctl.d/ms-az.confLägg till följande poster i konfigurationsfilen.
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Dricks
Undvik att ange
net.ipv4.ip_local_port_rangeochnet.ipv4.ip_local_reserved_portsuttryckligen i konfigurationsfilernasysctlså att SAP-värdagenten kan hantera portintervallen. Mer information finns i SAP Note 2382421.[A] Justera inställningarna enligt rekommendationerna
sunrpci SAP Note 3024346 – Linux Kernel Inställningar för NetApp NFS.sudo vi /etc/modprobe.d/sunrpc.confInfoga följande rad:
options sunrpc tcp_max_slot_table_entries=128[A] Utför RHEL OS-konfiguration för HANA.
Konfigurera operativsystemet enligt beskrivningen i följande SAP-anteckningar baserat på din RHEL-version:
- 2292690 – SAP HANA DB: Rekommenderade OS-inställningar för RHEL 7
- 2777782 – SAP HANA DB: Rekommenderat operativsystem Inställningar för RHEL 8
- 2455582 – Linux: Köra SAP-program som kompilerats med GCC 6.x
- 2593824 – Linux: Köra SAP-program som kompilerats med GCC 7.x
- 2886607 – Linux: Köra SAP-program som kompilerats med GCC 9.x
[A] Installera SAP HANA.
Från och med HANA 2.0 SPS 01 är MDC standardalternativet. När du installerar HANA-systemet skapas SYSTEMDB och en klientorganisation med samma SID tillsammans. I vissa fall vill du inte ha standardklientorganisationen. Om du inte vill skapa en första klientorganisation tillsammans med installationen kan du följa SAP Note 2629711.
Kör hdblcm-programmet från HANA DVD. Ange följande värden i kommandotolken:
- Välj installation: Ange 1 (för installation).
- Välj fler komponenter för installation: Ange 1.
- Ange installationssökväg [/hana/delad]: Välj Retur för att acceptera standardinställningen.
- Ange lokalt värdnamn [..]: Välj Retur för att acceptera standardvärdet. Vill du lägga till ytterligare värdar i systemet? (y/n) [n]: n.
- Ange SAP HANA-system-ID: Ange HN1.
- Ange instansnummer [00]: Ange 03.
- Välj Databasläge/Ange index [1]: Välj Retur för att acceptera standardvärdet.
- Välj Systemanvändning/Ange index [4]: Ange 4 (för anpassad).
- Ange Plats för datavolymer [/hana/data]: Välj Retur för att acceptera standardvärdet.
- Ange plats för loggvolymer [/hana/log]: Välj Retur för att acceptera standardvärdet.
- Begränsa maximal minnesallokering? [n]: Välj Retur för att acceptera standardvärdet.
- Ange certifikatvärdnamnet för värden ...: [...]: Välj Retur för att acceptera standardvärdet.
- Ange sap-värdagentens användarlösenord (sapadm): Ange användarlösenordet för värdagenten.
- Bekräfta SAPADM-lösenordet (SAP Host Agent User): Ange värdagentens användarlösenord igen för att bekräfta.
- Ange systemadministratörslösenord (hn1adm): Ange systemadministratörslösenordet.
- Bekräfta systemadministratörslösenord (hn1adm): Ange systemadministratörslösenordet igen för att bekräfta.
- Ange systemadministratörens startkatalog [/usr/sap/HN1/home]: Välj Retur för att acceptera standardvärdet.
- Ange systemadministratörsinloggningsgränssnittet [/bin/sh]: Välj Retur för att acceptera standardvärdet.
- Ange systemadministratörens användar-ID [1001]: Välj Retur för att acceptera standardvärdet.
- Ange ID för användargrupp (sapsys) [79]: Välj Retur för att acceptera standardvärdet.
- Ange lösenord för databasanvändare (SYSTEM): Ange databasanvändarlösenordet.
- Bekräfta lösenord för databasanvändare (SYSTEM): Ange databasanvändarlösenordet igen för att bekräfta.
- Starta om systemet efter omstart av datorn? [n]: Välj Retur för att acceptera standardvärdet.
- Vill du fortsätta? (y/n): Verifiera sammanfattningen. Ange y för att fortsätta.
[A] Uppgradera SAP-värdagenten.
Ladda ned det senaste SAP-värdagentarkivet från SAP Software Center och kör följande kommando för att uppgradera agenten. Ersätt sökvägen till arkivet för att peka på filen som du laddade ned:
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent SAR>[A] Konfigurera en brandvägg.
Skapa brandväggsregeln för Azure Load Balancer-avsökningsporten.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp –permanent
Konfigurera SAP HANA-systemreplikering
Följ stegen i Konfigurera SAP HANA System Replication för att konfigurera SAP HANA-systemreplikering.
Klusterkonfiguration
I det här avsnittet beskrivs de steg som krävs för att ett kluster ska fungera sömlöst när SAP HANA installeras på NFS-resurser med hjälp av Azure NetApp Files.
Skapa ett Pacemaker-kluster
Följ stegen i Konfigurera Pacemaker på Red Hat Enterprise Linux i Azure för att skapa ett grundläggande Pacemaker-kluster för den här HANA-servern.
Viktigt!
Med det systembaserade SAP Startup Framework kan SAP HANA-instanser nu hanteras av systemd. Den lägsta nödvändiga Versionen av Red Hat Enterprise Linux (RHEL) är RHEL 8 för SAP. Enligt beskrivningen i SAP Note 3189534, eventuella nya installationer av SAP HANA SPS07 revision 70 eller senare, eller uppdateringar av HANA-system till HANA 2.0 SPS07 revision 70 eller senare, registreras SAP Startup Framework automatiskt med systemd.
När du använder HA-lösningar för att hantera SAP HANA-systemreplikering i kombination med systemaktiverade SAP HANA-instanser (se SAP Note 3189534) krävs ytterligare steg för att säkerställa att HA-klustret kan hantera SAP-instansen utan systeminblandning. För SAP HANA-system som är integrerat med systemd måste därför ytterligare steg som beskrivs i Red Hat KBA 7029705 följas på alla klusternoder.
Implementera Python-systemreplikeringskroken SAPHanaSR
Det här steget är viktigt för att optimera integreringen med klustret och förbättra identifieringen när ett kluster behöver redundans. Vi rekommenderar starkt att du konfigurerar SAPHanaSR Python-kroken. Följ stegen i Implementera Python-systemreplikeringskroken SAPHanaSR.
Konfigurera filsystemresurser
I det här exemplet har varje klusternod sina egna HANA NFS-filsystem /hana/shared, /hana/dataoch /hana/log.
[1] Placera klustret i underhållsläge.
sudo pcs property set maintenance-mode=true[1] Skapa filsystemresurserna för hanadb1-monteringarna .
sudo pcs resource create hana_data1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_log1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_shared1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs[2] Skapa filsystemresurserna för hanadb2-monteringarna .
sudo pcs resource create hana_data2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_log2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_shared2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfsAttributet
OCF_CHECK_LEVEL=20läggs till i övervakningsåtgärden så att varje övervakare utför ett läs-/skrivtest i filsystemet. Utan det här attributet verifierar övervakningsåtgärden endast att filsystemet är monterat. Detta kan vara ett problem eftersom filsystemet kan förbli monterat trots att det är otillgängligt när anslutningen går förlorad.Attributet
on-fail=fenceläggs också till i övervakningsåtgärden. Med det här alternativet stängs den noden omedelbart om övervakningsåtgärden misslyckas på en nod. Utan det här alternativet är standardbeteendet att stoppa alla resurser som är beroende av den misslyckade resursen, starta om den misslyckade resursen och sedan starta alla resurser som är beroende av den misslyckade resursen.Det här beteendet kan inte bara ta lång tid när en SAPHana-resurs är beroende av den misslyckade resursen, men den kan också misslyckas helt och hållet. SAPHana-resursen kan inte stoppas om NFS-servern som innehåller HANA-körbara filer inte är tillgänglig.
De föreslagna timeout-värdena gör att klusterresurserna kan stå emot protokollspecifik paus, relaterade till NFSv4.1-låneförnyelser. Mer information finns i NFS i Bästa praxis för NetApp. Tidsgränserna i föregående konfiguration kan behöva anpassas till den specifika SAP-konfigurationen.
För arbetsbelastningar som kräver högre dataflöde bör du överväga att använda monteringsalternativet enligt beskrivningen
nconnecti NFS v4.1-volymer på Azure NetApp Files för SAP HANA. Kontrollera omnconnectstöds av Azure NetApp Files i Linux-versionen.[1] Konfigurera platsbegränsningar.
Konfigurera platsbegränsningar för att säkerställa att de resurser som hanterar unika hanadb1-monteringar aldrig kan köras på hanadb2 och vice versa.
sudo pcs constraint location hanadb1_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb2 sudo pcs constraint location hanadb2_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb1Alternativet
resource-discovery=neveranges eftersom de unika monteringarna för varje nod delar samma monteringspunkt. Till exempelhana_data1använder monteringspunkten/hana/dataochhana_data2använder även monteringspunkten/hana/data. Att dela samma monteringspunkt kan orsaka en falsk positiv identifiering för en avsökningsåtgärd, när resurstillståndet kontrolleras vid klusterstart och det i sin tur kan orsaka onödigt återställningsbeteende. För att undvika det här scenariot anger duresource-discovery=never.[1] Konfigurera attributresurser.
Konfigurera attributresurser. De här attributen är inställda på true om alla NFS-monteringar för en nod (
/hana/data,/hana/log, och/hana/data) monteras. Annars är de inställda på false.sudo pcs resource create hana_nfs1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs1_active sudo pcs resource create hana_nfs2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs2_active[1] Konfigurera platsbegränsningar.
Konfigurera platsbegränsningar för att säkerställa att attributresursen för hanadb1 aldrig körs på hanadb2 och vice versa.
sudo pcs constraint location hana_nfs1_active avoids hanadb2 sudo pcs constraint location hana_nfs2_active avoids hanadb1[1] Skapa ordningsbegränsningar.
Konfigurera ordningsbegränsningar så att en nods attributresurser startar först när alla nodernas NFS-monteringar har monterats.
sudo pcs constraint order hanadb1_nfs then hana_nfs1_active sudo pcs constraint order hanadb2_nfs then hana_nfs2_activeDricks
Om konfigurationen innehåller filsystem, utanför gruppen
hanadb1_nfsellerhanadb2_nfs, inkluderar dusequential=falsealternativet så att det inte finns några ordningsberoenden mellan filsystemen. Alla filsystem måste starta förehana_nfs1_active, men de behöver inte starta i någon ordning i förhållande till varandra. Mer information finns i Hur gör jag för att konfigurera SAP HANA-systemreplikering i Skala upp i ett Pacemaker-kluster när HANA-filsystemen finns på NFS-resurser
Konfigurera SAP HANA-klusterresurser
Följ stegen i Skapa SAP HANA-klusterresurser för att skapa SAP HANA-resurserna i klustret. När SAP HANA-resurser har skapats måste du skapa en platsregelbegränsning mellan SAP HANA-resurser och filsystem (NFS-monteringar).
[1] Konfigurera begränsningar mellan SAP HANA-resurserna och NFS-monteringarna.
Platsregelbegränsningar anges så att SAP HANA-resurserna endast kan köras på en nod om alla nodens NFS-monteringar monteras.
sudo pcs constraint location SAPHanaTopology_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne truePå RHEL 7.x:
sudo pcs constraint location SAPHana_HN1_03-master rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne truePå RHEL 8.x/9.x:
sudo pcs constraint location SAPHana_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueTa bort klustret från underhållsläget.
sudo pcs property set maintenance-mode=falseKontrollera status för klustret och alla resurser.
Kommentar
Den här artikeln innehåller referenser till en term som Microsoft inte längre använder. När termen tas bort från programvaran tar vi bort den från den här artikeln.
sudo pcs statusExempel på utdata>
Online: [ hanadb1 hanadb2 ] Full list of resources: rsc_hdb_azr_agt(stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem):Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1
Konfigurera AKTIV/läsaktiverad HANA-systemreplikering i Pacemaker-kluster
Från och med SAP HANA 2.0 SPS 01 tillåter SAP aktiva/läsaktiverade installationer för SAP HANA-systemreplikering, där de sekundära systemen i SAP HANA System Replication kan användas aktivt för läsintensiva arbetsbelastningar. För att stödja en sådan installation i ett kluster krävs en andra virtuell IP-adress som gör att klienter kan komma åt den sekundära läsaktiverade SAP HANA-databasen.
För att säkerställa att den sekundära replikeringsplatsen fortfarande kan nås efter ett övertagande måste klustret flytta runt den virtuella IP-adressen med den sekundära SAPHana-resursen.
Den extra konfigurationen, som krävs för att hantera HANA aktiv/läsaktiverad systemreplikering i ett Red Hat HA-kluster med en andra virtuell IP-adress, beskrivs i Konfigurera HANA Aktiv/Läsaktiverad systemreplikering i Pacemaker-kluster.
Innan du fortsätter kontrollerar du att du har konfigurerat Red Hat High Availability Cluster för att hantera SAP HANA-databasen enligt beskrivningen i föregående avsnitt i dokumentationen.
Testa klusterkonfigurationen
I det här avsnittet beskrivs hur du kan testa konfigurationen.
Innan du startar ett test kontrollerar du att Pacemaker inte har någon misslyckad åtgärd (via pc-status), att det inte finns några oväntade platsbegränsningar (till exempel rester av ett migreringstest) och att HANA-systemreplikeringen är i synkroniseringstillstånd, till exempel med
systemReplicationStatus:sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"Kontrollera klusterkonfigurationen för ett felscenario när en nod förlorar åtkomsten till NFS-resursen (
/hana/shared).SAP HANA-resursagenterna är beroende av binärfiler som lagras på
/hana/sharedför att utföra åtgärder under redundansväxlingen. Filsystemet/hana/sharedmonteras över NFS i det presenterade scenariot.Det är svårt att simulera ett fel där en av servrarna förlorar åtkomsten till NFS-resursen. Som ett test kan du återmontera filsystemet som skrivskyddat. Den här metoden verifierar att klustret kan redundansväxla om åtkomsten till
/hana/sharedgår förlorad på den aktiva noden.Förväntat resultat: När du skapar
/hana/sharedsom ett skrivskyddat filsystemOCF_CHECK_LEVELmisslyckas attributet för resursenhana_shared1, som utför läs-/skrivåtgärder på filsystem. Det går inte att skriva något i filsystemet och utför HANA-resursredundans. Samma resultat förväntas när HANA-noden förlorar åtkomsten till NFS-resurserna.Resurstillstånd innan testet startas:
sudo pcs statusExempel på utdata>
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem): Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1Du kan placera
/hana/sharedi skrivskyddat läge på den aktiva klusternoden med hjälp av det här kommandot:sudo mount -o ro 10.32.2.4:/hanadb1-shared-mnt00001 /hana/sharedhanadbstartas om eller stängs av baserat på den åtgärd som angetts påstonith(pcs property show stonith-action). När servern (hanadb1) är nere flyttas HANA-resursen tillhanadb2. Du kan kontrollera status för klustret frånhanadb2.sudo pcs statusExempel på utdata>
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb2 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Stopped hana_log1 (ocf::heartbeat:Filesystem): Stopped hana_shared1 (ocf::heartbeat:Filesystem): Stopped Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Stopped hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb2 ] Stopped: [ hanadb1 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb2 ] Stopped: [ hanadb1 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb2 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb2Vi rekommenderar att du testar konfigurationen av SAP HANA-klustret noggrant genom att även utföra de tester som beskrivs i Konfigurera SAP HANA-systemreplikering på RHEL.