Tek Parça Kalıcılık Kötü Modeli
Uygulamanın tüm verilerini tek bir veri deposuna yerleştirmek performansı olumsuz etkileyebilir çünkü bu kaynak çekişmesine yol açabilir veya veri deposu bazı verilere uygun olmayabilir.
Sorun açıklaması
Geçmişte, uygulamanın depolaması gereken farklı türde veriler dikkate alınmaksızın uygulamalar çoğunlukla tek veri deposu kullanırdı. Genellikle bunun yapılmasının nedeni uygulama tasarımını basitleştirmek veya geliştirme ekibinin mevcut becerilerine uymasını sağlamaktı.
Modern bulut tabanlı sistemlerin çoğunlukla işlevsel olan ve olmayan ek gereksinimleri vardır ve belgeler, resimler, önbelleğe alınmış veriler, kuyruğa alınmış iletiler, uygulama günlükleri ve telemetri gibi birçok heterojen veri türünü depolamaları gerekir. Geleneksel yaklaşım benimsendiğinde ve bu bilgilerin tümü aynı veri deposuna yerleştirildiğinde, iki ana nedenle performans olumsuz etkilenebilir:
- Büyük miktarlarda ilişkisiz verileri aynı veri deposuna yerleştirmek ve almak veri çekişmesine neden olabilir ve bu da yanıt sürelerinin uzamasına, bağlantı hatalarına yol açabilir.
- Hangi veri deposu seçilirse seçilsin, tüm farklı veri türleri için en uygun depo olamaz veya uygulamanın gerçekleştirdiği işlemler için iyileştirilemez.
Aşağıdaki örnekte, veritabanına yeni kayıt ekleyen ve ayrı zamanda sonucu günlüğe kaydeden bir ASP.NET Web API denetleyicisi gösterilir. Günlük, iş verileriyle aynı veritabanında tutulmaktadır. Örneğin tamamını burada bulabilirsiniz.
public class MonoController : ApiController
{
private static readonly string ProductionDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
await DataAccess.LogAsync(ProductionDb, LogTableName);
return Ok();
}
}
Günlük kayıtlarının oluşturulma hızı, işle ilgili işlemlerin performansını büyük olasılıkla etkiler. Bir de uygulama işlem izleyicisi gibi başka bir bileşen günlük verilerini düzenli olarak okuyor ve işliyorsa, işle ilgili işlemler bundan da etkilenebilir.
Sorunun çözümü
Verileri kullanımlarına göre ayırın. Her veri kümesi için, veri kümesinin kullanımına en uygun veri deposunu seçin. Önceki örnekte, uygulamanın günlüğü iş verilerinin tutulduğu depodan ayrı bir depoda tutması gerekir:
public class PolyController : ApiController
{
private static readonly string ProductionDb = ...;
private static readonly string LogDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
// Log to a different data store.
await DataAccess.LogAsync(LogDb, LogTableName);
return Ok();
}
}
Dikkat edilmesi gereken noktalar
Verileri kullanılma ve erişilme yöntemine göre ayırın. Örneğin, günlük bilgileriyle iş verilerini aynı veri deposuna yerleştirmeyin. Bu tür verilerin gereksinimleri ve erişim desenleri birbirinden ciddi düzeyde farklıdır. Günlük kayıtları doğaları gereği sıralı olurken, iş verileri daha çok rastgele erişim gerektirir ve sıklıkla ilişkiseldir.
Her veri türü için veri erişim desenini göz önünde bulundurun. Örneğin, biçimlendirilmiş raporları ve belgeleri Azure Cosmos DB gibi bir belge veritabanında depolayın, ancak geçici verileri önbelleğe almak için Redis için Azure Cache kullanın.
Bu yönergelere uyduğunuz hale yine de veritabanının sınırına ulaşırsanız, veritabanının ölçeğini büyütmeniz gerekebilir. Ayrıca, yatay ölçeklemeyi ve yükü veritabanı sunucuları arasında bölümlemeyi de göz önünde bulundurun. Öte yandan, bölümleme uygulamanın yeniden tasarlanmasını gerektirebilir. Daha fazla bilgi için bkz: Veri bölümleme.
Sorunu algılama
Sistemin veritabanı bağlantıları gibi kaynakları tükendikçe, sistem ciddi düzeyde yavaşlar ve sonunda başarısız olur.
Nedeni belirlemenize yardımcı olması için aşağıdaki adımları gerçekleştirebilirsiniz.
- Ana performans istatistiklerini kaydetmek için sistemi işaretleyin. Her işlemin zamanlama bilgilerini ve ayrıca uygulamanın verileri okuduğu ve yazdığı noktaları yakalayın.
- Mümkünse, sistemin nasıl kullanıldığını gösteren gerçek bir görünüm elde etmek için üretim ortamında çalışırken birkaç gün süreyle sistemi izleyin. Bu mümkün değilse, tipik işlem serileri gerçekleştiren gerçekçi bir sanal kullanıcı hacmiyle betikleştirilmiş yük testleri çalıştırın.
- Telemetri verilerini kullanarak düşük performans dönemlerini belirleyin.
- Bu dönemlerde hangi veri depolarına erişildiğini belirleyin.
- Çekişme yaşanıyor olabilecek veri depolama kaynaklarını belirleyin.
Örnek tanılama
Aşağıdaki bölümlerde, bu adımlar yukarıda açıklanan örnek uygulamaya uygulanmaktadır.
Sistemi işaretleme ve izleme
Aşağıdaki grafikte, daha önce açıklanan örnek uygulamanın yük testinin sonuçları gösterilmektedir. Testte 1000 eşzamanlı kullanıcıya kadar ulaşan bir adım yüklemesi kullanılmıştır.
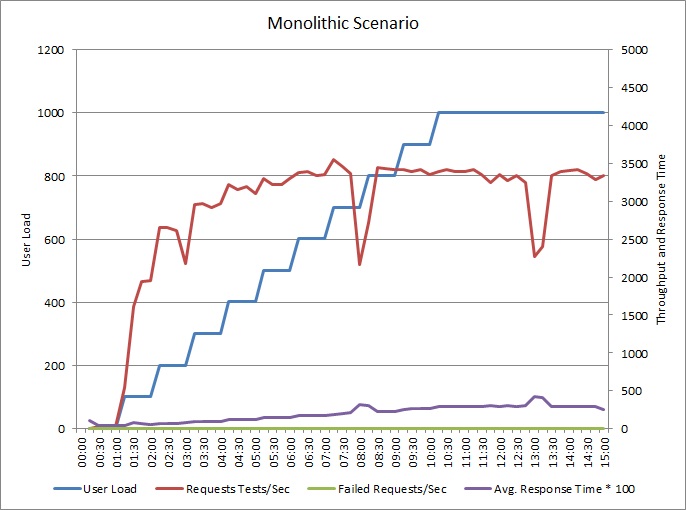
Yük 700 kullanıcı kadar artarken, aktarım hızı da artar. Ancak bu noktada, aktarım hızının artışı durur ve sistem kapasite üst sınırında çalışıyor gibi görünür. Kullanıcı yüküyle birlikte ortalama yanıt süresi de aşamalı olarak artar ve bu da sistemin talebe ayak uyduramadığını gösterir.
Düşük performans dönemlerini belirleme
Üretim sistemini izliyorsanız, desenleri fark edebilirsiniz. Örneğin, her gün aynı saatte yanıt süreleri önemli ölçüde uzuyor olabilir. Bunun nedeni düzenli bir iş yükü ve zamanlanmış bir toplu iş olabileceği gibi, yalnızca belirli saatlerde sistemde daha fazla kullanıcı bulunması da olabilir. Bu olaylar için telemetri verilerine odaklanmalısınız.
Artan yanıt süreleriyle artan veritabanı etkinliği veya paylaşılan kaynaklardaki G/Ç arasında bağıntılar olup olmadığına bakın. Bağıntılar varsa, bu veritabanında bir performans sorunu olduğu anlamına gelebilir.
Bu dönemlerde hangi veri depolarına erişildiğini belirleyin
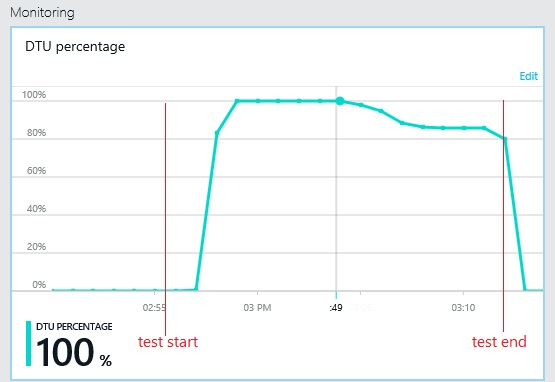
Sonraki grafikte, yük testi sırasında veritabanı işleme birimlerinin (DTU) kullanımı gösterilir. (DTU kullanılabilir kapasitenin bir ölçüsüdür ve CPU kullanımı, bellek ayırma, G/Ç oranının bir bileşimidir.) DTU kullanımı hızla %100'e ulaştı. Bu kabaca önceki örnekte aktarım hızının zirveye ulaştığı noktadır. Test bitene kadar veritabanı kullanımı çok yüksek düzeyde kalmıştır. Sona doğru, azalma, veritabanı bağlantılarına yönelik rekabet veya başka faktörlerin neden olabileceği hafif bir düşüş olmuştur.
Veri depoları için telemetriyi inceleyin
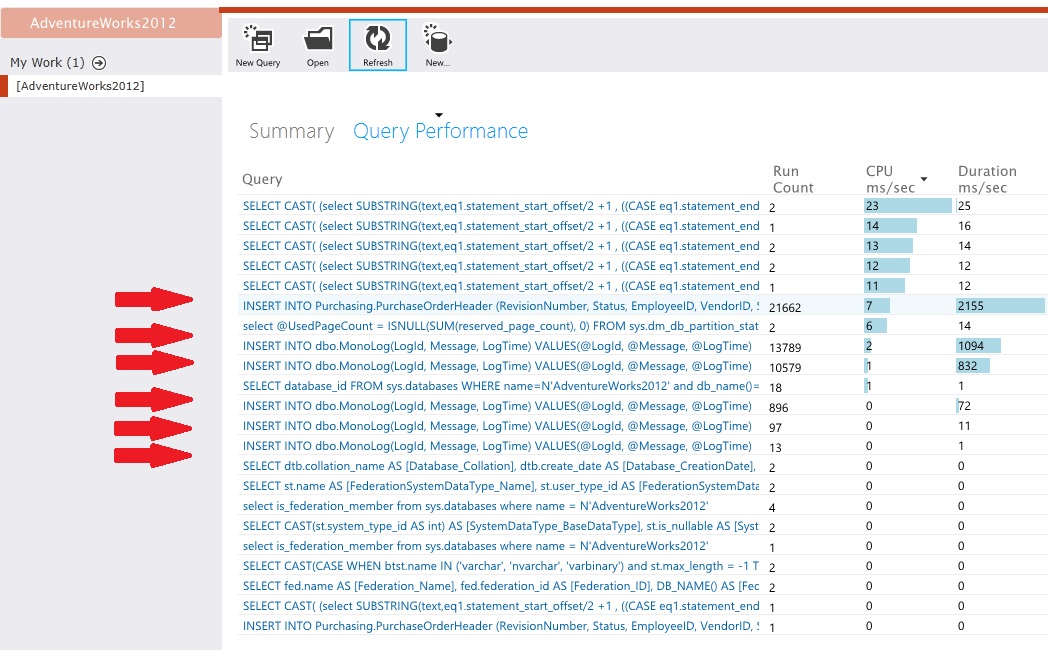
Etkinliğin alt düzey ayrıntılarını yakalamak için veri depolarını işaretleyin. Örnek uygulamada, veri erişim istatistikleri hem PurchaseOrderHeader tablosunda hem de MonoLog tablosunda büyük hacimli ekleme işlemleri yapıldığını gösterir.
Kaynak çekişmesini tanımlama
Bu noktada, kaynak kodu gözden geçirebilir ve uygulamanın çekişmeli kaynaklara eriştiği noktalara odaklanabilirsiniz. Şöyle durumları bulun:
- Mantıksal olarak birbirinden ayrı olan verilerin aynı depoya yazılması. Günlükler, raporlar ve kuyruğa alınmış iletiler gibi veriler, iş bilgileriyle aynı veritabanında tutulmamalıdır.
- Veri deposu seçimiyle veri türü arasında bir uyuşmazlık (örneğin, ilişkisel bir veritabanında büyük bloblar veya XML belgeleri).
- Kullanım desenleri önemli ölçüde farklı olup aynı depoyu paylaşan veriler (örneğin, yüksek-okuma/düşük-yazma verilerinin düşük-yazma/yüksek-okuma verileriyle birlikte depolanması).
Çözümü uygulama ve sonucu doğrulama
Uygulama, günlükleri ayrı bir veri deposuna yazacak şekilde değiştirilmiştir. Yük testi sonuçlarını şunlardır:
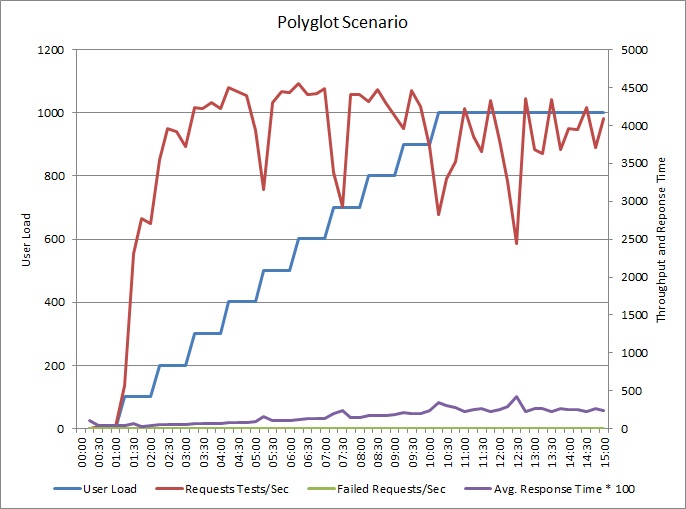
Aktarım hızının deseni önceki grafikle benzerdir, aman performansın zirveye ulaştığı nokta saniyede yaklaşık 500 istek kadar yüksektir. Ortalama yanıt süresi çok az düşüktür. Ancak, bu istatistikler hikayenin tamamını göstermez. İş veritabanına ilişkin telemetri DTU kullanımının %100 yerine %75 dolayında zirve yaptığını gösterir.
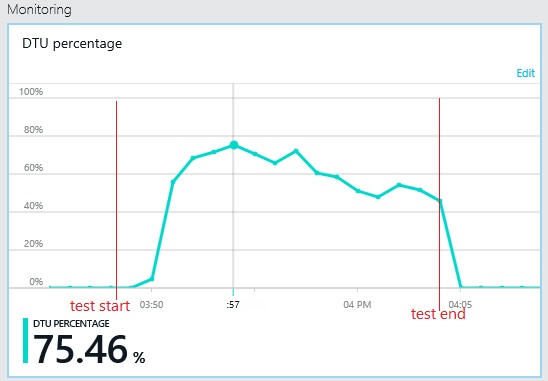
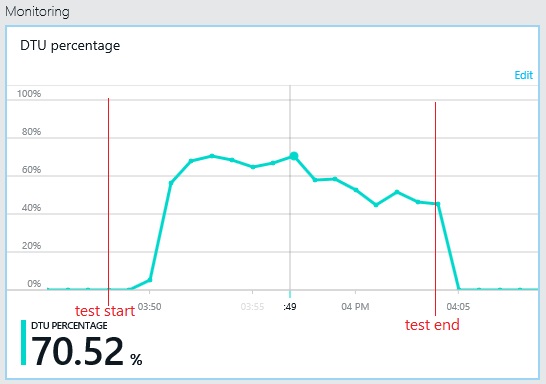
Benzer biçimde, günlük veritabanının DTU kullanımı üst sınırı yalnızca %70 dolayındadır. Veritabanları artık sistem performansını sınırlayan faktör değildir.
İlgili kaynaklar
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin