Meddelandeköer: Fallstudie
Tidigare har vi tittat på meddelandekösystem i allmänhet. Vi såg att allmänna meddelandekösystem för kommunikation mellan processer (interprocess communication) har funnits ett tag och mer specialiserade meddelandeköer för klient/server-system eller webbtjänstarkitekturer har utvecklats. Det finns flera olika system med unika design och funktioner, men vi kommer att titta på ett system som har byggts från grunden för skalbarhet och elasticitet: Apache Kafka.
Apache Kafka
Kafka ansvarar för att hantera meddelanden som kommer från en uppsättning program (som kallas producenter) och skicka dem till en uppsättning datorer som kan vara intresserad av meddelanden (som kallas konsumenter). Meddelanden publiceras av producenterna i ett Kafka-ämne. Konsumenter kan lyssna på specifika ämnen genom att prenumerera på dem och meddelanden levereras till konsumenterna av Kafka. Därför kan Apache Kafka beskrivas som en distribuerat publicera/prenumerera-meddelandesystem med öppen källkod.
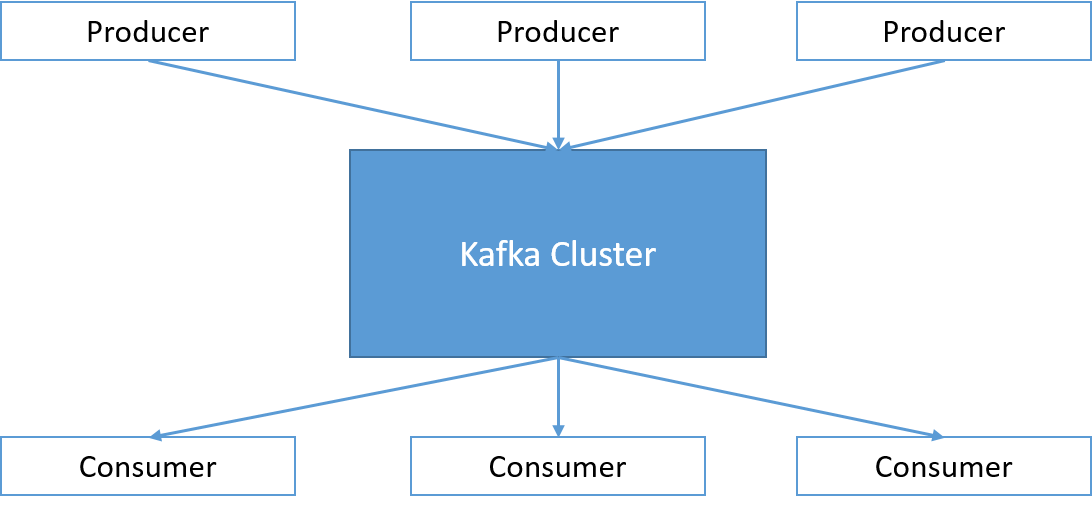
Bild 3: Ett Kafka-kluster
Ämnen representerar en användardefinierad kategori som meddelanden publiceras i. Ett exempelämne som man kan hitta på ett annonseringsföretag kan vara AdClickEvents. Alla konsumenter av data kan läsa från ett eller flera ämnen. Internt sparas varje ämne som en partitionerad incheckningslogg, som illustreras i bild 4. Det är viktigt att notera att ett ämne kan bestå av flera partitioner och ett Kafka-kluster kan hantera flera ämnen.

Bild 4: Meddelandeköer i Kafka
Formellt är varje partition en ordnad, oföränderlig sekvens meddelanden som kontinuerligt läggs till i en incheckningslogg. Alla meddelanden i partitionerna tilldelas ett sekventiellt ID-nummer som kallas förskjutningen. Det identifierar unikt varje meddelande i partitionen och kan inte användas till att ordna meddelanden i ett ämne mellan partitioner.
Partitionerna i loggen har flera olika syften. För det första tillåter de loggen att skalas bortom en storlek som passar på en enda server. Varje enskild partition måste passa på värdservrarna men ett ämne kan ha många partitioner så den kan hantera en godtycklig mängd data. För det andra fungerar det som parallellitetsenhet, så att enskilda partitioner av loggen som ska fördelas mellan flera datorer. Producenter har inte bara kontroll över ett meddelande, utan kan uttryckligen kontrollera partitionen som ett meddelande har skickats till, om det behövs, med hjälp av en semantisk partitionsfunktion (ungefär som partitionsfunktionerna som används i MapReduce). Som standard fördelas meddelanden i ett visst ämne med resursallokering mellan partitionerna för det ämnet.
Kafka-klustret behåller alla publicerade meddelanden – oavsett om de har konsumerats – under en konfigurerbar tidsperiod (standard är 7 dagar). Meddelanden som har passerat den här kvarhållningsperioden rensas automatiskt av Kafka för att skapa ledigt utrymme för nya meddelanden.
Kafka håller också reda på förloppet för varje konsument i läsning av meddelanden i loggfilen för ett visst ämne, som kallas för förskjutningen för en konsument. De flesta konsumenter flyttar fram det här förskjutningsvärdet när de konsumerar meddelanden. Konsumenter styr den här förskjutningsvariabeln och kan gå framåt eller bakåt för att läsa äldre eller nyare meddelanden, om det behövs.
Den här kombinationen av funktioner betyder att Kafka-konsumenter är mycket billiga. De kan komma och gå utan att det påverkar klustret eller andra konsumenter i så hög grad.
Garantier som tillhandahålls av Apache Kafka
Kafka tillhandahåller en uppsättning högnivågarantier som programutvecklare kan förlita sig på:
- Meddelanden skickade av en producent till en viss ämnespartition läggs till i den ordning de skickas. Det vill säga, om ett meddelande M1 skickas av samma producent som ett meddelande M2, och M1 skickas först, kommer sedan M1 att ha en lägre förskjutning än M2 och visas tidigare i loggen.
- En konsumentinstans ser meddelanden i den ordning som de lagras i loggen.
- För ett ämne med replikeringsfaktor $N$ tolererar vi upp till $N - 1$ serverfel utan att förlora några meddelanden incheckade i loggen.
Observera att leveransgarantierna inte är så strikta. Det omfattar faktumet att konsumenter kan få samma meddelande två gånger, i sällsynta fall.
Apache Kafkas arkitektur
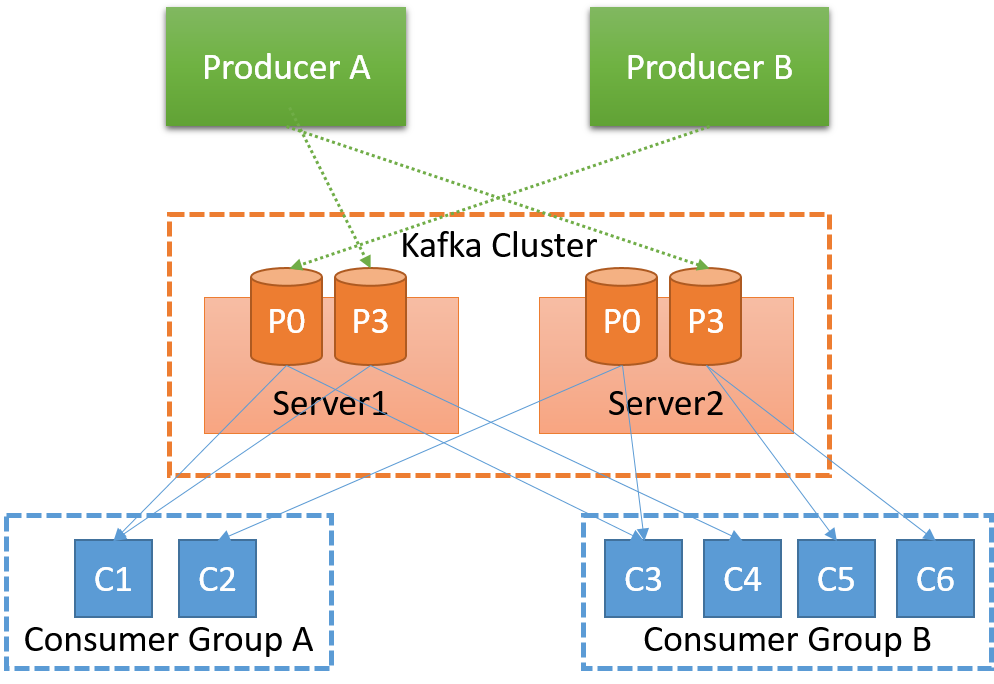
Bild 5: Kafka-arkitektur
Servrarna som överför meddelanden från utgivare (producenter) till prenumeranter (konsumenter) kallas Kafka-brokers. Kafka-brokers ansvarar för meddelandens beständighet och replikering. Partitionerna för varje ämne fördelas mellan asynkrona meddelandeköer och varje asynkron meddelandekö lagrar en eller flera partitioner.
Asynkrona meddelandeköer organiseras på ett decentraliserat sätt, eftersom det inte finns någon fast asynkron huvudmeddelandekö. För att asynkrona meddelandeköer ska kunna nå konsensus om tillståndet för systemet används Apache ZooKeeper. ZooKeeper tillhandahåller en kvorumkonsensustjänst med hög tillgänglighet i form av ett filsystemliknande API. ZooKeeper används i Kafka för följande uppgifter:
- Identifiera tillägget och borttagning av asynkrona meddelandeköer och konsumenter i systemet
- Utlösa en ombalansering av partitioner när antalet asynkrona meddelandeköer eller konsumenter ändras
- Upprätthålla konsumtionsrelationen och hålla reda på de förbrukade förskjutningarna för varje partition
Som tidigare nämnt är den minsta parallellitetsenheten i Kafka en partition i ett ämne. Det betyder att alla meddelanden för en partition förbrukas av en konsument vid en specifik tidpunkt. Det gör så att Kafka slipper utföra kostsam samordning mellan flera asynkrona meddelandeköer om det skulle vara för att garantera ordning mellan partitioner.
Partitioner replikeras mellan flera asynkrona meddelandeköer för feltolerans. En av de asynkrona meddelandeköerna utses till ledare för en viss partition och alla läsningar och skrivningar för den partitionen går till huvudrepliken som standard. Ett meddelande anses incheckad bara när alla repliker har checkat in meddelandet i loggen. Endast incheckade meddelanden vidarebefordras till konsumenterna. Producenter kan välja att blockera tills ett meddelande checkas in av Kafka eller väljer att kontinuerligt strömma meddelanden på ett icke-blockerande sätt. Det finns flera metoder som används av Kafka för att påskynda loggreplikeringsprocessen. Mer information finns i Apache Kafka-dokumentationen.
Eftersom Kafka-brokers förväntas att bearbeta stora mängder meddelanden, finns det två egenskaper för ”livsstatus” som Kafka övervakar för varje nod i klustret:
- Varje nod har en session med ZooKeeper via en pulsslagsmekanism.
- Varje underordnad måste replikera masterns uppdateringar och ska inte falla ”för långt” bakom. Replikfördröjningen är en konfigurerbar egenskap i ett Kafka-kluster.
Producentinteraktion
Producenter kan skicka meddelanden till ett Kafka-kluster med hjälp av Kafka-API:et. Producenter är medvetna om ämnena och partitioner som har konfigurerats. Kafka och en producent dirigerar normalt meddelanden till lämplig asynkron meddelandekö som ansvarar för att hantera den specifika partitionen för ett meddelande. API:et tillåter också att metadatabegäranden görs. Det gör så att producenter kan fråga och hitta lämplig asynkron meddelandekö för ett ämne och en partition. Som tidigare nämnt är partitioneringen av ett ämne konfigurerbar och slumpmässig belastningsutjämning eller innehållsmedveten semantisk partitionering av ett ämne kan användas.
Dessutom har producenter som interagerar med en Kafka-broker alternativet asynkron kommunikation för meddelanden och begäran om batchbearbetning, som ackumulerar meddelanden och skickar dem i batchar. Dessa kan också konfigureras, när det gäller antalet meddelanden för batchbearbetning eller en fast latensbindning, vilket gör att programmet kan kompromissa med svarstid mot dataflöde.
Konsumentinteraktion
Kafka-konsumenter utfärdar hämtningsbegäranden från asynkrona meddelandeköer för enskilda partitioner som måste förbrukas. En konsument kan ange en förskjutning i Kafka-loggen med varje begäran och sedan ta emot ett segment av meddelanden som börjar från den positionen. Konsumenter kan spola tillbaka till en förskjutning och begära meddelanden, förutsatt att dessa meddelanden är inom kvarhållningsfönstret för Kafka-klustret.
Användningsfall för Kafka
Meddelandekö: Föga förvånande kan Kafka användas som ersättning för traditionella meddelandeköer som ActiveMQ eller RabbitMQ. Kafka är särskilt viktigt eftersom det har utformats från grunden för hög tillgänglighet och skalbar meddelandeleverans, med konfigurerbar egenskaper för latens och dataflöde.
Spårning av webbplatsaktivitet: Kafka skapades ursprungligen av LinkedIn för att skapa en pipeline för användaraktivitet och fatta realtidsbeslut för innehåll och annonsplacering för LinkedIn-användare. I det här scenariot kan ämnen konstrueras efter användarinteraktionstyp (t.ex. ett ämne för sidvyer och rullningsinformation, ett annat för sökord och ett annat ämne för användarklickningar). Olika servertjänster, till exempel bearbetning och övervakning av användaraktivitet i realtid, kan prenumerera på relevanta ämnen och bearbeta dataströmmarna när de kommer in.
Loggaggregering: Kafka kan användas för att aggregera loggarna från flera tjänster och göra dem tillgängliga på en central plats för bearbetning. I jämförelse med loggcentrerade system som Scribe eller Flume har Kafka lika bra prestanda, starkare hållbarhetsgarantier tack vare replikering och mycket lägre latens slutpunkt till slutpunkt.