Beskriva normalisering
Databasnormalisering är en designprocess som används för att organisera en viss uppsättning data i tabeller och kolumner i en databas. Varje tabell bör innehålla data som rör en specifik "sak" och endast ha data som stöder samma "sak" som ingår i tabellen. Målet med den här processen är att minska duplicerade data i databasen för att minska prestandaförsämring av databasinfogningar och uppdateringar. En ändring av kundadressen är till exempel mycket enklare att implementera om den enda platsen där kundadressen lagras finns i tabellen Kunder. De vanligaste formerna av normalisering är första, andra och tredje normala formen och beskrivs nedan.
Första normala formen
Den första normala formen har följande specifikationer:
- Skapa en separat tabell för varje uppsättning relaterade data
- Eliminera upprepade grupper i enskilda tabeller
- Identifiera varje uppsättning relaterade data med en primärnyckel
I den här modellen bör du inte använda flera kolumner i en enda tabell för att lagra liknande data. Om produkten till exempel kan komma i flera färger bör du inte ha flera kolumner i en enda rad som innehåller de olika färgvärdena. Den första tabellen nedan (ProductColors) är inte i första normal form eftersom det finns upprepade värden för färg. För produkter med bara en färg finns det bortkastat utrymme. Och vad händer om en produkt kom i mer än tre färger? I stället för att behöva ange ett maximalt antal färger kan vi återskapa tabellen på det sätt som visas i den andra tabellen, ProductColor. Vi har också ett krav för det första normala formuläret att det finns en unik nyckel för tabellen, som är kolumn (eller kolumner) vars värde unikt identifierar raden. Ingen av kolumnerna i den andra tabellen är unik, men tillsammans är kombinationen av ProductID och Color unik. När flera kolumner behövs anropar vi den en sammansatt nyckel.
| Produktionen | Färg1 | Färg 2 | Färg 3 |
|---|---|---|---|
| 1 | Röd | Grönt | Gul |
| 2 | Gul | ||
| 3 | Blått | Röd | |
| 4 | Blått | ||
| 5 | Röd |
| Produktionen | Färg |
|---|---|
| 1 | Röd |
| 1 | Grönt |
| 1 | Gul |
| 2 | Gul |
| 3 | Blått |
| 3 | Röd |
| 4 | Blått |
| 5 | Röd |
Den tredje tabellen, ProductInfo, är i första normala form eftersom varje rad refererar till en viss produkt, det finns inga upprepande grupper och vi har kolumnen ProductID som ska användas som primärnyckel.
| Produktionen | Productname | Pris | ProductionCountry | ShortLocation |
|---|---|---|---|---|
| 1 | Widget | 15.95 | USA | USA |
| 2 | Foop | 41.95 | Storbritannien och Nordirland | Storbritannien |
| 3 | Glombit | 49.95 | Storbritannien och Nordirland | Storbritannien |
| 4 | Sorfin | 99,99 | Filippinerna | RepPhil |
| 5 | Stambult | 29.95 | USA | USA |
Andra normala formen
Den andra normala formen har följande specifikation, utöver de som krävs i den första normala formen:
- Om tabellen har en sammansatt nyckel måste alla attribut vara beroende av den fullständiga nyckeln och inte bara en del av den.
Den andra normala formen är endast relevant för tabeller med sammansatta nycklar, till exempel i tabellen ProductColor, som är den andra tabellen ovan. Tänk dig att tabellen ProductColor även innehåller produktens pris. Den här tabellen har en sammansatt nyckel för ProductID och Color, eftersom vi kan identifiera en rad unikt om vi bara använder båda kolumnvärdena. Om en produkts pris inte ändras med färgen kan vi se data som visas i den här tabellen:
| Produktionen | Färg | Pris |
|---|---|---|
| 1 | Röd | 15.95 |
| 1 | Grönt | 15.95 |
| 1 | Gul | 15.95 |
| 2 | Gul | 41.95 |
| 3 | Blått | 49.95 |
| 3 | Röd | 49.95 |
| 4 | Blått | 99,95 |
| 5 | Röd | 29.95 |
Tabellen ovan är inte i andra normala form. Prisvärdet är beroende av ProductID men inte på färgen. Det finns tre rader för ProductID 1, så priset för produkten upprepas tre gånger. Problemet med att bryta mot den andra normala formen är att om vi måste uppdatera priset måste vi se till att vi uppdaterar det överallt. Om vi uppdaterar priset på den första raden, men inte den andra eller tredje, skulle vi ha något som kallas "uppdateringsavvikelse". Efter uppdateringen skulle vi inte kunna säga vad det faktiska priset för ProductID 1 var. Lösningen är att flytta kolumnen Price till en tabell som har ProductID som en enda kolumnnyckel, eftersom det är den enda kolumn som Price är beroende av. Vi kan till exempel använda tabell 3 för att lagra priset.
Om priset för en produkt var annorlunda baserat på dess färg, skulle den fjärde tabellen vara i den andra normala formen, eftersom priset skulle bero på båda delarna av nyckeln: ProductID och Color.
Tredje normala formen
Den tredje normala formen är vanligtvis målet för de flesta OLTP-databaser. Den tredje normala formen har följande specifikation, utöver de som krävs i andra normala form:
- Alla icke-nyckelkolumner är inte transitivt beroende av primärnyckeln.
Den transitiva relationen innebär att en kolumn i en tabell är relaterad till andra kolumner, via en andra kolumn. Beroende innebär att en kolumn kan härleda sitt värde från en annan, till följd av ett beroende. Till exempel kan din ålder bestämmas från ditt födelsedatum, vilket gör din ålder beroende av ditt födelsedatum. Gå tillbaka till den tredje tabellen, ProductInfo. Den här tabellen är i den andra normala formen, men inte i tredje. Kolumnen ShortLocation är beroende av kolumnen ProductionCountry, som inte är nyckeln. Precis som i den andra normala formen kan brott mot tredje normala formulär leda till uppdateringsavvikelser. Vi skulle få inkonsekventa data om vi uppdaterade ShortLocation på en rad men inte uppdaterade den på alla rader där platsen inträffade. För att förhindra detta kan vi skapa en separat tabell för att lagra namn på land/region och deras förkortade formulär.
Avormalisering
Även om den tredje normala formen är teoretiskt önskvärd är det inte alltid möjligt för alla data. Dessutom ger en normaliserad databas inte alltid bästa prestanda. Normaliserade data kräver ofta flera kopplingsåtgärder för att få alla nödvändiga data som returneras i en enda fråga. Det finns en kompromiss mellan normalisering av data när antalet kopplingar som krävs för att returnera frågeresultat har hög CPU-användning och avnormaliserade data som har färre kopplingar och mindre PROCESSOR krävs, men öppnar upp risken för uppdateringsavvikelser.
Kommentar
Avnormaliserade data är inte samma somnormaliserade. För avnormalisering börjar vi med att utforma tabeller som är normaliserade. Sedan kan vi lägga till ytterligare kolumner i vissa tabeller för att minska antalet kopplingar som krävs, men när vi gör det är vi medvetna om eventuella uppdateringsavvikelser. Vi ser sedan till att vi har utlösare eller andra typer av bearbetning som ser till att alla dubblettdata också uppdateras när vi utför en uppdatering.
Avnormaliserade data kan vara effektivare att fråga, särskilt för läsintensiva arbetsbelastningar som ett informationslager. I sådana fall kan extra kolumner erbjuda bättre frågemönster och/eller fler förenklade frågor.
Star-schema
De flesta normaliseringar riktar sig till OLTP-arbetsbelastningar, men informationslager har en egen modelleringsstruktur, som vanligtvis är en avnormaliserad modell. Den här designen använder faktatabeller, som registrerar mått för specifika händelser som en försäljning, och kopplar dem till dimensionstabeller, som är mindre när det gäller radantal, men som kan ha ett stort antal kolumner för att beskriva faktadata. Några exempeldimensioner skulle omfatta inventering, tid och/eller geografi. Det här designmönstret används för att göra databasen enklare att fråga efter och erbjuda prestandavinster för läsarbetsbelastningar.
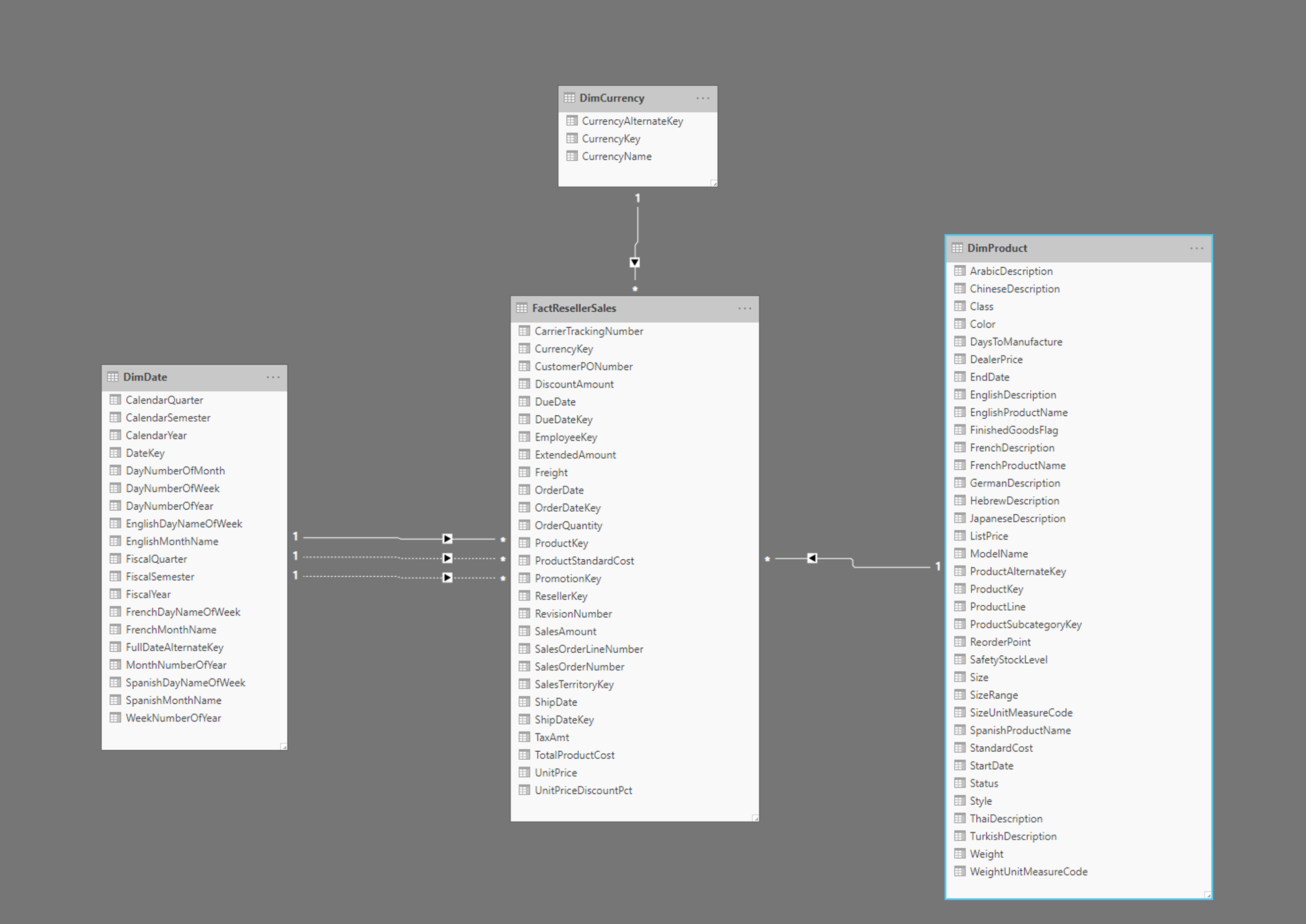
Bilden ovan visar ett exempel på ett stjärnschema, inklusive faktatabellen FactResellerSales och dimensioner för datum, valuta och produkter. Faktatabellen innehåller data som är relaterade till försäljningstransaktionerna och dimensionerna innehåller endast data som är relaterade till ett specifikt element i försäljningsdata. Tabellen FactResellerSales innehåller till exempel endast en ProductKey som anger vilken produkt som såldes. All information om varje produkt lagras i tabellen DimProduct och relateras tillbaka till faktatabellen med kolumnen ProductKey .
Relaterat till star-schemadesign är ett snowflake-schema, som använder en uppsättning mer normaliserade tabeller för en enskild affärsentitet. Följande bild visar ett exempel på en enda dimension för ett snowflake-schema. Produktdimensionen normaliseras och lagras i tre tabeller med namnet DimProductCategory, DimProductSubcategory och DimProduct.
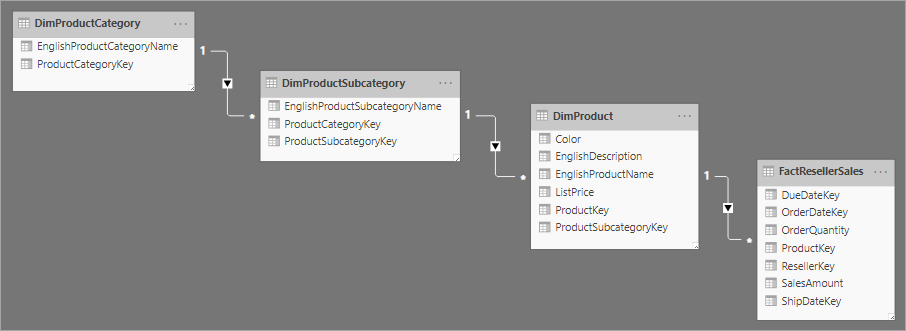
Den största skillnaden mellan star- och snowflake-scheman är att dimensionerna i ett snowflake-schema normaliseras för att minska redundansen, vilket sparar lagringsutrymme. Kompromissen är att dina frågor kräver fler kopplingar, vilket kan öka din komplexitet och minska prestanda.