Azure Cosmos DB ile sosyal çalışma
ŞUNLAR IÇIN GEÇERLIDIR: ![]() Nosql
Nosql ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tablo
Tablo
Büyük ölçüde birbirine bağlı bir toplumda yaşamak, yaşamın bir noktasında bir sosyal ağın parçası olduğunuz anlamına gelir. Sosyal ağları arkadaşlarınızla, iş arkadaşlarınızla, ailenizle iletişim halinde olmak veya bazen tutkunuzu ortak ilgi alanları olan kişilerle paylaşmak için kullanırsınız.
Mühendisler veya geliştiriciler olarak bu ağların verilerinizi nasıl depolayıp birbirine bağlayabileceğini merak ediyor olabilirsiniz. Hatta belirli bir niş pazar için yeni bir sosyal ağ oluşturma veya mimari oluşturma görevi bile almış olabilirsiniz. İşte bu noktada önemli bir soru ortaya çıkıyor: Tüm bu veriler nasıl depolanıyor?
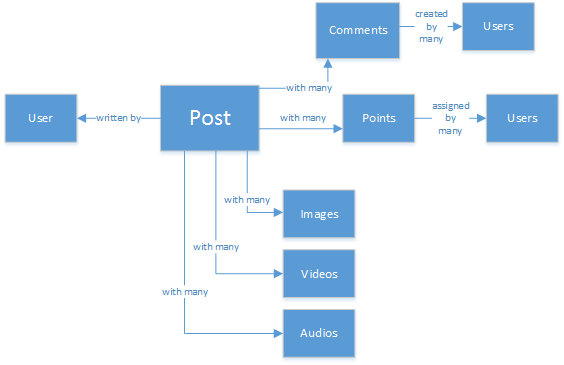
Kullanıcılarınızın resimler, videolar ve hatta müzikler gibi ilgili medyalarla makale gönderebileceği yeni ve parlak bir sosyal ağ oluşturduğunuzu varsayalım. Kullanıcılar gönderilere yorum yapabilir ve derecelendirmeler için puan verebilir. Kullanıcıların ana web sitesi giriş sayfasında göreceği ve etkileşim kuracağı bir gönderi akışı olacaktır. Bu yöntem ilk başta karmaşık görünmüyor, ancak kolaylık sağlamak için orada duralım. (İlişkilerden etkilenen özel kullanıcı akışlarını inceleyebilirsiniz, ancak bu makalenin amacının ötesine geçer.)
Peki, bu verileri nasıl ve nerede depolursunuz?
SQL veritabanlarında deneyim sahibi olabilirsiniz veya verilerin ilişkisel modellemesi hakkında bir fikrimiz olabilir. Aşağıdaki gibi bir şey çizmeye başlayabilirsiniz:
Mükemmel şekilde normalleştirilmiş ve güzel bir veri yapısı... bu ölçeklendirilmiyor.
Yanlış anlamadım, hayatım boyunca SQL veritabanlarıyla çalıştım. Harikalar, ancak her desen, uygulama ve yazılım platformu gibi her senaryo için mükemmel değildir.
Sql neden bu senaryoda en iyi seçenek değil? Şimdi tek bir gönderinin yapısına bakalım. Gönderiyi bir web sitesinde veya uygulamada göstermek isteseydim,... yalnızca tek bir gönderi göstermek için sekiz tabloyu birleştirerek(!) Şimdi dinamik olarak yüklenen ve ekranda görünen bir gönderi akışı çizdiğinizde nereye gittiğimi görebilirsiniz.
İçeriğinizi sunmak için birçok birleşimle binlerce sorgu çözmek için yeterli güce sahip muazzam bir SQL örneği kullanabilirsiniz. Ama neden daha basit bir çözüm varken?
NoSQL yolu
Bu makale, Azure'ın NoSQL veritabanı Azure Cosmos DB ile sosyal platformunuzun verilerini uygun maliyetli bir şekilde modelleme konusunda size yol gösterir. Ayrıca Gremlin için API gibi diğer Azure Cosmos DB özelliklerini nasıl kullanacağınızı da bildirir. NoSQL yaklaşımını kullanarak, verileri JSON biçiminde depolayarak ve normal olmayanlaştırma uygulayarak, daha önce karmaşık olan gönderi tek bir Belgeye dönüştürülebilir:
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
Tek bir sorguyla ve birleştirme olmadan elde edilebilir. Bu sorgu çok basit ve basittir ve bütçe açısından daha iyi bir sonuç elde etmek için daha az kaynak gerektirir.
Azure Cosmos DB, tüm özelliklerin otomatik dizin oluşturma özelliğiyle dizine yazıldığından emin olur. Otomatik dizin oluşturma bile özelleştirilebilir. Şemasız yaklaşım, farklı ve dinamik yapılara sahip belgeleri depolamamıza olanak tanır. Belki yarın gönderilerin kendileriyle ilişkilendirilmiş kategorilerin veya hashtag'lerin listesinin olmasını istersiniz? Azure Cosmos DB, ek iş gerekmeden eklenen özniteliklerle yeni Belgeleri işler.
Bir gönderideki açıklamalar, üst özelliği olan diğer gönderiler olarak ele alınabilir. (Bu uygulama nesne eşlemenizi basitleştirir.)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
Ayrıca tüm sosyal etkileşimler sayaç olarak ayrı bir nesnede depolanabilir:
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
Akış oluşturmak, belirli bir ilgi sırasına sahip posta kimliklerinin listesini tutabilen belgeler oluşturmaktır:
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
Oluşturma tarihine göre sıralanmış gönderiler içeren bir "en son" akışınız olabilir. Ya da son 24 saat içinde daha fazla beğeni içeren bu gönderilerle "en sıcak" akışınız olabilir. Takipçiler ve ilgi alanları gibi mantık temelinde her kullanıcı için özel bir akış bile uygulayabilirsiniz. Yine de gönderilerin listesi olacaktır. Bu listelerin nasıl derlendiği önemlidir, ancak okuma performansı engelsiz kalır. Bu listelerden birini aldıktan sonra, aynı anda gönderi sayfalarını almak için IN anahtar sözcüğünü kullanarak Azure Cosmos DB'ye tek bir sorgu gönderebilirsiniz.
Akış akışları, Azure Uygulaması Hizmetleri'nin arka plan işlemleri kullanılarak oluşturulabilir: Web işleri. Bir gönderi oluşturulduktan sonra arka plan işleme, Azure Webjobs SDK'sı kullanılarak tetiklenen Azure Depolama Queues ve Web işleri kullanılarak tetiklenebilir ve akışlar içinde kendi özel mantığınıza göre yayın sonrası uygulanabilir.
Bir gönderideki puanlar ve beğeniler, nihai tutarlı bir ortam oluşturmak için aynı teknik kullanılarak ertelenmiş bir şekilde işlenebilir.
Takipçiler daha karmaşıktır. Azure Cosmos DB'nin belge boyutu sınırı vardır ve büyük belgeleri okumak/yazmak uygulamanızın ölçeklenebilirliğini etkileyebilir. Bu nedenle takipçileri bu yapıya sahip bir belge olarak depolamayı düşünebilirsiniz:
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
Bu yapı, birkaç bin takipçisi olan bir kullanıcı için işe yarayabilir. Ancak bazı ünlüler derecelere katılırsa, bu yaklaşım büyük bir belge boyutuna yol açar ve sonunda belge boyutu üst sınırına ulaşabilir.
Bu sorunu çözmek için karma bir yaklaşım kullanabilirsiniz. Kullanıcı İstatistikleri belgesinin bir parçası olarak takipçi sayısını depolayabilirsiniz:
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
Gremlin için Azure Cosmos DB API'sini kullanarak gerçek takipçi grafını depolayarak her kullanıcı ve kenar için "A-follows-B" ilişkilerini koruyan köşeler oluşturabilirsiniz. Gremlin API'siyle belirli bir kullanıcının takipçilerini alabilir ve ortak kişiler önermek için daha karmaşık sorgular oluşturabilirsiniz. Grafiğe insanların beğenebileceği veya beğenebileceği İçerik Kategorilerini eklerseniz, akıllı içerik bulma, takip ettiğiniz kişilere içerik önerme veya çok ortak olabileceğiniz kişileri bulma gibi deneyimler eklemeye başlayabilirsiniz.
Kullanıcı İstatistikleri belgesi, kullanıcı arabiriminde veya hızlı profil önizlemelerinde kart oluşturmak için kullanılabilir.
"Ladder" deseni ve veri yinelemesi
Bir gönderiye başvuran JSON belgesinde fark etmiş olabileceğiniz gibi, kullanıcının birçok tekrarı vardır. Ve doğru tahmin etmişsinizdir, bu yinelenenler, bu normal dışılaştırma göz önünde bulundurulduğunda bir kullanıcıyı tanımlayan bilgilerin birden fazla yerde bulunabileceği anlamına gelir.
Daha hızlı sorgulara izin vermek için veri yineleme işlemine tabi olursunuz. Bu yan etkinin sorunu, bir eylemle kullanıcının verileri değişirse kullanıcının yaptığı tüm etkinlikleri bulmanız ve tümünü güncelleştirmeniz gerektiğidir. Kulağa pratik gelmiyor, değil mi?
Her etkinlik için uygulamanızda gösterdiğiniz bir kullanıcının temel özniteliklerini belirleyerek bu sorunu çözeceksiniz. Uygulamanızda görsel olarak bir gönderi gösteriyor ve yalnızca oluşturucunun adını ve resmini gösteriyorsanız, neden kullanıcının tüm verilerini "createdBy" özniteliğinde depolayasınız? Her açıklama için yalnızca kullanıcının resmini gösterirseniz, kullanıcının diğer bilgilerine gerçekten ihtiyacınız yoktur. "Merdiven deseni" diye adlandırdığım bir şey işte burada devreye girdi.
Örnek olarak kullanıcı bilgilerini ele alalım:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
Bu bilgilere bakarak, hangilerinin kritik bilgi olduğunu ve hangilerinin olmadığını hızla algılayabilir, böylece bir "Merdiven" oluşturabilirsiniz:

En küçük adım UserChunk olarak adlandırılır. Bu adım, kullanıcıyı tanımlayan ve veri yinelemesi için kullanılan en küçük bilgi parçasıdır. Yinelenen veri boyutunu yalnızca "göstereceğiniz" bilgilere küçülterek çok büyük güncelleştirmeler olasılığını azaltmış olursunuz.
Orta adım kullanıcı olarak adlandırılır. En çok erişilen ve kritik olan Azure Cosmos DB'de performansa bağımlı sorguların çoğunda kullanılacak olan tam verilerdir. UserChunk tarafından temsil edilen bilgileri içerir.
En büyük olan Genişletilmiş Kullanıcı'dır. Kritik kullanıcı bilgilerini ve hızlı bir şekilde okunması gerekmeyen veya oturum açma işlemi gibi nihai kullanımı olan diğer verileri içerir. Bu veriler Azure Cosmos DB dışında, Azure SQL Veritabanı veya Azure Depolama Tablolarında depolanabilir.
Neden kullanıcıyı böler ve hatta bu bilgileri farklı yerlerde depolarsınız? Çünkü performans açısından belgeler ne kadar büyükse sorgular o kadar maliyetli olur. Sosyal ağınız için performansa bağımlı tüm sorgularınızı yapmak için doğru bilgilerle belgeleri ince tutun. Kullanım analizi ve Büyük Veri girişimleri için tam profil düzenlemeleri, oturum açma bilgileri ve veri madenciliği gibi nihai senaryolar için diğer ek bilgileri depolayın. Veri madenciliği için veri toplama işlemi Azure SQL Veritabanı üzerinde çalıştığından veri toplama işleminin daha yavaş olup olmadığı sizin için önemli değildir. Kullanıcılarınızın hızlı ve ince bir deneyime sahip olduğu konusunda endişeleriniz var. Azure Cosmos DB'de depolanan bir kullanıcı şu koda benzer olacaktır:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
Bir Gönderi de şöyle görünür:
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
Öbek özniteliğinin etkilendiği bir düzenleme gerçekleştiğinde, etkilenen belgeleri kolayca bulabilirsiniz. Gibi SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id"dizine alınan özniteliklere işaret eden sorguları kullanın ve sonra öbekleri güncelleştirin.
Arama kutusu
Kullanıcılar neyse ki çok fazla içerik oluşturacak. Ayrıca içerik akışlarında doğrudan bulunamayabilecek içerikleri arama ve bulma olanağı sağlayabilmeniz gerekir. Bunun nedeni içerik oluşturucuları takip etmeyebilmeniz veya altı ay önce yaptığınız eski gönderiyi bulmaya çalışmanız olabilir.
Azure Cosmos DB kullandığınızdan, arama işlemi ve kullanıcı arabirimi dışında kod yazmadan birkaç dakika içinde Azure AI Search kullanarak kolayca bir arama altyapısı uygulayabilirsiniz.
Bu işlem neden bu kadar kolay?
Azure AI Search dizin oluşturucuları olarak adlandırdıkları şeyi, veri depolarınıza takılan ve dizinlerdeki nesnelerinizi otomatik olarak ekleyen, güncelleştiren veya kaldıran arka plan işlemlerini uygular. Azure SQL Veritabanı dizin oluşturucularını, Azure Blob dizin oluşturucularını ve neyse ki Azure Cosmos DB dizin oluşturucularını destekler. Bilgilerin Azure Cosmos DB'den Azure AI Search'e geçişi basittir. Her iki teknoloji de bilgileri JSON biçiminde depolar, bu nedenle dizininizi oluşturmanız ve dizine eklemek istediğiniz Belgelerinizdeki öznitelikleri eşlemeniz yeterlidir. İşlem tamamlanır. Verilerinizin boyutuna bağlı olarak, tüm içeriğiniz bulut altyapısındaki en iyi Hizmet Olarak Ara çözümü tarafından dakikalar içinde aranabilecektir.
Azure AI Search hakkında daha fazla bilgi için Hitchhiker'ın Arama Kılavuzu'nu ziyaret edebilirsiniz.
Temel alınan bilgiler
Her gün büyüyen ve büyüyen tüm bu içeriği depoladıktan sonra şunu düşünebilirsiniz: Kullanıcılarımdan gelen tüm bu bilgi akışıyla ne yapabilirim?
Yanıt oldukça basittir: Bunu çalışır duruma getir ve bundan ders çıkar.
Ama ne öğrenebilirsin ki? Yaklaşım analizi, kullanıcının tercihlerine dayalı içerik önerileri ve hatta sosyal ağınız tarafından yayımlanan içeriğin aile için güvenli olmasını sağlayan otomatik bir con çadır modu rator gibi birkaç kolay örnek verilebilir.
Şimdi seni bağladığıma göre, muhtemelen matematik biliminde bu desenleri ve bilgileri basit veritabanlarından ve dosyalardan ayıklamak için doktoraya ihtiyacın olduğunu düşüneceksin, ama yanılıyorsun.
Azure Machine Learning, basit bir sürükle ve bırak arabirimindeki algoritmaları kullanarak iş akışları oluşturmanıza, R'de kendi algoritmalarınızı kodlayarak veya Metin Analizi, Content Moderator veya Öneriler gibi önceden oluşturulmuş ve kullanıma hazır API'lerden bazılarını kullanmanıza olanak tanıyan, tam olarak yönetilen bir bulut hizmetidir.
Bu Machine Learning senaryolarından herhangi birini başarmak için Azure Data Lake'i kullanarak farklı kaynaklardan bilgi alabilirsiniz. Ayrıca bilgileri işlemek ve Azure Machine Learning tarafından işlenebilen bir çıkış oluşturmak için U-SQL kullanabilirsiniz.
Diğer bir seçenek de kullanıcılarınızın içeriğini analiz etmek için Azure AI hizmetlerini kullanmaktır; bunları daha iyi anlamakla kalmaz (Metin Analizi API ile yazdıklarını analiz ederek) aynı zamanda istenmeyen veya olgun içeriği algılayabilir ve Görüntü İşleme API'si ile uygun şekilde işlem yapabilirsiniz. Azure yapay zeka hizmetleri, kullanmak için herhangi bir Makine Öğrenmesi bilgisi gerektirmeyen kullanıma sunulan birçok çözüm içerir.
Gezegen ölçeğinde bir sosyal deneyim
Son, ancak önemli bir makaleye değinmeliyim: ölçeklenebilirlik. Bir mimari tasarlarken, her bileşenin kendi başına ölçeklendirilmesi gerekir. Sonunda daha fazla veri işlemeniz gerekecek veya daha büyük bir coğrafi kapsama sahip olmak isteyeceksiniz. Neyse ki her iki görevi de başarmak Azure Cosmos DB ile anahtar teslimi bir deneyimdir .
Azure Cosmos DB, dinamik bölümlendirmeyi kullanıma açık olarak destekler. Belgelerinizde öznitelik olarak tanımlanan belirli bir bölüm anahtarını temel alan bölümleri otomatik olarak oluşturur. Doğru bölüm anahtarını tanımlama işlemi tasarım zamanında yapılmalıdır. Daha fazla bilgi için bkz . Azure Cosmos DB'de bölümleme.
Sosyal bir deneyim için bölümleme stratejinizi sorgulama ve yazma yönteminizle uyumlu hale getirmeniz gerekir. (Örneğin, aynı bölümdeki okumalar istenir ve yazmaları birden çok bölüme yayarak "sık erişimli noktalardan" kaçının.) Bazı seçenekler şunlardır: zamana bağlı anahtara (gün/ay/hafta), içerik kategorisine, coğrafi bölgeye veya kullanıcıya göre bölümler. Her şey, verileri nasıl sorguladığınıza ve sosyal deneyiminizde verileri nasıl göstereceğinize bağlıdır.
Azure Cosmos DB tüm bölümlerinizde sorgularınızı (toplamlar dahil) saydam bir şekilde çalıştırır, bu nedenle verileriniz büyüdükçe herhangi bir mantık eklemeniz gerekmez.
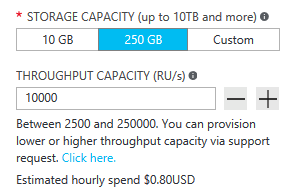
Zamanla trafikte büyüyeceksiniz ve kaynak tüketiminiz (RU'larla veya İstek Birimleriyle ölçülür) artacaktır. Kullanıcı tabanınız büyüdükçe daha sık okuyup yazacaksınız. Kullanıcı tabanı daha fazla içerik oluşturmaya ve okumaya başlar. Bu nedenle aktarım hızınızı ölçeklendirme özelliği çok önemlidir. RU'larınızı artırmak kolaydır. Azure portalında birkaç tıklamayla veya API aracılığıyla komutlar vererek bunu yapabilirsiniz.
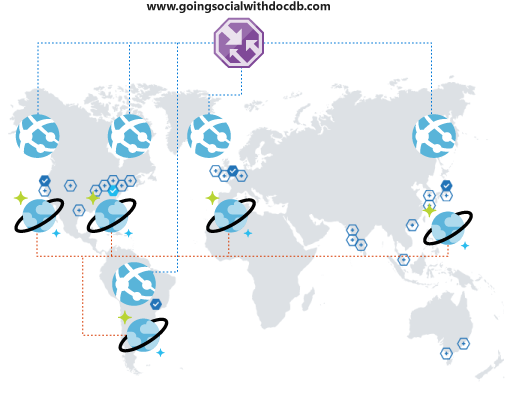
İşler daha iyiye giderse ne olur? Başka bir ülkeden/bölgeden veya kıtadan kullanıcıların platformunuzu fark edip kullanmaya başladığını varsayalım. Ne harika bir sürpriz!
Ama bekleyin! Kısa süre içinde platformunuzla ilgili deneyimlerinin en uygun olmadığını fark ediyorsunuz. İşletim bölgenizden o kadar uzaktalar ki gecikme süresi çok kötü. Belli ki bırakmalarını istemiyorsun. Küresel erişiminizi genişletmenin kolay bir yolu olsaydı? Var!
Azure Cosmos DB, birkaç tıklamayla verilerinizi genel ve şeffaf bir şekilde çoğaltmanıza ve istemci kodunuzdaki kullanılabilir bölgeler arasından otomatik olarak seçim yapmanıza olanak tanır. Bu işlem, birden çok yük devretme bölgesine sahip olabileceğiniz anlamına da gelir.
Verilerinizi genel olarak çoğalttığınızda, müşterilerinizin bu verilerden yararlanadığından emin olmanız gerekir. Web ön ucu kullanıyorsanız veya mobil istemcilerden API'lere erişiyorsanız, Genişletilmiş genel kapsamınızı desteklemek için bir performans yapılandırması kullanarak Azure Traffic Manager'ı dağıtabilir ve Azure Uygulaması Hizmetinizi istediğiniz tüm bölgelere kopyalayabilirsiniz. İstemcileriniz ön ucunuza veya API'lerinize eriştiğinde en yakın App Service'e yönlendirilir ve bu da yerel Azure Cosmos DB çoğaltmasına bağlanır.
Sonuç
Bu makale, düşük maliyetli hizmetlerle tamamen Azure'da sosyal ağ oluşturma alternatiflerine biraz ışık tutar. çok katmanlı depolama çözümünün ve "Ladder" adlı veri dağıtımının kullanımını teşvik ederek sonuçlar sunar.
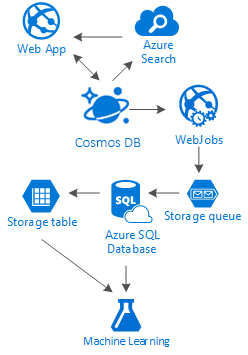
Gerçek şu ki, bu tür senaryolar için gümüş madde işareti yoktur. Harika deneyimler oluşturmamıza olanak sağlayan harika hizmetlerin birleşimiyle oluşturulan sinerjidir: Azure Cosmos DB'nin harika bir sosyal uygulama sağlama hızı ve özgürlüğü, Azure AI Search gibi birinci sınıf bir arama çözümünün arkasındaki zeka, Azure Uygulaması Hizmetleri'nin dilden bağımsız uygulamaları değil, güçlü arka plan süreçlerini barındırma esnekliği ve genişletilebilir Azure Depolama ve Azure SQL Veritabanı süreçlerinize geri bildirim sağlayabilecek ve doğru kullanıcılara doğru içeriği sunmamıza yardımcı olabilecek bilgi ve zeka oluşturmak için çok büyük miktarlarda veri depolamak ve Azure Machine Learning'in analiz gücü.
Sonraki adımlar
Azure Cosmos DB kullanım örnekleri hakkında daha fazla bilgi edinmek için bkz . Yaygın Azure Cosmos DB kullanım örnekleri.