CQRS, bir veri deposu için okuma ve güncelleştirme işlemlerini ayıran bir desen olan Komut ve Sorgu Sorumluluğu Ayrımı'nın kısaltmasıdır. Uygulamanızda CQRS uygulamak performansını, ölçeklenebilirliğini ve güvenliğini en üst düzeye çıkarabilir. CQRS'ye geçirilerek oluşturulan esneklik, bir sistemin zaman içinde daha iyi gelişmesine olanak tanır ve güncelleştirme komutlarının etki alanı düzeyinde birleştirme çakışmalarına neden olmasını önler.
Bağlam ve sorun
Geleneksel mimarilerde, bir veritabanının sorgulanması ve güncelleştirilmesi için aynı veri modeli kullanılır. Bu, basit bir işlemdir ve temel CRUD işlemleri için kullanışlıdır. Ancak daha karmaşık uygulamalarda bu yaklaşım zahmetli hale gelebilir. Örneğin, okuma tarafında, uygulama birçok farklı sorgu gerçekleştirerek farklı şekillere sahip veri aktarımı nesneleri (DTO’lar) döndürebilir. Nesne eşleme karmaşık hale gelebilir. Yazma tarafında ise modeli, karmaşık doğrulama ve iş mantığı uygulayabilir. Sonuç olarak, çok fazla işlem gerçekleştiren aşırı karmaşık bir modelle karşı karşıya kalabilirsiniz.
Okuma ve yazma iş yükleri genellikle çok farklı performans ve ölçek gereksinimleriyle asimetriktir.
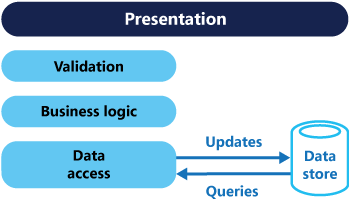
Verilerin okuma ve yazma gösterimleri arasında genellikle bir işlem parçası olarak gerekli olmasalar bile doğru güncelleştirilmesi gereken ek sütunlar veya özellikler gibi bir uyuşmazlık vardır.
İşlemler aynı veri kümesinde paralel olarak gerçekleştirildiğinde veri çekişmesi oluşabilir.
Geleneksel yaklaşım, veri deposu ve veri erişim katmanı üzerindeki yük ve bilgileri almak için gereken sorguların karmaşıklığı nedeniyle performans üzerinde olumsuz bir etkiye sahip olabilir.
Her varlık hem okuma hem de yazma işlemlerine tabi olduğundan güvenliği ve izinleri yönetmek karmaşık hale gelebilir ve bu da verileri yanlış bağlamda kullanıma sunabilir.
Çözüm
CQRS, verileri güncelleştirmek için komutları ve verileri okumak için sorgular kullanarak okuma ve yazmaları farklı modellere ayırır.
- Komutlar veri merkezli değil görev tabanlı olmalıdır. ("Rezervasyon otel odası", "ReservationStatus'ı Ayrılmış olarak ayarlama") değil. Bu, kullanıcı etkileşim stilinde bazı ilgili değişiklikleri gerektirebilir. Bunun diğer bölümü, bu komutların daha sık başarılı olması için iş mantığını işlemenin değiştirilmesine bakmaktır. Bunu destekleyen bir teknik, komutu göndermeden önce bile istemcide bazı doğrulama kuralları çalıştırmak, muhtemelen düğmeleri devre dışı bırakmak ve bunun nedenini kullanıcı arabiriminde açıklamaktır ("oda kalmadı"). Bu şekilde, sunucu tarafı komut hatalarının nedeni yarış koşullarına (son odada rezervasyon yapmaya çalışan iki kullanıcı) daraltılabilir ve hatta bunlar bazen daha fazla veri ve mantıkla (bir konuğu bekleme listesine koymak) ele alınabilir.
- Komutlar zaman uyumlu olarak işlenmek yerine zaman uyumsuz işleme için kuyruğa yerleştirilebilir.
- Sorgular, veritabanını hiçbir zaman değiştirmez. Bir sorgu, herhangi bir etki alanı bilgisini kapsamayan bir DTO döndürür.
Ardından, aşağıdaki diyagramda gösterildiği gibi modeller yalıtılabilir, ancak bu mutlak bir gereksinim değildir.
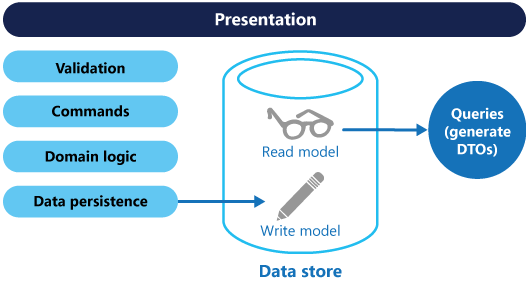
Ayrı sorgu ve güncelleştirme modellerinin olması tasarımı ve uygulamayı basitleştirir. Ancak, CQRS kodunun O/RM araçları gibi yapı iskelesi mekanizmaları kullanılarak bir veritabanı şemasından otomatik olarak oluşturulamaması bir dezavantajdır (Ancak, özelleştirmenizi oluşturulan kodun üzerinde oluşturabileceksiniz).
Daha büyük bir ayırma işlemi için okuma verilerini, yazma verilerinden fiziksel olarak ayırabilirsiniz. Bu durumda, okuma veritabanı, sorgular için optimize edilmiş kendi veri şemasını kullanabilir. Örneğin, karmaşık birleştirmelerden veya karmaşık O/RM eşlemelerinden kaçınmak için verilerin gerçekleştirilmiş bir görünümünü depolayabilir. Ayrıca farklı türde bir veri deposu bile kullanabilir. Örneğin, yazma veritabanı ilişkisel olabilse de okuma veritabanı bir belge veritabanıdır.
Ayrı okuma ve yazma veritabanları kullanılıyorsa, bunların eşitlenmiş olarak tutulması gerekir. Bu genellikle yazma modelinin veritabanını her güncelleştirdiğinde bir olay yayımlamasını sağlayarak gerçekleştirilir. Olayları kullanma hakkında daha fazla bilgi için bkz . Olay temelli mimari stili. İleti aracıları ve veritabanları genellikle tek bir dağıtılmış işlemde listelenemediğinden, veritabanını güncelleştirirken ve olayları yayımlarken tutarlılığı garanti etme konusunda zorluklar olabilir. Daha fazla bilgi için, bir kez etkili ileti işleme yönergelerine bakın.
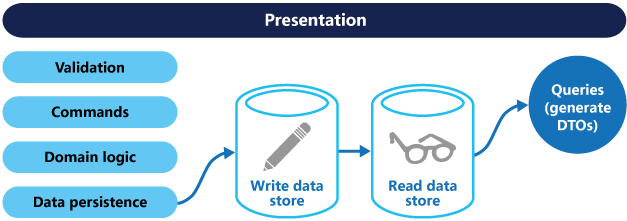
Okuma deposu yazma deposunun salt okunur bir çoğaltması olabilir ya da okuma ve yazma depoları tamamen farklı bir yapıda olabilir. Birden çok salt okunur çoğaltma kullanmak, özellikle salt okunur çoğaltmaların uygulama örneklerine yakın bir yerde bulunduğu dağıtılmış senaryolarda sorgu performansını artırabilir.
Okuma ve yazma depolarının ayrılması, her birinin yüke uygun şekilde ölçeklendirilmesine de imkan sağlar. Örneğin, okuma depolarının yükü genellikle yazma depolarından çok daha yüksektir.
Bazı CQRS uygulamaları Olay Kaynağını Belirleme düzenini kullanır. Bu düzenle uygulama durumu bir olay dizisi olarak depolanır. Her olay, verilerdeki bir dizi değişikliği temsil eder. Geçerli durum, olaylar yeniden yürütülerek oluşturulur. CQRS bağlamında, Olay Kaynağını Belirleme'nin avantajlarından biri, aynı olayların diğer bileşenlere , özellikle de okuma modeline bildirimde bulunabilmek için kullanılabilmesidir. Okuma modeli, geçerli durumun anlık görüntüsünü oluşturmak için olayları kullanır; bu, sorgular için daha etkilidir. Ancak Olay Kaynağını Belirleme, tasarıma karmaşıklık ekler.
CQRS'nin avantajları şunlardır:
- Bağımsız ölçeklendirme. CQRS, okuma ve yazma iş yüklerinin bağımsız olarak ölçeklendirilebilmesine olanak tanır ve daha az sayıda kilit çakışması oluşmasını sağlayabilir.
- En iyi duruma getirilmiş veri şemaları. Yazma tarafı, sorgular için en iyi duruma getirilmiş bir şemayı; yazma tarafı ise güncelleştirmeler için en iyi duruma getirilmiş bir şemayı kullanır.
- Güvenlik. Veriler üzerinde yazma işlemini yalnızca uygun etki alanı varlıklarının gerçekleştirmesini sağlamak artık daha kolay.
- Görev ayrımı. Okuma ve yazma taraflarının ayrılması daha sürdürülebilir ve esnek modellerin oluşmasını sağlayabilir. Karmaşık iş mantığının büyük bir kısmı yazma modelinden geçer. Okuma modeli oldukça basit olabilir.
- Daha basit sorgular. Uygulama, okuma veritabanında gerçekleştirilmiş bir görünüm depolayarak, sorgu oluşturma sırasında karmaşık birleştirme işlemlerinden kaçınabilir.
Uygulama sorunları ve dikkat edilmesi gerekenler
Bu düzeni uygulamanın bazı zorlukları şunlardır:
Karmaşıklık. CQRS mantığı temel olarak basittir. Ancak özellikle Olay Kaynağını Belirleme düzeni dahilse bu, daha karmaşık bir uygulama tasarımına neden olabilir.
Mesajlaşma. CQRS için mesajlaşma gerekli olmasa da komutları işlemek ve güncelleştirme olaylarını yayımlamak için yaygın olarak kullanılan bir işlevdir. Bu durumda uygulamanın, ileti hatalarını veya yinelenen iletileri işlemesi gerekir. Farklı önceliklere sahip komutlarla ilgilenmek için Öncelik Kuyrukları kılavuzuna bakın.
Nihai tutarlılık. Okuma ve yazma veritabanlarını ayırıyorsanız okuma veritabanı eski olabilir. Okuma modeli deposu, yazma modeli deposundaki değişiklikleri yansıtacak şekilde güncelleştirilmelidir ve bir kullanıcının eski okuma verilerine dayalı bir istek yayımladığını algılamak zor olabilir.
CQRS deseni ne zaman kullanılır?
Aşağıdaki senaryolar için CQRS'yi göz önünde bulundurun:
Birçok kullanıcının aynı verilere paralel olarak eriştiği işbirliğine dayalı etki alanları. CQRS, etki alanı düzeyinde birleştirme çakışmalarını en aza indirmek için yeterli ayrıntı düzeyine sahip komutlar tanımlamanıza olanak tanır ve ortaya çıkan çakışmalar komutuyla birleştirilebilir.
Karmaşık bir işlem boyunca kullanıcılara bir dizi adımla veya karmaşık etki alanı modelleriyle rehberlik eden görev tabanlı kullanıcı arabirimleri. Yazma modeli, iş mantığı, giriş doğrulaması ve iş doğrulama ile tam bir komut işleme yığınına sahiptir. Yazma modeli, veri değişiklikleri (DDD terminolojisinde bir toplama) için ilişkili nesneler kümesini tek bir birim olarak ele alabilir ve bu nesnelerin her zaman tutarlı bir durumda olduğundan emin olabilir. Okuma modelinin iş mantığı veya doğrulama yığını yoktur ve yalnızca görünüm modelinde kullanmak üzere bir DTO döndürür. Okuma modeli, nihai olarak yazma modeliyle tutarlıdır.
Özellikle okuma sayısı yazma sayısından çok daha fazla olduğunda, veri okumalarının performansının veri yazma performansından ayrı olarak ayarlanması gereken senaryolar. Bu senaryoda, okuma modelinin ölçeğini genişletebilir, ancak yazma modelini yalnızca birkaç örnekte çalıştırabilirsiniz. Yazma modeli örnek sayısının az olması, birleştirme çakışmaları sayısının en aza indirilmesine de yardımcı olur.
Bir geliştirici ekibinin yazma modelinin bir parçası olan karmaşık etki alanı modeline, başka bir ekibin okuma modeline ve kullanıcı arabirimine odaklanabileceği senaryolar.
Sistemin zamanla gelişmesinin beklendiği ve modelin birden fazla sürümünü içerebildiği ya da iş kurallarının düzenli olarak değiştiği senaryolarda.
Bir alt sistemin geçici olarak başarısız olması durumunda diğerlerinin kullanılabilirlik açısından etkilenme olasılığının düşük olduğu, özellikle de olay kaynağını belirleme ile birlikte diğer sistemlerle tümleştirme gerektiren durumlar.
Bu desen aşağıdaki durumlarda önerilmez:
Etki alanı veya iş kuralları basittir.
Basit bir CRUD stili kullanıcı arabirimi ve veri erişim işlemleri yeterlidir.
CQRS modelini yalnızca en çok değer katacağını düşündüğünüz belirli sistem bölümlerine uygulayın.
İş yükü tasarımı
Bir mimar, Azure İyi Tasarlanmış Çerçeve yapılarında ele alınan hedefleri ve ilkeleri ele almak için CQRS deseninin iş yükünün tasarımında nasıl kullanılabileceğini değerlendirmelidir. Örneğin:
| Yapı Taşı | Bu desen sütun hedeflerini nasıl destekler? |
|---|---|
| Performans Verimliliği , ölçeklendirme, veri ve kod iyileştirmeleri aracılığıyla iş yükünüzün talepleri verimli bir şekilde karşılamasını sağlar. | Okuma ve yazma işlemlerinin yüksek okuma-yazma iş yüklerinde ayrılması, her işlemin belirli bir amacı için hedeflenen performans ve ölçeklendirme iyileştirmelerine olanak tanır. - PE:05 Ölçeklendirme ve bölümleme - PE:08 Veri performansı |
Herhangi bir tasarım kararında olduğu gibi, bu desenle ortaya konulabilecek diğer sütunların hedeflerine karşı herhangi bir dengeyi göz önünde bulundurun.
Olay Kaynağını Belirleme ve CQRS düzeni
CQRS modeli çoğunlukla Olay Kaynağını Belirleme modeli ile birlikte kullanılır. CQRS tabanlı sistemler, her biri ilgili görevlere uyarlanmış ve genellikle fiziksel olarak ayrı depolarda bulunan ayrı okuma ve yazma modelleri kullanır. Olay Kaynağını Belirleme modeli ile birlikte kullanıldığında, olayların yer aldığı ve resmi bilgi kaynağı olan depo yazma modelidir. CQRS tabanlı bir sistemin okuma modeli, verilerin gerçekleştirilmiş görünümlerini (genellikle yüksek oranda normalleştirilmişlikten çıkarılmış görünümler olarak) sağlar. Bu görünümler uygulamanın arabirimlerine ve görüntüleme gereksinimlerine uyarlandığından, hem görüntüleme hem de sorgu performansının en üst düzeye çıkarılmasına yardımcı olur.
Yazma deposu olarak bir noktadaki gerçek veriler yerine olay akışının kullanılması, tek bir toplamada güncelleştirme çakışmaları gerçekleşmesini önler ve performans ile ölçeklenebilirliği en üst düzeye çıkarır. Olaylar, okuma deposunun doldurulması için kullanılan gerçekleştirilmiş veri görünümlerinin zaman uyumsuz olarak oluşturulması için kullanılabilir.
Olay deposu resmi bilgi kaynağı olduğundan, sistem geliştiğinde veya okuma modelinin değiştirilmesi gerektiğinde gerçekleştirilmiş görünümlerin silinmesi ve tüm geçmiş olayların yeniden yürütülmesi yoluyla geçerli durumun yeni bir temsilinin oluşturulması mümkündür. Gerçekleştirilmiş görünümler aslında dayanıklı bir salt okunur veri önbelleğidir.
CQRS modelini Olay Kaynağını Belirleme modeli ile birlikte kullanırken aşağıdaki noktalara dikkat edin:
Yazma ve okuma depolarının ayrı olduğu tüm sistemlerde olduğu gibi bu modeli temel alan sistemler yalnızca son tutarlılık sağlar. Olayın oluşturulması ile veri deposunun güncelleştirilmesi arasında bir gecikme olur.
Olayların başlatılması veya işlenmesi ve sorgular ya da bir okuma modeli için gerekli uygun görünümlerin veya nesnelerin derlenmesi ya da güncelleştirilmesi için kod oluşturulması gerektiğinden, bu model karmaşıklığın artmasına neden olur. Olay Kaynağını Belirleme modeli ile birlikte kullanılan CQRS modelinin karmaşıklığı, başarılı bir uygulamanın zorlaşmasına yol açabilir ve sistem tasarımı konusunda farklı bir yaklaşım gerektirir. Bununla birlikte, olay kaynağını belirleme modeli etki alanının modellenmesini kolaylaştırabilir ve verilerdeki değişikliklerin amacı korunduğundan, görünümleri yeniden oluşturmak ya da yeni görünümler oluşturmak daha kolaydır.
Belirli varlıklar veya varlık koleksiyonları için olayların yeniden yürütülmesi ve işlenmesi yoluyla okuma modelinde veya veri izdüşümlerinde kullanılmak üzere gerçekleştirilmiş görünümler oluşturmak için gerekli işleme süresi ve kaynak kullanımı önemli bir boyutta olabilir. Bu, özellikle de değerlerin uzun dönemler boyunca toplanmasını veya analiz edilmesini gerektiren durumlar (tüm ilişkili olayların incelenmesi gerekebileceğinden) için geçerlidir. Gerçekleşen belirli bir eylemin toplam sayısı veya bir varlığın geçerli durumu gibi zamanlanmış aralıklarla verilerin anlık görüntülerini uygulayarak bu sorunu çözebilirsiniz.
CQRS deseni örneği
Aşağıdaki kodda, okuma ve yazma modelleri için farklı tanımlar kullanılan örnek bir CQRS uygulamasından alınan bazı bölümler gösterilmiştir. Model arabirimleri temel veri depolarının herhangi bir özelliğe sahip olmasını zorunlu kılmaz ve bu arabirimler ayrı olduğundan, depolar bağımsız olarak geliştirilebilir ve depolarda ince ayar yapılabilir.
Aşağıdaki kodda okuma modeli tanımı gösterilmiştir.
// Query interface
namespace ReadModel
{
public interface ProductsDao
{
ProductDisplay FindById(int productId);
ICollection<ProductDisplay> FindByName(string name);
ICollection<ProductInventory> FindOutOfStockProducts();
ICollection<ProductDisplay> FindRelatedProducts(int productId);
}
public class ProductDisplay
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public decimal UnitPrice { get; set; }
public bool IsOutOfStock { get; set; }
public double UserRating { get; set; }
}
public class ProductInventory
{
public int Id { get; set; }
public string Name { get; set; }
public int CurrentStock { get; set; }
}
}
Sistem, kullanıcıların ürünleri derecelendirmesine izin verir. Uygulama kodu bunu aşağıdaki kodda gösterilen RateProduct komutunu kullanarak yapar.
public interface ICommand
{
Guid Id { get; }
}
public class RateProduct : ICommand
{
public RateProduct()
{
this.Id = Guid.NewGuid();
}
public Guid Id { get; set; }
public int ProductId { get; set; }
public int Rating { get; set; }
public int UserId {get; set; }
}
Sistem, uygulama tarafından gönderilen komutları işlemek için ProductsCommandHandler sınıfını kullanır. İstemciler komutları genellikle kuyruk gibi bir mesajlaşma sistemi üzerinden etki alanına gönderir. Komut işleyici bu komutları kabul eder ve etki alanı arabiriminin metotlarını çağırır. Her komutun ayrıntı düzeyi, isteklerin çakışma olasılığını azaltmaya yönelik olarak tasarlanır. Aşağıdaki kodda bir ProductsCommandHandler sınıfının ana hattı gösterilmiştir.
public class ProductsCommandHandler :
ICommandHandler<AddNewProduct>,
ICommandHandler<RateProduct>,
ICommandHandler<AddToInventory>,
ICommandHandler<ConfirmItemShipped>,
ICommandHandler<UpdateStockFromInventoryRecount>
{
private readonly IRepository<Product> repository;
public ProductsCommandHandler (IRepository<Product> repository)
{
this.repository = repository;
}
void Handle (AddNewProduct command)
{
...
}
void Handle (RateProduct command)
{
var product = repository.Find(command.ProductId);
if (product != null)
{
product.RateProduct(command.UserId, command.Rating);
repository.Save(product);
}
}
void Handle (AddToInventory command)
{
...
}
void Handle (ConfirmItemsShipped command)
{
...
}
void Handle (UpdateStockFromInventoryRecount command)
{
...
}
}
Sonraki adımlar
Bu model uygulanırken aşağıdaki modeller ve yönergeler kullanışlıdır:
Veri Tutarlılığı Temel Bilgileri. SQRS modeli kullanılırken okuma ve yazma veri depoları arasındaki son tutarlılık nedeniyle sık karşılaşılan sorunları ve bunların nasıl çözülebileceğini açıklar.
Yatay, dikey ve işlevsel veri bölümleme. Ölçeklenebilirliği geliştirmek, çekişmeyi azaltmak ve performansı iyileştirmek için verileri ayrı olarak yönetilebilen ve erişilebilen bölümlere bölmeye yönelik en iyi yöntemleri açıklar.
Modeller ve uygulamalar kılavuzu CQRS Gezisi. Özellikle, Komut Sorgusu Sorumluluğu Ayrım düzenine giriş, deseni ve ne zaman yararlı olduğunu keşfeder ve Epilogue: Öğrenilen Dersler, bu deseni kullanırken ortaya çıkan sorunların bazılarını anlamanıza yardımcı olur.
Martin Fowler'ın blog gönderileri:
İlgili kaynaklar
Olay Kaynağını Belirleme düzeni. Etki alanlarındaki karmaşık görevlerin basitleştirilmesinin yanı sıra performans, ölçeklenebilirlik ve yanıt verme hızının artırılması amacıyla Olay Kaynağını Belirleme modelinin nasıl CQRS modeliyle birlikte kullanılabileceğini açıklar. Ayrıca, işlem verilerinde tutarlılık sağlarken telafi eylemlerine olanak tanıyacak tam denetim kayıtlarını ve geçmişini korumanın nasıl mümkün olduğunu gösterir.
Gerçekleştirilmiş Görünüm düzeni. Bir CQRS uygulamasının okuma modeli, yazma modeli verilerinin gerçekleştirilmiş görünümlerini içerebilir ya da gerçekleştirilmiş görünümlerin oluşturulması için okuma modeli kullanılabilir.
Zaman uyumsuz kullanıcı etkileşim desenleri aracılığıyla daha iyi CQRS'de sunu