Kopyalama etkinliği performansı sorunlarını giderme
UYGULANANLAR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Bahşiş
Kuruluşlar için hepsi bir arada analiz çözümü olan Microsoft Fabric'te Data Factory'yi deneyin. Microsoft Fabric , veri taşımadan veri bilimine, gerçek zamanlı analize, iş zekasına ve raporlamaya kadar her şeyi kapsar. Yeni bir deneme sürümünü ücretsiz olarak başlatmayı öğrenin!
Bu makalede, Azure Data Factory'de kopyalama etkinliği performansı sorununun nasıl giderilir açıklanmaktadır.
Kopyalama etkinliğini çalıştırdıktan sonra, kopyalama etkinliği izleme görünümünde çalıştırma sonucunu ve performans istatistiklerini toplayabilirsiniz. Aşağıda bir örnek verilmiştir.
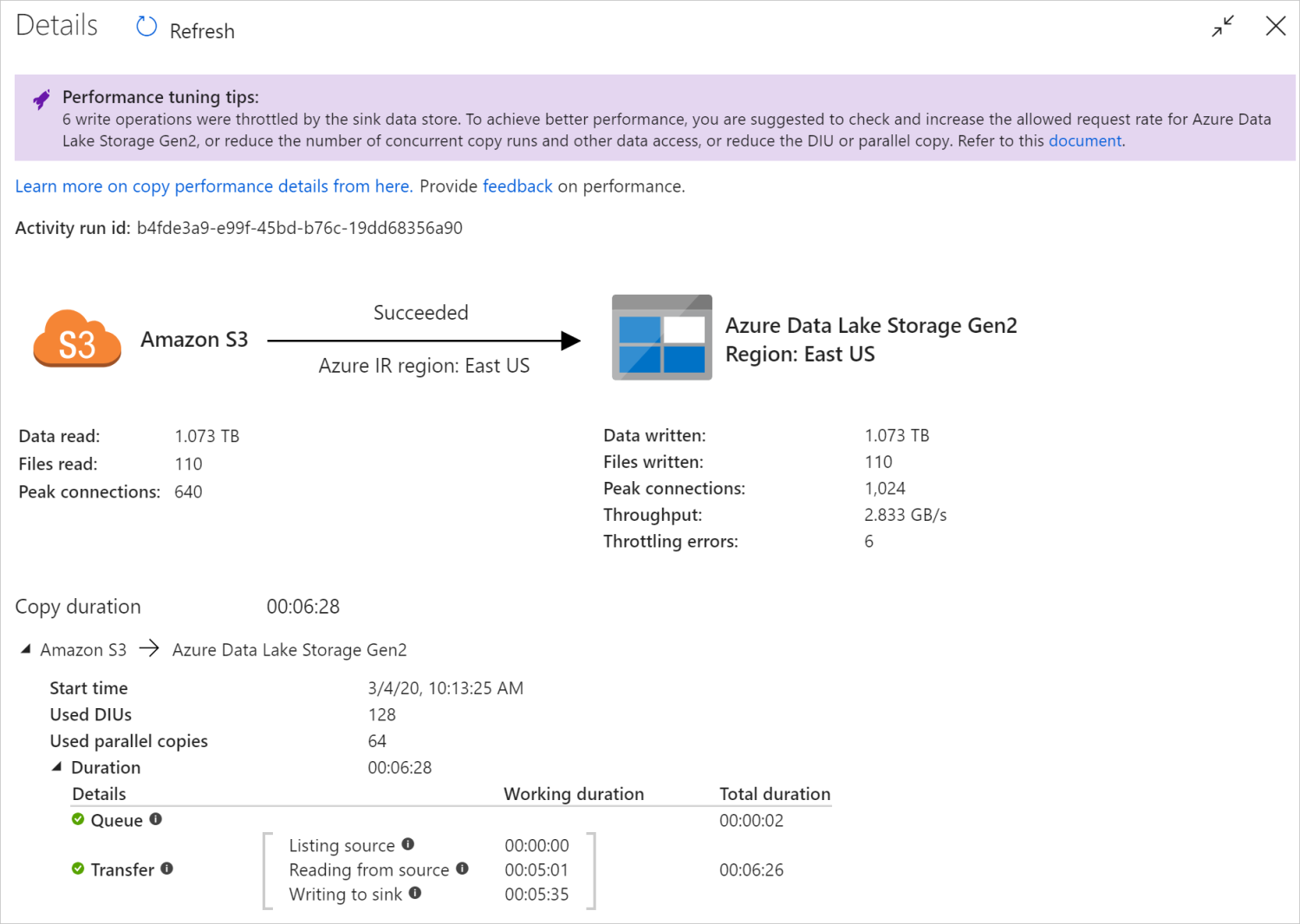
Performans ayarlama ipuçları
Bazı senaryolarda, bir kopyalama etkinliği çalıştırdığınızda, yukarıdaki örnekte gösterildiği gibi en üstte "Performans ayarlama ipuçları" görürsünüz. İpuçları, bu belirli kopyalama çalıştırması için hizmet tarafından tanımlanan performans sorununu ve kopyalama aktarım hızını artırma önerisini gösterir. Önerilen değişikliği yapmayı deneyin, ardından kopyayı yeniden çalıştırın.
Başvuru olarak, şu anda performans ayarlama ipuçları aşağıdaki durumlar için öneriler sağlar:
| Kategori | Performans ayarlama ipuçları |
|---|---|
| Veri deposuna özgü | Azure Synapse Analytics'e veri yükleme: Kullanılmadıysa PolyBase veya COPY deyimini kullanmayı önerin. |
| Verileri Azure SQL Veritabanı/Azure SQL Veritabanı kopyalama: DTU yüksek kullanım altındayken, daha yüksek katmana yükseltmeyi önerin. | |
| Azure Cosmos DB'den/Azure Cosmos DB'ye veri kopyalama: RU yüksek kullanım altındayken daha büyük RU'ya yükseltmeyi önerin. | |
| SAP Tablosundan veri kopyalama: Büyük miktarda veri kopyalarken, paralel yükü etkinleştirmek ve maksimum bölüm sayısını artırmak için SAP bağlayıcısının bölüm seçeneğinden yararlanmayı önerin. | |
| Amazon Redshift'ten veri alma: Kullanılmıyorsa UNLOAD kullanılmasını önerin. | |
| Veri deposu azaltma | Kopyalama sırasında veri deposu tarafından bir dizi okuma/yazma işlemi kısıtlanırsa, veri deposu için izin verilen istek oranını denetlemeyi ve artırmayı veya eşzamanlı iş yükünü azaltmayı önerin. |
| Tümleştirme çalışma zamanı | Şirket İçinde Barındırılan Tümleştirme Çalışma Zamanı (IR) kullanıyorsanız ve kopyalama etkinliği IR yürütülecek kullanılabilir kaynağa sahip olana kadar kuyrukta uzun süre beklerse, IR'nizin ölçeğini genişletmeyi/artırmayı önerin. |
| Okuma/yazmanın yavaş olmasına neden olan, en uygun olmayan bir bölgede yer alan bir Azure Integration Runtime kullanıyorsanız, başka bir bölgede IR kullanmak için yapılandırmayı önerin. | |
| Hataya dayanıklılık | Hataya dayanıklılık yapılandırıp uyumsuz satırların atlanması performansın yavaş olmasına neden olursa kaynak ve havuz verilerinin uyumlu olduğundan emin olunmasını önerin. |
| Aşamalı kopya | Aşamalı kopya yapılandırıldıysa ancak kaynak havuz çiftiniz için yararlı değilse, kaldırmanızı önerin. |
| Sürdür | Kopyalama etkinliği son hata noktasından devam ettirildiğinde ancak özgün çalıştırmadan sonra DIU ayarını değiştirdiğinizde, yeni DIU ayarının etkin olmadığını unutmayın. |
Kopyalama etkinliği yürütme ayrıntılarını anlama
Kopyalama etkinliği izleme görünümünün en altındaki yürütme ayrıntıları ve süreleri, kopyalama etkinliğinizin ilerlediği temel aşamaları açıklar (bu makalenin başındaki örnağa bakın), bu özellikle kopyalama performansı sorunlarını gidermek için kullanışlıdır. Kopyalama çalıştırmanızın performans sorunu, en uzun süreye sahip olandır. Her aşamanın tanımıyla ilgili aşağıdaki tabloya bakın ve Azure IR'de kopyalama etkinliği sorunlarını giderme ve Şirket içinde barındırılan IR'de kopyalama etkinliği sorunlarını giderme hakkında bilgi edinin.
| Aşama | Açıklama |
|---|---|
| Sıra | Kopyalama etkinliği tümleştirme çalışma zamanında gerçekten başlayana kadar geçen süre. |
| Ön kopyalama betiği | IR'de başlayan kopyalama etkinliği ile kopyalama etkinliğinin havuz veri deposunda kopyalama öncesi betiği yürütmesi arasında geçen süre. Veritabanı havuzları için kopyalama öncesi betiği yapılandırırken uygulayın; örneğin, Azure SQL Veritabanı veri yazarken yeni verileri kopyalamadan önce temizleme yapın. |
| Aktarma | Önceki adımın sonu ile tüm verilerin kaynaktan havuza aktarılması arasında geçen süre. Aktarım altındaki alt adımların paralel olarak çalıştığını ve bazı işlemlerin artık gösterilmediğini (örneğin, dosya biçimini ayrıştırma/oluşturma) not edin. - İlk bayt süresi: Önceki adımın sonu ile IR'nin kaynak veri deposundan ilk bayta sahip olduğu süre arasında geçen süre. Dosya tabanlı olmayan kaynaklar için geçerlidir. - Listeleme kaynağı: Kaynak dosyaları veya veri bölümlerini listelemek için harcanan süre. İkincisi, veritabanı kaynakları için bölüm seçeneklerini yapılandırdığınızda (örneğin Oracle/SAP HANA/Teradata/Netezza/ vb. gibi veritabanlarından veri kopyalarken) geçerlidir. -Kaynaktan okuma: Kaynak veri deposundan veri almak için harcanan süre. - Havuza yazma: Havuz veri deposuna veri yazmak için harcanan süre. Azure AI Search, Azure Veri Gezgini, Azure Tablo depolama, Oracle, SQL Server, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce/Salesforce Service Cloud gibi bazı bağlayıcıların şu anda bu ölçüme sahip olmadığını unutmayın. |
Azure IR'de kopyalama etkinliği sorunlarını giderme
Senaryonuz için performans testini planlamak ve yürütmek için Performans ayarlama adımlarını izleyin.
Kopyalama etkinliği performansı beklentilerinizi karşılamadığında, Azure Integration Runtime'da çalışan tek kopya etkinliğinin sorunlarını gidermek için kopyalama izleme görünümünde gösterilen performans ayarlama ipuçlarını görürseniz öneriyi uygulayın ve yeniden deneyin. Aksi takdirde kopyalama etkinliği yürütme ayrıntılarını anlayın, hangi aşamanın en uzun süreye sahip olduğunu denetleyin ve kopyalama performansını artırmak için aşağıdaki kılavuzu uygulayın:
"Ön kopyalama betiği" uzun süre yaşadı: Havuz veritabanında çalışan kopyalama öncesi betiğin tamamlanmasının uzun sürdüğü anlamına gelir. Performansı artırmak için belirtilen kopyalama öncesi betik mantığını ayarlayın. Betiği geliştirme konusunda daha fazla yardıma ihtiyacınız varsa veritabanı ekibinize başvurun.
"Aktarım - İlk bayta kadar olan süre" uzun çalışma süresiyle karşılaşmıştır: Bu, kaynak sorgunuzun veri döndürmesi uzun sürdüğü anlamına gelir. Sorguyu veya sunucuyu denetleyin ve iyileştirin. Daha fazla yardıma ihtiyacınız varsa veri deposu ekibinize başvurun.
"Aktar - Kaynak listeleme" uzun çalışma süresi yaşadı: Kaynak dosyaları veya kaynak veritabanı veri bölümlerini listelemenin yavaş olduğu anlamına gelir.
Dosya tabanlı kaynaktan veri kopyalarken, klasör yolunda veya dosya adında (
wildcardFolderPathveya ) joker karakter filtresi kullanırsanız veya dosya son değiştirme zamanı filtresini (modifiedDatetimeStartveyamodifiedDatetimeEnd) kullanırsanız, bu filtrenin, belirtilen klasör altındaki tüm dosyaların istemci tarafına listelenmesine neden olacağını unutmayın ve ardından filtreyiwildcardFileNameuygulayın. Bu tür dosya numaralandırması, özellikle yalnızca küçük dosya kümesi filtre kuralına uyulduğunda performans sorununa neden olabilir.Dosyaları tarih saat bölümlenmiş dosya yoluna veya adına göre kopyalayıp kopyalayamayacağınızı denetleyin. Bu şekilde kaynak tarafı listeleme yükü getirmez.
Bunun yerine veri deposu yerel filtresini kullanıp kullanamadığını denetleyin; özellikle Amazon S3/Azure Blob storage/Azure Dosyalar için "ön ek" ve ADLS 1. Nesil için "listAfter/listBefore". Bu filtreler veri deposu sunucu tarafı filtresidir ve çok daha iyi performansa sahip olur.
Tek bir büyük veri kümesini birkaç küçük veri kümesine bölmeyi ve bu kopyalama işlerinin verilerin her bir bölümünü eşzamanlı olarak çalıştırmasına izin vermeyi düşünün. Bunu Lookup/GetMetadata + ForEach + Copy ile yapabilirsiniz. Genel örnek olarak, Birden çok kapsayıcıdan dosya kopyalama veya Amazon S3'ten ADLS 2. Nesil çözüm şablonlarına veri geçirme bölümüne bakın.
Hizmetin kaynakta azaltma hatası bildirip bildirmediğini veya veri deponuzun yüksek kullanım durumunda olup olmadığını denetleyin. Bu durumda veri deposundaki iş yüklerinizi azaltın veya azaltma sınırını veya kullanılabilir kaynağı artırmak için veri deposu yöneticinize başvurun.
Azure IR'yi kaynak veri deposu bölgenizle aynı veya yakın konumda kullanın.
"Aktarım - kaynaktan okuma" uzun çalışma süresi yaşadı:
Uygulanıyorsa bağlayıcıya özgü veri yükleme en iyi uygulamasını benimseyin. Örneğin, Amazon Redshift'ten veri kopyalarken Redshift UNLOAD kullanacak şekilde yapılandırın.
Hizmetin kaynakta azaltma hatası bildirip bildirmediğini veya veri deponuzun yüksek kullanım altında olup olmadığını denetleyin. Bu durumda veri deposundaki iş yüklerinizi azaltın veya azaltma sınırını veya kullanılabilir kaynağı artırmak için veri deposu yöneticinize başvurun.
Kopyalama kaynağınızı ve havuz deseninizi denetleyin:
Kopyalama deseniniz 4'ten büyük Veri Entegrasyonu Birimi (DIU) destekliyorsa ayrıntılarla ilgili bu bölüme bakın; genellikle daha iyi performans elde etmek için DIU'ları artırmayı deneyebilirsiniz.
Aksi takdirde, tek bir büyük veri kümesini birkaç küçük veri kümesine bölmeyi ve bu kopyalama işlerinin verilerin her bir kısmını eşzamanlı olarak çalıştırmasını sağlayın. Bunu Lookup/GetMetadata + ForEach + Copy ile yapabilirsiniz. Genel örnek olarak, Birden çok kapsayıcıdan dosya kopyalama, Amazon S3'ten ADLS 2. Nesil'e veri geçirme veya Denetim tablosu çözüm şablonlarıyla toplu kopyalama bölümüne bakın.
Azure IR'yi kaynak veri deposu bölgenizle aynı veya yakın konumda kullanın.
"Aktar - havuza yazma" uzun çalışma süresi yaşadı:
Uygulanıyorsa bağlayıcıya özgü veri yükleme en iyi uygulamasını benimseyin. Örneğin, Verileri Azure Synapse Analytics'e kopyalarken PolyBase veya COPY deyimini kullanın.
Hizmetin havuz üzerinde azaltma hatası bildirip bildirmediğini veya veri deponuzun yüksek kullanım altında olup olmadığını denetleyin. Bu durumda veri deposundaki iş yüklerinizi azaltın veya azaltma sınırını veya kullanılabilir kaynağı artırmak için veri deposu yöneticinize başvurun.
Kopyalama kaynağınızı ve havuz deseninizi denetleyin:
Kopyalama deseniniz 4'ten büyük Veri Entegrasyonu Birimi (DIU) destekliyorsa ayrıntılarla ilgili bu bölüme bakın; genellikle daha iyi performans elde etmek için DIU'ları artırmayı deneyebilirsiniz.
Aksi takdirde, paralel kopyaları aşamalı olarak ayarlayın, çok fazla paralel kopyanın performansa zarar verebileceğini unutmayın.
Azure IR'yi havuz veri deposu bölgenizle aynı veya yakın konumda kullanın.
Şirket içinde barındırılan IR'de kopyalama etkinliği sorunlarını giderme
Senaryonuz için performans testini planlamak ve yürütmek için Performans ayarlama adımlarını izleyin.
Kopyalama performansı beklentilerinizi karşılamadığında, Azure Integration Runtime'da çalışan tek kopyalama etkinliğinin sorunlarını gidermek için kopyalama izleme görünümünde performans ayarlama ipuçlarının gösterildiğini görürseniz öneriyi uygulayın ve yeniden deneyin. Aksi takdirde kopyalama etkinliği yürütme ayrıntılarını anlayın, hangi aşamanın en uzun süreye sahip olduğunu denetleyin ve kopyalama performansını artırmak için aşağıdaki kılavuzu uygulayın:
"Kuyruk" uzun süre yaşadı: Bu, şirket içinde barındırılan IR'nizin yürütülecek kaynağı olana kadar kopyalama etkinliğinin kuyrukta uzun süre beklediği anlamına gelir. IR kapasitesini ve kullanımını denetleyin ve iş yükünüze göre ölçeği artırın veya genişletin .
"Aktarım - İlk bayta kadar olan süre" uzun çalışma süresiyle karşılaşmıştır: Bu, kaynak sorgunuzun veri döndürmesi uzun sürdüğü anlamına gelir. Sorguyu veya sunucuyu denetleyin ve iyileştirin. Daha fazla yardıma ihtiyacınız varsa veri deposu ekibinize başvurun.
"Aktar - Kaynak listeleme" uzun çalışma süresi yaşadı: Kaynak dosyaları veya kaynak veritabanı veri bölümlerini listelemenin yavaş olduğu anlamına gelir.
Şirket içinde barındırılan IR makinesinin kaynak veri deposuna bağlanmada düşük gecikme süresi olup olmadığını denetleyin. Kaynağınız Azure'daysa, şirket içinde barındırılan IR makinesinden Azure bölgesine olan gecikme süresini denetlemek için bu aracı kullanabilirsiniz.
Dosya tabanlı kaynaktan veri kopyalarken, klasör yolunda veya dosya adında (
wildcardFolderPathveya ) joker karakter filtresi kullanırsanız veya dosya son değiştirme zamanı filtresini (modifiedDatetimeStartveyamodifiedDatetimeEnd) kullanırsanız, bu filtrenin, belirtilen klasör altındaki tüm dosyaların istemci tarafına listelenmesine neden olacağını unutmayın ve ardından filtreyiwildcardFileNameuygulayın. Bu tür dosya numaralandırması, özellikle yalnızca küçük dosya kümesi filtre kuralına uyulduğunda performans sorununa neden olabilir.Dosyaları tarih saat bölümlenmiş dosya yoluna veya adına göre kopyalayıp kopyalayamayacağınızı denetleyin. Bu şekilde kaynak tarafı listeleme yükü getirmez.
Bunun yerine veri deposu yerel filtresini kullanıp kullanamadığını denetleyin; özellikle Amazon S3/Azure Blob storage/Azure Dosyalar için "ön ek" ve ADLS 1. Nesil için "listAfter/listBefore". Bu filtreler veri deposu sunucu tarafı filtresidir ve çok daha iyi performansa sahip olur.
Tek bir büyük veri kümesini birkaç küçük veri kümesine bölmeyi ve bu kopyalama işlerinin verilerin her bir bölümünü eşzamanlı olarak çalıştırmasına izin vermeyi düşünün. Bunu Lookup/GetMetadata + ForEach + Copy ile yapabilirsiniz. Genel örnek olarak, Birden çok kapsayıcıdan dosya kopyalama veya Amazon S3'ten ADLS 2. Nesil çözüm şablonlarına veri geçirme bölümüne bakın.
Hizmetin kaynakta azaltma hatası bildirip bildirmediğini veya veri deponuzun yüksek kullanım durumunda olup olmadığını denetleyin. Bu durumda veri deposundaki iş yüklerinizi azaltın veya azaltma sınırını veya kullanılabilir kaynağı artırmak için veri deposu yöneticinize başvurun.
"Aktarım - kaynaktan okuma" uzun çalışma süresi yaşadı:
Şirket içinde barındırılan IR makinesinin kaynak veri deposuna bağlanmada düşük gecikme süresi olup olmadığını denetleyin. Kaynağınız Azure'daysa, şirket içinde barındırılan IR makinesinden Azure bölgelerine kadar olan gecikme süresini denetlemek için bu aracı kullanabilirsiniz.
Şirket içinde barındırılan IR makinesinin verileri verimli bir şekilde okumak ve aktarmak için yeterli gelen bant genişliğine sahip olup olmadığını denetleyin. Kaynak veri deponuz Azure'daysa indirme hızını denetlemek için bu aracı kullanabilirsiniz.
Veri fabrikanız veya Synapse çalışma alanınız> olan> Azure portalında Şirket içinde barındırılan IR'nin CPU ve bellek kullanımı eğilimine genel bakış sayfasını gözden geçirin. CPU kullanımı yüksekse veya kullanılabilir bellek düşükse IR ölçeğini artırmayı/genişletmeyi göz önünde bulundurun.
Uygulanıyorsa bağlayıcıya özgü veri yükleme en iyi uygulamasını benimseyin. Örneğin:
Oracle, Netezza, Teradata, SAP HANA, SAP Table ve SAP Open Hub'dan veri kopyalarken, verileri paralel olarak kopyalamak için veri bölümü seçeneklerini etkinleştirin.
HDFS'den veri kopyalarken DistCp kullanacak şekilde yapılandırın.
Amazon Redshift'ten veri kopyalarken Redshift UNLOAD kullanacak şekilde yapılandırın.
Hizmetin kaynakta azaltma hatası bildirip bildirmediğini veya veri deponuzun yüksek kullanım altında olup olmadığını denetleyin. Bu durumda veri deposundaki iş yüklerinizi azaltın veya azaltma sınırını veya kullanılabilir kaynağı artırmak için veri deposu yöneticinize başvurun.
Kopyalama kaynağınızı ve havuz deseninizi denetleyin:
Bölüm seçeneği etkin veri depolarından veri kopyalarsanız, paralel kopyaları aşamalı olarak ayarlamayı göz önünde bulundurun; çok fazla paralel kopyanın performansı bile olumsuz etkileyeebileceğini unutmayın.
Aksi takdirde, tek bir büyük veri kümesini birkaç küçük veri kümesine bölmeyi ve bu kopyalama işlerinin verilerin her bir kısmını eşzamanlı olarak çalıştırmasını sağlayın. Bunu Lookup/GetMetadata + ForEach + Copy ile yapabilirsiniz. Genel örnek olarak, Birden çok kapsayıcıdan dosya kopyalama, Amazon S3'ten ADLS 2. Nesil'e veri geçirme veya Denetim tablosu çözüm şablonlarıyla toplu kopyalama bölümüne bakın.
"Aktar - havuza yazma" uzun çalışma süresi yaşadı:
Uygulanıyorsa bağlayıcıya özgü veri yükleme en iyi uygulamasını benimseyin. Örneğin, Verileri Azure Synapse Analytics'e kopyalarken PolyBase veya COPY deyimini kullanın.
Şirket içinde barındırılan IR makinesinin havuz veri deposuna düşük gecikme süresine sahip olup olmadığını denetleyin. Havuzunuz Azure'daysa, şirket içinde barındırılan IR makinesinden Azure bölgesine kadar olan gecikme süresini denetlemek için bu aracı kullanabilirsiniz.
Şirket içinde barındırılan IR makinesinin verileri verimli bir şekilde aktarmak ve yazmak için yeterli giden bant genişliğine sahip olup olmadığını denetleyin. Havuz veri deponuz Azure'daysa yükleme hızını denetlemek için bu aracı kullanabilirsiniz.
Azure portalında şirket içinde barındırılan IR'nin CPU ve bellek kullanımı eğiliminin (> veri fabrikanız veya Synapse çalışma alanınız)> genel bakış sayfasında olup olmadığını denetleyin. CPU kullanımı yüksekse veya kullanılabilir bellek düşükse IR ölçeğini artırmayı/genişletmeyi göz önünde bulundurun.
Hizmetin havuz üzerinde azaltma hatası bildirip bildirmediğini veya veri deponuzun yüksek kullanım altında olup olmadığını denetleyin. Bu durumda veri deposundaki iş yüklerinizi azaltın veya azaltma sınırını veya kullanılabilir kaynağı artırmak için veri deposu yöneticinize başvurun.
Paralel kopyaları aşamalı olarak ayarlamayı göz önünde bulundurun, çok fazla paralel kopyanın performansa zarar verebileceğini unutmayın.
Bağlan ve IR performansı
Bu bölümde, belirli bağlayıcı türü veya tümleştirme çalışma zamanı için bazı performans sorun giderme kılavuzları incelenmektedir.
Etkinlik yürütme süresi, Azure IR ile Azure VNet IR arasında değişiklik gösterir
Veri kümesi farklı Integration Runtime'a dayalı olduğunda etkinlik yürütme süresi değişir.
Belirtiler: Yalnızca veri kümesindeki Bağlı Hizmet açılan listesinin geçişini yapmak aynı işlem hattı etkinliklerini gerçekleştirir, ancak önemli ölçüde farklı çalışma sürelerine sahiptir. Veri kümesi Yönetilen Sanal Ağ Tümleştirme Çalışma Zamanı'nı temel aldığında, Varsayılan Tümleştirme Çalışma Zamanı'nı temel alan çalıştırmadan ortalama olarak daha fazla zaman alır.
Neden: İşlem hattı çalıştırmalarının ayrıntılarını denetlediğinizde, Azure IR'de normal işlem hattı çalışırken yavaş işlem hattının Yönetilen Sanal Ağ (Sanal Ağ) IR üzerinde çalıştığını görebilirsiniz. Hizmet örneği başına bir işlem düğümü ayırmadığımız için Yönetilen Sanal Ağ IR'si, tasarım gereği Azure IR'den daha uzun kuyruk süresine sahiptir. Bu nedenle her kopyalama etkinliğinin başlatılması için bir ısınma vardır ve öncelikle Azure IR yerine sanal ağ katılımında gerçekleşir.
verileri Azure SQL Veritabanı yüklerken düşük performans
Belirtiler: Azure SQL Veritabanı'a veri kopyalama işlemi yavaş olmaya başladı.
Neden: Sorunun kök nedeni çoğunlukla Azure SQL Veritabanı tarafındaki performans sorunu tarafından tetikleniyor. Olası nedenler şunlardır:
Azure SQL Veritabanı katmanı yeterince yüksek değil.
Azure SQL Veritabanı DTU kullanımı %100'e yakındır. Performansı izleyebilir ve Azure SQL Veritabanı katmanını yükseltmeyi düşünebilirsiniz.
Dizinler düzgün ayarlanmadı. Veri yüklemeden önce tüm dizinleri kaldırın ve yükleme tamamlandıktan sonra yeniden oluşturun.
WriteBatchSize şema satırı boyutuna sığacak kadar büyük değil. Sorunun özelliğini büyütmeyi deneyin.
Toplu ekleme yerine, daha kötü performansa sahip olması beklenen saklı yordam kullanılıyor.
Büyük Excel dosyasını ayrıştırırken zaman aşımı veya yavaş performans
Belirtiler:
Excel veri kümesi oluşturduğunuzda ve şemayı bağlantıdan/depodan, önizleme verilerinden, listelerden veya yenileme çalışma sayfalarından içeri aktardığınızda, Excel dosyasının boyutu büyükse zaman aşımı hatasıyla karşılaşabilirsiniz.
Büyük Excel dosyasından (>= 100 MB) diğer veri deposuna veri kopyalamak için kopyalama etkinliğini kullandığınızda, yavaş performans veya OOM sorunuyla karşılaşabilirsiniz.
Neden:
Şemayı içeri aktarma, verileri önizleme ve Excel veri kümesindeki çalışma sayfalarını listeleme gibi işlemler için zaman aşımı 100 sn ve statiktir. Büyük Excel dosyası için bu işlemler zaman aşımı değeri içinde bitmeyebilir.
Kopyalama etkinliği, excel dosyasının tamamını belleğe okur ve ardından verileri okumak için belirtilen çalışma sayfasını ve hücreleri bulur. Bu davranış, hizmetin kullandığı temel SDK'dan kaynaklanır.
Çözüm:
Şemayı içeri aktarmak için, özgün dosyanın alt kümesi olan daha küçük bir örnek dosya oluşturabilir ve "şemayı bağlantıdan/depodan içeri aktar" yerine "örnek dosyadan şemayı içeri aktar" seçeneğini belirleyebilirsiniz.
Çalışma sayfasını listelemek için, çalışma sayfası açılan listesinde "Düzenle"ye tıklayabilir ve bunun yerine sayfa adını/dizinini giriş yapabilirsiniz.
Büyük Excel dosyasını (>100 MB) başka bir depoya kopyalamak için, spor akışının daha iyi okunduğu ve daha iyi performans sergilediği Veri Akışı Excel kaynağını kullanabilirsiniz.
Büyük JSON/Excel/XML dosyalarını okuma OOM Sorunu
Belirtiler: Büyük JSON/Excel/XML dosyalarını okuduğunuzda, etkinlik yürütme sırasında bellek yetersiz (OOM) sorununu karşılarsınız.
Neden:
- Büyük XML dosyaları için: Büyük XML dosyalarının okunmasıyla ilgili OOM sorunu tasarım gereğidir. Bunun nedeni, xml dosyasının tamamının tek bir nesne olduğu için belleğe okunması, ardından şemanın çıkarılıp verilerin alınmasıdır.
- Büyük Excel dosyaları için: Büyük Excel dosyalarını okumanın OOM sorunu tasarım gereğidir. Bunun nedeni, kullanılan SDK'nın (POI/NPOI) excel dosyasının tamamını belleğe okuması, ardından şemayı çıkarması ve veri alması gerekir.
- Büyük JSON dosyaları için: Büyük JSON dosyalarının okunmasıyla ilgili OOM sorunu, JSON dosyası tek bir nesne olduğunda tasarım gereğidir.
Öneri: Sorununuzu çözmek için aşağıdaki seçeneklerden birini uygulayın.
- 1. Seçenek: Kopyalama etkinliğiniz aracılığıyla büyük dosyanızdaki verileri okumak için güçlü makine (yüksek CPU/bellek) ile çevrimiçi şirket içinde barındırılan bir tümleştirme çalışma zamanı kaydedin.
- 2. Seçenek: Eşleme veri akışı etkinliği aracılığıyla büyük dosyanızdaki verileri okumak için iyileştirilmiş bellek ve büyük boyutlu küme (örneğin, 48 çekirdek) kullanın.
- Seçenek-3: Büyük dosyayı küçük dosyalara bölün, ardından klasörü okumak için kopyalama veya eşleme veri akışı etkinliğini kullanın.
- Seçenek-4: XML/Excel/JSON klasörünü kopyalama sırasında takılı kaldıysanız veya OOM sorununu karşılıyorsanız, her dosyayı veya alt klasörü işlemek için işlem hattınızdaki foreach etkinliği + kopyalama/eşleme veri akışı etkinliğini kullanın.
- Seçenek-5: Diğerleri:
- XML için, her dosya aynı şemaya sahipse dosyalardan verileri okumak için bellek için iyileştirilmiş kümeyle Not Defteri etkinliğini kullanın. Şu anda Spark'ın XML işlemek için farklı uygulamaları vardır.
- JSON için, eşleme veri akışı kaynağı altındaki JSON ayarlarında farklı belge formlarını (örneğin, Tek belge, Satır başına belge ve Belge dizisi) kullanın. JSON dosya içeriği Satır başına belge ise çok az bellek tüketir.
Diğer başvurular
Desteklenen veri depolarından bazıları için performans izleme ve ayarlama başvuruları aşağıdadır:
- Azure Blob depolama: Blob depolama için ölçeklenebilirlik ve performans hedefleri ile Blob depolama için Performans ve ölçeklenebilirlik denetim listesi.
- Azure Tablo depolama: Tablo depolama için ölçeklenebilirlik ve performans hedefleri ile Tablo depolama için Performans ve ölçeklenebilirlik denetim listesi.
- Azure SQL Veritabanı: Performansı izleyebilir ve Veritabanı İşlem Birimi (DTU) yüzdesini de kontrol edebilirsiniz.
- Azure Synapse Analytics: Özelliği Veri Ambarı Birimlerinde (DWU) ölçülür. Bkz. Azure Synapse Analytics'te işlem gücünü yönetme (Genel Bakış).
- Azure Cosmos DB: Azure Cosmos DB'de performans düzeyleri.
- SQL Server: Performansı izleyin ve ayarlayın.
- Şirket içi dosya sunucusu: Dosya sunucuları için performans ayarlama.
İlgili içerik
Diğer kopyalama etkinliği makalelerine bakın: