Bu makalede, Azure Kubernetes Service (AKS) üzerinde çalışan bir mikro hizmet uygulamasını izlemeye yönelik en iyi yöntemler açıklanmaktadır. Telemetri toplama, kümenin durumunu izleme, ölçümler, günlüğe kaydetme, yapılandırılmış günlük kaydı ve dağıtılmış izleme gibi konulara özgü konular yer alır. İkincisi bu diyagramda gösterilmiştir:

Bu mimarinin bir Visio dosyasını indirin.
Telemetri koleksiyonu
Herhangi bir karmaşık uygulamada, bir noktada bir sorun olacaktır. Mikro hizmetler uygulamasında, onlarca, hatta yüzlerce hizmette neler olduğunu izlemeniz gerekir. Neler olduğuna anlam vermek için uygulamadan telemetri toplamanız gerekir. Telemetri şu kategorilere ayrılabilir: günlükler, izlemeler ve ölçümler.
Günlükler , bir uygulama çalışırken gerçekleşen olayların metin tabanlı kayıtlarıdır. Bunlar uygulama günlükleri (izleme deyimleri) ve web sunucusu günlükleri gibi öğeleri içerir. Günlükler öncelikle adli tıp ve kök neden analizi için yararlıdır.
İşlemler olarak da adlandırılan izlemeler, tek bir isteğin adımlarını mikro hizmetler içinde ve mikro hizmetler arasında birden çok çağrı arasında bağlar. Sistem bileşenlerinin etkileşimlerine yapılandırılmış gözlemlenebilirlik sağlayabilirler. İzlemeler, bir uygulamanın kullanıcı arabiriminde olduğu gibi istek işleminin erken aşamalarında başlayabilir ve ağ hizmetleri aracılığıyla isteği işleyen bir mikro hizmet ağına yayılabilir.
- Yayılma alanları , bir izleme içindeki çalışma birimleridir. Her yayılma alanı tek bir izlemeyle bağlanır ve diğer yayılma alanlarıyla iç içe yerleştirilebilir. Bunlar genellikle hizmetler arası bir işlemdeki tek tek isteklere karşılık gelir, ancak bir hizmet içindeki tek tek bileşenlerde de çalışma tanımlayabilirler. Spans ayrıca bir hizmetten diğerine giden çağrıları da izler. (Bazen yayılma alanları bağımlılık kayıtları olarak adlandırılır.)
Ölçümler , analiz edilebilen sayısal değerlerdir. Bir sistemi gerçek zamanlı (veya gerçek zamanlıya yakın) gözlemlemek veya zaman içindeki performans eğilimlerini analiz etmek için bunları kullanabilirsiniz. Bir sistemi bütünsel olarak anlamak için, fiziksel altyapıdan uygulamaya kadar çeşitli mimari düzeylerinde ölçümler toplamanız gerekir, örneğin:
CPU, bellek, ağ, disk ve dosya sistemi kullanımı gibi düğüm düzeyinde ölçümler. Sistem ölçümleri, kümedeki her düğüm için kaynak ayırmayı anlamanıza ve aykırı değerlerin sorunlarını gidermenize yardımcı olur.
Kapsayıcı ölçümleri. Kapsayıcılı uygulamalar için ölçümleri yalnızca VM düzeyinde değil kapsayıcı düzeyinde toplamanız gerekir.
Uygulama ölçümleri. Bu ölçümler bir hizmetin davranışını anlamak için geçerlidir. Örnek olarak kuyruğa alınan gelen HTTP isteklerinin sayısı, istek gecikme süresi ve ileti kuyruğu uzunluğu verilebilir. Uygulamalar, dakika başına işlenen iş işlemlerinin sayısı gibi etki alanına özgü özel ölçümler de kullanabilir.
Bağımlı hizmet ölçümleri. Hizmetler bazen yönetilen PaaS veya SaaS hizmetleri gibi dış hizmetleri veya uç noktaları çağırır. Üçüncü taraf hizmetler ölçüm sağlamayabilir. Aksi takdirde, gecikme süresi ve hata oranı istatistiklerini izlemek için kendi uygulama ölçümlerinize güvenmeniz gerekir.
Küme durumunu izleme
Kümelerinizin durumunu izlemek için Azure İzleyici'yi kullanın. Aşağıdaki ekran görüntüsünde, kullanıcı tarafından dağıtılan podlarda kritik hataları olan bir küme gösterilmektedir:

Buradan, sorunu bulmak için daha fazla detaya gidebilirsiniz. Örneğin, pod durumu ise ImagePullBackoffKubernetes kayıt defterinden kapsayıcı görüntüsünü çekemez. Bu sorun, kayıt defterinden çekme sırasında geçersiz bir kapsayıcı etiketinden veya kimlik doğrulama hatasından kaynaklanabilir.
Bir kapsayıcı kilitlenirse kapsayıcı StateWaiting, ile ReasonCrashLoopBackOffolur. Podun bir çoğaltma kümesinin parçası olduğu ve yeniden deneme ilkesinin olduğu Alwaystipik bir senaryo için bu sorun küme durumunda bir hata olarak gösterilmez. Ancak, bu koşul için sorgular çalıştırabilir veya uyarılar ayarlayabilirsiniz. Daha fazla bilgi için bkz . Azure İzleyici Kapsayıcı içgörüleriyle AKS kümesi performansını anlama.
AKS kaynağının çalışma kitapları bölmesinde kapsayıcıya özgü birden çok çalışma kitabı vardır. Hızlı bir genel bakış, sorun giderme, yönetim ve içgörüler için bu çalışma kitaplarını kullanabilirsiniz. Aşağıdaki ekran görüntüsünde AKS iş yükleri için varsayılan olarak kullanılabilen çalışma kitaplarının listesi gösterilmektedir.

Ölçümler
AKS kümelerinizin ve diğer bağımlı Azure hizmetlerinin ölçümlerini toplamak ve görüntülemek için İzleyici'yi kullanmanızı öneririz.
Küme ve kapsayıcı ölçümleri için Azure İzleyici Kapsayıcı içgörülerini etkinleştirin. Bu özellik etkinleştirildiğinde İzleyici, Kubernetes Metrics API'sini kullanarak denetleyicilerden, düğümlerden ve kapsayıcılardan bellek ve işlemci ölçümlerini toplar. Kapsayıcı içgörüleri tarafından sağlanan ölçümler hakkında daha fazla bilgi için bkz . Azure İzleyici Kapsayıcı içgörüleriyle AKS kümesi performansını anlama.
Uygulama ölçümlerini toplamak için Uygulama Analizler kullanın. Uygulama Analizler genişletilebilir bir uygulama performans yönetimi (APM) hizmetidir. Bunu kullanmak için uygulamanıza bir izleme paketi yüklersiniz. Bu paket uygulamayı izler ve telemetri verilerini Application Analizler'a gönderir. Ayrıca ana bilgisayar ortamından telemetri verilerini de çekebilir. Ardından veriler İzleyici'ye gönderilir. Uygulama Analizler ayrıca yerleşik bağıntı ve bağımlılık izleme de sağlar. (Bkz. Bu makalenin devamında yer alan dağıtılmış izleme.)
Uygulama Analizler saniyedeki olaylarla ölçülen en yüksek aktarım hızına sahiptir ve veri hızı sınırı aşarsa telemetriyi kısıtlar. Ayrıntılar için bkz. Uygulama Analizler sınırları. Geliştirme ve test ortamlarının kota için üretim telemetrisi ile rekabet etmemesi için her ortam için farklı Uygulama Analizler örnekleri oluşturun.
Tek bir işlem birçok telemetri olayı oluşturabilir, bu nedenle bir uygulama yüksek miktarda trafikle karşılaşırsa telemetri yakalaması kısıtlanmış olabilir. Bu sorunu azaltmak için telemetri trafiğini azaltmak için örnekleme gerçekleştirebilirsiniz. Sonuç olarak ölçümlerinizin önceden toplamayı desteklemediği sürece daha az hassas olması gerekir. Bu durumda, sorun giderme için daha az izleme örneği olacaktır, ancak ölçümler doğruluğu korur. Daha fazla bilgi için bkz. Uygulama Analizler Örnekleme. Ayrıca ölçümleri önceden toplayarak veri hacmini azaltabilirsiniz. Başka bir ifadeyle, ortalama ve standart sapma gibi istatistiksel değerleri hesaplayabilir ve ham telemetri yerine bu değerleri gönderebilirsiniz. Bu blog gönderisinde, Uygulama Analizler büyük ölçekte kullanmaya yönelik bir yaklaşım açıklanmaktadır: Azure İzleme ve Uygun Ölçekte Analiz.
Veri hızınız azaltmayı tetikleye kadar yüksekse ve örnekleme veya toplama kabul edilebilir değilse, ölçümleri kümede çalışan Azure Veri Gezgini, Prometheus veya InfluxDB gibi bir zaman serisi veritabanına dışarı aktarmayı göz önünde bulundurun.
Azure Veri Gezgini, günlük ve telemetri verileri için Azure'a özel, yüksek oranda ölçeklenebilir bir veri araştırma hizmetidir. Jupyter Notebooks ve Grafana gibi popüler araçlarda veri tüketmek için birden çok veri biçimi, zengin bir sorgu dili ve bağlantılar için destek sunar. Azure Veri Gezgini, Azure Event Hubs aracılığıyla günlük ve ölçüm verilerini almak için yerleşik bağlayıcılara sahiptir. Daha fazla bilgi için bkz. Azure Veri Gezgini'da veri alma ve sorgulama.
InfluxDB, gönderme tabanlı bir sistemdir. Bir aracının ölçümleri göndermesi gerekir. Kubernetes'in izlenmesini ayarlamak için TICK yığınını kullanabilirsiniz. Daha sonra ölçümleri toplamak ve raporlamak için bir aracı olan Telegraf'ı kullanarak ölçümleri InfluxDB'ye gönderebilirsiniz. Düzensiz olaylar ve dize veri türleri için InfluxDB kullanabilirsiniz.
Prometheus, çekme tabanlı bir sistemdir. Yapılandırılan konumlardaki ölçümleri düzenli aralıklarla kazır. Prometheus, Azure İzleyici veya kube-state-metrics tarafından oluşturulan ölçümleri kazıyabilir. kube-state-metrics , Kubernetes API sunucusundan ölçüm toplayan ve bunları Prometheus (veya Prometheus istemci uç noktasıyla uyumlu bir kazıyıcı) için kullanılabilir hale getiren bir hizmettir. Sistem ölçümleri için, sistem ölçümleri için prometheus ihracatçısı olan düğüm dışarıyı vereni kullanın. Prometheus kayan nokta verilerini destekler ancak dize verilerini desteklemez, bu nedenle sistem ölçümleri için uygundur ancak günlüklere uygun değildir. Kubernetes Ölçüm Sunucusu , kaynak kullanım verilerinin küme genelindeki bir toplayıcısıdır.
Günlük Kaydı
Mikro hizmetler uygulamasında günlüğe kaydetmenin bazı genel zorlukları şunlardır:
- Tek bir isteği işlemek için birden çok hizmetin çağrılabileceği istemci isteğinin uçtan uca işlenmesini anlama.
- Birden çok hizmetten gelen günlükleri tek bir toplu görünümde birleştirme.
- Kendi günlük şemalarını kullanan veya belirli bir şeması olmayan birden çok kaynaktan gelen günlükleri ayrıştırma. Günlükler, denetlemediğiniz üçüncü taraf bileşenler tarafından oluşturulabilir.
- Bir işlemde daha fazla hizmet, ağ çağrısı ve adım olduğundan mikro hizmet mimarileri genellikle geleneksel monolitlerden daha büyük bir günlük hacmi oluşturur. Bu, günlüğe kaydetmenin uygulama için bir performans veya kaynak performans sorunu olabileceği anlamına gelir.
Kubernetes tabanlı mimariler için bazı ek zorluklar vardır:
- Kapsayıcılar gezinebilir ve yeniden zamanlanabilir.
- Kubernetes'in sanal IP adreslerini ve bağlantı noktası eşlemelerini kullanan bir ağ soyutlaması vardır.
Kubernetes'te günlüğe kaydetmeye yönelik standart yaklaşım, kapsayıcının stdout ve stderr'a günlük yazmasıdır. Kapsayıcı altyapısı bu akışları bir günlük sürücüsüne yönlendirir. Bir düğüm yanıt vermeyi durdurursa sorgulamayı kolaylaştırmak ve günlük verilerinin olası kaybını önlemek için her düğümden günlükleri toplamak ve bunları merkezi bir depolama konumuna göndermek normal bir yaklaşımdır.
Azure İzleyici, bu yaklaşımı desteklemek için AKS ile tümleşir. İzleyici, kapsayıcı günlüklerini toplar ve bir Log Analytics çalışma alanına gönderir. Buradan, toplanan günlüklerde sorgu yazmak için Kusto Sorgu Dili kullanabilirsiniz. Örneğin, aşağıda belirtilen pod için kapsayıcı günlüklerini gösteren bir Kusto sorgusu verilmişti:
ContainerLogV2
| where PodName == "podName" //update with target pod
| project TimeGenerated, Computer, ContainerId, LogMessage, LogSource
Azure İzleyici yönetilen bir hizmettir ve AKS kümesini İzleyici'yi kullanacak şekilde yapılandırmak, CLI veya Azure Resource Manager şablonunda basit bir yapılandırma değişikliğidir. (Daha fazla bilgi için bkz. Azure İzleyici Kapsayıcı içgörülerini etkinleştirme.) Azure İzleyici'yi kullanmanın bir diğer avantajı, birleşik bir izleme deneyimi sağlamak için AKS günlüklerinizi diğer Azure platform günlükleriyle birleştirmesidir.
Azure İzleyici, hizmete alınan gigabayt (GB) veri başına faturalandırılır. (Bkz. Azure İzleyici fiyatlandırması.) Yüksek hacimlerde maliyet göz önünde bulundurulabilir. Kubernetes ekosistemi için birçok açık kaynak alternatif vardır. Örneğin, birçok kuruluş Elasticsearch ile Fluentd kullanır. Fluentd bir açık kaynak veri toplayıcısı ve Elasticsearch ise arama için kullanılan bir belge veritabanıdır. Bu seçeneklerle ilgili bir zorluk, kümenin ek yapılandırmasına ve yönetimine ihtiyaç duymalarıdır. Üretim iş yükü için yapılandırma ayarlarıyla deneme yapmanız gerekebilir. Günlük altyapısının performansını da izlemeniz gerekir.
OpenTelemetry
OpenTelemetry; uygulamalar, kitaplıklar, telemetri ve veri toplayıcılar arasındaki arabirimi standartlaştırarak izlemeyi geliştirmeye yönelik sektörler arası bir çabadır. OpenTelemetry ile izlenen bir kitaplık ve çerçeve kullandığınızda, geleneksel olarak sistem işlemleri olan izleme işlemlerinin çoğu, aşağıdaki yaygın senaryoları içeren temel kitaplıklar tarafından işlenir:
- Başlangıç saati, çıkış zamanı ve süre gibi temel istek işlemlerinin günlüğe kaydedilmesi
- Özel durumlar oluştu
- Bağlam yayma (HTTP çağrı sınırları arasında bağıntı kimliği gönderme gibi)
Bunun yerine, bu işlemleri işleyen temel kitaplıklar ve çerçeveler zengin birbiriyle ilişkili yayılma alanı oluşturur ve veri yapılarını izler ve bunları bağlamlar arasında yayılım. OpenTelemetry öncesinde bunlar genellikle yalnızca özel günlük iletileri olarak veya izleme araçlarını oluşturan satıcıya özgü özel veri yapıları olarak eklenmişti. OpenTelemetry ayrıca geleneksel günlük öncelikli bir yaklaşımdan daha zengin bir izleme veri modelini teşvik eder ve günlük iletileri oluşturuldukları izlemelere ve aralıklara bağlı olduğundan günlükler daha kullanışlıdır. Bu genellikle belirli bir işlem veya istekle ilişkili günlükleri bulmayı kolaylaştırır.
Azure SDK'larının çoğu OpenTelemetry ile izlenmiştir veya uygulama sürecindedir.
Uygulama geliştiricisi, aşağıdaki etkinlikleri yapmak için OpenTelemetry SDK'larını kullanarak el ile izleme ekleyebilir:
- Temel alınan kitaplığın sağlamadığı izleme ekleme.
- Uygulamaya özgü iş birimlerini kullanıma sunmak için span'lar ekleyerek izleme bağlamını zenginleştirin (her sipariş satırının işlenmesi için bir yayılma alanı oluşturan bir sipariş döngüsü gibi).
- Daha kolay izleme sağlamak için var olan yayılma aralıklarını varlık anahtarlarıyla zenginleştirin. (Örneğin, bu siparişi işleyen isteğe bir OrderID anahtarı/değeri ekleyin.) Bu anahtarlar, izleme araçları tarafından sorgulama, filtreleme ve toplama için yapılandırılmış değerler olarak ortaya çıkar (günlük iletisi dizelerini ayrıştırmadan veya günlük öncelikli bir yaklaşımda olduğu gibi günlük iletisi dizilerinin birleşimlerini aramadan).
- İzleme ve yayılma özniteliklerine erişerek, traceId'leri yanıtlara ve yüklere ekleyerek ve/veya istekleri ve yayılmaları oluşturmak için gelen iletilerden traceId'leri okuyarak izleme bağlamını yayma.
OpenTelemetry belgelerinde izleme ve OpenTelemetry SDK'ları hakkında daha fazla bilgi edinin.
Application Insights
Application Analizler, OpenTelemetry ve izleme kitaplıklarından zengin veriler toplar ve zengin görselleştirme ve sorgu desteği sağlamak için bunları verimli bir veri deposunda yakalar. Application Analizler .NET, Java, Node.js ve Python gibi diller için OpenTelemetry tabanlı izleme kitaplıkları, Telemetri verilerinin Application Analizler'a gönderilmesini kolaylaştırır.
.NET Core kullanıyorsanız Kubernetes için Uygulama Analizler kitaplığını da göz önünde bulundurmanızı öneririz. Bu kitaplık Application Analizler izlemelerini kapsayıcı, düğüm, pod, etiketler ve çoğaltma kümesi gibi ek bilgilerle zenginleştirir.
Uygulama Analizler OpenTelemetry bağlamını kendi iç veri modeliyle eşler:
- İzleme -> İşlem
- İzleme Kimliği -> İşlem Kimliği
- Span -> İstek veya Bağımlılık
Aşağıdaki noktaları dikkate alın:
- Veri hızı üst sınırı aşarsa uygulama Analizler telemetriyi kısıtlar. Ayrıntılar için bkz. Uygulama Analizler sınırları. Tek bir işlem birkaç telemetri olayı oluşturabilir, bu nedenle bir uygulama yüksek miktarda trafikle karşılaşırsa büyük olasılıkla kısıtlanabilir.
- Uygulama Analizler verileri toplu işlediğinden, bir işlem işlenmeyen özel durumla başarısız olursa toplu işlemi kaybedebilirsiniz.
- Uygulama Analizler faturalaması veri hacmini temel alır. Daha fazla bilgi için bkz. Uygulama Analizler fiyatlandırmayı ve veri hacmini yönetme.
Yapılandırılmış günlük kaydı
Günlüklerin ayrıştırmasını kolaylaştırmak için, yapılandırabildiğiniz zaman yapılandırılmış günlükleri kullanın. Yapılandırılmış günlük kaydı kullandığınızda, uygulama günlükleri yapılandırılmamış metin dizeleri çıkarmak yerine JSON gibi yapılandırılmış bir biçimde yazar. Birçok yapılandırılmış günlük kitaplığı vardır. Örneğin, .NET Core için Serilog kitaplığını kullanan bir günlük deyimi aşağıda verilmiştır:
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
...
}
Burada çağrısı LogInformation bir Id parametre ve DeliveryInfo parametre içerir. Yapılandırılmış günlük kullandığınızda, bu değerler ileti dizesiyle ilişkilendirmez. Bunun yerine, günlük çıkışı şuna benzer:
{"@t":"2019-06-13T00:57:09.9932697Z","@mt":"In Put action with delivery {Id}: {@DeliveryInfo}","Id":"36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef","DeliveryInfo":{...
Bu bir JSON dizesidir; burada @t alan bir zaman damgasıdır, @mt ileti dizesidir ve kalan anahtar/değer çiftleri parametrelerdir. JSON biçiminin çıkışı, verileri yapılandırılmış bir şekilde sorgulamayı kolaylaştırır. Örneğin, Kusto sorgu dilinde yazılan aşağıdaki Log Analytics sorgusu, adlı fabrikam-deliverytüm kapsayıcılardan bu iletinin örneklerini arar:
traces
| where customDimensions.["Kubernetes.Container.Name"] == "fabrikam-delivery"
| where customDimensions.["{OriginalFormat}"] == "In Put action with delivery {Id}: {@DeliveryInfo}"
| project message, customDimensions["Id"], customDimensions["@DeliveryInfo"]
Sonucu Azure portalında görüntülerseniz, bunun modelin serileştirilmiş gösterimini DeliveryInfo içeren yapılandırılmış bir kayıt olduğunu görebilirsinizDeliveryInfo:

Bu örnekteki JSON şöyledir:
{
"Id": "36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef",
"Owner": {
"UserId": "user id for logging",
"AccountId": "52dadf0c-0067-43e7-af76-86e32b48bc5e"
},
"Pickup": {
"Altitude": 0.29295161612934972,
"Latitude": 0.26815900219052985,
"Longitude": 0.79841844309047727
},
"Dropoff": {
"Altitude": 0.31507750848078986,
"Latitude": 0.753494655598651,
"Longitude": 0.89352830773849423
},
"Deadline": "string",
"Expedited": true,
"ConfirmationRequired": 0,
"DroneId": "AssignedDroneId01ba4d0b-c01a-4369-ba75-51bde0e76cc9"
}
Birçok günlük iletisi, bir iş biriminin başlangıcını veya sonunu işaretler veya izlenebilirlik için bir iş varlığını bir dizi ileti ve işlemle bağlar. Çoğu durumda OpenTelemetry span ve request nesnelerini zenginleştirmek yalnızca işlemin başlangıç ve bitişini günlüğe kaydetmekten daha iyi bir yaklaşımdır. Bunu yaptığınızda bu bağlam tüm bağlı izlemelere ve alt işlemlere eklenir ve bu bilgiler tam işlemin kapsamına eklenir. Çeşitli diller için OpenTelemetry SDK'ları, yayılma alanları oluşturmayı veya span'lara özel öznitelikler eklemeyi destekler. Örneğin aşağıdaki kod, Application Analizler tarafından desteklenen Java OpenTelemetry SDK'sını kullanır. Var olan bir üst yayılma alanı (örneğin, rest denetleyici çağrısıyla ilişkilendirilmiş ve kullanılmakta olan web çerçevesi tarafından oluşturulan bir istek aralığı), burada gösterildiği gibi kendisiyle ilişkilendirilmiş bir varlık kimliğiyle zenginleştirilebilir:
import io.opentelemetry.api.trace.Span;
// ...
Span.current().setAttribute("A1234", deliveryId);
Bu kod, geçerli yayılma alanı üzerinde bir anahtar veya değer ayarlar. Bu anahtar, söz konusu yayılma alanının altında gerçekleşen işlemlere ve günlük iletilerine bağlanır. Değer, burada gösterildiği gibi Uygulama Analizler isteği nesnesinde görünür:
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project timestamp, name, url, success, resultCode, duration, operation_Id, deliveryId
Bu teknik, burada gösterildiği gibi günlükler, filtreleme ve span bağlamı ile günlük izlemelerine ek açıklama ekleme ile kullanıldığında daha güçlü hale gelir:
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project deliveryId, operation_Id, requestTimestamp = timestamp, requestDuration = duration // keep some request info
| join kind=inner traces on operation_Id // join logs only for this deliveryId
| project requestTimestamp, requestDuration, logTimestamp = timestamp, deliveryId, message
OpenTelemetry ile önceden izlenmiş bir kitaplık veya çerçeve kullanıyorsanız, yayılma alanları ve istekler oluşturulur, ancak uygulama kodu da iş birimleri oluşturabilir. Örneğin, her biri üzerinde çalışma gerçekleştiren bir varlık dizisi boyunca döngü yapan bir yöntem, işleme döngüsünün her yinelemesi için bir span oluşturabilir. Uygulama ve kitaplık koduna izleme ekleme hakkında bilgi için OpenTelemery izleme belgelerine bakın.
Dağıtılmış izleme
Mikro hizmetleri kullanırken karşılaşılan zorluklardan biri, hizmetler arasında olayların akışını anlamaktır. Tek bir işlem birden çok hizmete yapılan çağrıları içerebilir.
Dağıtılmış izleme örneği
Bu örnekte, bir dizi mikro hizmet aracılığıyla dağıtılmış bir işlemin yolu açıklanmaktadır. Örnek, bir insansız hava aracı teslim uygulamasını temel alır.
Bu senaryoda, dağıtılmış işlem şu adımları içerir:
- Alma hizmeti, Azure Service Bus kuyruğuna bir ileti yerleştirir.
- İş Akışı hizmeti iletiyi kuyruktan çeker.
- İş Akışı hizmeti, isteği işlemek için üç arka uç hizmetini çağırır (İnsansız Hava Aracı Zamanlayıcı, Paket ve Teslimat).
Aşağıdaki ekran görüntüsünde insansız hava aracı teslim uygulaması için uygulama haritası gösterilmektedir. Bu harita, beş mikro hizmet içeren bir iş akışına neden olan genel API uç noktasına yapılan çağrıları gösterir.
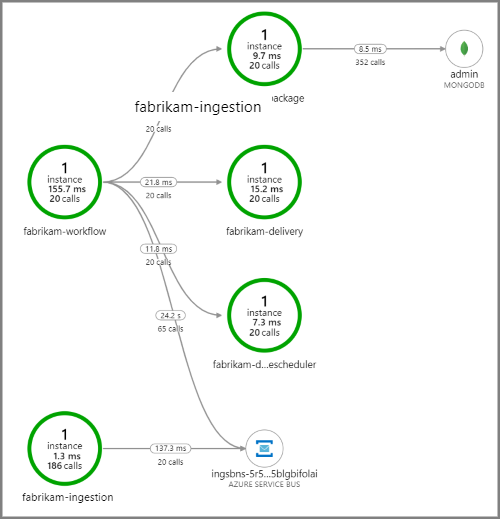
Service Bus kuyruğundan fabrikam-workflow ve fabrikam-ingestion kuyruğuna giden oklar, iletilerin gönderildiği ve alındığı yeri gösterir. Diyagramdan hangi hizmetin ileti gönderdiğini ve hangilerinin aldığını anlayamazsınız. Oklar her iki hizmetin de Service Bus'ı çağırdığını gösterir. Ancak, hangi hizmetin gönderdiği ve hangi hizmeti aldığıyla ilgili bilgiler şu ayrıntılarda bulunabilir:
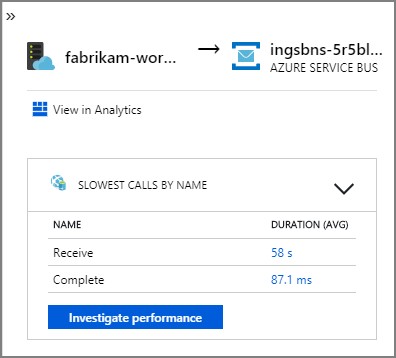
Her çağrı bir işlem kimliği içerdiğinden, zamanlama bilgileri ve her adımda HTTP çağrıları dahil olmak üzere tek bir işlemin uçtan uca adımlarını da görüntüleyebilirsiniz. Böyle bir işlemin görselleştirmesi aşağıdadır:

Bu görselleştirme, alma hizmetinden kuyruğa, kuyruktan İş Akışı hizmetine ve İş Akışı hizmetinden diğer arka uç hizmetlerine kadar olan adımları gösterir. Son adım, Service Bus iletisini tamamlandı olarak işaret eden İş Akışı hizmetidir.
Bu örnekte, başarısız olan bir arka uç hizmetine yapılan çağrılar gösterilir:
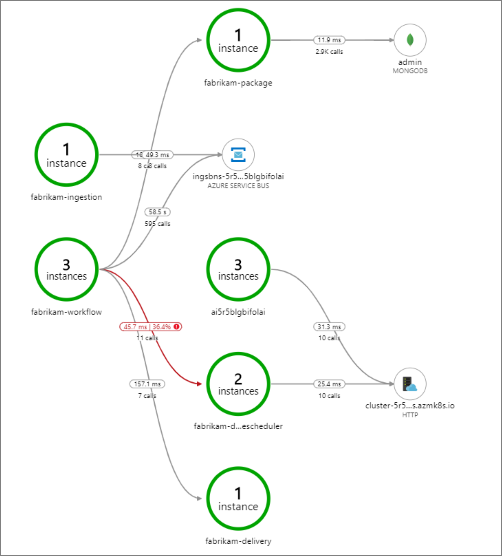
Bu harita, İnsansız Hava Aracı Zamanlayıcı hizmetine yapılan çağrıların büyük bir kısmının (%36) sorgu sırasında başarısız olduğunu gösterir. Uçtan uca işlem görünümü, hizmete bir HTTP PUT isteği gönderildiğinde bir özel durumun oluştuğunun ortaya çıktığını gösterir:

Daha fazla detaya giderseniz, özel durumun bir yuva özel durumu olduğunu görebilirsiniz: "Böyle bir cihaz veya adres yok."
Fabrikam.Workflow.Service.Services.BackendServiceCallFailedException:
No such device or address
---u003e System.Net.Http.HttpRequestException: No such device or address
---u003e System.Net.Sockets.SocketException: No such device or address
Bu özel durum, arka uç hizmetine ulaşılamazsınız. Bu noktada, dağıtım yapılandırmasını görüntülemek için kubectl kullanabilirsiniz. Bu örnekte, Kubernetes yapılandırma dosyalarındaki bir hata nedeniyle hizmet ana bilgisayar adı çözülemiyor. Kubernetes belgelerindeki Hizmetlerde Hata Ayıklama makalesinde bu tür hataları tanılamaya yönelik ipuçları bulunur.
Hataların bazı yaygın nedenleri şunlardır:
- Kod hataları. Bu hatalar şu şekilde görünebilir:
- Özel Durumlar. Özel durum ayrıntılarını görüntülemek için Uygulama Analizler günlüklerine bakın.
- İşlem başarısız oluyor. Kapsayıcı ve pod durumuna bakın ve kapsayıcı günlüklerini veya Uygulama Analizler izlemelerini görüntüleyin.
- HTTP 5xx hataları.
- Kaynak tükenmesi:
- Azaltma (HTTP 429) veya istek zaman aşımları arayın.
- CPU, bellek ve disk için kapsayıcı ölçümlerini inceleyin.
- Kapsayıcı ve pod kaynak sınırlarının yapılandırmalarına bakın.
- Hizmet bulma. Kubernetes hizmet yapılandırmasını ve bağlantı noktası eşlemelerini inceleyin.
- API uyuşmazlığı. HTTP 400 hatalarını arayın. API'ler sürümüne sahipse çağrılan sürüme bakın.
- Kapsayıcı görüntüsü çekerken hata oluştu. Pod belirtimine bakın. Ayrıca kümenin kapsayıcı kayıt defterinden çekme yetkisine sahip olduğundan emin olun.
- RBAC sorunları.
Sonraki adımlar
Azure İzleyici'de AKS'de uygulamaların izlenmesini destekleyen özellikler hakkında daha fazla bilgi edinin:
- Azure İzleyici kapsayıcı içgörülerine genel bakış
- Azure İzleyici Kapsayıcı içgörüleri ile AKS kümesi performansını anlama