Bu başvuru mimarisi, kullanılabilirlik ve sağlam bir olağanüstü durum kurtarma altyapısı elde etmek için birden çok Azure bölgesinde N katmanlı bir uygulamayı çalıştırmaya yönelik kanıtlanmış bir dizi yöntem gösterir.
Mimari
Bu mimarinin bir Visio dosyasını indirin.
İş Akışı
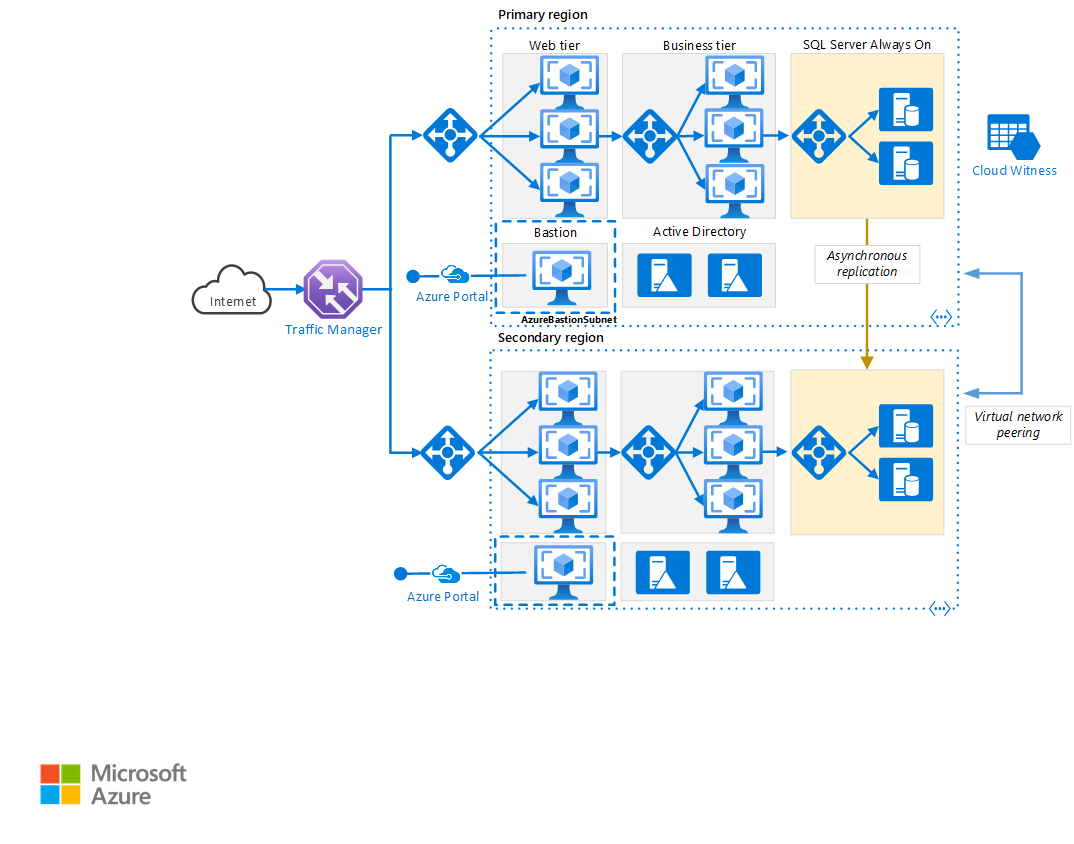
Birincil ve ikincil bölgeler. Yüksek kullanılabilirlik elde etmek için iki bölge kullanın. Bunlardan biri, birincil bölgedir. Diğeri yük devretme bölgesidir.
Azure Traffic Manager. Traffic Manager, gelen istekleri bölgelerden birine yönlendirir. Normal işlemler sırasında, istekleri birincil bölgeye yönlendirir. Bu bölge kullanılamaz duruma gelirse Traffic Manager, yükü ikincil bölgeye devreder. Daha fazla bilgi için bkz. Traffic Manager yapılandırması.
Kaynak grupları. Birincil bölge, ikincil bölge ve Traffic Manager için ayrı kaynak grupları oluşturun. Bu yöntem, her bölgeyi tek bir kaynak koleksiyonu olarak yönetme esnekliği sağlar. Örneğin, bir bölgeyi devre dışı bırakmadan diğer bölgeyi yeniden dağıtabilirsiniz. Uygulamaya ilişkin tüm kaynakları listelemek üzere sorgu çalıştırabilmek için kaynak gruplarını bağlayın.
Sanal ağlar. Her bölge için ayrı bir sanal ağ oluşturun. Adres alanlarının çakışmadığından emin olun.
SQL Server Always On Kullanılabilirlik Grubu. SQL Server kullanıyorsanız, yüksek kullanılabilirlik için SQL Always On Kullanılabilirlik Grupları'nın kullanılmasını öneririz. Her iki bölgedeki SQL Server örneklerini içeren tek bir kullanılabilirlik grubu oluşturun.
Dekont
Ayrıca, bulut hizmet olarak ilişkisel bir veritabanı sağlayan Azure SQL Veritabanı’nı da göz önünde bulundurun. SQL Veritabanı kullanırsanız yük devretme grubu yapılandırmanız veya yük devretmeyi yönetmeniz gerekmez.
Sanal ağ eşlemesi. Birincil bölgeden ikincil bölgeye veri çoğaltmasına izin vermek için iki sanal ağı eşleyin. Daha fazla bilgi için bkz . Sanal ağ eşlemesi.
Bileşenler
- Kullanılabilirlik kümeleri , Azure'da dağıttığınız VM'lerin bir kümedeki birden çok yalıtılmış donanım düğümüne dağıtılmasını sağlar. Azure'da bir donanım veya yazılım hatası oluşursa VM'lerinizin yalnızca bir alt kümesi etkilenir ve çözümünüzün tamamı kullanılabilir ve çalışır durumda kalır.
- Kullanılabilirlik alanları , uygulamalarınızı ve verilerinizi veri merkezi hatalarından korur. Kullanılabilirlik alanları, bir Azure bölgesi içinde ayrı fiziksel konumlardır. Her bölge bağımsız güç, soğutma ve ağ ile donatılmış bir veya daha fazla veri merkezinden oluşur.
- Azure Traffic Manager , trafiği en iyi şekilde dağıtan DNS tabanlı bir trafik yük dengeleyicidir. Yüksek kullanılabilirlik ve yanıt hızı ile küresel Azure bölgelerinde hizmetler sağlar.
- Azure Load Balancer , tanımlanan kurallara ve sistem durumu yoklamalarına göre gelen trafiği dağıtır. Yük dengeleyici, tüm TCP ve UDP uygulamaları için milyonlarca akışın ölçeğini artırarak düşük gecikme süresi ve yüksek aktarım hızı sağlar. Bu senaryoda, gelen istemci trafiğini web katmanına dağıtmak için genel yük dengeleyici kullanılır. Bu senaryoda, iş katmanından arka uç SQL Server kümesine trafiği dağıtmak için iç yük dengeleyici kullanılır.
- Azure Bastion , sağlandığı sanal ağda tüm VM'lere güvenli RDP ve SSH bağlantısı sağlar. RdP/SSH kullanarak güvenli erişim sağlarken sanal makinelerinizi RDP/SSH bağlantı noktalarını dış dünyaya göstermeden korumak için Azure Bastion'ı kullanın.
Öneriler
Çok bölgeli bir mimari, tek bir bölgeye dağıtmaya göre daha yüksek kullanılabilirlik sağlayabilir. Birinci bölge bölgesel bir kesintiden etkileniyorsa, ikinci bölgeye yük devretmek için Traffic Manager kullanabilirsiniz. Mimari ayrıca tek başına bir alt sistem veya uygulama başarısız olursa da yardımcı olabilir.
Bölgeler arasında yüksek kullanılabilirlik sağlamak için birkaç genel yaklaşım bulunur:
- Etkin bekleme ile aktif/pasif. Trafik bir yöne doğru giderken diğerinin etkin beklemesi. Etkin bekleme, ikincil bölgedeki VM'lerin ayrıldığı ve her zaman çalıştığı anlamına gelir.
- Etkin olmayan hazırda bekleme. Trafik bir yöne doğru giderken diğerinin etkin olmayan hazırda beklemesi. Soğuk bekleme, ikincil bölgedeki VM'lerin yük devretme için gerekene kadar ayrılmaması anlamına gelir. Bu yaklaşımı çalıştırmak daha düşük maliyetlidir ancak bir hata sırasında tekrar çevrimiçi olması genellikle daha uzun sürer.
- Etkin/etkin. İki bölge de etkin ve aralarında yük dengelemesi yapılıyor. Bir bölge kullanılamaz duruma gelirse, rotasyondan çıkar.
Bu başvuru mimarisi, yük devretme için Traffic Manager’ı kullanarak etkin bekleme ile aktif/pasif durumuna odaklanır. Çalışırken bekleme için birkaç VM dağıtabilir ve sonra ölçeği gerektiği gibi genişletebilirsiniz.
Bölgesel eşleştirme
Her Azure bölgesi aynı coğrafyadaki başka bir bölgeyle eşleştirilir. Genel olarak, bölgeler için aynı bölge çiftinden (örneğin, Doğu ABD 2 ve ABD Orta) seçim yapın. Bunu yapmanın avantajları şunları içerir:
- Geniş çaplı bir kesinti varsa, her çiftten en az bir bölgenin kurtarılması önceliklendirilir.
- Olası kapalı kalma süresini en aza indirmek için, planlı Azure sistem güncelleştirmeleri bölge çiftlerine tek tek uygulanır.
- Veri yerleşikliğinin karşılanması için çiftler aynı coğrafyada yer alır.
Ancak uygulamanız için gereken tüm Azure hizmetlerinin her iki bölge tarafından da desteklendiğinden emin olun. (Bkz. Bölgeye göre hizmetler.) Bölgesel çiftler hakkında daha fazla bilgi için bkz. İş sürekliliği ve olağanüstü durum kurtarma (BCDR): Eşleştirilmiş Azure Bölgeleri.
Traffic Manager yapılandırması
Traffic Manager’ı yapılandırırken aşağıdaki noktaları göz önünde bulundurun:
- Yönlendirme. Traffic Manager çeşitli yönlendirme algoritmalarını destekler. Bu makalede açıklanan senaryo için, öncelikli yönlendirmeyi (eski adıyla yük devretme yönlendirmesini) kullanın. Bu ayar kullanıldığında, birincil bölge ulaşılamaz duruma gelmediği sürece Traffic Manager tüm istekleri birincil bölgeye gönderir. Bu noktada, otomatik olarak ikinci bölgeye yük devredilir. Bkz. Yük devretme yönlendirme yöntemini yapılandırma.
- Sistem durumu araştırma. Traffic Manager, her bölgenin kullanılabilirliğini izlemek için HTTP (veya HTTPS) yoklamasını kullanır. Yoklama, belirtilen bir URL yolu için bir HTTP 200 yanıtının alınıp alınmadığını denetler. En iyi uygulama olarak, uygulamanın genel durumunu raporlayan bir uç nokta oluşturun ve durum yoklaması için bu uç noktayı kullanın. Aksi takdirde, gerçekte uygulamanın kritik bölümleri başarısız olduğu halde araştırma uç noktanın sistem durumunun iyi olduğunu raporlayabilir. Daha fazla bilgi için bkz . Sistem Durumu Uç Noktası İzleme düzeni.
Traffic Manager yük devredildiğinde, istemcilerin uygulamaya erişemediği bir süre vardır. Bu süre aşağıdaki faktörlerden etkilenir:
- Durum yoklaması, birincil bölgenin ulaşılamaz hale geldiğini algılamalıdır.
- DNS sunucuları, önbelleğe alınan DNS kayıtlarını IP adresi için güncelleştirmelidir; bu, DNS yaşam süresine (TTL) bağlıdır. Varsayılan TTL 300 saniyedir (5 dakika), ancak Traffic Manager profilini oluştururken bu değeri yapılandırabilirsiniz.
Ayrıntılar için bkz. Traffic Manager İzleme Hakkında.
Traffic Manager yük devrederse, otomatik bir yeniden çalışma uygulamak yerine el ile bir yeniden çalışma gerçekleştirmenizi öneririz. Aksi takdirde, uygulamanın bölgeler arasında sürekli olarak geçiş yaptığı bir durum oluşturabilirsiniz. Yeniden çalıştırmadan önce tüm uygulama alt sistemlerinin iyi durumda olduğunu doğrulayın.
Traffic Manager varsayılan olarak otomatik olarak yeniden başarısız olur. Bu sorunu önlemek için yük devretme olayından sonra birincil bölgenin önceliğini el ile düşürebilirsiniz. Örneğin, birincil bölge öncelik 1 ve ikincil bölge öncelik 2 değerine sahip olsun. Bir yük devretmeden sonra, otomatik yeniden çalışmayı önlemek için birincil bölgenin önceliğini 3 olarak ayarlayın. Geri dönmeye hazır olduğunuzda önceliği 1 olarak güncelleştirin.
Şu Azure CLI komutu, önceliği güncelleştirir:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --priority 3
Bir diğer yaklaşım da yeniden çalışmaya hazır olana kadar uç noktayı geçici olarak devre dışı bırakmaktır:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --endpoint-status Disabled
Yük devretme nedenine bağlı olarak, bir bölgede kaynakları yeniden dağıtmanız gerekebilir. İlk duruma döndürmeden önce bir işlemsel hazırlık testi gerçekleştirin. Test aşağıdaki gibi durumları doğrulamalıdır:
- VM’lerin doğru şekilde yapılandırılmış olması. (Gerekli olan tüm yazılımların yüklenmiş olması, IIS’nin çalışıyor olması vb.)
- Uygulama alt sistemlerinin iyi durumda olması.
- İşlevsel test. (Örneğin, web katmanından veritabanı katmanına ulaşılabilmesi.)
SQL Server Always On Kullanılabilirlik Grupları yapılandırma
Windows Server 2016’dan önceki sürümlerde SQL Server Always On Kullanılabilirlik Grupları bir etki alanı denetleyicisi gerektirir ve kullanılabilirlik grubundaki tüm düğümler aynı Active Directory (AD) etki alanında olmalıdır.
Kullanılabilirlik grubunu yapılandırmak için:
Her bir bölgeye en az iki etki alanı denetleyicisi yerleştirin.
Her etki alanı denetleyicisine statik bir IP adresi verin.
aralarında iletişim sağlamak için iki sanal ağı eşleyin.
Her sanal ağ için, etki alanı denetleyicilerinin (her iki bölgeden de) IP adreslerini DNS sunucusu listesine ekleyin. Aşağıdaki CLI komutunu kullanabilirsiniz. Daha fazla bilgi için bkz . DNS sunucularını değiştirme.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Her iki bölgedeki SQL Server örneklerini içeren bir Windows Server Yük Devretme Kümelemesi (WSFC) oluşturun.
Hem birincil hem de ikincil bölgedeki SQL Server örneklerini içeren bir SQL Server Always On Kullanılabilirlik Grubu oluşturun. Adımlar için bkz. Always On Kullanılabilirlik Grubu’nu Uzak Azure Veri Merkezine Genişletme (PowerShell).
Birincil çoğaltmayı birincil bölgeye yerleştirin.
Birincil bölgeye bir veya daha fazla ikincil çoğaltma yerleştirin. Bu çoğaltmaları otomatik yük devretme ile zaman uyumlu işleme kullanacak şekilde yapılandırın.
İkincil bölgeye bir veya daha fazla ikincil çoğaltma yerleştirin. Bu çoğaltmaları, performans nedeniyle zaman uyumsuz işleme kullanacak şekilde yapılandırın. (Aksi takdirde, tüm T-SQL işlemlerinin ağ üzerinden ikincil bölgeye gidiş dönüş için beklemesi gerekir.)
Dekont
Zaman uyumsuz işleme çoğaltmaları otomatik yük devretmeyi desteklemez.
Dikkat edilmesi gereken noktalar
Bu önemli noktalar, bir iş yükünün kalitesini artırmak için kullanılabilecek bir dizi yol gösteren ilke olan Azure İyi Tasarlanmış Çerçeve'nin yapı taşlarını uygular. Daha fazla bilgi için bkz . Microsoft Azure İyi Tasarlanmış Çerçeve.
Kullanılabilirlik
Karmaşık N katmanlı bir uygulama ile ikincil bölgede tüm uygulamayı çoğaltmanız gerekmeyebilir. Bunun yerine, yalnızca iş sürekliliğinin desteklenmesi için gerekli önemli bir alt sistemi çoğaltabilirsiniz.
Traffic Manager sistemde olası bir hata noktasıdır. Traffic Manager hizmeti başarısız olursa, istemciler kapalı kalma süresince uygulamanıza erişemez. Traffic Manager SLA’sını gözden geçirin ve yalnızca Traffic Manager kullanımıyla, yüksek kullanılabilirliğe ilişkin iş gereksinimlerinizin karşılanıp karşılanmadığını belirleyin. Aksi durumda, yeniden çalıştırma çözümü olarak başka bir trafik yönetim çözümü eklemeyi göz önünde bulundurun. Azure Traffic Manager hizmeti başarısız olursa, DNS’teki CNAME kayıtlarınızı diğer trafik yönetimi hizmetini gösterecek şekilde değiştirin. (Bu adımın el ile uygulanması gerekir ve uygulamanız DNS değişiklikleri yayılana kadar kullanılamaz.)
SQL Server kümesi için dikkate alınması gereken iki yük devretme senaryosu vardır:
Birincil bölgedeki tüm SQL Server veritabanı çoğaltmalarının başarısız olması. Örneğin, bu hata bölgesel bir kesinti sırasında oluşabilir. Bu durumda, Traffic Manager otomatik olarak ön uçta yük devretme gerçekleştirse bile kullanılabilirlik grubunun yükünü el ile devretmeniz gerekir. SQL Server 2016’da SQL Server Management Studio, Transact-SQL veya PowerShell kullanarak zorlamalı yük devretme gerçekleştirmeyi açıklayan SQL Server Kullanılabilirlik Grubunun Yükünü El ile Zorlamalı Olarak Devretme İşlemi Gerçekleştirme konusundaki adımları izleyin.
Uyarı
Zorlamalı yük devretme ile veri kaybı riski vardır. Birincil bölge yeniden çevrimiçi olduğunda, veritabanının anlık görüntüsünü alın ve farkları bulmak için tablediff’i kullanın.
Traffic Manager ikincil bölgeye yük devretme gerçekleştirir, ancak birincil SQL Server veritabanı çoğaltması kullanılabilir kalır. Örneğin, ön uç katmanı SQL Server sanal makinelerini etkilemeden başarısız olabilir. Bu durumda, İnternet trafiği ikincil bölgeye yönlendirilir ve bu bölge birincil çoğaltmaya bağlanmaya devam edebilir. Ancak, SQL Server bağlantıları bölgeler arasında gerçekleştiğinden gecikme süresi daha yüksek olur. Bu durumda, aşağıdaki gibi el ile yük devretme gerçekleştirmeniz gerekir:
- İkincil bölgedeki bir SQL Server veritabanı çoğaltmasını geçici olarak zaman uyumlu işlemeye geçirin. Bu adım, yük devretme sırasında veri kaybı olmamasını sağlar.
- Bu çoğaltmaya yük devretme gerçekleştirin.
- Birincil bölgede yeniden çalışmaya başladığınızda zaman uyumsuz işleme ayarını geri yükleyin.
Yönetilebilirlik
Dağıtımınızı güncelleştirdiğinizde, yanlış bir yapılandırma veya uygulamadaki bir hata nedeniyle ortaya çıkabilecek genel hata riskini azaltmak için tek seferde bir uygulamayı güncelleştirin.
Sistemin hatalara karşı esnekliğini test edin. Test edebileceğiniz bazı yaygın hata senaryoları şunlardır:
- VM örneklerini kapatın.
- CPU ve bellek gibi baskı kaynakları.
- Ağın bağlantısını kesin/ağı geciktirin.
- İşlemlerde kilitlenme yaratın.
- Sertifikaların süresinin dolmasını sağlayın.
- Donanım hatalarının benzetimini yapın.
- Etki alanı denetleyicilerindeki DNS hizmetini kapatın.
Kurtarma zamanlarını ölçün ve iş gereksinimlerinizin karşılandığını doğrulayın. Hata modlarının birleşimlerini de test edin.
Maliyet iyileştirme
Maliyet iyileştirmesi, gereksiz giderleri azaltmanın ve operasyonel verimlilikleri iyileştirmenin yollarını aramaktır. Daha fazla bilgi için bkz . Maliyet iyileştirme sütununa genel bakış.
Maliyetleri tahmin etmek için Azure Fiyatlandırma Hesaplayıcısı'nı kullanın. Burada dikkat edilmesi gereken diğer bazı noktalar bulunmaktadır.
Sanal Makine Ölçek Kümeleri
Sanal Makine Ölçek Kümeleri tüm Windows VM boyutlarında kullanılabilir. Yalnızca dağıttığınız Azure VM'leri ve depolama ve ağ gibi tüketilen tüm ek altyapı kaynakları için ücretlendirilirsiniz. Sanal Makine Ölçek Kümeleri hizmeti için artımlı ücret alınmaz.
Tek VM fiyatlandırma seçenekleri için bkz . Windows VM fiyatlandırması.
SQL Server
Azure SQL DBaas'ı seçerseniz Her Zaman Açık Kullanılabilirlik Grubu ve etki alanı denetleyicisi makineleri yapılandırmanız gerekmeyen maliyetten tasarruf edebilirsiniz. Tek veritabanından yönetilen örneğe veya elastik havuzlara kadar çeşitli dağıtım seçenekleri vardır. Daha fazla bilgi için bkz . Azure SQL fiyatlandırması.
SQL Server VM'leri fiyatlandırma seçenekleri için bkz . SQL VM fiyatlandırması.
Yük dengeleyiciler
Yalnızca yapılandırılmış yük dengeleme ve giden kuralları için ücretlendirilirsiniz. Gelen NAT kuralları ücretsizdir. Kural yapılandırılmadığında Standart Load Balancer için saatlik ücret alınmaz.
Traffic Manager fiyatlandırması
Traffic Manager alınan DNS sorgusu sayısı üzerinden faturalandırılır ve ayda 1 milyardan fazla DNS sorgusu alan hizmetlere indirim uygulanır. ayrıca izlenen her uç nokta için ücretlendirilirsiniz.
Daha fazla bilgi için Microsoft Azure İyi Oluşturulmuş Mimari Çerçevesi makalesindeki maliyet bölümüne bakın.
VNET Eşleme fiyatlandırması
Birden çok Azure Bölgesi kullanan yüksek kullanılabilirlik dağıtımı, sanal ağ eşlemesini kullanır. Aynı bölge içindeki sanal ağ eşlemesi ve Genel VNET Eşlemesi için farklı ücretler vardır.
Daha fazla bilgi için bkz. fiyatlandırma Sanal Ağ.
DevOps
Azure kaynaklarını ve bağımlılıklarını sağlamak için tek bir Azure Resource Manager şablonu kullanın. Kaynakları hem birincil hem de ikincil bölgelere dağıtmak için aynı şablonu kullanın. Aynı temel iş yükünde yalıtılmış olmaları için tüm kaynakları aynı sanal ağa ekleyin. Tüm kaynakları dahil ederek, iş yükünün belirli kaynaklarını bir DevOps ekibiyle ilişkilendirmeyi kolaylaştırırsınız, böylece ekip bu kaynakların tüm yönlerini bağımsız olarak yönetebilir. Bu yalıtım, DevOps Ekip ve Hizmetlerinin sürekli tümleştirme ve sürekli teslim (CI/CD) gerçekleştirmesini sağlar.
Ayrıca, farklı Azure Resource Manager şablonlarını kullanabilir ve bunları Azure DevOps Services ile tümleştirerek dakikalar içinde farklı ortamlar sağlayabilirsiniz. Örneğin, senaryolar veya yük testi ortamları gibi üretim ortamlarını yalnızca gerektiğinde çoğaltarak maliyet tasarrufu sağlayabilirsiniz.
Altyapınızın performansını analiz etmek ve iyileştirmek, sanal makinelerinizde oturum açmadan ağ sorunlarını izlemek ve tanılamak için Azure İzleyici'yi kullanmayı göz önünde bulundurun. Uygulama Analizler aslında Azure İzleyici'nin bileşenlerinden biridir ve tam Azure ortamınızın durumunu doğrulamak için size zengin ölçümler ve günlükler sağlar. Azure İzleyici, altyapınızın durumunu izlemenize yardımcı olur.
Bir uygulamanın veri katmanının düşük performansı ciddi sonuçlara neden olabileceğinden, yalnızca uygulama kodunuzu destekleyen işlem öğelerinizi değil veri platformunuzu da , özellikle de veritabanlarınızı izlediğinizden emin olun.
Uygulamaların çalıştığı Azure ortamını test etmek için, uygulama koduyla aynı mekanizmalar aracılığıyla sürüm denetimi yapılıp dağıtılmalıdır, ardından DevOps test paradigmaları kullanılarak test edilebilir ve doğrulanabilir.
Daha fazla bilgi için Microsoft Azure İyi Tasarlanmış Çerçeve'deki Operasyonel Mükemmellik bölümüne bakın.
Katkıda Bulunanlar
Bu makale Microsoft tarafından yönetilir. Başlangıçta aşağıdaki katkıda bulunanlar tarafından yazılmıştır.
Asıl yazar:
- Donnie Trumpower | Üst Düzey Bulut Çözümü Mimarı
Genel olmayan LinkedIn profillerini görmek için LinkedIn'de oturum açın.
Sonraki adımlar
İlgili kaynaklar
Aşağıdaki mimaride aynı teknolojilerden bazıları kullanılır: