Definiera arkitektur, komponenter och funktioner i Datadeduplicering
De flesta organisationer och företag, inklusive Contoso, måste hantera bearbetning och lagring av en ökande mängd data. Det finns lösningar som gör att du kan avlasta och arkivera data till molnet, men i många fall är det nödvändigt att underhålla dem i lokala datacenter. Effektiv hantering av sådana data kräver rätt verktyg. När du använder Windows Server kan du använda för detta ändamål Datadeduplicering.
Vad är datadeduplicering?
Datadeduplicering är en rolltjänst för Windows Server som identifierar och tar bort dupliceringar i data utan att äventyra dataintegriteten. Detta uppnår målet att lagra mer data och använda mindre fysiskt diskutrymme.
För att minska diskanvändningen genomsöker Datadeduplicering filer och delar sedan upp filerna i segment och behåller endast en kopia av varje segment. Efter dedupliceringen lagras inte längre filer som oberoende dataströmmar. I stället ersätter Datadeduplicering filerna med punkter som pekar på datablock som lagras i ett gemensamt segmentlager. Processen för att komma åt deduplicerade data är helt transparent för användare och appar.
I många fall ökar dataduplicering övergripande diskprestanda, eftersom flera filer kan dela ett segment som cachelagras i minnet. På så sätt kan det vara möjligt att hämta data från dessa filer genom att utföra färre läsåtgärder, vilket kompenserar för en liten prestandapåverkan vid läsning av deduplicerade filer. Datadeduplicering påverkar inte prestandan för diskskrivningar eftersom den gäller för data som redan finns på disken.
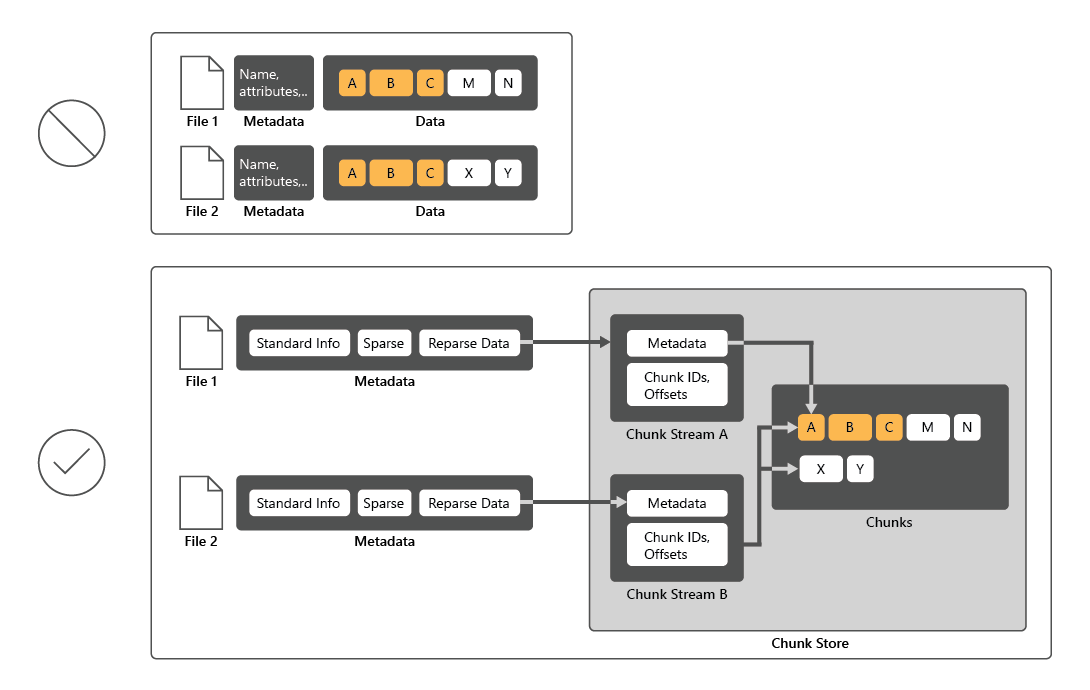
Vilka är komponenterna i Datadeduplicering?
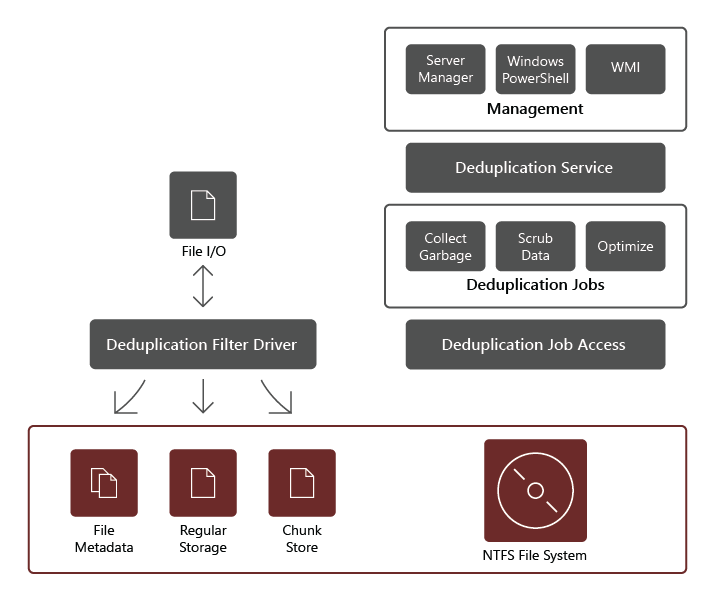
Rolltjänsten Datadeduplicering består av följande komponenter:
- Filterdrivrutin. Den här komponenten omdirigerar läsbegäranden till de segment som ingår i den fil som begärs. Det finns en filterdrivrutin för varje volym.
- Dedupliceringstjänsten. Den här komponenten hanterar följande jobb:
- Deduplicering och komprimering. De här jobben bearbetar filer enligt datadedupliceringsprincipen för volymen. Om filen sedan ändras och uppfyller tröskelvärdet för datadedupliceringsprincip för optimering, optimeras filen igen efter den inledande optimeringen av en fil.
- Skräpinsamling. Det här jobbet bearbetar borttagna eller ändrade data på volymen så att alla datasegment som inte längre refereras rensas, vilket ger ledigt diskutrymme. Som standard körs skräpinsamling varje vecka, men du kan också överväga att anropa den när du har raderat många filer.
- Skrubbning. Det här jobbet förlitar sig på sådana återhämtningsfunktioner som verifiering av kontrollsummor och konsekvenskontroll av metadata för att identifiera och, när det är möjligt, automatiskt lösa dataintegritetsproblem.
Kommentar
På grund av de ytterligare valideringsfunktionerna kan deduplicering identifiera och rapportera tidiga tecken på skadade data.
- Avoptimisering. Det här jobbet återställer dedupliceringen på alla optimerade filer på volymen. Några vanliga scenarier för att använda den här typen av jobb är felsökningsproblem med deduplicerade data eller migrering av data till ett annat system som inte stöder datadeduplicering.
Kommentar
Innan du startar det här jobbet bör du använda Windows PowerShell-cmdleten Disable-DedupVolume för att inaktivera ytterligare datadedupliceringsaktivitet på en eller flera volymer.
Kommentar
När du har inaktiverat Datadeduplicering förblir volymen i deduplicerat tillstånd och befintliga deduplicerade data är fortfarande tillgängliga. Servern slutar dock att köra optimeringsjobb för volymen och deduplicerar inte de nya data. Därefter kan du använda avoptimiseringsjobbet för att ångra befintliga deduplicerade data på en volym. I slutet av ett lyckat deoptimeringsjobb tas alla datadedupliceringsmetadata bort från volymen.
Viktigt!
När du använder avoptimiseringsjobbet kontrollerar du att volymen som är värd för dessa data har tillräckligt med ledigt utrymme eftersom alla deduplicerade filer återgår till sin ursprungliga storlek.
Omfång för datadeduplicering
Datadeduplicering bearbetar alla data på en vald volym, med några undantag, inklusive:
- Filer som inte uppfyller den dedupliceringsprincip som du konfigurerar.
- Filer i mappar som du uttryckligen undantar från dedupliceringens omfång.
- Systemtillståndsfiler.
- Alternativa dataströmmar.
- Krypterade filer.
- Filer med utökade attribut.
- Filer som är mindre än 32 KB.
Kommentar
Sedan Windows Server 2019 stöder Resilient File System (ReFS) datadeduplicering för volymer på upp till 64 terabyte (TB) i storlek och filer med upp till 4 TB i storlek. Det förlitar sig också på ett segmentlager med variabel storlek som innehåller valfri komprimering för att maximera diskutrymmesbesparingarna, medan arkitekturen med flera trådar efter bearbetning håller prestandapåverkan minst.