Veri gölü nedir?
Veri gölü, büyük miktarda veriyi yerel ve ham biçiminde tutan bir depolama deposudur. Data Lake Store'lar terabaytlar ve petabaytlar kadar veriyi ölçeklendirmek için iyileştirilmiştir. Veriler genellikle birden çok heterojen kaynaktan gelir ve yapılandırılmış, yarı yapılandırılmış veya yapılandırılmamış olabilir. Bir veri gölüyle ilgili fikir, her şeyi özgün, çevrilmemiş durumda depolamaktır. Bu yaklaşım, veri alımı sırasında verileri dönüştüren ve işleyen geleneksel bir veri ambarından farklıdır.
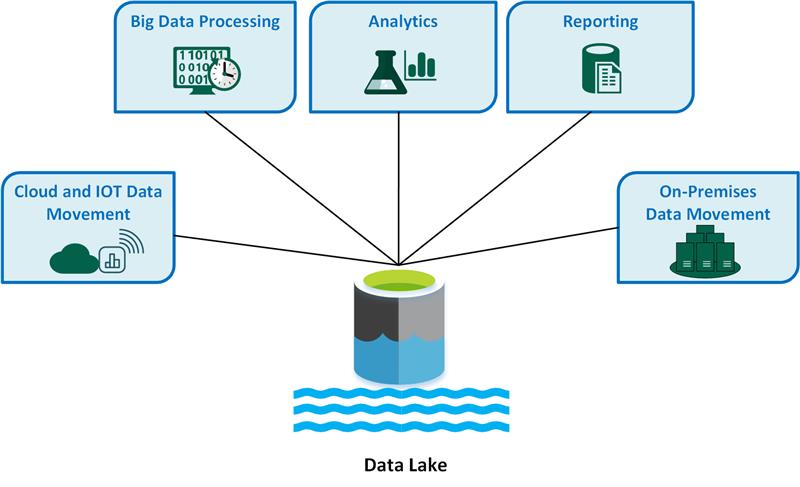
Önemli data lake kullanım örnekleri şunlardır:
- Bulut ve IoT veri taşıma
- Büyük veri işleme
- Analiz
- Raporlama
- Şirket içi veri taşıma
Veri gölü avantajları:
- Veriler ham biçiminde depolandığından veriler hiçbir zaman atılır. Bu özellikle büyük bir veri ortamında, verilerden hangi içgörülerin kullanılabilir olduğunu önceden bilmediğiniz durumlarda kullanışlıdır.
- Kullanıcılar verileri keşfedebilir ve kendi sorgularını oluşturabilir.
- Geleneksel ETL araçlarından daha hızlı olabilir.
- Yapılandırılmamış ve yarı yapılandırılmış verileri depolayabildiğinden veri ambarından daha esnektir.
Eksiksiz bir data lake çözümü hem depolama hem de işlemeden oluşur. Data Lake Storage, hataya dayanıklılık, sonsuz ölçeklenebilirlik ve çeşitli şekiller ve boyutlara sahip yüksek aktarım hızına sahip verilerin alımı için tasarlanmıştır. Veri gölü işleme, bu hedefler göz önünde bulundurularak oluşturulmuş bir veya daha fazla işleme altyapısını içerir ve büyük ölçekte bir veri gölünde depolanan veriler üzerinde çalışabilir.
Veri gölü ne zaman kullanılır?
Veri gölü için tipik kullanım alanları arasında veri keşfi, veri analizi ve makine öğrenmesi yer alır.
Veri gölü, veri ambarı için veri kaynağı olarak da görev yapabilir. Bu yaklaşımla ham veriler veri gölüne alınır ve sonra yapılandırılmış sorgulanabilir biçime dönüştürülür. Bu dönüşüm genellikle verilerin alındığı ve dönüştürüldüğü bir ELT (extract-load-transform) işlem hattı kullanır. Zaten ilişkisel olan kaynak veriler, etl işlemi kullanarak veri gölü atlayarak doğrudan veri ambarı'na gidebilir.
Data lake store'lar genellikle olay akışı veya IoT senaryolarında kullanılır, çünkü dönüştürme veya şema tanımı olmadan büyük miktarlarda ilişkisel ve ilişkisel olmayan verileri kalıcı hale gelebilirler. Bunlar, düşük gecikme süresinde yüksek hacimli küçük yazma işlemlerini işleyecek şekilde derlenir ve yüksek aktarım hızı için iyileştirilmiştir.
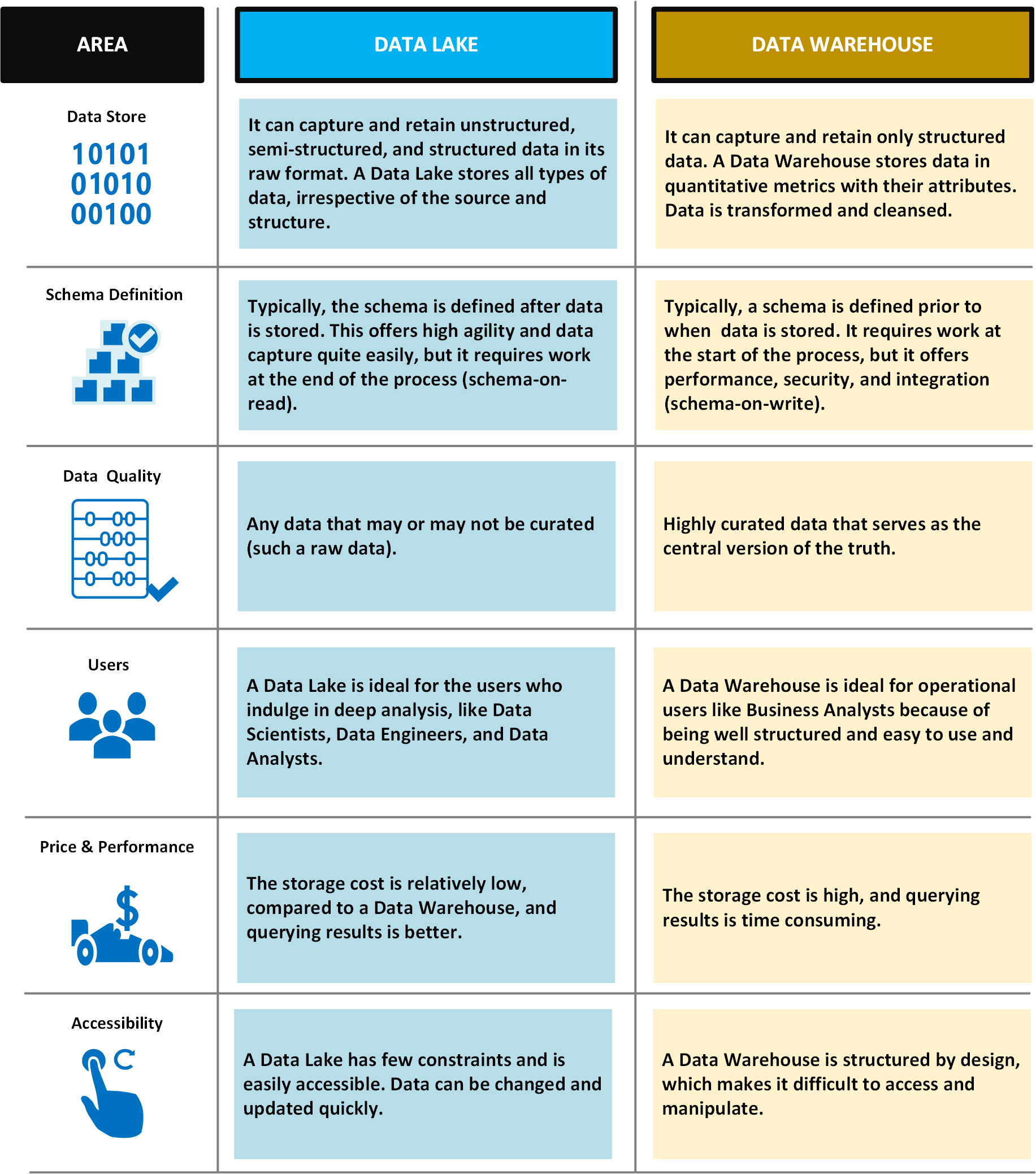
Aşağıdaki tablo veri göllerini ve veri ambarlarını karşılaştırır:
Zorluklar
- Şema veya açıklayıcı meta verilerin olmaması, verilerin tüketilmelerini veya sorgularını zorlaştırabilir.
- Veriler arasında anlam tutarlılığının olmaması, kullanıcılar veri analizi konusunda yüksek beceriye sahip olmadığı sürece veriler üzerinde analiz yapmayı zorlaştırabilir.
- Veri gölüne giden verilerin kalitesini garanti etmek zor olabilir.
- Uygun idare olmadan erişim denetimi ve gizlilik sorunları olabilir. Veri gölünde hangi bilgiler var, bu verilere kimlerin erişebileceği ve hangi kullanımlar için?
- Veri gölü, zaten ilişkisel olan verileri tümleştirmenin en iyi yolu olmayabilir.
- Veri gölü tek başına kuruluş genelinde tümleşik veya bütünsel görünümler sağlamaz.
- Veri gölü, içgörüler için hiçbir zaman analiz edilen veya mayınlı olmayan veriler için döküm alanı haline gelebilir.
Teknoloji seçimleri
Azure tarafından sunulan aşağıdaki hizmetleri kullanarak data lake çözümleri oluşturun:
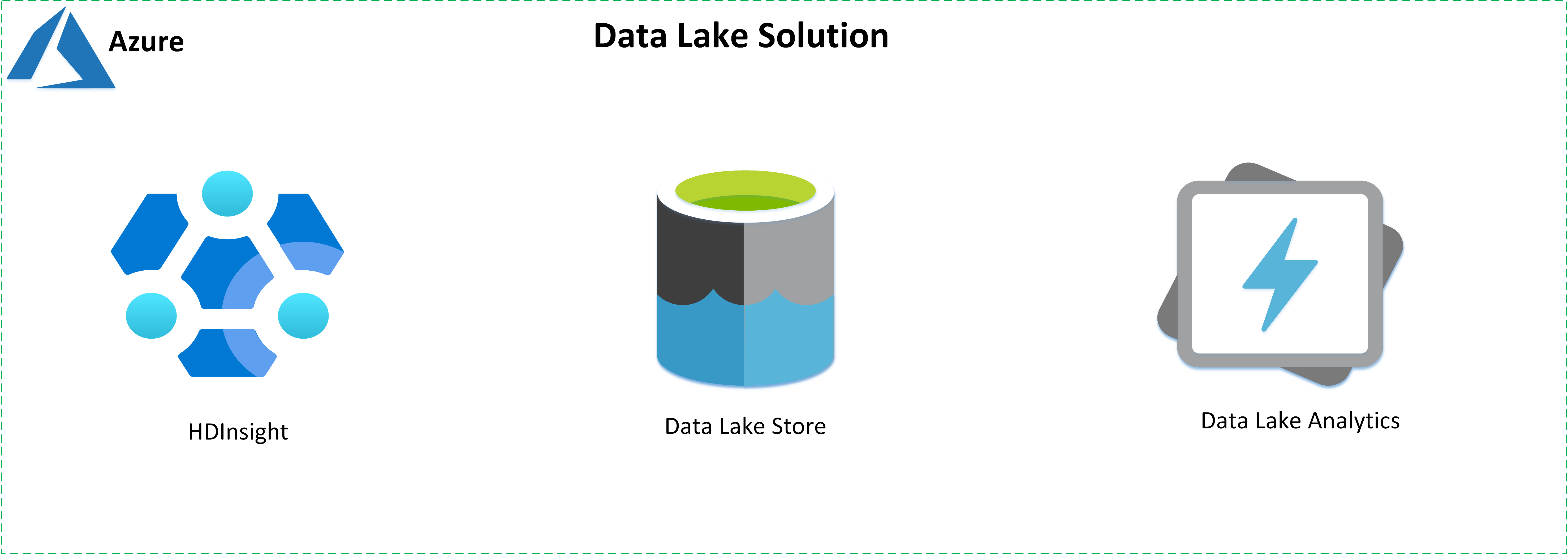
- Azure HD Insight , kuruluşlar için bulutta yönetilen, tam spektrumlu bir açık kaynak analiz hizmetidir.
- Azure Data Lake Store hiper ölçek, Hadoop uyumlu bir depodur.
- Azure Data Lake Analytics , büyük veri analizini basitleştirmek için isteğe bağlı bir analiz iş hizmetidir.
Katkıda Bulunanlar
Bu makale Microsoft tarafından yönetilir. Başlangıçta aşağıdaki katkıda bulunanlar tarafından yazılmıştır.
Asıl yazar:
- Avijit Prasad | Bulut Danışmanı
Sonraki adımlar
- Azure HDInsight nedir?
- Azure Data Lake Depolama'ne giriş
- Azure Data Lake Analytics Belgeleri
- Azure Data Lake Depolama'ne giriş (eğitim modülü)
- Data Lake nedir?
İlgili kaynaklar
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin