summarize işleci
Giriş tablosunun içeriğini toplayan bir tablo oluşturur.
Syntax
T| summarize [ SummarizeParameters ] [[Sütun=] Toplama [, ...]] [by [Sütun=] GroupExpression [, ...]]
Söz dizimi kuralları hakkında daha fazla bilgi edinin.
Parametreler
| Ad | Tür | Gerekli | Açıklama |
|---|---|---|---|
| Sütun | string |
Sonuç sütununun adı. Varsayılan olarak ifadeden türetilen bir addır. | |
| Toplama | string |
✔️ | sütun adlarını bağımsız değişken olarak içeren veya avg()gibi count()bir toplama işlevine yapılan çağrı. |
| GroupExpression | Skalar | ✔️ | Giriş verilerine başvurabilen skaler ifade. Çıktı, tüm grup ifadelerinin ayrı değerleri olduğu kadar çok kayda sahip olur. |
| SummarizeParameters | string |
Davranışı denetleen Ad=Değeri biçiminde sıfır veya daha fazla boşlukla ayrılmış parametre. Desteklenen parametrelere bakın. |
Not
Giriş tablosu boş olduğunda, çıkış GroupExpression'ın kullanılıp kullanılmadığına bağlıdır:
- GroupExpression sağlanmazsa, çıkış tek bir (boş) satır olur.
- GroupExpression sağlanırsa, çıktıda satır olmaz.
Desteklenen parametreler
| Ad | Açıklama |
|---|---|
hint.num_partitions |
Küme düğümlerinde sorgu yükünü paylaşmak için kullanılan bölüm sayısını belirtir. Bkz . karıştırma sorgusu |
hint.shufflekey=<key> |
Sorgu, shufflekey verileri bölümleme anahtarını kullanarak küme düğümlerinde sorgu yükünü paylaşır. Bkz . karıştırma sorgusu |
hint.strategy=shuffle |
Strateji shuffle sorgusu, her düğümün verilerin bir bölümünü işleyeceği küme düğümlerinde sorgu yükünü paylaşır. Bkz . karıştırma sorgusu |
Döndürülenler
Giriş satırları, ifadelerin by aynı değerlerine sahip gruplar halinde düzenlenir. Ardından, belirtilen toplama işlevleri her grup üzerinde hesaplanır ve her grup için bir satır oluşturulur. Sonuç, her hesaplanan toplama için sütunları ve en az bir sütunu içerir by . (Bazı toplama işlevleri birden çok sütun döndürür.)
Sonuç, farklı değer bileşimleri by (sıfır olabilir) kadar çok satıra sahiptir. Sağlanan grup anahtarı yoksa, sonucun tek bir kaydı vardır.
Sayısal değer aralıklarını özetlemek için, aralıkları ayrık değerlere küçültmek için kullanın bin() .
Not
- Hem toplama hem de gruplandırma ifadeleri için rastgele ifadeler sağlayabilmenize rağmen, basit sütun adlarını kullanmak veya sayısal bir sütuna uygulamak
bin()daha verimlidir. - Tarih saat sütunları için otomatik saatlik bölmeler artık desteklenmiyor. Bunun yerine açık gruplama kullanın. Örneğin,
summarize by bin(timestamp, 1h).
Toplamaların varsayılan değerleri
Aşağıdaki tabloda toplamaların varsayılan değerleri özetlemektedir:
| Operatör | Varsayılan değer |
|---|---|
count(), countif(), dcount(), dcountif(), count_distinct(), sum(), sumif(), variance(), varianceif(), stdev(), stdevif() |
0 |
make_bag(), make_bag_if(), make_list(), make_list_if(), make_set(), make_set_if() |
boş dinamik dizi ([]) |
| Diğerleri | null |
Not
Bu toplamalar null değerler içeren varlıklara uygulanırken, null değerler yoksayılır ve hesaplamayı dikkate almaz. Örnekler için bkz. Varsayılan değerleri toplama.
Örnekler
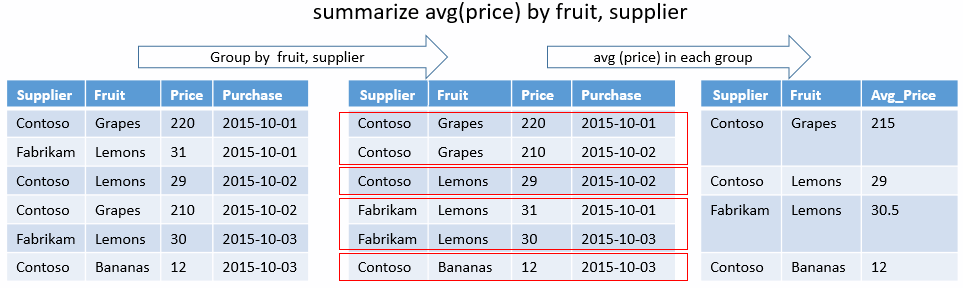
Benzersiz birleşim
Aşağıdaki sorgu, hangi benzersiz birleşimlerin StateEventType ve doğrudan yaralanmaya neden olan fırtınalar için olduğunu belirler. Toplama işlevi yoktur, yalnızca gruplandırma tuşları vardır. Çıkışta yalnızca bu sonuçların sütunları gösterilir.
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
Çıkış
Aşağıdaki tabloda yalnızca ilk 5 satır gösterilmektedir. Çıkışın tamamını görmek için sorguyu çalıştırın.
| Durum | Olay türü |
|---|---|
| TEXAS | Fırtına Rüzgarı |
| TEXAS | Ani Sel |
| TEXAS | Kış Hava Durumu |
| TEXAS | Yüksek Rüzgar |
| TEXAS | Sel |
| ... | ... |
Minimum ve maksimum zaman damgası
Hawaii'deki en düşük ve en yüksek şiddetli yağmur fırtınalarını bulur. Group-by yan tümcesi olmadığından çıktıda yalnızca bir satır vardır.
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
Çıkış
| Min | En yüksek değer |
|---|---|
| 01:08:00 | 11:55:00 |
Ayrı sayı
Etkinliklerin gerçekleştiği şehirlerin sayısını gösteren her kıta için bir satır oluşturun. "Kıta" için az sayıda değer olduğundan, 'by' yan tümcesinde gruplandırma işlevi gerekmez:
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
Çıkış
Aşağıdaki tabloda yalnızca ilk 5 satır gösterilmektedir. Çıkışın tamamını görmek için sorguyu çalıştırın.
| Durum | TypesOfStorms |
|---|---|
| TEXAS | 27 |
| CALİFORNİA | 26 |
| PENNSYLVANIA | 25 |
| GÜRCİSTAN | 24 |
| ILLİNOİS | 23 |
| ... | ... |
Histogram
Aşağıdaki örnek, 1 günden uzun süren fırtınalara sahip bir histogram fırtına olayı türünü hesaplar. Birçok değeri olduğundan Duration , değerlerini 1 günlük aralıklar halinde gruplandırmak için kullanın bin() .
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
Çıkış
| Olay türü | Uzunluk | EventCount |
|---|---|---|
| Kurak -lık | 30.00:00:00 | 1646 |
| Wildfire | 30.00:00:00 | 11 |
| Isı | 30.00:00:00 | 14 |
| Sel | 30.00:00:00 | 20 |
| Şiddetli Yağmur | 29.00:00:00 | 42 |
| ... | ... | ... |
Varsayılan değerleri toplar
İşleç girişi summarize en az bir boş gruplandırma ölçütü anahtarına sahip olduğunda, sonucu da boş olur.
İşleç girişinin summarize group-by anahtarı boş olmadığında sonuç, toplamaların summarize varsayılan değerleridir. Daha fazla bilgi için bkz. Toplamaların varsayılan değerleri.
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
Çıkış
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | max_x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NaN | 0 | 0 | 0 | 0 |
sonucunun avg_x(x)NaN 0'a bölünmesi gerekir.
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
Çıkış
| count_x | Countıf_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
Çıkış
| set_x | list_x |
|---|---|
| [] | [] |
Toplam ortalama null olmayan tüm değerleri toplar ve yalnızca hesaplamaya katılanları sayar (null değerleri dikkate almaz).
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
Çıkış
| sum_y | avg_y |
|---|---|
| 15 | 5 |
Normal sayı null değerleri sayar:
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
Çıkış
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
Çıkış
| set_y | set_y1 |
|---|---|
| [5.0] | [5.0] |
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin