Fazlalık Getirme kötü modeli
Anti-desenler, yazılımınızı veya uygulamalarınızı stres durumları altında bozabilen ve göz ardı edilmemesi gereken yaygın tasarım kusurlarıdır. Gereksiz bir getirme kötü modelinde, bir iş işlemi için gerekenden fazla veri alınır ve bu da genellikle gereksiz G/Ç ek yüküne ve yanıt hızının azalmasına neden olur.
Yabancı getirme kötü modeli örnekleri
Bu kötü model, uygulama ihtiyaç duyabileceği tüm verileri alarak G/Ç isteklerinin sayısını en aza indirmeye çalışırsa ortaya çıkabilir. Bu durum genellikle Geveze G/Ç kötü modelinin fazlasıyla telafi edilmesinin bir sonucudur. Örneğin, uygulama bir veritabanındaki her ürüne ait ayrıntıları getirebilir. Ancak kullanıcının ayrıntıların yalnızca bir kısmına ihtiyacı olabilir (bazı ayrıntılar müşterilerle ilgili olmayabilir). Ayrıca, kullanıcının büyük olasılıkla ürünlerin tamamını aynı anda görmesi gerekmiyordur. Kullanıcı kataloğun tamamına göz atsa bile, sonuçları sayfalandırmak mantıklı olur; örneğin, bir kerede 20'yi gösterir.
Bu sorunun bir diğer kaynağı da kötü programlama veya tasarım uygulamalarının kullanılmasıdır. Örneğin, aşağıdaki kod Entity Framework’ü kullanarak her ürüne ait tüm ayrıntıları getiriyor. Kod daha sonra sonuçları filtreleyerek alanların yalnızca bir bölümünü döndürüp kalanları atıyor. Örneğin tamamını burada bulabilirsiniz.
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
Sıradaki örnekte, uygulama bir toplama işlemi gerçekleştirmek için veri alıyor. Ancak, bu toplama işlemi veritabanı tarafından yapılabilir. Uygulama, toplam satış rakamını hesaplamak için satılan tüm siparişlere ait her kaydı alıyor ve toplamı bu kayıtlar üzerinden hesaplıyor. Örneğin tamamını burada bulabilirsiniz.
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
Sıradaki örnekte, Entity Framework’ün LINQ to Entities’i kullanma şekli nedeniyle ortaya çıkan ince bir sorun gösteriliyor.
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Uygulama, SellStartDate değeri bir haftadan daha eski olan ürünleri bulmaya çalışıyor. LINQ to Entities, çoğu durumda bir where yan tümcesini veritabanı tarafından yürütülen bir SQL deyimine çevirir. Ancak LINQ to Entities, bu durumda AddDays yöntemini SQL’e eşleyemiyor. Bu nedenle, Product tablosundaki her satır döndürülüyor ve sonuçlar bellekte filtreleniyor.
AsEnumerable çağrısı bir sorun olduğunun ipucunu veriyor. Bu yöntem, sonuçları bir IEnumerable arabirimine dönüştürür. IEnumerable filtrelemeyi desteklese de filtreleme işlemi veritabanında değil, istemci tarafında yapılır. LINQ to Entities, varsayılan olarak IQueryable arabirimini kullanır ve bu arabirim filtreleme sorumluluğunu veri kaynağına geçirir.
Gereksiz getirme kötü modeli nasıl düzeltilir?
Güncel olmaktan hızla çıkabilecek veya atılabilecek büyük miktarda veri getirmekten kaçının ve yalnızca gerçekleştirilmekte olan işlem için gereken verileri getirin.
Bir tablonun tüm sütunlarını alıp sonra filtrelemek yerine veritabanından gereksinim duyduğunuz sütunları seçin.
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
Benzer şekilde, toplama işlemini uygulama belleğinde değil, veritabanında gerçekleştirin.
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
Entity Framework kullanırken, LINQ sorgularının arabirimi IEnumerablekullanılarak değil kullanılarak çözümlendiğinden IQueryable emin olun. Sorguyu sadece veri kaynağına eşlenebilecek işlevleri kullanacak şekilde ayarlamanız gerekebilir. Önceki örnek yeniden düzenlenerek AddDays yöntemi sorgudan kaldırılabilir ve böylece filtreleme işlemi veritabanı tarafından yapılır.
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Dikkat edilmesi gereken noktalar
Bazı durumlarda, verileri yatay olarak bölümleyerek performans artırılabilir. Farklı operasyonlar verilerin farklı özniteliklerine erişiyorsa yatay bölümleme uygulanması çekişmeyi azaltabilir. Genellikle, operasyonların çoğu verilerin küçük bir kısmı üzerinde çalıştırılır, bu yükün dağıtılması performansı artırabilir. Bkz. Veri bölümleme.
Sınırsız sorguları desteklemesi gereken operasyonlar için sayfalandırma uygulayın ve aynı anda yalnızca sınırlı sayıda varlık getirin. Örneğin, müşteri bir ürün kataloğuna göz atıyorsa aynı anda yalnızca bir sayfalık sonuç gösterebilirsiniz.
Mümkün olduğunda veri deposunun yerleşik özelliklerinden yararlanın. Örneğin, SQL veritabanları genellikle toplama işlevleri sağlar.
Toplama gibi belirli bir işlevi desteklemeyen bir veri deposu kullanıyorsanız hesaplanan sonucu başka bir yerde depolayabilir ve kayıtlar eklendikçe veya güncelleştirildikçe depoladığınız değeri güncelleştirebilirsiniz. Böylece uygulamanın, her ihtiyacı olduğunda değeri baştan hesaplaması gerekmez.
İsteklerin çok sayıda alanı aldığını fark ederseniz bu alanların tümünün gerekli olup olmadığını belirlemek için kaynak kodu inceleyin. Bazen bu istekler kötü tasarlanmış bir
SELECT *sorgusunun sonucudur.Benzer şekilde, çok sayıda varlık alan istekler uygulamanın verileri doğru şekilde filtrelemediğinin göstergesi olabilir. Tüm bu varlıkların gerekli olup olmadığını denetleyin. Mümkünse, örneğin SQL’de
WHEREyan tümceleri aracılığıyla veritabanı tarafı filtrelemesi kullanın.İşleme faaliyetlerinin veritabanına aktarılması her zaman en iyi seçenek değildir. Bu stratejiyi yalnızca veritabanı buna göre tasarlanmış ya da iyileştirilmiş olduğunda kullanın. Veritabanı sistemlerinin çoğu belirli işlevler için son derece iyileştirilmiştir, ancak genel amaçlı uygulama altyapıları gibi davranmak üzere tasarlanmamıştır. Daha fazla bilgi için bkz. Meşgul Veritabanı kötü modeli.
Yabancı getirme kötü modeli algılama
Fazlalık getirme durumunun belirtileri, gecikme sürelerinin yüksek ve aktarım hızının düşük olmasını içerir. Veriler bir veri deposundan alınıyorsa çekişmenin artması da mümkündür. Son kullanıcılar büyük olasılıkla genişletilmiş yanıt süreleri veya hizmetlerin zaman aşımına uğramasından kaynaklanan hataları bildirecek. Bu hatalar HTTP 500 (İç Sunucu) hataları veya HTTP 503 (Hizmet Kullanılamıyor) hataları döndürebilir. Web sunucusunun olay günlüklerini inceleyin. Bu günlüklerde büyük olasılıkla hataların nedenleri ve koşulları hakkında ayrıntılı bilgiler bulunur.
Bu kötü modelin belirtileri ve alınan bazı telemetri verileri Tek Parça Kalıcılık kötü modeline çok benzer olabilir.
Nedeni belirlemenize yardımcı olması için aşağıdaki adımları gerçekleştirebilirsiniz:
- Yük testi, işlem izleme ya da izleme verileri yakalamaya yönelik başka yöntemlerle yavaş iş yükleri veya işlemleri tespit edin.
- Sistem tarafından sergilenen tüm davranış kalıplarını gözlemleyin. Saniye başına işlem veya kullanıcı sayısı açısından belirli bir sınır var mı?
- Yavaş iş yükü durumları ile davranış kalıpları arasında ilişki kurun.
- Kullanılan veri depolarını belirleyin. Her veri kaynağı için alt düzeyde telemetri çalıştırarak işlemlerin davranışını gözlemleyin.
- Bu veri kaynaklarına başvuran tüm yavaş çalışan sorguları belirleyin.
- Yavaş çalışan sorguların kaynağa özel analizini gerçekleştirin, verilerin nasıl kullanıldığını ve tüketildiğini saptayın.
Aşağıdaki belirtilerin varlığını denetleyin:
- Aynı kaynağa veya veri deposuna gönderilen sık, büyük G/Ç istekleri.
- Paylaşılan bir kaynakta veya veri deposunda çekişme.
- Ağ üzerinden sık sık yüksek miktarda veri alan bir işlem.
- G/Ç’nin tamamlanması için ciddi bir süre bekleyen uygulama ve hizmetler.
Örnek tanılama
Aşağıdaki bölümlerde, bu adımlar yukarıdaki örneklere uygulanmaktadır.
Yavaş iş yüklerini tespit etme
Aşağıdaki grafik, 400 adede kadar eşzamanlı kullanıcının daha önce gösterilen GetAllFieldsAsync yöntemini çalıştırmasının benzetimini yapan bir yük testinin performans sonuçlarını göstermektedir. Yük arttıkça aktarım hızı yavaşça azalır. İş yükü arttıkça ortalama yanıt süresi artar.
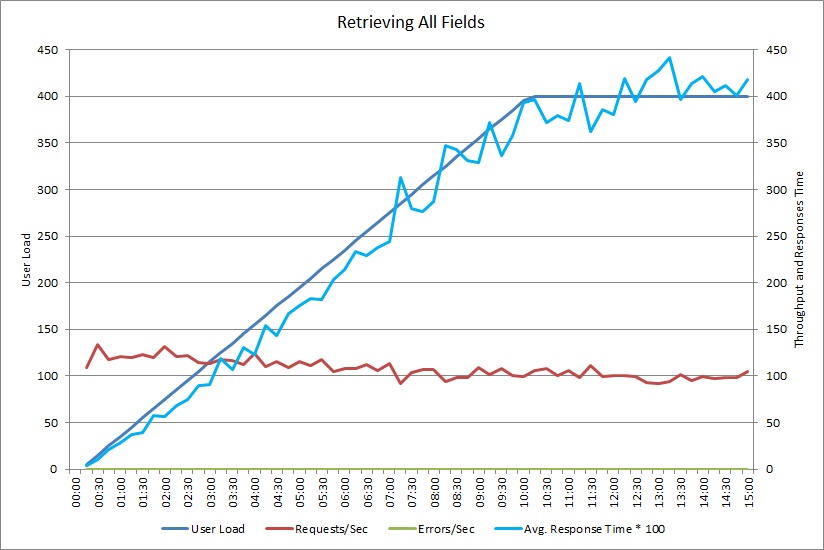
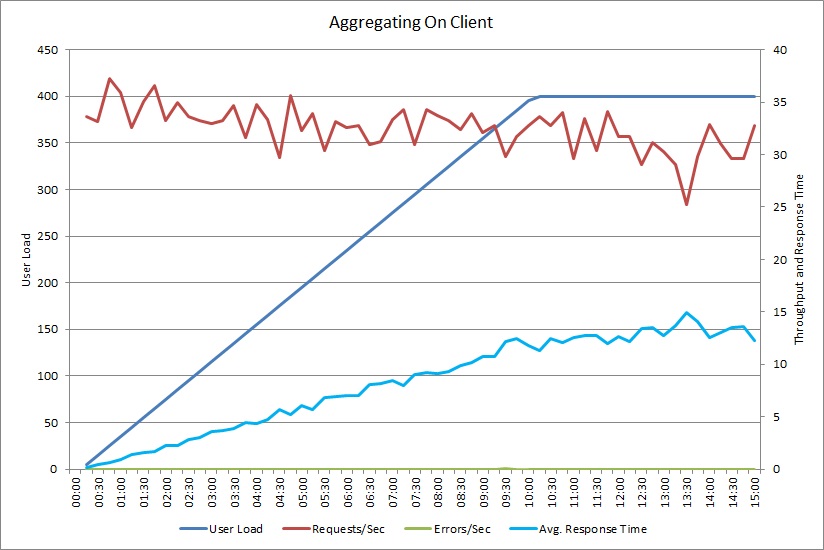
AggregateOnClientAsync işlemine yönelik bir yük testi de benzer bir düzen gösterir. İstek hacmi nispeten sabittir. İş yükü arttıkça ortalama yanıt süresi de artar, ancak bu artış önceki grafiğe göre daha yavaş gerçekleşir.
Yavaş iş yükleri ile davranış kalıpları arasında ilişki kurma
Düzenli olarak yüksek kullanım yaşanan dönemler ile performans düşmesi arasındaki herhangi bir ilişki sorunlu bir alana işaret ediyor olabilir. Yavaş çalıştığından şüphelenilen işlevlerin performans profilini yakından inceleyin. Bu profilin daha önce gerçekleştirilen yük testi ile eşleşip eşleşmediğini belirleyin.
Adım bazlı kullanıcı yükleri kullanarak aynı işlevin yük testini yapın ve performansın ciddi ölçüde düştüğü veya tamamen sıfırlandığı noktayı bulun. Bu nokta gerçek dünyada beklediğiniz kullanım sınırları dahilindeyse işlevin nasıl uygulandığını inceleyin.
Yavaş bir işlem mutlaka bir sorun değildir. Sistem baskı altında olduğunda gerçekleştirilmiyorsa, zaman açısından kritik değilse ve başka önemli işlemlerin performansını olumsuz etkilemiyorsa bir sorun olarak görülmeyebilir. Örneğin, aylık operasyonel istatistiklerin üretilmesi uzun süren bir işlem olabilir, ancak toplu bir işlem olarak yürütülüp düşük öncelikli bir iş olarak çalıştırılabilir. Öte yandan, müşterilerin ürün kataloğunu sorgulaması kritik bir iş işlemidir. Yüksek kullanım dönemleri sırasında performansın nasıl değiştiğini görmek için bu kritik işlemler tarafından üretilen telemetri üzerinde odaklanın.
Yavaş iş yüklerindeki veri kaynaklarını belirleme
Bir hizmetin veri alma şekli nedeniyle kötü performans gösterdiğinden şüpheleniyorsanız uygulamanın kullandığı depolar ile nasıl etkileştiğini araştırın. Kötü performans gösterildiği sırada hangi kaynaklara erişildiğini görmek için canlı sistemi izleyin.
Her bir veri kaynağı için sistemi izleyerek aşağıdakileri yakalayın:
- Her bir veri deposuna erişim sıklığı.
- Veri deposunda giriş ve çıkış yapan veri hacmi.
- Bu işlemlerin süreleri, özellikle isteklerin gecikme süresi.
- Tipik bir yük altında her bir veri deposuna erişilirken oluşan hataların doğası ve oranı.
Bu bilgileri, uygulama tarafından istemciye döndürülen veri hacmine göre karşılaştırın. Veri deposu tarafından döndürülen veri hacminin istemciye döndürülen veri hacmine oranını izleyin. Büyük bir fark varsa uygulamanın gerek duymadığı veriler getirip getirmediğini araştırın.
Bu verileri yakalamak için canlı sistemi gözlemleyip her kullanıcı isteğinin yaşam döngüsünü izleyebilir veya bir dizi yapay iş yükü modelleyip bunları bir test sisteminde çalıştırabilirsiniz.
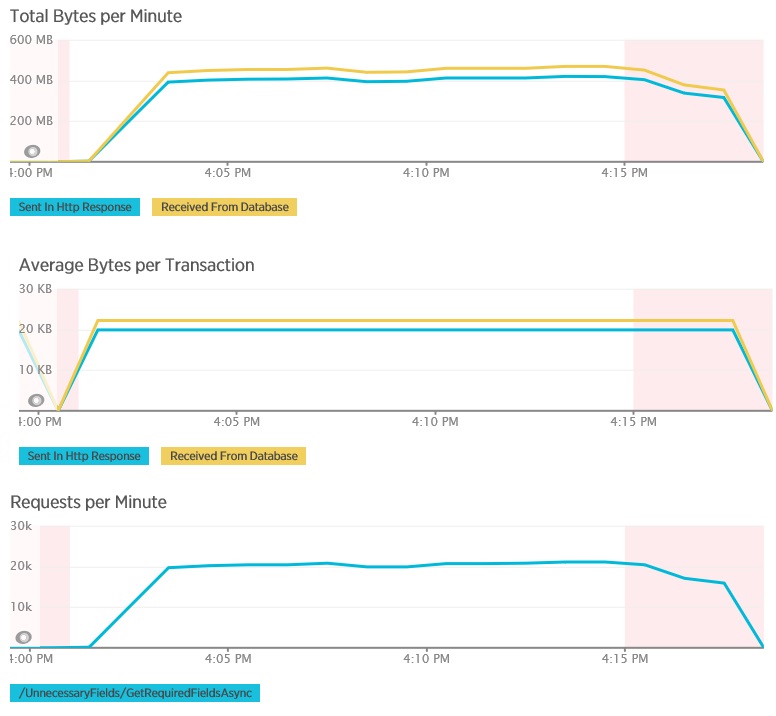
Aşağıdaki grafiklerde, GetAllFieldsAsync yönteminin yük testi sırasında New Relic APM kullanılarak yakalanan telemetri gösterilmektedir. Veritabanından ve ilgili HTTP yanıtlarından alınan veri hacimleri arasındaki farka dikkat edin.
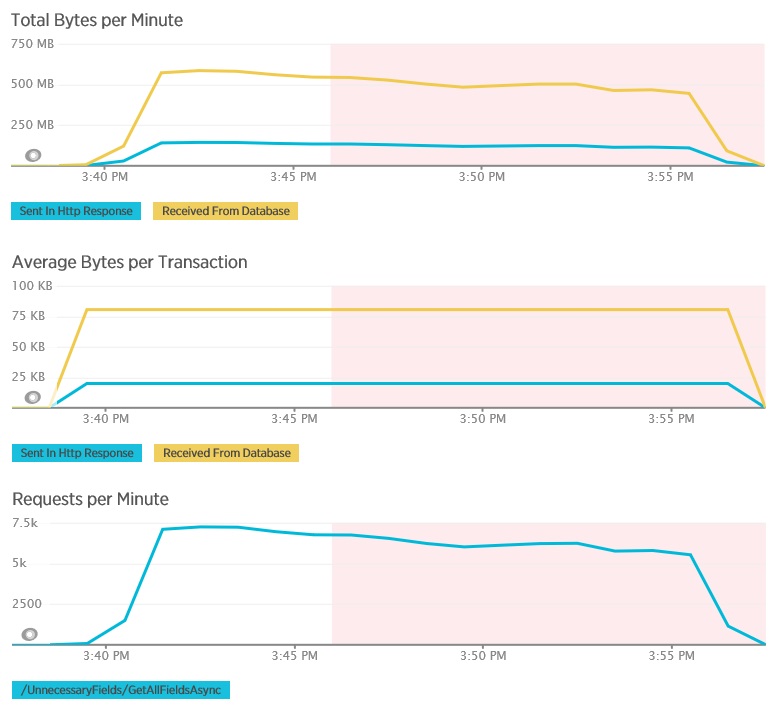
Her bir istek için veritabanı 80.503 bayt döndürdü, ancak istemciye giden yanıtta yalnızca veritabanı yanıtının %25’i civarında 19.855 bayt vardı. İstemciye döndürülen verilerin boyutu biçime bağlı olarak değişebilir. Bu yük testi için istemci JSON verileri istedi. XML kullanarak yapılan ayrı bir test (gösterilmemektedir), veritabanı yanıtının %44’ü kadar olan 35.655 bayt yanıt boyutu gösterdi.
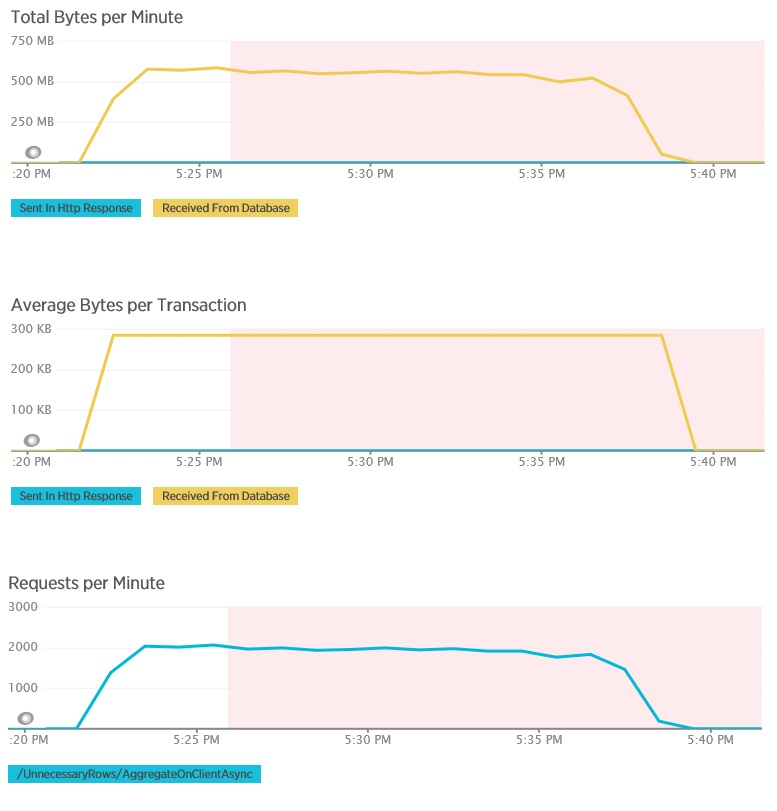
AggregateOnClientAsync yönteminin yük testi, daha aşırı sonuçlar göstermektedir. Bu durumda her test, veritabanından 280 KB’ın üzerinde veri alan bir sorgu gerçekleştirdi, ancak JSON yanıtı sadece 14 bayt boyutundaydı. Bu büyük farkın nedeni yöntemin yüksek miktarda veriden toplu bir sonuç hesaplamasıdır.
Yavaş sorguları belirleyin ve analiz edin
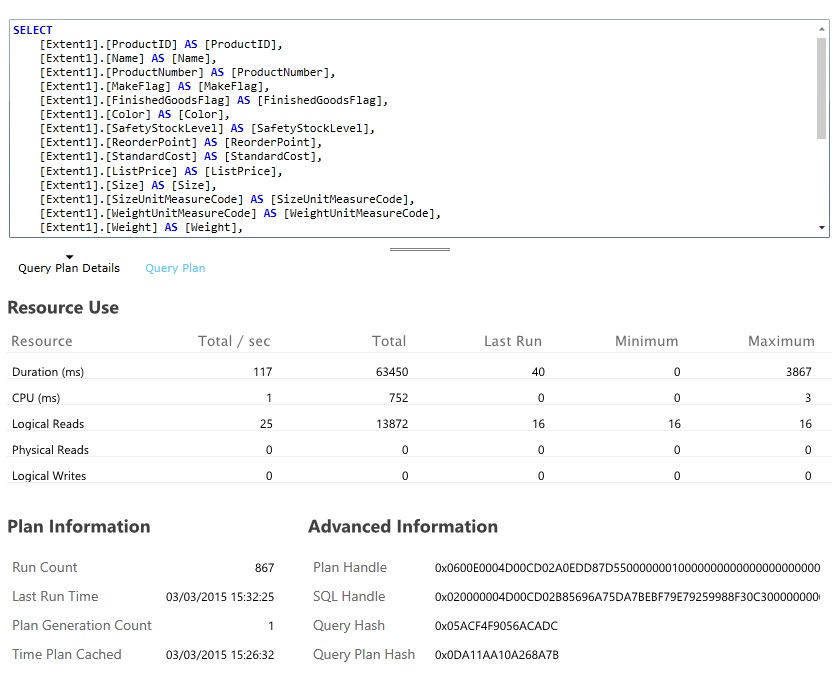
En fazla kaynak kullanan ve yürütülmesi en çok zaman alan veritabanı sorgularını bulun. Birçok veritabanı işleminin başlangıç ve tamamlanma zamanlarını bulmak için izleme ekleyebilirsiniz. Birçok veri deposu, sorguların nasıl gerçekleştirildiği ve iyileştirildiği hakkında ayrıntılı bilgi de sağlar. Örneğin, Azure SQL Veritabanı yönetim portalındaki Sorgu Performansı bölmesi bir sorgu seçip ayrıntılı çalışma zamanı performans bilgilerini görüntülemenize olanak sağlar. GetAllFieldsAsync işlemi tarafından oluşturulan sorgu aşağıdadır:
Çözümü uygulama ve sonucu doğrulama
GetRequiredFieldsAsync yöntemini veritabanı tarafında bir SELECT deyimi kullanacak şekilde değiştirdikten sonra yük testi aşağıdaki sonuçları gösterdi.
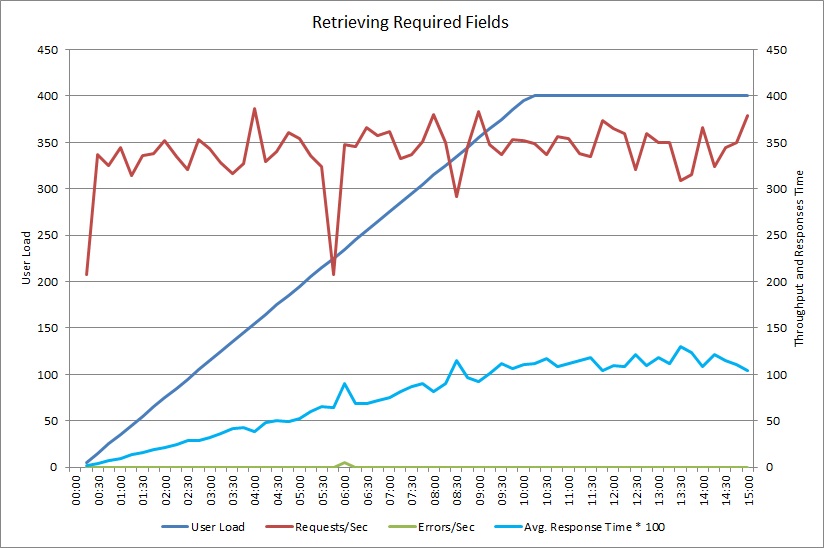
Bu yük testinde aynı dağıtım ve 400 eşzamanlı kullanıcıya göre benzetimi yapılmış aynı iş yükü kullanılmıştır. Grafik çok daha düşük gecikme süresi göstermektedir. Yanıt süresi, yükün artmasıyla birlikte yükselerek yaklaşık 1,3 saniyeye ulaşmaktadır. Önceki örnekte bu süre 4 saniyeydi. Aktarım hızı da daha önceki saniyede 100 istek değerine göre daha yüksek olup saniyede 350 istektir. Veritabanından alınan veri hacmi artık HTTP yanıt iletilerinin boyutuna oldukça yakındır.
AggregateOnDatabaseAsync yöntemi kullanarak yapılan yük testi aşağıdaki sonuçları oluşturur:
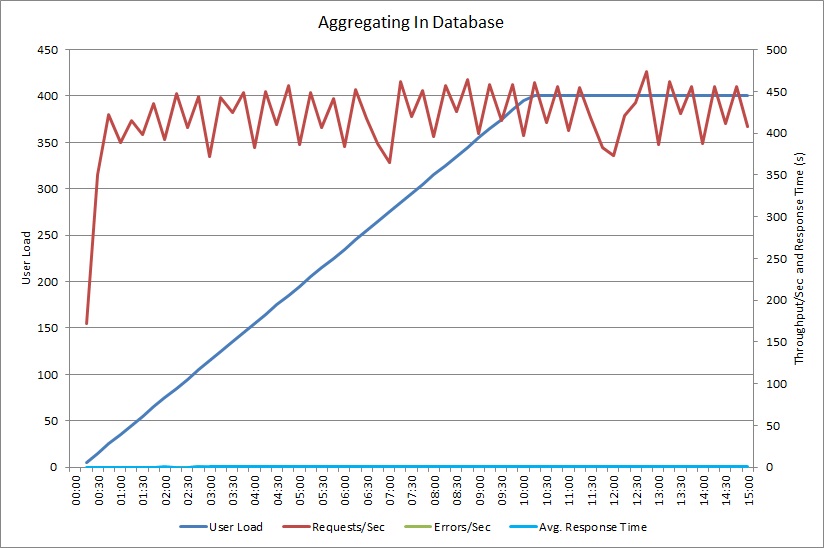
Ortalama yanıt süresi artık oldukça düşüktür. Bu durum esas olarak veritabanı G/Ç’sindeki büyük düşüşten kaynaklanan çok büyük bir performans artışıdır.
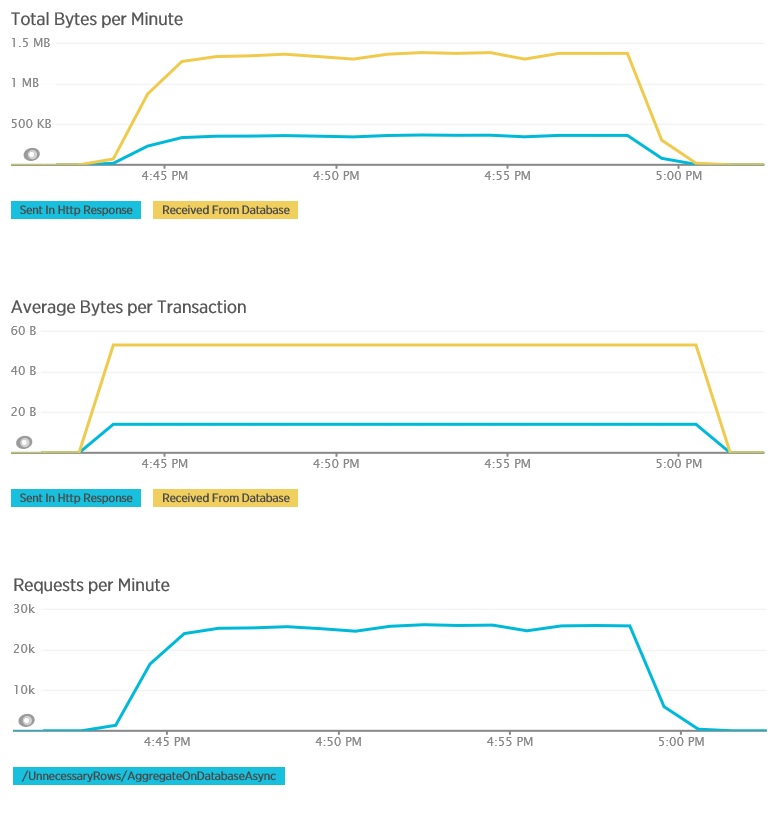
AggregateOnDatabaseAsync yöntemi için ilgili telemetri aşağıdadır. Veritabanından alınan veri miktarı ciddi ölçüde azalarak işlem başına 280 KB’tan 53 bayta düşmüştür. Bunun sonucunda dakika başına sürdürülen en yüksek istek sayısı yaklaşık 2.000’den 25.000’in üzerine çıkmıştır.
İlgili kaynaklar
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin