Büyük veri mimarisi, geleneksel veritabanı sistemleri için çok büyük veya karmaşık olan verilerin alımını, işlenmesini ve analizini yönetecek şekilde tasarlanmıştır.

Büyük veri çözümleri genellikle aşağıdaki iş yükü türlerinden bir veya daha fazlasını içerir:
- Bekleyen büyük veri kaynaklarının toplu işlenmesi.
- Hareket halindeki büyük verilerin gerçek zamanlı işlenmesi.
- Büyük verilerin etkileşimli incelenmesi.
- Tahmine dayalı analiz ve makine öğrenimi.
Büyük veri mimarilerinin çoğu, aşağıdaki bileşenlerin bazılarını veya tümünü içerir:
Veri kaynakları: Tüm büyük veri çözümleri bir veya daha fazla veri kaynağıyla başlar. Örnekler şunları içerir:
- İlişkisel veritabanları gibi uygulama verisi depoları.
- Uygulamalar tarafından üretilen web sunucusu günlük dosyaları gibi statik dosyalar.
- IoT cihazları gibi gerçek zamanlı veri kaynakları.
Veri depolama: Toplu işleme yönelik veriler genellikle çeşitli biçimlerdeki büyük dosyaları yüksek miktarlarda tutabilen bir dağıtılmış dosya deposunda depolanır. Bu tür depolara genelde veri gölü adı verilir. Bu depolamayı uygulamak seçenekleri arasında Azure Depolama'daki blob kapsayıcıları ve Azure Data Lake Store bulunur.
Toplu işlem: Veri kümeleri çok büyük olduğundan büyük veri çözümleri genellikle uzun süre çalışan toplu işler aracılığıyla verileri filtreleyerek, toplayarak ve diğer yollardan analize hazırlayarak veri dosyalarını işlemelidir. Bu işler, çoğu zaman kaynak dosyaların okunması, işlenmesi ve çıktının yeni dosyalara yazılmasını içerir. Seçenekler arasında Azure Data Lake Analytics’te U-SQL işleri çalıştırma, bir HDInsight Hadoop kümesinde Hive, Pig veya özel Map/Reduce işleri kullanma veya bir HDInsight Spark kümesinde Java, Scala veya Python programları kullanma bulunur.
Gerçek zamanlı ileti alımı: Çözüm gerçek zamanlı kaynaklar içeriyorsa mimarinin akış işlemek için gerçek zamanlı iletileri yakalayıp depolayacak bir yol içermesi gerekir. Bu yol, gelen iletilerin işlenmek üzere bir klasöre bırakıldığı basit bir veri deposu olabilir. Ancak, birçok çözüm ileti alım deposunun iletiler için bir arabellek görevi görmesini, ayrıca ölçeği genişletme işlemini, güvenilir teslimi ve diğer iletiyi kuyruğa alma semantiğini desteklemesini gerektirir. Seçenekler Azure Event Hubs, Azure IoT Hub ve Kafka’yı içerir.
Akış işleme: Çözümün, gerçek zamanlı iletileri yakaladıktan sonra filtreleme, toplama ve diğer verileri analize hazırlama işlemleriyle bu iletileri işlemesi gerekir. İşlenen akış verileri daha sonra bir çıkış havuzuna yazılır. Azure Stream Analytics, sınırsız akışlar üzerinde sürekli çalıştırılan SQL sorgularına dayalı yönetilen bir akış işleme hizmeti sağlar. HdInsight kümesinde Spark Streaming gibi apache akış teknolojilerini açık kaynak de kullanabilirsiniz.
Analitik veri deposu: Büyük veri çözümlerinin çoğu, verileri analiz için hazırlar ve sonra işlenen verileri analiz araçları kullanılarak sorgulanabilecek yapılandırılmış bir biçimde sunar. Bu sorgulara hizmet veren analitik veri deposu, birçok geleneksel iş zekası (BI) çözümünde görüldüğü gibi Kimball tarzında ilişkisel bir veri ambarı olabilir. Alternatif olarak, veriler HBase gibi düşük gecikme süreli bir NoSQL teknolojisi veya dağıtılmış veri deposundaki veri dosyalarının meta verilerle özetini sağlayan etkileşimli bir Hive veritabanı aracılığıyla sunulabilir. Azure Synapse Analytics büyük ölçekli, bulut tabanlı veri ambarlamaya yönelik yönetilen bir hizmet sağlar. HDInsight; Interactive Hive, HBase ve analiz için verileri sunmak amacıyla da kullanılabilen Spark SQL’i destekler.
Analiz ve Raporlama: Büyük veri çözümlerinin çoğunun amacı analiz ve raporlama aracılığıyla veriler hakkında öngörüler sağlamaktır. Mimari, kullanıcılara veri analizi desteği sağlamak amacıyla Azure Analysis Services’te çok boyutlu OLAP küpü veya tablo verisi modeli gibi bir veri modelleme katmanı içerebilir. Ayrıca, Microsoft Power BI veya Microsoft Excel'deki modelleme ve görselleştirme teknolojilerini kullanarak self servis BI işlemlerini de destekleyebilir. Analiz ve raporlama, veri uzmanları veya veri analistlerinin etkileşimli veri incelemelerini de içerir. Azure hizmetlerinin çoğu bu senaryolar için Jupyter gibi analitik not defterlerini destekleyerek söz konusu kullanıcıların mevcut Python veya R becerilerinden yararlanmasına olanak sağlar. Büyük ölçekli veri incelemeleri için Microsoft R Server’ı tek başına veya Spark ile kullanabilirsiniz.
Düzenleme: Büyük veri çözümlerinin çoğu, iş akışlarıyla temsil edilen şekilde yinelenen veri işleme faaliyetlerinden oluşur. Bu iş akışları kaynak verileri dönüştürür, verileri çeşitli kaynaklar ve havuzlar arasında taşır, işlenen verileri bir analitik veri deposuna yükler ya da sonuçları doğrudan bir rapora veya panoya gönderir. Bu iş akışlarını otomatik hale getirmek için Azure Data Factory veya Apache Oozie ve Sqoop gibi bir düzenleme teknolojisi kullanabilirsiniz.
Azure, büyük veri mimarisinde kullanılabilecek birçok hizmet içerir. Bu hizmetler kabaca iki kategoriye ayrılır:
- Azure Data Lake Store, Azure Data Lake Analytics, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs, Azure IoT Hub ve Azure Data Factory gibi yönetilen hizmetler.
- HDFS, HBase, Hive, Spark, Oozie, Sqoop ve Kafka gibi Apache Hadoop platformunu temel alan açık kaynak teknolojileri. Bu teknolojiler, Azure’da Azure HDInsight hizmetinde kullanılabilir.
Bu seçenekler birbirini dışlamaz ve birçok çözüm, açık kaynaklı teknolojiler ile Azure hizmetlerini birleştirir.
Bu mimarinin kullanılacağı durumlar
Aşağıdakileri yapmanız gerektiğinde bu mimari stilini göz önünde bulundurun:
- Geleneksel bir veritabanı için çok büyük hacme sahip veri depolama ve işleme.
- Yapılandırılmamış verileri analiz ve raporlama için dönüştürme.
- Sınırsız veri akışlarını gerçek zamanlı olarak veya düşük gecikme süresiyle yakalama, işleme ve analiz etme.
- Azure Machine Learning veya Azure Bilişsel Hizmetler'i kullanın.
Sosyal haklar
- Teknoloji seçimleri: HDInsight kümelerinde Azure yönetilen hizmetleri ile Apache teknolojilerini eşleştirip bir araya getirerek mevcut becerilerden veya teknoloji yatırımlarından yararlanabilirsiniz.
- Paralel çalışma aracılığıyla performans. Büyük veri çözümleri paralel çalışmadan yararlanarak büyük miktarda veriye göre ölçeklendirilebilen yüksek performanslı çözümlere olanak sağlar.
- Esnek ölçek. Büyük veri mimarisinin tüm bileşenleri, ölçek genişletme sağlanmasını destekler. Böylece çözümünüzü küçük veya büyük iş yüklerine göre ayarlayabilir ve yalnızca kullandığınız kaynaklar için ödeme yaparsınız.
- Mevcut çözümlerle birlikte çalışabilirlik. Büyük veri mimarisinin bileşenleri ayrıca IoT işleme ve kurumsal BI çözümleri için de kullanılır. Bu sayede tüm veri iş yüklerini kapsayan tümleşik bir çözüm oluşturabilirsiniz.
Zorluklar
- Karmaşıklık. Büyük veri çözümleri çok karmaşık olabilir. Çeşitli veri kaynaklarından veri alımı gerçekleştirmek için çok sayıda bileşen vardır. Büyük veri süreçleri oluşturmak, test etmek ve bu çözümlerin sorunlarını gidermek oldukça zor olabilir. Ayrıca, performansı iyileştirmek için birden çok sistem üzerindeki çok sayıda yapılandırma ayarının kullanılması gerekebilir.
- Beceriler. Büyük veri teknolojilerinin çoğu yüksek ölçüde özelleştirilmiştir ve daha genel uygulama mimarilerinde pek rastlanmayan altyapılardan ve dillerden yararlanır. Öte yandan, büyük veri teknolojileri daha iyi bilinen dilleri temel alan yeni API’ler geliştirmektedir. Örneğin, Azure Data Lake Analytics’teki U-SQL dili Transact-SQL ve C# dillerini temel alır. Benzer şekilde Hive, HBase ve Spark için kullanılabilecek SQL tabanlı API’ler vardır.
- Teknolojik olgunluk. Büyük veri için kullanılan teknolojilerin birçoğu gelişmektedir. Hive ve Pig gibi temel Hadoop teknolojileri istikrarlı bir hale gelmiş olsa da Spark gibi yeni teknolojiler her yeni sürümde kapsamlı değişiklikler ve iyileştirmeler sunmaktadır. Azure Data Lake Analytics ve Azure Data Factory gibi yönetilen hizmetler diğer Azure hizmetlerine göre daha yenidir ve büyük olasılıkla zaman içinde gelişecektir.
- Güvenlik. Büyük veri çözümleri, genellikle tüm statik verileri merkezi bir veri gölünde depolar. Bu verilere güvenli bir şekilde erişmek, özellikle verilerin çok sayıda uygulama ve platform tarafından alınıp tüketilmesi gerektiğinde oldukça zorlu olabilir.
En iyi yöntemler
Paralel çalışmadan yararlanma. Büyük veri işleme teknolojilerinin çoğu, iş yükünü birden çok işleme birimi arasında dağıtır. Bunun için statik veri dosyalarının bölünebilir bir biçimde oluşturulup depolanması gerekir. HDFS gibi dağıtılmış dosya sistemleri okuma ve yazma performansını iyileştirebilir. Gerçek işleme birden çok küme düğümü tarafından paralel olarak gerçekleştirilir ve böylece toplam iş süresi kısalır.
Verileri bölümleme. Toplu işlem genellikle yinelenen bir zamanlamaya göre (örneğin, haftalık veya aylık) gerçekleşir. Veri dosyalarını ve tablo gibi veri yapılarını işleme zamanlamasıyla uyumlu zaman dönemlerine göre bölümleyin. Böylece veri alımı ve iş zamanlaması basitleşir ve hataların giderilmesi kolaylaşır. Ayrıca Hive, U-SQL veya SQL sorgularında kullanılan tabloların bölümlenmesi sorgu performansını önemli ölçüde iyileştirebilir.
Okuma sırasında şema belirleme semantiğini uygulama. Veri gölü kullanmak, yapılandırılmış, yarı yapılandırılmış veya yapılandırılmamış dosyalar için depolamayı birden çok biçimde birleştirmenizi sağlar. Verilere depolanırken değil, işlenirken bir şema uygulayan okuma sırasında şema belirleme semantiğini kullanın. Böylece çözümün esnek olması sağlanır ve veri alımı sırasında veri doğrulama ve tür denetimi nedeniyle performans sorunları yaşanması önlenir.
Verileri yerinde işleme. Geleneksel BI çözümleri verileri bir veri ambarına taşımak için genellikle ayıklama, dönüştürme ve yükleme (ETL) sürecini kullanır. Büyük veri çözümleri, daha yüksek miktarda ve daha farklı biçimlerdeki veriler için genellikle dönüştürme, ayıklama ve yükleme (TEL) gibi ETL’nin farklı çeşitlerini kullanır. Bu yaklaşımda veriler dağıtılmış veri deposunda işlenerek gerekli yapıya dönüştürülür ve ardından dönüştürülen veriler analitik veri deposuna taşınır.
Kullanım ve süre maliyetlerini dengeleme. Toplu işlemler için iki faktörü göz önünde bulundurmak önemlidir: İşlem düğümlerinin birim başına maliyeti ve işi tamamlamak için bu düğümleri kullanmanın dakika başına maliyeti. Örneğin, bir toplu iş dört küme düğümüyle sekiz saat sürebilir. Ancak, iş dört düğümün hepsini yalnızca ilk iki saat boyunca kullanıyor ve bu noktadan sonra yalnızca iki düğüm gerekiyor olabilir. Bu durumda, tüm işin iki düğüm üzerinde çalıştırılması toplam iş süresini artıracak ancak iki katına çıkarmayacaktır ve bu nedenle toplam maliyet daha az olacaktır. Bazı iş senaryolarında, az kullanılan küme kaynaklarını kullanmanın daha yüksek maliyetine daha uzun bir işlem süresi tercih edilebilir.
Küme kaynaklarını ayırma. HDInsight kümeleri dağıtırken her iş yükü türü için ayrı küme kaynakları sağlarsanız normalde daha iyi performans elde edersiniz. Örneğin, Spark kümeleri Hive’ı içerse de hem Hive hem de Spark ile kapsamlı işleme gerçekleştirmeniz gerekiyorsa ayrı adanmış Spark ve Hadoop kümeleri dağıtmanız iyi bir fikir olabilir. Benzer şekilde, düşük gecikme süreli akış işlemesi için HBase ve Storm’u, toplu işlem için Hive’ı kullanıyorsanız ayrı Storm, HBase ve Hadoop kümeleri dağıtmak isteyebilirsiniz.
Veri alımını düzenleme. Bazı durumlarda, mevcut iş uygulamaları toplu işlem yapılacak veri dosyalarını doğrudan Azure depolama blob kapsayıcılarına yazabilir. Dosyalar burada HDInsight veya Azure Data Lake Analytics tarafından kullanılabilir. Ancak, genellikle verilerin şirket içi veya dış veri kaynaklarından veri gölüne alımını düzenlemeniz gerekir. Bu süreci öngörülebilir ve merkezi olarak yönetilebilir bir şekilde yürütmek için Azure Data Factory veya Oozie tarafından desteklenenler gibi bir düzenleme iş akışı veya işlem hattı kullanın.
Hassas verileri erken temizleme. Veri alımı iş akışı, hassas verileri sürecin erken aşamalarında temizleyerek veri gölünde depolanmalarını önlemelidir.
IoT mimarisi
Nesnelerin İnterneti (IoT), büyük veri çözümlerinin özel bir alt kümesidir. Aşağıdaki diyagramda IoT’ye yönelik olası bir mantıksal mimari gösterilmektedir. Diyagramda mimarinin olay akışı bileşenleri vurgulanmaktadır.
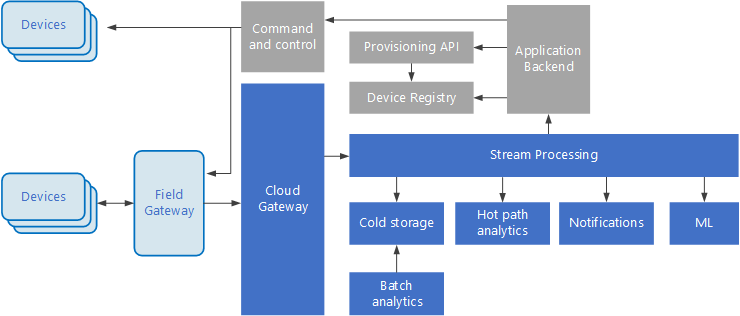
Bulut ağ geçidi, düşük gecikmeli güvenilir bir mesajlaşma sistemi kullanarak bulut sınırındaki cihaz olaylarını alır.
Cihazlar olayları bulut ağ geçidine doğrudan veya bir alan ağ geçidi üzerinden gönderebilir. Alan ağ geçidi genellikle cihazlarla aynı konumda olan ve olayları alıp bulut ağ geçidine ileten özel bir cihaz veya yazılımdır. Alan ağ geçidi aynı zamanda ham cihaz olaylarını yeniden işleyerek filtreleme, toplama veya protokol dönüştürme gibi işlevler de gerçekleştirebilir.
Alım sonrasında olaylar, verileri (örneğin, depolamaya) yönlendirebilen ya da analiz ve diğer işlemleri gerçekleştirebilen bir veya birden çok akış işlemcisinden geçer.
Aşağıda sık kullanılan bazı işleme türleri verilmiştir. (Bu liste tam kapsamlı değildir.)
Arşivleme veya toplu analiz amacıyla olay verilerini soğuk depolamaya yazma.
Etkin yol analizi: anormallikleri algılamak, toplanan zaman pencereleri üzerinden düzenleri tanımak veya akışta belirli bir koşul oluştuğunda uyarıları tetiklemek için olay akışını gerçek zamanlıya yakın olarak analiz etme.
Cihazlardan alınan, bildirim ve alarm gibi telemetri dışı özel ileti türlerini işleme.
Makine öğrenimi.
Gri gölgeli kutular bir IoT sisteminin, doğrudan olay akışıyla bağlantılı olmayan ancak bütünlük açısından buraya dahil edilen bileşenlerini gösterir.
Cihaz kayıt defteri, cihaz kimlikleri ve genellikle konum gibi cihaz meta verileri de dahil olmak üzere sağlanan cihazlardan oluşan bir veritabanıdır.
Sağlama API’si, yeni cihazların sağlanmasına ve kaydedilmesine yönelik olarak sık kullanılan bir dış arabirimdir.
Bazı IoT çözümleri komut ve denetim iletilerinin cihazlara gönderilmesini sağlar.
Bu bölümde IoT’nin son derece yüksek düzey bir görünümü sunulmaktadır ve dikkate alınması gereken çok sayıda ince fark ve zorluk söz konusudur. Daha ayrıntılı bir başvuru mimarisi ve tartışma için bkz. Microsoft Azure IoT Reference Architecture (Microsoft Azure IoT Başvuru Mimarisi) (indirilebilir PDF).