Geveze G/Ç kötü modeli
Çok sayıda G/Ç isteğinin toplu etkisi, performansta ve yanıtlama hızında büyük bir değişikliğe neden olabilir.
Sorun açıklaması
Ağ çağrıları ve diğer G/Ç işlemleri, yapıları itibarıyla işlem görevlerine göre yavaştır. Her G/Ç isteğinin normal olarak ciddi miktarda ek yükü vardır ve çok sayıda G/Ç işleminin toplu etkisi sistemi yavaşlatabilir. Geveze G/Ç’nin bazı yaygın nedenleri aşağıdadır.
Bir veritabanında tek tek kayıtları ayrı istekler olarak okuma ve yazma
Aşağıdaki örnek bir ürün veritabanından okumaktadır. Product, ProductSubcategory ve ProductPriceListHistory olarak üç tablo vardır. Kod, bir dizi sorgu yürüterek bir alt kategorideki tüm ürünleri fiyatlandırma bilgileriyle birlikte alır:
ProductSubcategorytablosundan alt kategoriyi sorgulayın.Producttablosunu sorgulayarak söz konusu alt kategorideki tüm ürünleri bulun.- Her bir ürün için
ProductPriceListHistorytablosundan fiyatlandırma verilerini sorgulayın.
Uygulama, veritabanını sorgulamak için Entity Framework’ü kullanır. Örneğin tamamını burada bulabilirsiniz.
public async Task<IHttpActionResult> GetProductsInSubCategoryAsync(int subcategoryId)
{
using (var context = GetContext())
{
// Get product subcategory.
var productSubcategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subcategoryId)
.FirstOrDefaultAsync();
// Find products in that category.
productSubcategory.Product = await context.Products
.Where(p => subcategoryId == p.ProductSubcategoryId)
.ToListAsync();
// Find price history for each product.
foreach (var prod in productSubcategory.Product)
{
int productId = prod.ProductId;
var productListPriceHistory = await context.ProductListPriceHistory
.Where(pl => pl.ProductId == productId)
.ToListAsync();
prod.ProductListPriceHistory = productListPriceHistory;
}
return Ok(productSubcategory);
}
}
Bu örnekte sorun açıkça gösterilmektedir, ancak bazen bir O/RM alt kayıtları örtük olarak teker teker getiriyorsa sorunu maskeleyebilir. Bu duruma "N+1 sorunu" adı verilir.
Tek bir mantıksal işlemi bir dizi HTTP isteği olarak uygulama
Bu durum, genellikle geliştiriciler nesneye dayalı bir yaklaşım izleyip uzak nesnelere bellekteki yerel nesnelermiş gibi davrandıklarında ortaya çıkar. Bunun sonucunda ağda çok fazla gidiş dönüş yaşanabilir. Örneğin, aşağıdaki web API'si ayrı HTTP GET yöntemleri aracılığıyla User nesnelerinin özelliklerini bireysel olarak kullanıma sunar.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}/username")]
public HttpResponseMessage GetUserName(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/gender")]
public HttpResponseMessage GetGender(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/dateofbirth")]
public HttpResponseMessage GetDateOfBirth(int id)
{
...
}
}
Bu yaklaşımda teknik yönden yanlış bir şey yoktur, ancak birçok istemcinin büyük olasılıkla her bir User için çeşitli özellikler alması gerekecektir. Bu durum da aşağıdaki gibi istemci kodlarına yol açar.
HttpResponseMessage response = await client.GetAsync("users/1/username");
response.EnsureSuccessStatusCode();
var userName = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/gender");
response.EnsureSuccessStatusCode();
var gender = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/dateofbirth");
response.EnsureSuccessStatusCode();
var dob = await response.Content.ReadAsStringAsync();
Disk üzerindeki bir dosyada okuma ve yazma
Dosya G/Ç’si bir dosyanın açılmasını ve veri okumadan veya yazmadan önce uygun noktaya gidilmesini içerir. İşlem tamamlandığında işletim sistemi kaynaklarından tasarruf etmek için dosya kapanabilir. Bir dosyada sürekli olarak küçük miktarlarda bilgi okuyan ve yazan bir uygulama ciddi oranda G/Ç ek yükü oluşturur. Küçük yazma istekleri ayrıca dosya parçalanmasına yol açarak daha sonraki G/Ç işlemlerinin daha da yavaşlamasına neden olabilir.
Aşağıdaki örnekte, FileStream kullanılarak bir dosyaya bir Customer nesnesi yazılmaktadır. FileStream oluşturulması dosyayı açar ve bunun atılması dosyayı kapatır. (deyimi using nesneyi otomatik olarak atar FileStream .) Uygulama yeni müşteriler eklendikçe bu yöntemi tekrar tekrar çağırırsa G/Ç ek yükü hızla birikebilir.
private async Task SaveCustomerToFileAsync(Customer customer)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
byte [] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
Sorunun çözümü
Verileri daha az sayıda, daha büyük istekler şeklinde paketleyerek G/Ç isteklerinin sayısını azaltın.
Verileri veritabanından çeşitli küçük sorgular yerine tek bir sorgu olarak getirin. Ürün bilgilerini alan kodun düzeltilmiş bir hali aşağıdadır.
public async Task<IHttpActionResult> GetProductCategoryDetailsAsync(int subCategoryId)
{
using (var context = GetContext())
{
var subCategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subCategoryId)
.Include("Product.ProductListPriceHistory")
.FirstOrDefaultAsync();
if (subCategory == null)
return NotFound();
return Ok(subCategory);
}
}
Web API’leri için REST tasarım ilkelerini uygulayın. Yukarıdaki örnekteki web API’sinin düzeltilmiş bir hali aşağıdadır. Her bir özellik için ayrı GET yöntemleri yerine tek bir GET yöntemi ile User döndürülmektedir. Bunun sonucunda istek başına yanıt hacmi artar, ancak her istemcinin yapacağı API çağrılarının sayısı büyük olasılıkla azalacaktır.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}")]
public HttpResponseMessage GetUser(int id)
{
...
}
}
// Client code
HttpResponseMessage response = await client.GetAsync("users/1");
response.EnsureSuccessStatusCode();
var user = await response.Content.ReadAsStringAsync();
Dosya G/Ç’si için bellekteki verileri arabelleğe alabilir ve arabelleğe alınmış verileri tek bir işlemde dosyaya yazabilirsiniz. Bu yaklaşım sayesinde dosyanın tekrar tekrar açılıp kapanmasından doğan ek yük düşürülür ve diskteki dosyanın parçalanması azaltılır.
// Save a list of customer objects to a file
private async Task SaveCustomerListToFileAsync(List<Customer> customers)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
foreach (var customer in customers)
{
byte[] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
}
// In-memory buffer for customers.
List<Customer> customers = new List<Customers>();
// Create a new customer and add it to the buffer
var customer = new Customer(...);
customers.Add(customer);
// Add more customers to the list as they are created
...
// Save the contents of the list, writing all customers in a single operation
await SaveCustomerListToFileAsync(customers);
Dikkat edilmesi gereken noktalar
İlk iki örnekte daha az G/Ç çağrısı yapılmakta ve her çağrıda daha fazla bilgi alınmaktadır. Bu iki faktörün karşılıklı avantaj ve dezavantajlarını dikkate almanız gerekir. Doğru yanıt, gerçek kullanım kalıplarınıza bağlıdır. Örneğin, web API’si örneğinde istemciler çoğu zaman yalnızca kullanıcı adına ihtiyaç duyuyor olabilir. Böyle bir durumda, bu bilginin ayrı bir API çağrısı olarak kullanıma sunulması mantıklı olabilir. Daha fazla bilgi için Fazlalık Getirme kötü modeline bakın.
Veri okurken G/Ç isteklerinizi çok büyük tutmayın. Uygulamalar, yalnızca kullanma olasılıkları olan bilgileri almalıdır.
Bazen bir nesneye ait bilgilerin iki parça halinde bölümlenmesi faydalı olabilir: isteklerin çoğuna karşılık veren sık erişilen veriler ve nadiren kullanılan daha seyrek erişilen veriler. En sık erişilen veriler, çoğu zaman nesneye ait tüm verilerin nispeten küçük bir kısmıdır. Bu nedenle, sadece bu kısmın döndürülmesi G/Ç ek yükünü önemli ölçüde azaltabilir.
Veri yazarken kaynakları gereğinden uzun süre kilitlemekten kaçının. Böylece uzun işlemler sırasında çekişme olasılığı azaltılır. Bir yazma işlemi birden çok veri deposu, dosya veya hizmeti kapsıyorsa nihai tutarlılık yaklaşımını benimseyin. Bkz. Veri Tutarlılığı kılavuzu.
Verileri yazmadan önce bellekte arabelleğe alıyorsanız işlem kilitlenirse veriler savunmasızdır. Veri oranı genellikle ani artışlar içeriyorsa veya nispeten seyrekse verilerin Event Hubs gibi dayanıklı bir dış kuyrukta arabelleğe alınması daha güvenli olabilir.
Bir hizmet veya veritabanından alınan verileri önbelleğe almanız iyi bir fikir olabilir. Bu sayede, aynı verilere yönelik yinelenen isteklerden kaçınılarak G/Ç hacmi azaltılabilir. Daha fazla bilgi için bkz. Önbelleğe alma ile ilgili en iyi deneyimler.
Sorunu algılama
Geveze G/Ç durumunun belirtileri, gecikme sürelerinin yüksek ve aktarım hızının düşük olmasını içerir. G/Ç kaynakları için artan çekişme nedeniyle son kullanıcılar, uzayan yanıt süreleri veya hizmetlerin zaman aşımına uğramasından doğan hatalar bildirebilir.
Herhangi bir sorunun nedenini belirlemenize yardımcı olması için aşağıdaki adımları gerçekleştirebilirsiniz:
- Üretim sistemindeki süreçleri izleyerek uzun yanıt sürelerine sahip işlemleri belirleyin.
- Önceki adımda belirlenen her işlem için yük testi gerçekleştirin.
- Yük testleri sırasında, her bir işlem tarafından yapılan veri erişim istekleriyle ilgili telemetri verileri toplayın.
- Veri depolarına gönderilen her istek için ayrıntılı istatistikler toplayın.
- G/Ç performans sorunları ortaya çıkabilecek noktaları saptamak için test ortamında uygulamanın profilini oluşturun.
Aşağıdaki belirtilerin varlığını denetleyin:
- Aynı dosyaya yönelik çok sayıda küçük G/Ç isteği.
- Bir uygulama örneği tarafından aynı hizmete yönelik olarak yapılan çok sayıda küçük ağ isteği.
- Bir uygulama örneği tarafından aynı veri deposuna yönelik olarak yapılan çok sayıda küçük istek.
- Uygulamalar ve hizmetlerin G/Ç’ye bağlı bir hal alması.
Örnek tanılama
Aşağıdaki bölümlerde, bu adımlar yukarıdaki bir veritabanının sorgulandığı örneğe uygulanmaktadır.
Uygulamaya yük testi uygulama
Aşağıdaki grafikte yük testinin sonuçları gösterilmektedir. Ortanca yanıt süresi, istek başına saniyenin onda biri cinsinden ölçülmektedir. Grafikte gecikme süresinin çok yüksek olduğu görülmektedir. Yük 1000 kullanıcı olduğunda kullanıcıların yaptıkları sorgunun sonuçlarını görmek için yaklaşık bir dakika beklemesi gerekebilir.
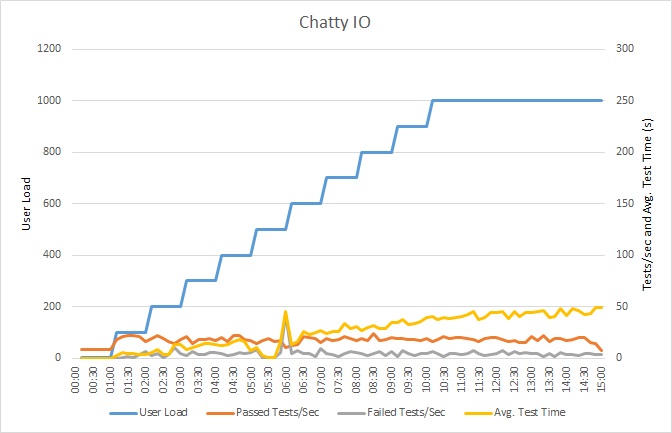
Dekont
Uygulama, Azure SQL Veritabanı kullanılıp bir Azure App Service web uygulaması olarak dağıtıldı. Yük testi, 1000 adede kadar eş zamanlı kullanıcı içeren, benzetimi yapılmış adımlı bir iş yükü kullandı. Bağlantı için çekişmenin sonuçları etkilemesi olasılığını azaltmak için veritabanı, 1000 adede kadar eş zamanlı bağlantıyı destekleyen bir bağlantı havuzu ile yapılandırıldı.
Uygulamayı izleme
Geveze G/Ç’yi tespit edebilecek ana ölçümleri yakalamak ve analiz etmek için bir uygulama performansı izleme (APM) paketi kullanabilirsiniz. Hangi ölçümlerin önemli olduğu G/Ç iş yüküne bağlıdır. Bu örnekte ilginç G/Ç istekleri veritabanı sorgularıydı.
Aşağıdaki resimde, New Relic APM kullanılarak üretilen sonuçlar gösterilmektedir. Ortalama veritabanı yanıt süresi, en fazla iş yükü sırasında istek başına yaklaşık 5,6 saniye ile en yüksek değerine ulaştı. Sistem, test boyunca dakika başına ortalama 410 isteği destekleyebildi.
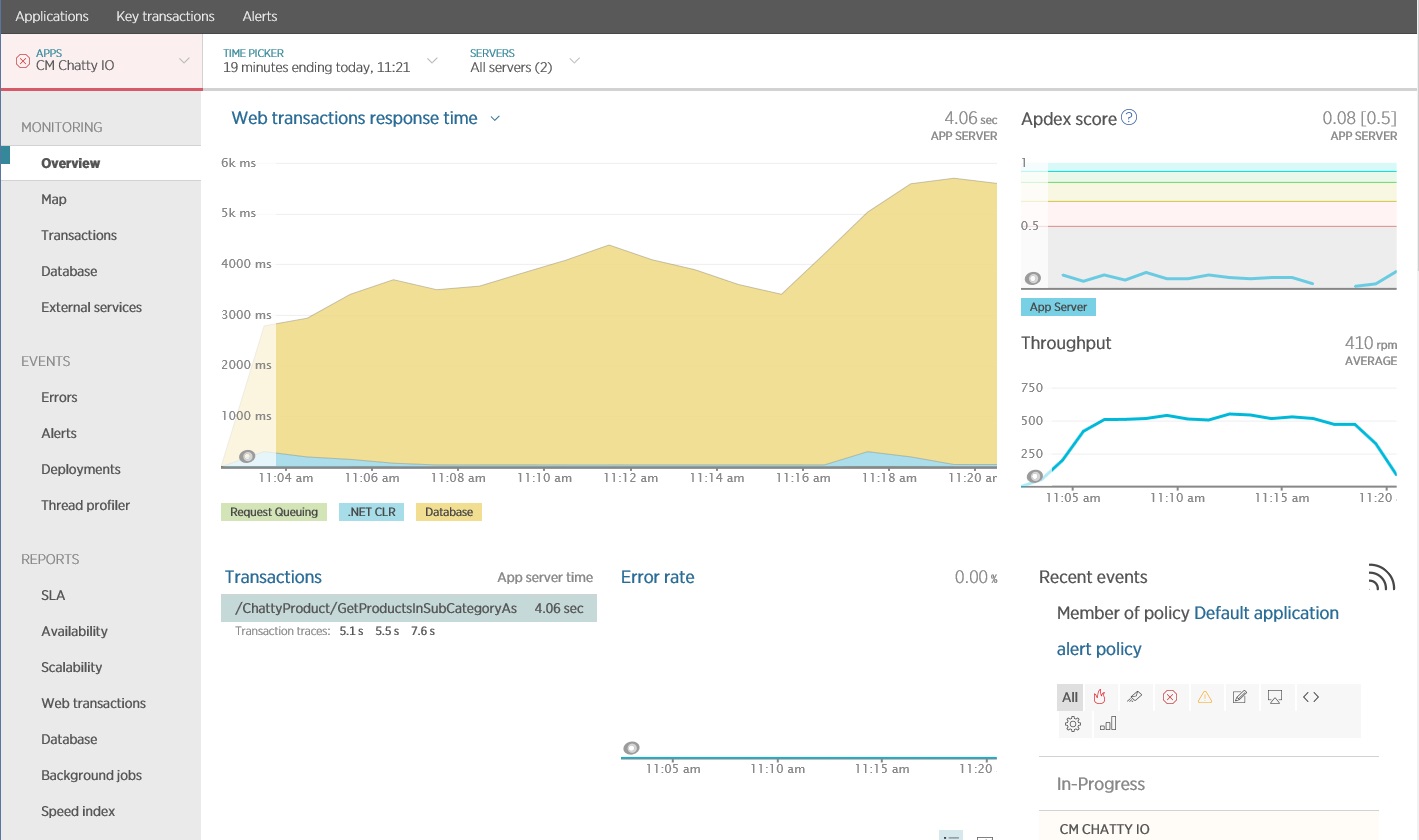
Ayrıntılı veri erişim bilgileri toplama
İzleme verilerine daha ayrıntılı olarak bakıldığında uygulamanın üç farklı SQL SELECT deyimi yürüttüğü görülmektedir. Bu deyimler ProductListPriceHistory, Product ve ProductSubcategory tablolarından veri getirmek için Entity Framework tarafından oluşturulan isteklere karşılık gelmektedir. Ayrıca, ProductListPriceHistory tablosundan veri alan sorgu, açık arayla en sık yürütülen SELECT deyimidir.

Daha önce gösterilmiş olan GetProductsInSubCategoryAsync yöntemi, 45 adet SELECT sorgusu gerçekleştirir. Her bir sorgu, uygulamanın yeni bir SQL bağlantısı açmasına neden olur.
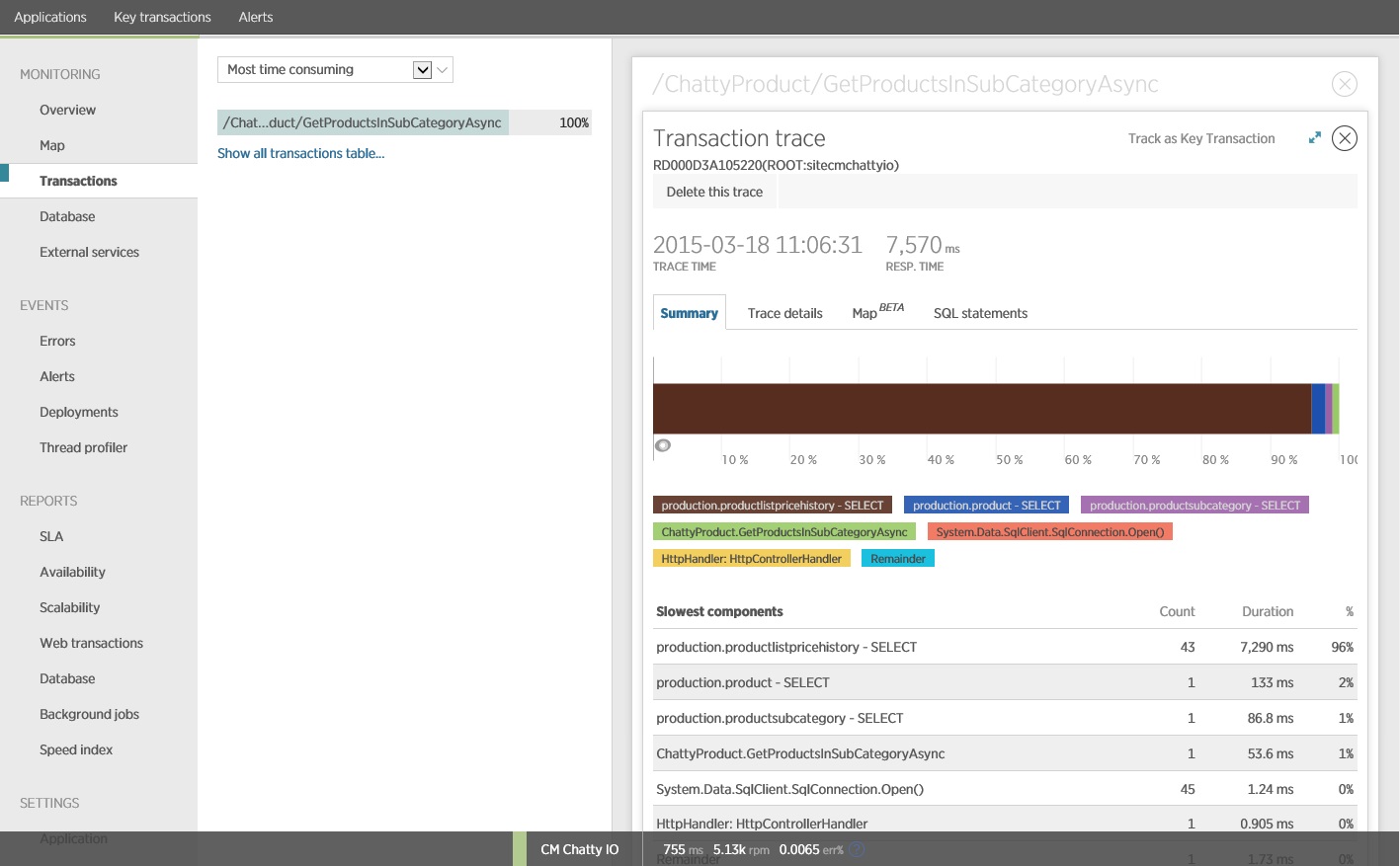
Dekont
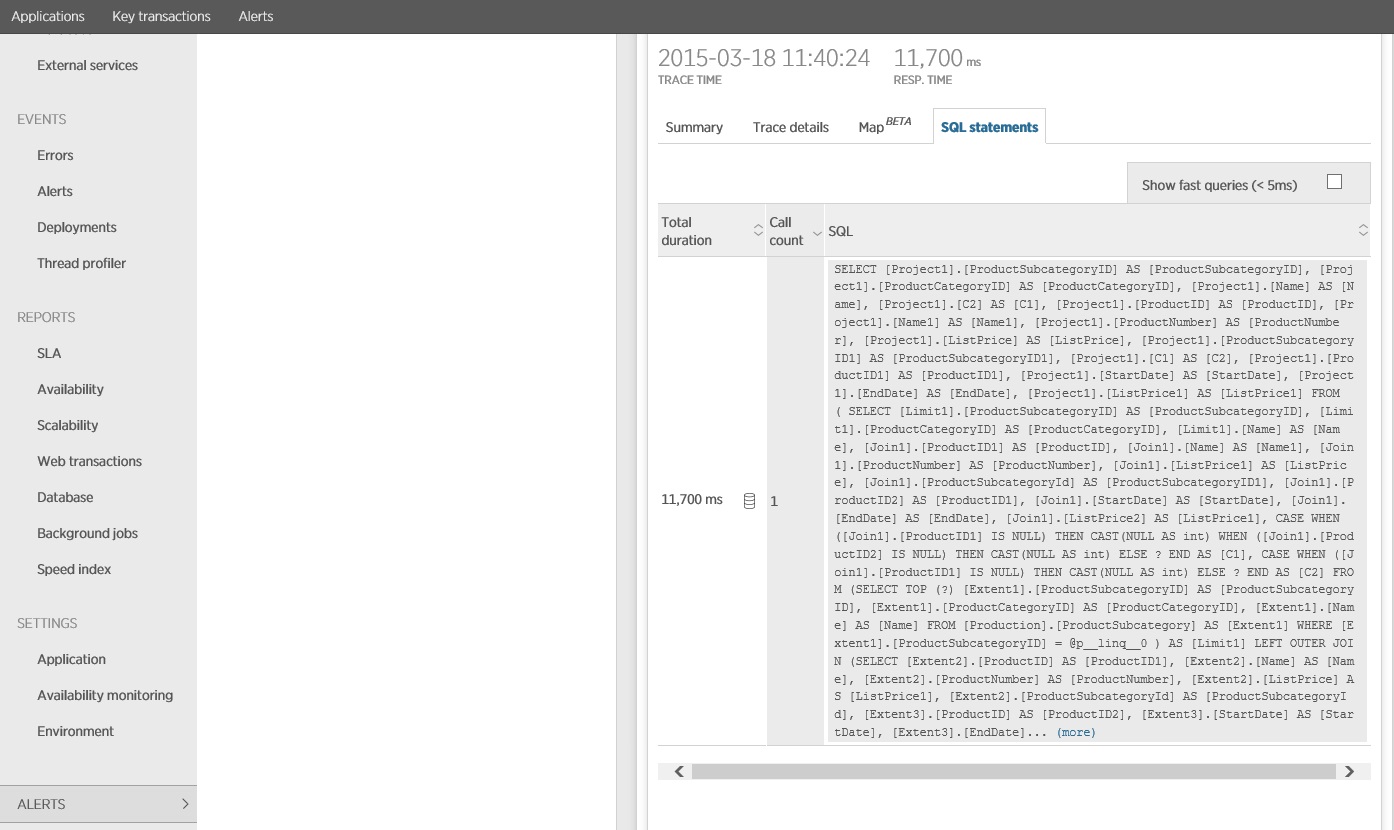
Bu resimde, yük testinde GetProductsInSubCategoryAsync işleminin en yavaş örneği için izleme bilgileri gösterilmektedir. Üretim ortamında, bir sorun olduğuna işaret eden bir kalıp olup olmadığını görmek için en yavaş örneklerin izlemelerinin incelenmesi kullanışlıdır. Yalnızca ortalama değerlere bakarsanız yük altında çok daha kötü bir hal alacak olan sorunları atlayabilirsiniz.
Sıradaki resimde, gönderilen gerçek SQL deyimleri gösterilmektedir. Fiyat bilgilerini getiren sorgu, ürün alt kategorisindeki her bir ürün için çalıştırılır. Bir birleşim kullanılması veritabanı çağrısı sayısını ciddi ölçüde azaltır.
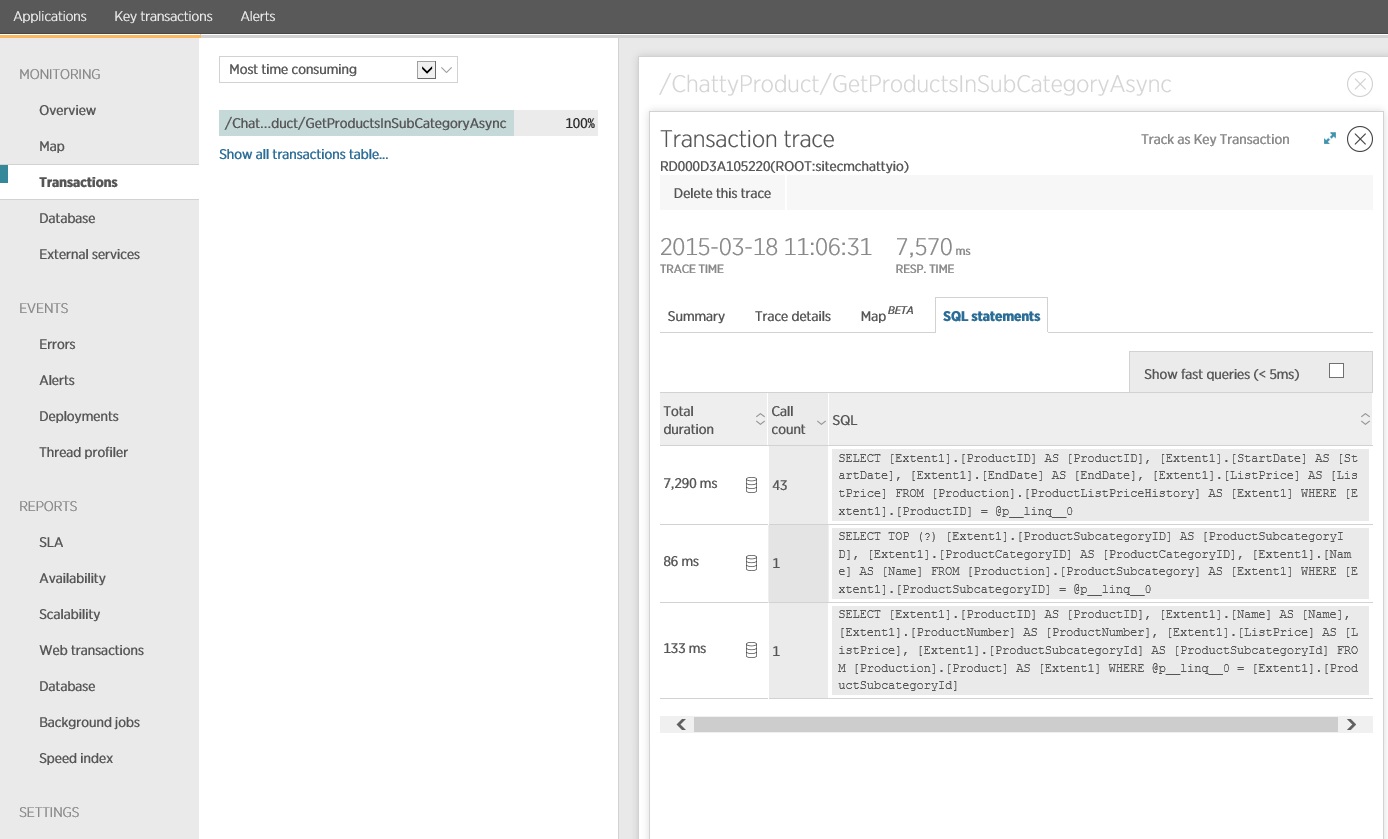
Entity Framework gibi bir O/RM kullanıyorsanız SQL sorgularının izlenmesi, O/RM’nin programlı çağrıları SQL deyimlerine nasıl çevirdiğinin daha iyi anlaşılmasını sağlayabilir ve veri erişiminin iyileştirilebileceği alanları belirtebilir.
Çözümü uygulama ve sonucu doğrulama
Entity Framework çağrısının yeniden yazılması aşağıdaki sonuçları üretti.
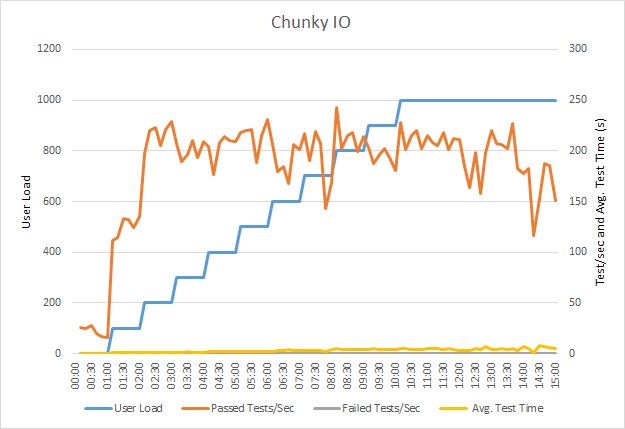
Bu yük testi, aynı yük profili kullanılarak aynı dağıtım üzerinde gerçekleştirildi. Grafik, bu kez çok daha düşük gecikme süresi göstermektedir. 1000 kullanıcı olduğunda ortalama istek zamanı, yaklaşık 1 dakikalık değerinden 5-6 saniyeye inmiştir.
Sistem, önceki testteki dakikada 410 istek yerine bu kez dakikada ortalama 3.970 isteği desteklemektedir.
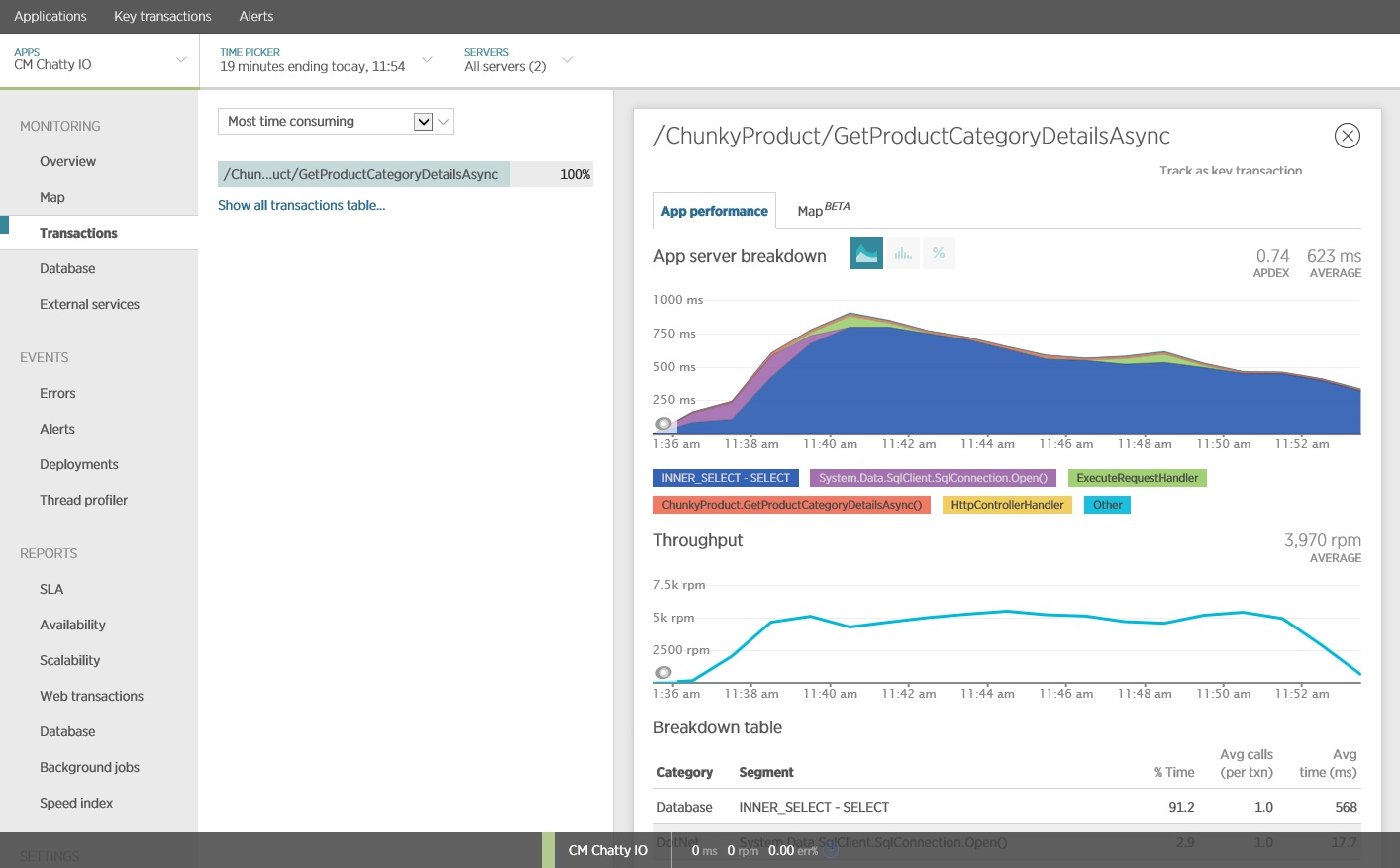
SQL deyiminin izlemesi, tüm verilerin tek bir SELECT deyiminde getirildiğini göstermektedir. Bu sorgu çok daha karmaşık olsa da işlem başına yalnızca bir kez gerçekleştirilir. Karmaşık birleştirmeler pahalı bir hal alabilir, ancak ilişkisel veritabanı sistemleri bu tür bir sorgu için iyileştirilmiştir.
İlgili kaynaklar
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin