Delta tablo akışı okuma ve yazma işlemleri
Delta Lake, ve writeStreamaracılığıyla readStream Spark Yapılandırılmış Akışı ile derin bir şekilde tümleşiktir. Delta Lake, akış sistemleri ve dosyalarıyla ilgili aşağıdakiler gibi birçok sınırlamanın üstesinden gelir:
- Düşük gecikme süresiyle alınan küçük dosyaları birleştirme.
- Birden fazla akışla (veya eşzamanlı toplu işlerle) "tam olarak bir kez" işlemeyi koruma.
- Bir akışın kaynağı olarak dosyaları kullanırken hangi dosyaların yeni olduğunu verimli bir şekilde bulma.
Not
Bu makalede Delta Lake tablolarının akış kaynakları ve havuzlar olarak kullanılması açıklanmaktadır. Databricks SQL'de akış tablolarını kullanarak veri yüklemeyi öğrenmek için bkz . Databricks SQL'de akış tablolarını kullanarak veri yükleme.
Kaynak olarak Delta tablosu
Yapılandırılmış Akış, Delta tablolarını artımlı olarak okur. Delta tablosunda akış sorgusu etkin olsa da, yeni tablo sürümleri kaynak tabloya işlendiğinde yeni kayıtlar bir kez etkili bir şekilde işlenir.
Aşağıdaki kod örneklerde, tablo adını veya dosya yolunu kullanarak bir akış okuma yapılandırması gösterilmektedir.
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Önemli
Delta tablosunun şeması, akış okuması tabloda başladıktan sonra değişirse sorgu başarısız olur. Çoğu şema değişikliğinde, şema uyuşmazlıklarını çözmek ve işlemeye devam etmek için akışı yeniden başlatabilirsiniz.
Databricks Runtime 12.2 LTS ve altında, sütunları yeniden adlandırma veya bırakma gibi eklemeli olmayan şema evriminden geçmiş sütun eşlemesi etkinleştirilmiş bir Delta tablosundan akış yapamazsınız. Ayrıntılar için bkz. Sütun eşleme ve şema değişiklikleriyle akış.
Giriş hızını sınırla
Mikro toplu işlemleri denetlemek için aşağıdaki seçenekler kullanılabilir:
maxFilesPerTrigger: Her mikro toplu işlemde dikkate alınması gereken yeni dosya. Varsayılan değer 1000’dir.maxBytesPerTrigger: Her mikro toplu işlemde ne kadar verinin işlendiği. Bu seçenek bir "soft max" ayarlar; başka bir deyişle bir toplu işlem yaklaşık olarak bu miktarda veriyi işler ve en küçük giriş biriminin bu sınırdan büyük olduğu durumlarda akış sorgusunun ileriye doğru ilerlemesini sağlamak için sınırdan daha fazlasını işleyebilecektir. Bu varsayılan olarak ayarlanmaz.
ile maxFilesPerTriggerbirlikte kullanırsanızmaxBytesPerTrigger, mikro toplu işlem veya maxBytesPerTrigger sınırına ulaşılana maxFilesPerTrigger kadar verileri işler.
Not
Kaynak tablo işlemlerinin yapılandırma nedeniyle logRetentionDurationtemizlendiği ve akış sorgusunun bu sürümleri işlemeye çalıştığı durumlarda, sorgu varsayılan olarak veri kaybını önleyemezse. Kayıp verileri yoksaymak ve işlemeye devam etmek için false seçeneğini failOnDataLoss ayarlayabilirsiniz.
Delta Lake değişiklik veri yakalama (CDC) akışı akışı
Delta Lake değişiklik veri akışı , güncelleştirmeler ve silmeler de dahil olmak üzere delta tablosundaki değişiklikleri kaydeder. Etkinleştirildiğinde, değişiklik veri akışından akış yapabilir ve eklemeleri, güncelleştirmeleri ve silme işlemlerini aşağı akış tablolarına işlemek için mantık yazabilirsiniz. Değişiklik veri akışı veri çıkışı, açıklandığı Delta tablosundan biraz farklı olsa da, bu, madalyon mimarisindeki aşağı akış tablolarına artımlı değişiklikler yaymaya yönelik bir çözüm sağlar.
Önemli
Databricks Runtime 12.2 LTS ve altında, sütunları yeniden adlandırma veya bırakma gibi eklemesiz şema evrimi geçirmiş sütun eşlemesi etkin bir Delta tablosunun değişiklik veri akışından akış yapamazsınız. Bkz. Sütun eşleme ve şema değişiklikleriyle akış yapma.
Güncelleştirmeleri ve silmeleri yoksay
Yapılandırılmış Akış, ekleme olmayan girişleri işlemez ve kaynak olarak kullanılan tabloda herhangi bir değişiklik olursa bir özel durum oluşturur. Otomatik olarak aşağı akışa yayılamayan değişikliklerle ilgilenmek için iki ana strateji vardır:
- Çıktıyı ve denetim noktasını silebilir ve akışı baştan yeniden başlatabilirsiniz.
- Şu iki seçenekten birini ayarlayabilirsiniz:
ignoreDeletes: bölüm sınırlarında verileri silen işlemleri yoksayın.skipChangeCommits: mevcut kayıtları silen veya değiştiren işlemleri yoksayın.skipChangeCommits,ignoreDeletesişlemini kapsar.
Not
Databricks Runtime 12.2 LTS ve üzerinde önceki skipChangeCommits ayarı ignoreChangeskullanımdan kaldırıyor. Databricks Runtime 11.3 LTS ve altında ignoreChanges desteklenen tek seçenektir.
ignoreChanges ile skipChangeCommits semantiği ile arasında büyük farklar vardır. ignoreChangesetkinleştirildiğinde, kaynak tablodaki yeniden yazılan veri dosyaları, UPDATE, MERGE INTO, DELETE(bölümler içinde) veya OVERWRITE gibi bir veri değiştirme işleminden sonra yeniden yayılır. Değişmeyen satırlar genellikle yeni satırlarla birlikte yayılır, bu nedenle aşağı akış tüketicilerinin yinelenenleri işleyebilmesi gerekir. Silme işlemleri aşağı akışa yayılmaz. ignoreChanges, ignoreDeletes işlemini kapsar.
skipChangeCommits, dosya değiştirme işlemlerini tamamen göz ardı eder. UPDATE, MERGE INTO, DELETE ve OVERWRITE gibi veri değiştirme işlemi nedeniyle kaynak tabloda yeniden yazılan veri dosyaları tamamen yoksayılır. Yukarı akış kaynak tablolarındaki değişiklikleri yansıtmak için ayrı bir mantık uygulayarak bu değişiklikleri yaymanız gerekir.
ile ignoreChanges yapılandırılan iş yükleri bilinen semantiği kullanarak çalışmaya devam eder, ancak Databricks tüm yeni iş yükleri için kullanılmasını skipChangeCommits önerir. kullanarak ignoreChanges iş yüklerinin geçirilmesi için skipChangeCommits yeniden düzenleme mantığı gerekir.
Örnek
Örneğin, ile bölümlenmiş , user_emailve action sütunları olan bir tablonuz user_eventsdatedateolduğunu varsayalım. Tablodan user_events akışla çıkarsınız ve GDPR nedeniyle veri silmeniz gerekir.
Bölüm sınırlarında sildiğinizde (yani, WHERE bir bölüm sütunundadır), dosyalar zaten değere göre segmentlere ayrılmıştır, bu nedenle silme işlemi yalnızca bu dosyaları meta verilerden bırakır. Veri bölümünün tamamını sildiğinizde aşağıdakileri kullanabilirsiniz:
spark.readStream.format("delta")
.option("ignoreDeletes", "true")
.load("/tmp/delta/user_events")
Birden çok bölümdeki verileri silerseniz (bu örnekte filtreleme) user_emailaşağıdaki söz dizimini kullanın:
spark.readStream.format("delta")
.option("skipChangeCommits", "true")
.load("/tmp/delta/user_events")
deyimiyle UPDATE güncelleştirdiğinizdeuser_email, söz konusu dosyayı içeren user_email dosya yeniden yazılır. Değiştirilen veri dosyalarını yoksaymak için kullanın skipChangeCommits .
İlk konumu belirtme
Delta Lake akış kaynağının başlangıç noktasını tablonun tamamını işlemeden belirtmek için aşağıdaki seçenekleri kullanabilirsiniz.
startingVersion: Başlangıç olarak Delta Lake sürümü. Databricks, çoğu iş yükü için bu seçeneğin atlanması önerilir. Ayarlanmadığında akış, tablonun o anda tam bir anlık görüntüsü de dahil olmak üzere kullanılabilir en son sürümden başlar.Belirtilirse, akış belirtilen sürümden (dahil) başlayarak Delta tablosundaki tüm değişiklikleri okur. Belirtilen sürüm artık kullanılamıyorsa akış başlatılamaz. İşleme sürümlerini
versionDESCRIBE HISTORY komut çıkışının sütunundan alabilirsiniz.Yalnızca en son değişiklikleri döndürmek için belirtin
latest.startingTimestamp: Başlangıç olarak zaman damgası. Zaman damgası (dahil) sırasında veya sonrasında işlenen tüm tablo değişiklikleri akış okuyucusu tarafından okunur. Sağlanan zaman damgası tüm tablo işlemelerinden önce gelirse, akış okuması en erken kullanılabilir zaman damgasıyla başlar. Bunlardan biri:- Zaman damgası dizesi. Örneğin,
"2019-01-01T00:00:00.000Z". - Tarih dizesi. Örneğin,
"2019-01-01".
- Zaman damgası dizesi. Örneğin,
Her iki seçeneği de aynı anda ayarlayamazsınız. Yalnızca yeni bir akış sorgusu başlatılırken geçerlilik kazanırlar. Akış sorgusu başlatıldıysa ve ilerleme durumu denetim noktasına kaydedildiyse, bu seçenekler yoksayılır.
Önemli
Akış kaynağını belirtilen bir sürümden veya zaman damgasından başlatabilirsiniz, ancak akış kaynağının şeması her zaman Delta tablosunun en son şemasıdır. Belirtilen sürümden veya zaman damgasından sonra Delta tablosunda uyumsuz şema değişikliği olmadığından emin olmanız gerekir. Aksi takdirde, akış kaynağı verileri yanlış şemayla okurken yanlış sonuçlar döndürebilir.
Örnek
Örneğin, bir tablonuz user_eventsolduğunu varsayalım. Sürüm 5'ten bu yana yapılan değişiklikleri okumak istiyorsanız şunu kullanın:
spark.readStream.format("delta")
.option("startingVersion", "5")
.load("/tmp/delta/user_events")
2018-10-18'den bu yana yapılan değişiklikleri okumak istiyorsanız şunu kullanın:
spark.readStream.format("delta")
.option("startingTimestamp", "2018-10-18")
.load("/tmp/delta/user_events")
Veriler bırakılmadan ilk anlık görüntüyü işleme
Not
Bu özellik Databricks Runtime 11.3 LTS ve üzerinde kullanılabilir. Bu özellik Genel Önizlemededir.
Delta tablosunu akış kaynağı olarak kullanırken sorgu önce tabloda bulunan tüm verileri işler. Bu sürümdeki Delta tablosuna ilk anlık görüntü adı verilir. Varsayılan olarak, Delta tablosunun veri dosyaları en son hangi dosyanın değiştirildiğine göre işlenir. Ancak, son değişiklik saati mutlaka kayıt olayı saat sırasını temsil etmez.
Tanımlı filigrana sahip durum bilgisi olan bir akış sorgusunda, dosyaların değişiklik zamanına göre işlenmesi kayıtların yanlış sırada işlenmesine neden olabilir. Bu, kayıtların filigran tarafından geç olaylar olarak düşmesine neden olabilir.
Aşağıdaki seçeneği etkinleştirerek veri bırakma sorununu önleyebilirsiniz:
- withEventTimeOrder: İlk anlık görüntünün olay zaman sırası ile işlenip işlenmeyeceği.
Olay zaman sırası etkinleştirildiğinde, ilk anlık görüntü verilerinin olay zaman aralığı zaman demetlerine ayrılır. Her mikro toplu işlem, zaman aralığındaki verileri filtreleyerek bir demeti işler. maxFilesPerTrigger ve maxBytesPerTrigger yapılandırma seçenekleri hala mikrobatch boyutunu denetlemek için geçerlidir, ancak yalnızca işlemin doğası gereği yaklaşık bir şekilde geçerlidir.
Aşağıdaki grafikte bu işlem gösterilmektedir:
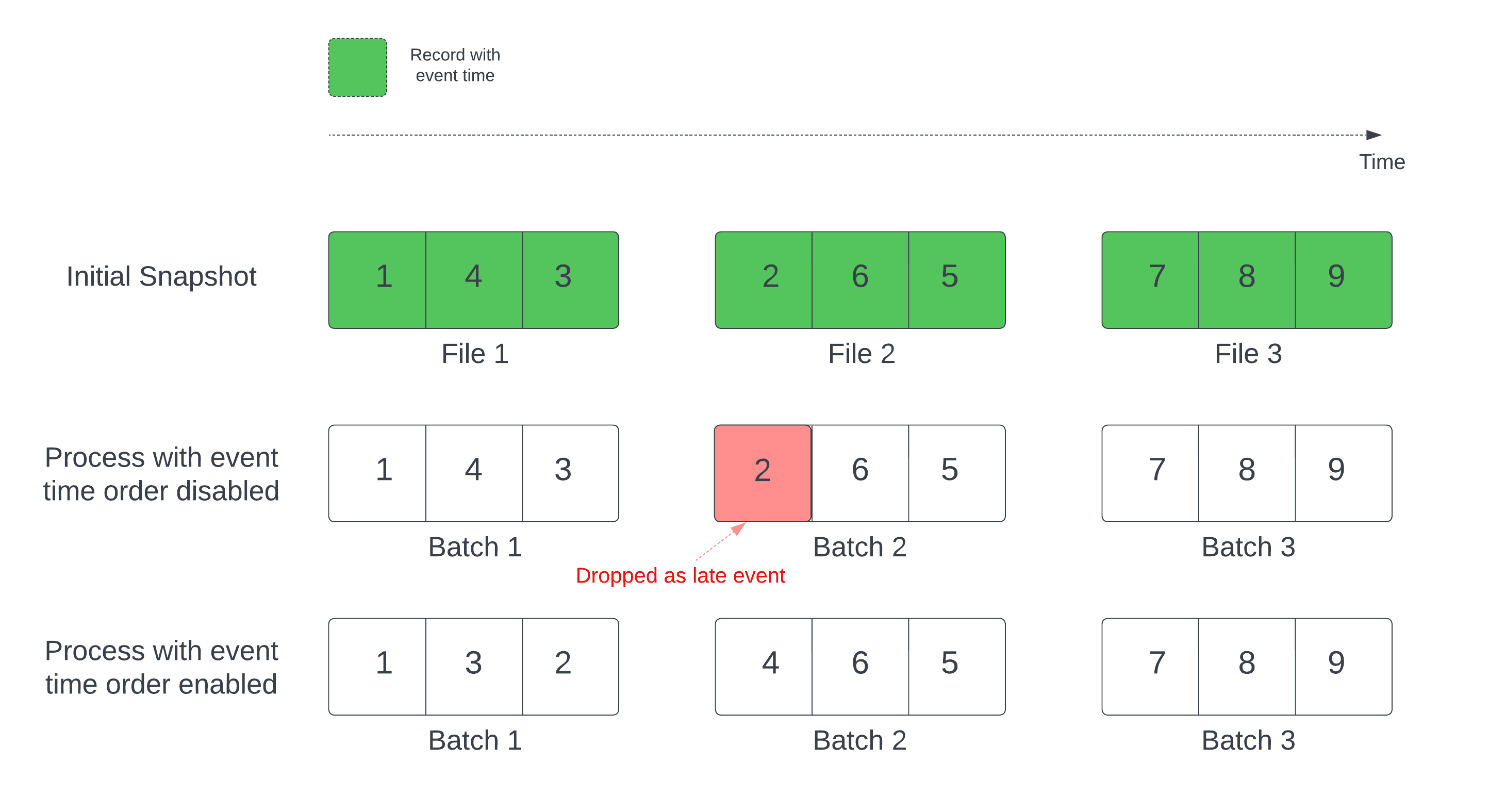
Bu özellik hakkında önemli bilgiler:
- Veri bırakma sorunu yalnızca durum bilgisi olan bir akış sorgusunun ilk Delta anlık görüntüsü varsayılan sırada işlendiğinde oluşur.
- İlk anlık görüntü işlenmeye devam ederken akış sorgusu başlatıldıktan sonra değiştiremezsiniz
withEventTimeOrder. Değişiklikle yenidenwithEventTimeOrderbaşlatmak için denetim noktasını silmeniz gerekir. - AventTimeOrder etkinken bir akış sorgusu çalıştırıyorsanız, ilk anlık görüntü işleme tamamlanana kadar bu özelliği desteklemeyen bir DBR sürümüne düşüremezsiniz. Eski sürüme düşürmeniz gerekiyorsa, ilk anlık görüntünün bitmesini bekleyebilir veya denetim noktasını silip sorguyu yeniden başlatabilirsiniz.
- Bu özellik aşağıdaki yaygın olmayan senaryolarda desteklenmez:
- Olay zamanı sütunu oluşturulan bir sütundur ve Delta kaynağı ile filigran arasında projeksiyon dışı dönüştürmeler vardır.
- Akış sorgusunda birden fazla Delta kaynağı olan bir filigran vardır.
- Olay zaman sırası etkinleştirildiğinde Delta ilk anlık görüntü işleme performansı daha yavaş olabilir.
- Her mikro toplu işlem, ilgili olay zaman aralığındaki verileri filtrelemek için ilk anlık görüntüyü tarar. Daha hızlı filtre eylemi için, veri atlama işleminin uygulanabilmesi için olay zamanı olarak delta kaynak sütununun kullanılması önerilir (uygun olduğunda Delta Lake için veri atlama konusuna bakın). Ayrıca, olay zamanı sütunu boyunca tablo bölümleme işlemi daha da hızlandırabilir. Belirli bir mikro toplu iş için kaç delta dosyasının taranmış olduğunu görmek için Spark kullanıcı arabirimini de kontrol edebilirsiniz.
Örnek
Sütunlu event_time bir tablonuz user_events olduğunu varsayalım. Akış sorgunuz bir toplama sorgusudur. İlk anlık görüntü işleme sırasında veri bırakmadığından emin olmak istiyorsanız şunları kullanabilirsiniz:
spark.readStream.format("delta")
.option("withEventTimeOrder", "true")
.load("/tmp/delta/user_events")
.withWatermark("event_time", "10 seconds")
Not
Bunu, tüm akış sorguları için geçerli olacak kümedeki Spark yapılandırmasıyla da etkinleştirebilirsiniz: spark.databricks.delta.withEventTimeOrder.enabled true
Havuz olarak Delta tablosu
Yapılandırılmış Akış kullanarak delta tablosuna da veri yazabilirsiniz. İşlem günlüğü, tablo üzerinde eşzamanlı olarak çalışan başka akışlar veya toplu sorgular olsa bile Delta Lake'in tam olarak bir kez işleme garantisi vermesine olanak tanır.
Not
Delta Lake işlevi Delta Lake VACUUM tarafından yönetilmeyen tüm dosyaları kaldırır ancak ile _başlayan dizinleri atlar. gibi <table-name>/_checkpointsbir dizin yapısı kullanarak Delta tablosu için denetim noktalarını diğer veri ve meta verilerin yanı sıra güvenle depolayabilirsiniz.
Ölçümler
Ve ölçümleri olarak bir akış sorgusu işleminde henüz işlenmek üzere bayt sayısını ve numFilesOutstanding dosya sayısını öğrenebilirsiniznumBytesOutstanding. Ek ölçümler şunlardır:
numNewListedFiles: Bu toplu iş için kapsamı hesaplamak için listelenen Delta Lake dosyalarının sayısı.backlogEndOffset: Kapsamı hesaplamak için kullanılan tablo sürümü.
Akışı bir not defterinde çalıştırıyorsanız, akış sorgusu ilerleme durumu panosundaki Ham Veri sekmesinin altında şu ölçümleri görebilirsiniz:
{
"sources" : [
{
"description" : "DeltaSource[file:/path/to/source]",
"metrics" : {
"numBytesOutstanding" : "3456",
"numFilesOutstanding" : "8"
},
}
]
}
Ekleme modu
Varsayılan olarak, akışlar tabloya yeni kayıtlar ekleyen ekleme modunda çalışır.
yol yöntemini kullanabilirsiniz:
Python
(events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/_checkpoints/")
.start("/delta/events")
)
Scala
events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.start("/tmp/delta/events")
toTable veya yöntemine aşağıdaki gibi bakın:
Python
(events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Tamamlama modu
Tablonun tamamını her toplu işlemle değiştirmek için Yapılandırılmış Akış'ı da kullanabilirsiniz. Örnek kullanım örneklerinden biri, toplamayı kullanarak bir özet hesaplamaktır:
Python
(spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
)
Scala
spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
Yukarıdaki örnek, müşteriye göre toplam olay sayısını içeren bir tabloyu sürekli olarak güncelleştirir.
Daha uzun süreli gecikme süresi gereksinimleri olan uygulamalar için tek seferlik tetikleyicilerle bilgi işlem kaynaklarından tasarruf edebilirsiniz. Belirli bir zamanlamaya göre özet toplama tablolarını güncelleştirmek ve yalnızca son güncelleştirmeden sonra gelen yeni verileri işlemek için bunları kullanın.
Akış statik birleşimleri gerçekleştirme
Akış statik birleşimleri gerçekleştirmek için Delta Lake'in işlem garantilerine ve sürüm oluşturma protokolüne güvenebilirsiniz. Akış statik birleşimi, durum bilgisi olmayan birleştirme kullanarak Delta tablosunun (statik veriler) en son geçerli sürümünü veri akışına ekler.
Azure Databricks bir akış statik birleşiminde mikro toplu verileri işlediğinde, statik Delta tablosundaki verilerin en son geçerli sürümü geçerli mikro toplu iş içinde bulunan kayıtlarla birleşir. Birleştirme durum bilgisi olmadığından filigran yapılandırmanız gerekmez ve düşük gecikme süresiyle sonuçları işleyebilirsiniz. Birleştirmede kullanılan statik Delta tablosundaki veriler yavaş değişiyor olmalıdır.
streamingDF = spark.readStream.table("orders")
staticDF = spark.read.table("customers")
query = (streamingDF
.join(staticDF, streamingDF.customer_id==staticDF.id, "inner")
.writeStream
.option("checkpointLocation", checkpoint_path)
.table("orders_with_customer_info")
)
Kullanarak akış sorgularından upsert foreachBatch
Bir akış sorgusundan merge Delta tablosuna karmaşık upsert'ler yazmak için ve foreachBatch birleşimini kullanabilirsiniz. Bkz. Rastgele veri havuzlarına yazmak için foreachBatch'i kullanma.
Bu desende aşağıdakiler de dahil olmak üzere birçok uygulama vardır:
- Akış toplamalarını Güncelleştirme Modu'nda yazma: Bu, Tam Mod'dan çok daha verimlidir.
- Delta tablosuna veritabanı değişiklikleri akışı yazma: Değişiklik verilerini yazmak için birleştirme sorgusu, delta tablosuna sürekli olarak bir değişiklik akışı uygulamak için içinde kullanılabilir
foreachBatch. - Yinelenenleri kaldırma ile Delta tablosuna veri akışı yazma: Yinelenenleri kaldırma için yalnızca ekleme birleştirme sorgusu, yinelenen verileri otomatik yinelenenleri kaldırma ile bir Delta tablosuna sürekli olarak yazmak için içinde
foreachBatchkullanılabilir.
Not
- Akış sorgusunun yeniden başlatılması işlemi aynı veri grubuna birden çok kez uygulayaabildiği için içindeki
foreachBatchdeyiminizinmergebir kez etkili olduğundan emin olun. mergeiçindeforeachBatchkullanıldığında, akış sorgusunun giriş veri hızı (aracılığıyla raporlanırStreamingQueryProgressve not defteri hızı grafiğinde görünür) verilerin kaynakta oluşturulduğu gerçek oranın katı olarak raporlanabilir. Bunun nedeni,mergeişleminin giriş verilerini birden çok kez okuması ve giriş ölçümlerinin çarpılmasına neden olmasıdır. Bu bir performans sorunuysa, DataFrame toplu işinimergeişleminden önce önbelleğe alabilir ve ardındanmergeişleminden sonra önbellekten kaldırabilirsiniz.
Aşağıdaki örnekte, bu görevi gerçekleştirmek için içinde foreachBatch SQL'i nasıl kullanabileceğiniz gösterilmektedir:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Aşağıdaki örnekte olduğu gibi akış upsert'leri gerçekleştirmek için Delta Lake API'lerini kullanmayı da seçebilirsiniz:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Idempotent tablo yazmaları foreachBatch
Not
Databricks, güncelleştirmek istediğiniz her havuz için ayrı bir akış yazma yapılandırması önerir. Birden foreachBatch çok tabloya yazmak için kullanılması, yazmaları seri hale getirerek paralelliği azaltır ve genel gecikme süresini artırır.
Delta tabloları, aynı anda birden çok tabloya foreachBatch yazma işlemi yapmak için aşağıdaki DataFrameWriter seçenekleri destekler:
txnAppId: Her DataFrame yazma işlemine geçirebileceğiniz benzersiz bir dize. Örneğin, StreamingQuery Kimliğini olaraktxnAppIdkullanabilirsiniz.txnVersion: İşlem sürümü işlevi gören monoton olarak artan bir sayı.
Delta Lake, yinelenen yazmaları tanımlamak ve yoksaymak için ve txnVersion birleşimini txnAppId kullanır.
Toplu yazma işlemi bir hatayla kesilirse, toplu işlemi yeniden çalıştırmak, çalışma zamanının yinelenen yazma işlemlerini doğru şekilde tanımlamasına ve bunları yoksaymasına yardımcı olmak için aynı uygulamayı ve toplu iş kimliğini kullanır. Uygulama Kimliği (txnAppId), kullanıcı tarafından oluşturulan herhangi bir benzersiz dize olabilir ve akış kimliğiyle ilişkili olması gerekmez. Bkz. Rastgele veri havuzlarına yazmak için foreachBatch'i kullanma.
Uyarı
Akış denetim noktasını siler ve sorguyu yeni bir denetim noktasıyla yeniden başlatırsanız, farklı txnAppIdbir sağlamanız gerekir. Yeni denetim noktaları toplu iş kimliğiyle 0başlar. Delta Lake, toplu iş kimliğini ve txnAppId benzersiz bir anahtar olarak kullanır ve önceden görülen değerleri içeren toplu işlemleri atlar.
Aşağıdaki kod örneği bu düzeni gösterir:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}